Gatling脚本编写技巧篇(二)
脚本示例:
import io.gatling.core.Predef._
import io.gatling.http.Predef._
import scala.concurrent.duration._
class BaiduSimulation extends Simulation {
//读取配置文件
val conf = ConfigFactory.load()
//实例化请求方法
val httpProtocol = http.baseUrl(conf.getString("baseUrl"))
//包装请求接口
val rootEndPointUsers = scenario("信贷重构")
.exec(http("信贷重构-授信申请")
.post("/apply")
.header("Content-Type", "application/json")
.header("Accept-Encoding", "gzip")
.body(RawFileBody("computerdatabase/recordedsimulation/0001_request.json"))
.check(status.is(200)
.saveAs("myresponse") )
.check(bodyString.saveAs("Get_bodys")))
.exec{
session => println("这就是传说的值传递"+session("Get_bodys").as[String] )
session
}
}
配置文件(application.properties):
#新信贷通用接口
baseUrl = http://172.16.3.179:7800
脚本编写:
Gatling脚本的编写主要包含三个步骤:
1. http head配置
2. Scenario 执行细节
3. setUp 组装
编写实例:
//配置文件地址src/galting/resource/application.properties //使用的时候 初始化配置文件的读
val conf = ConfigFactory.load()
报头定义:
//设置请求的根路径
val httpConf = http.baseURL(conf.getString("baseUrl"))
这里需要知道的是报头也可以在seniario中定义(有下列两种方式去设置Json和xml要求的报头)
//http(...).get(...).asJSON等同于:
http(...).get(...)
.header(HttpHeaderNames.ContentType,HttpHeaderValues.ApplicationJson)
.header(HttpHeaderNames.accept,HttpHeaderValues.ApplicationJson) //http(...).get(...).asXML等同于
http(...).get(...)
.header(HttpHeaderNames.ContentType,HttpHeaderValues.ApplicationXml)
.header(HttpHeaderNames.accept,HttpHeaderValues.ApplicationXml)
场景定义:
val rootEndPointUsers = scenario("信贷重构").exec(http("信贷重构-授信申请").post("/apply"))
场景的定义要有名称,原因是同一个模拟器中可以 定义多个场景,场景通常被存储在Scala的变量中
场景的基本机构有两种
exec :用来描述行动,通常是发送到待测应用的一个请求
pause: 用来模拟连续请求的用户思考时间
模拟器的定义:
//设置线程数
setUp(rootEndPointUsers.inject(atOnceUsers(10)).protocols(httpConf))
模拟器的参数:
setUp( rootEndPointUsers.inject(
nothingFor(4 seconds), // 1
atOnceUsers(10), // 2
rampUsers(10) over(5 seconds), // 3
constantUsersPerSec(20) during(15 seconds), // 4
constantUsersPerSec(20) during(15 seconds) randomized, // 5
rampUsersPerSec(10) to 20 during(10 minutes), // 6
rampUsersPerSec(10) to 20 during(10 minutes) randomized, // 7
splitUsers(1000) into(rampUsers(10) over(10 seconds)) separatedBy(10 seconds), // 8
splitUsers(1000) into(rampUsers(10) over(10 seconds)) separatedBy atOnceUsers(30), // 9
heavisideUsers(1000) over(20 seconds) // 10
).protocols(httpConf)
)
| 函数 | 解释 |
| nothingFor(4 seconds) | 等待一个指定的时间 |
| atOnceUsers(10) | 一次性注入指定数量的用户 |
| ampUsers(10) over(5 seconds) | 在指定的时间内,以线性增长的方式注入指定数量的用户 |
| constantUsersPerSec(20) during(15 seconds) | 在指定的时间内,以固定频率注入用户,以每秒的多少用户的方式。固定时间间隔 |
| constantUsersPerSec(20) during(15 seconds) randomized | 在指定时间段内,用固定的频率注入用户,以每秒多少个用户的方式定义。用户以随机间隔注 |
| ampUsersPerSec(10) to 20 during(10 minutes) | 在指定时间段内,从起始频率到目标频率注入用户,以每秒多少个用户的方式定义。用户以固定间隔注入 |
| rampUsersPerSec(10) to 20 during(10 minutes) randomized | 在指定时间段内,从起始频率到目标频率注入用户,以每秒多少个用户的方式定义。用户以随机间隔注入 |
| splitUsers(1000) into(rampUsers(10) over(10 seconds)) separatedBy(10 seconds) | 在指定时间内,重复执行定义好的 注入步骤,间隔指定时间,直到达到最大用户数nbUsers |
| splitUsers(1000) into(rampUsers(10) over(10 seconds)) separatedBy atOnceUsers(30) | 在指定时间内,重复执行定义好的 第一个注入步骤,间隔定义好的 第二个注入步骤,直到达到最大用户数nbUsers |
设置场景属性的时候 需要注意以下两点:
开放的负载:
封闭系统,您可以控制并发的使用数量
封闭系统是并发用户数量有上限的系统。在满负荷运行时,新用户只能在另一个用户退出时才能有效地进入系统
封闭的负载:
开放系统,您可以控制用户的到达率
相反,开放系统无法控制并发用户的数量:即使应用程序无法为用户提供服务,用户也会不断地到达。大多数网站都是这样的
重点注意:
如果您希望根据每秒请求数而不是并发用户数进行推理,那么可以考虑使用constantUsersPerSec()来设置用户的到达率,从而设置请求数,而不需要进行节流,因为在大多数情况下这是多余的
技巧篇:
对于测试中的数据构造 往往是我们比较痛苦的地方 虽然Gatling中提供了参数生成 但是并不能满足我们的测试需求 ,凭借之前对其他工具的理解 同时Gatling
也是运行在java虚拟机中这两点 我尝试了将自己的java工具类放到Gatling中调用 从而进行参数的构造。
下面开始介绍我的做法:
1、在Gatling 工程中的resource 目录下创建一个lib 目录
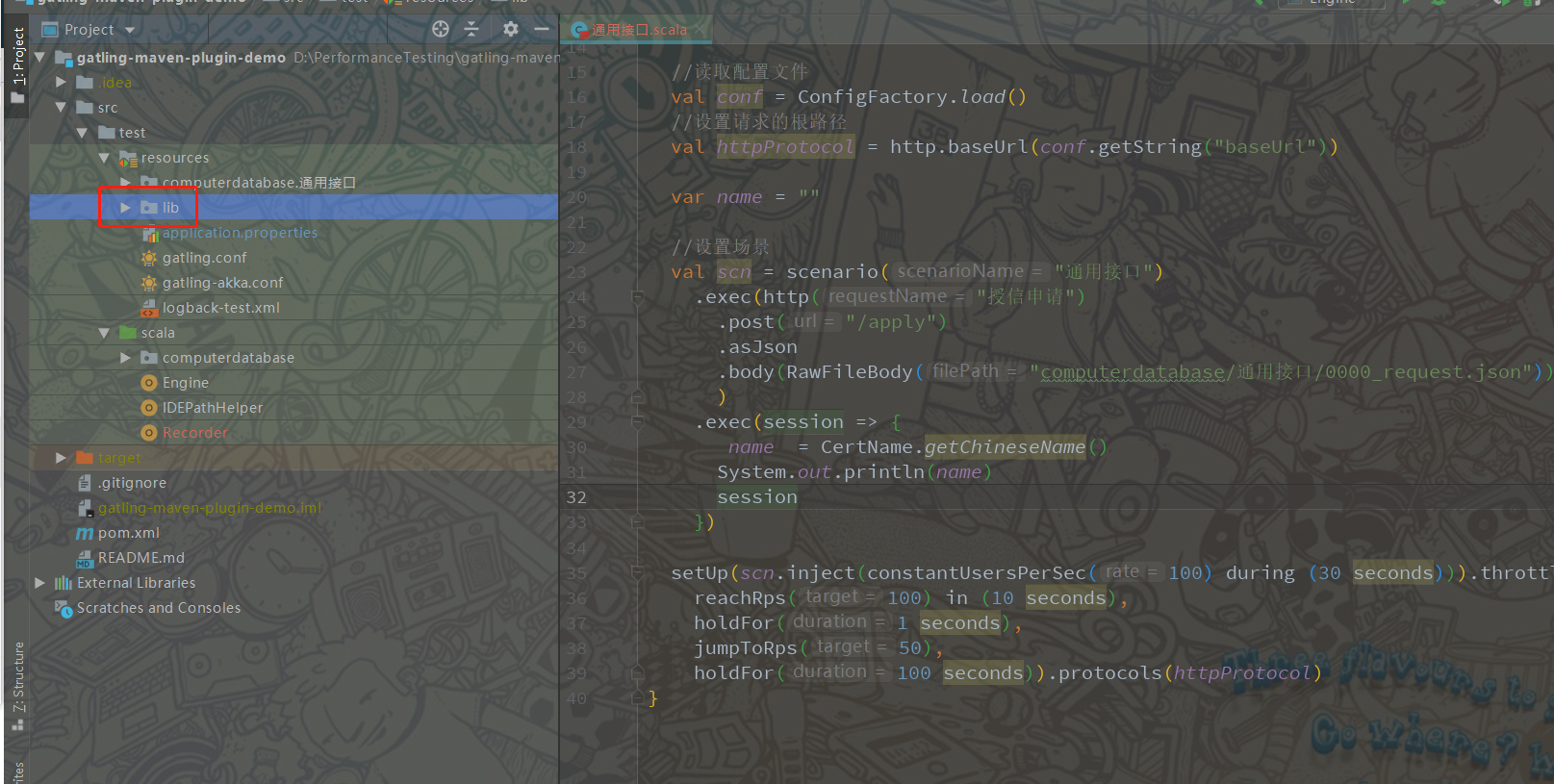
2、将自己生成的工具类jar包放到lib目录下
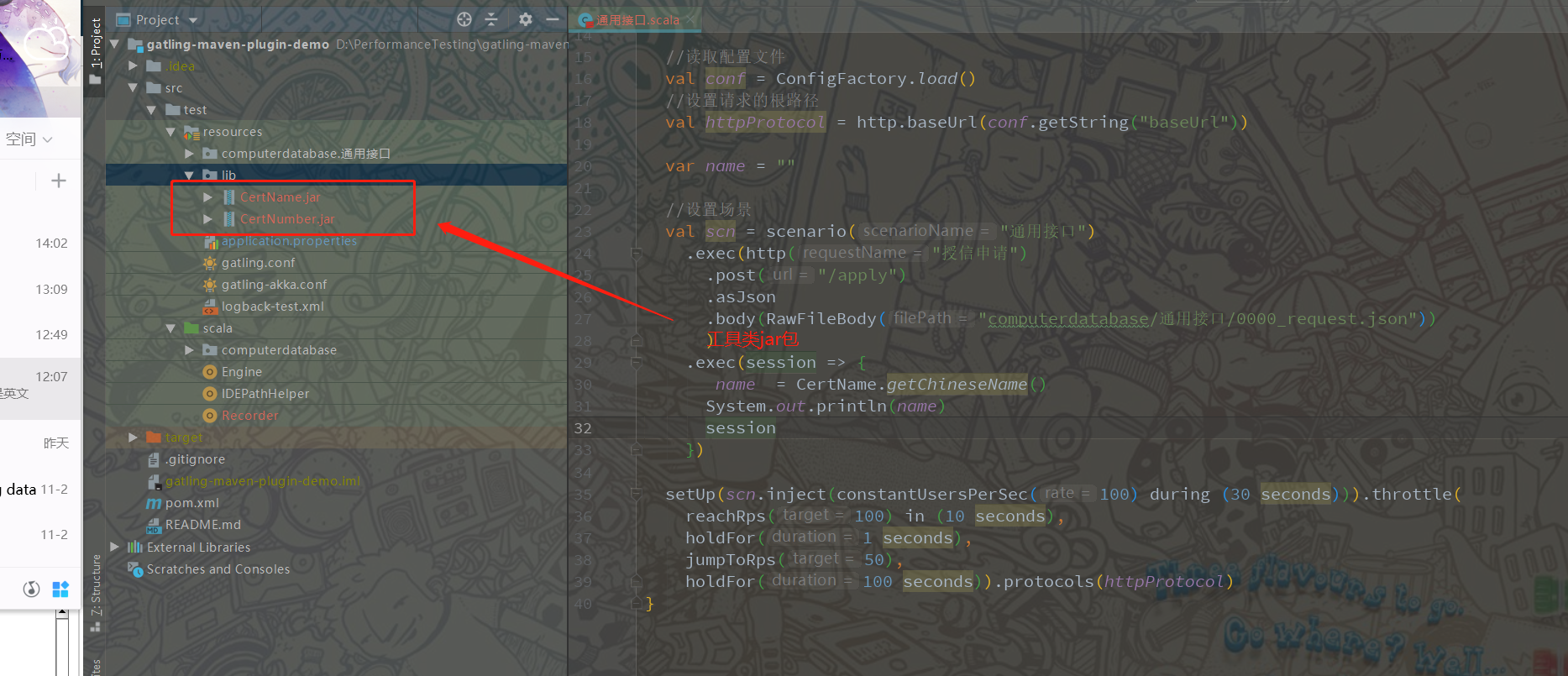
3、将jar包载入System Library库中
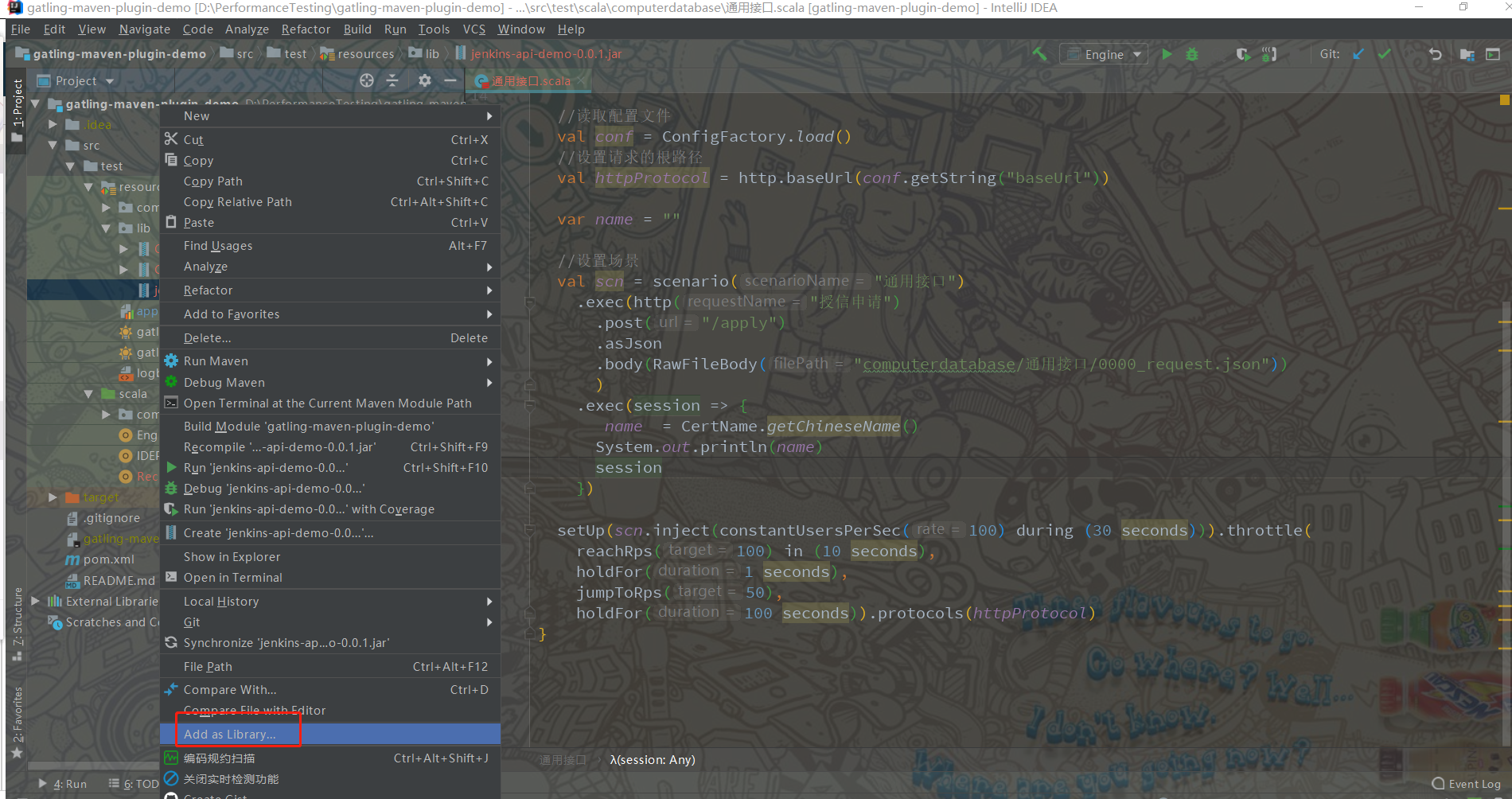
4、引入工具类
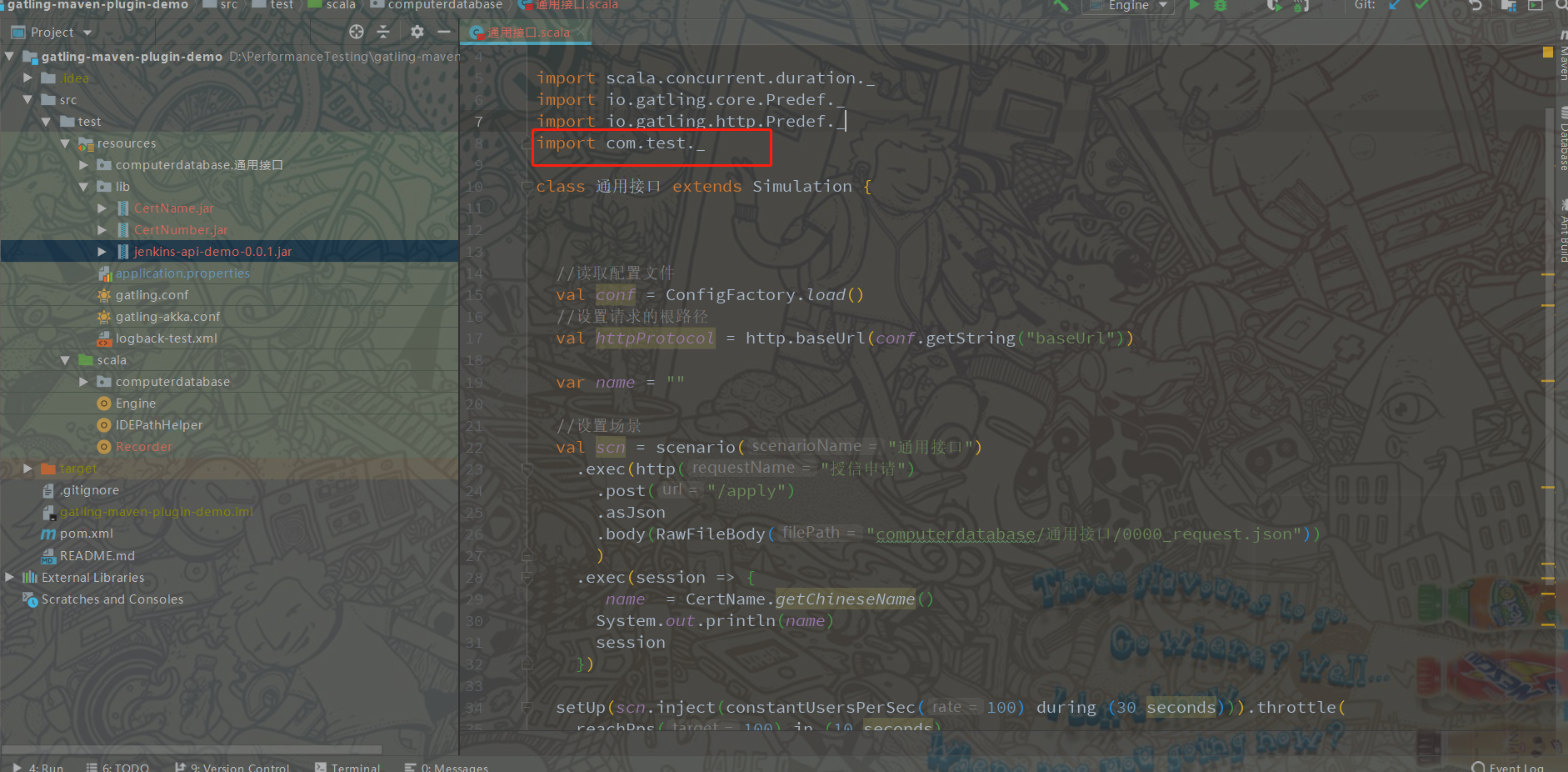
5、测试工具类 方法调用
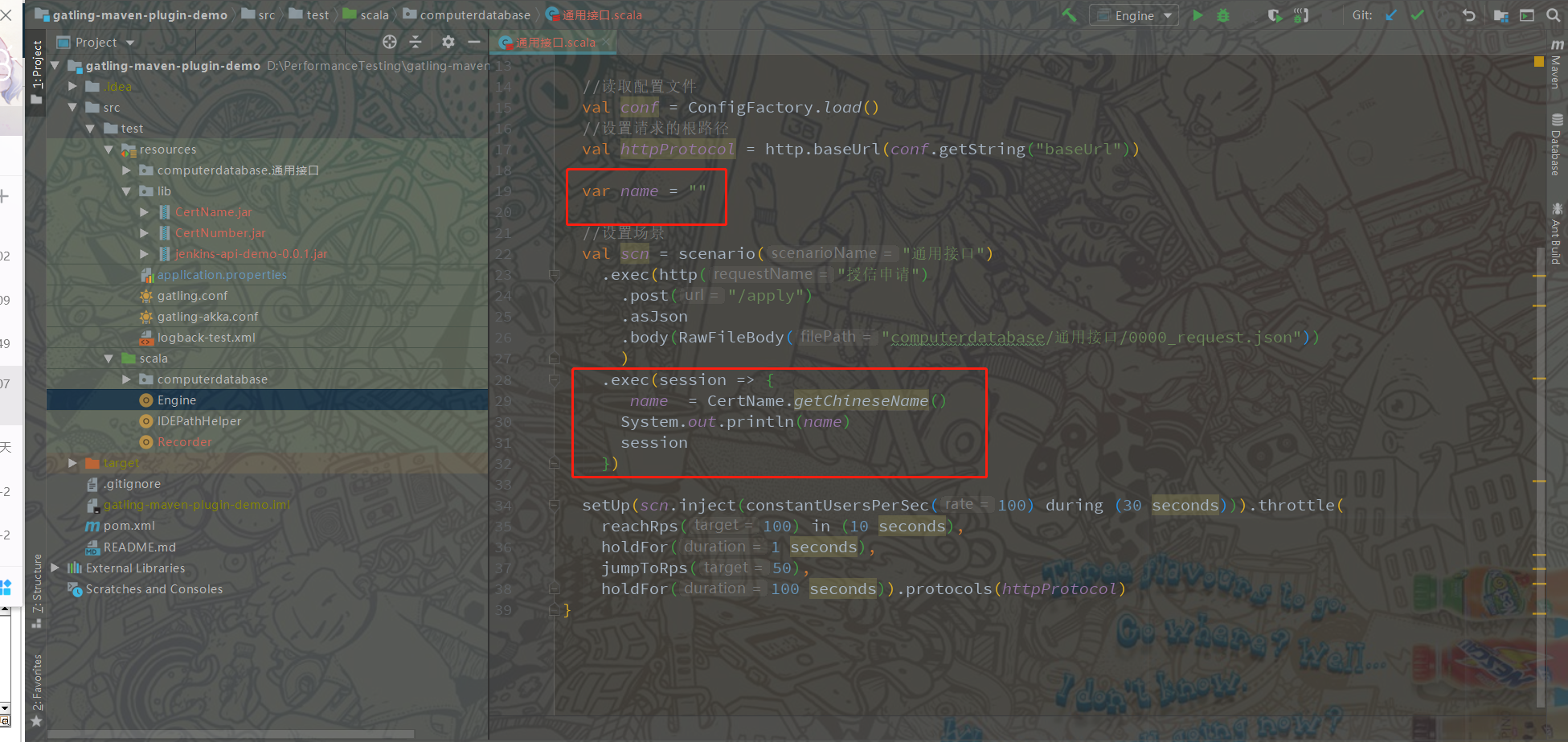
这里要注意的是Feeder这个函数,在加载参数的时候或者通过我这种方法,函数调用的外部jar包 都只会生效一次。因此要想灵活运用外部jar包工具类还需要在工程中再次加工,例如:我会调用jar包工具类一次性生成3000个数据,
然后在调用封装的方法即可。
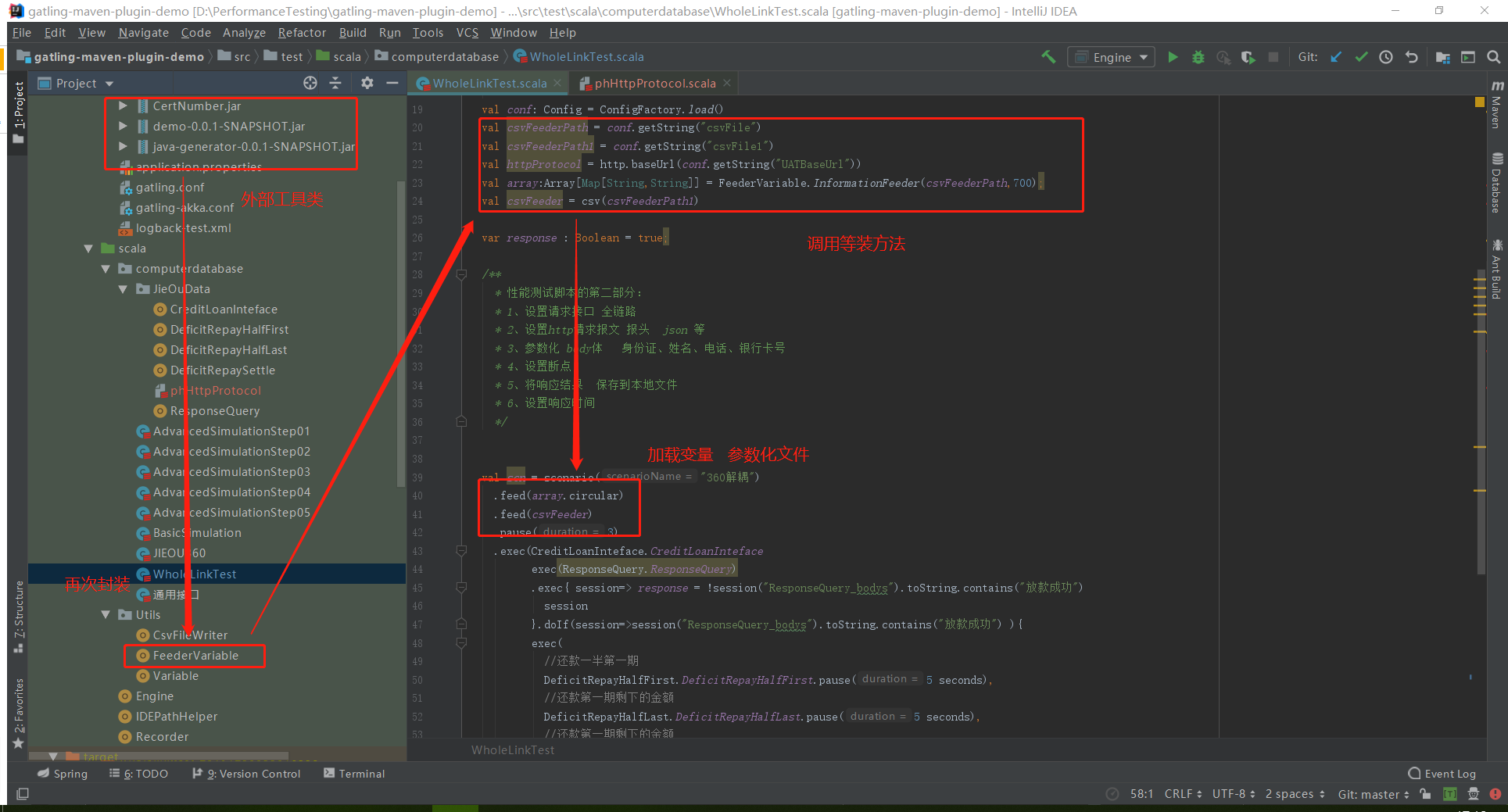
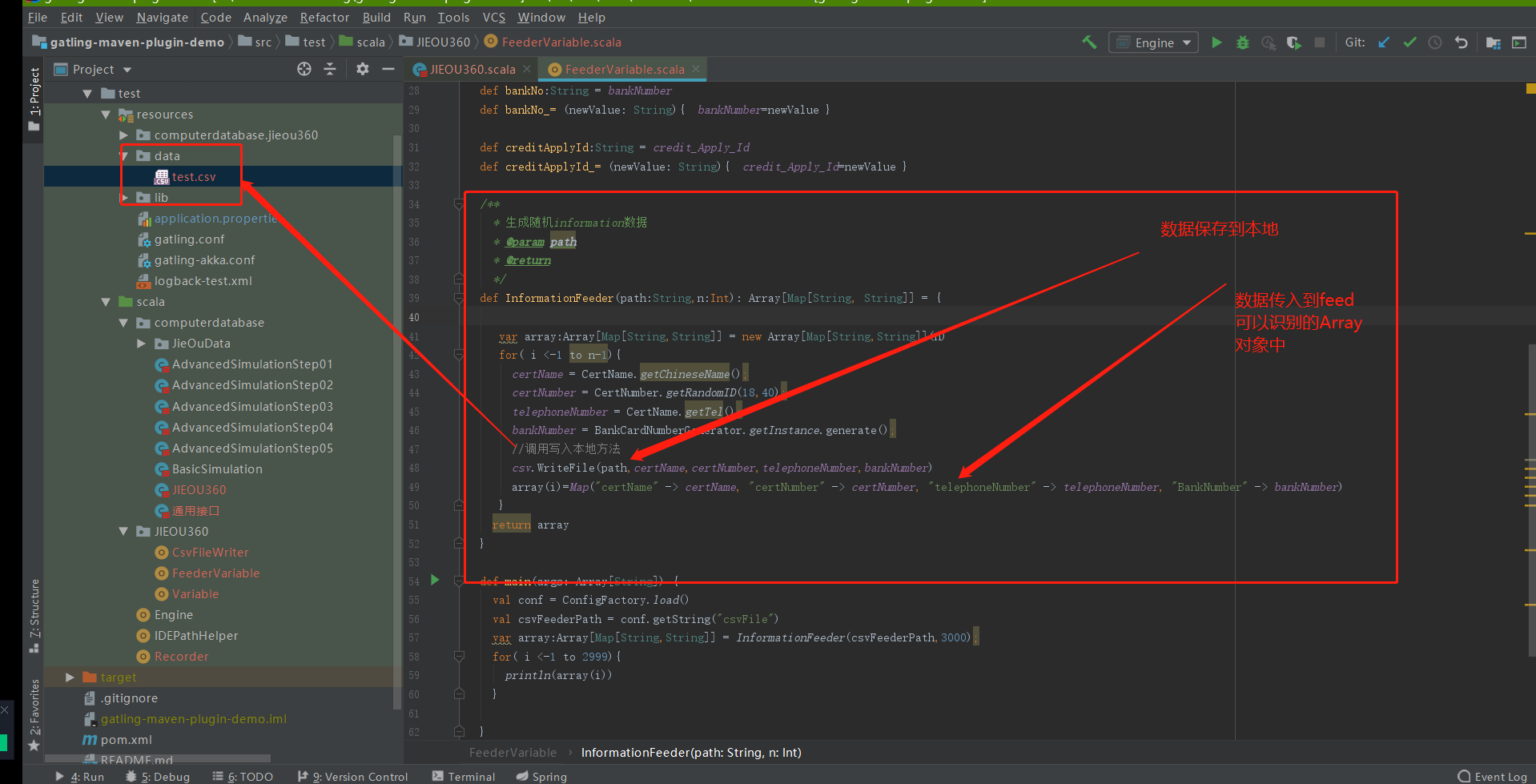
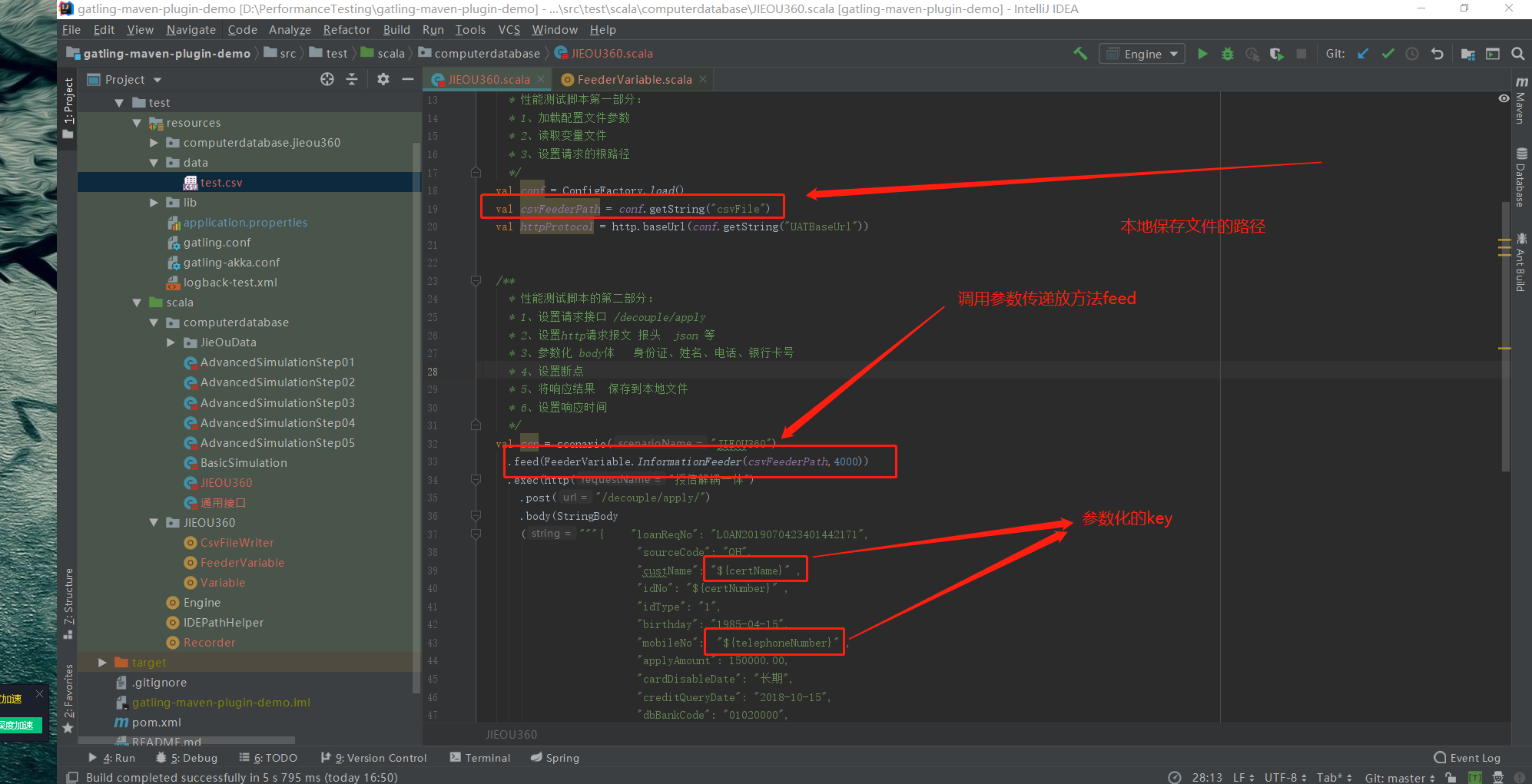
1、需要注意的是feed在整个请求过程中只加载一次传递参数的文件 也就是谁所有的传递的参数需要提前构造好 然后一次性加载到场景中
2、创建一个构造数据的脚本
实现两个功能:
随机生成的参数保存到本地
留作备用定位问题使用 随机生成的参数传递到Array中
Gatling脚本编写技巧篇(二)的更多相关文章
- Gatling脚本编写技巧篇(一)
一.公共类抽取 熟悉Gatling的同学都知道Gatling脚本的同学都知道,Gatling的脚本包含三大部分: http head配置 Scenario 执行细节 setUp 组装 那么针对三部分我 ...
- 《手把手教你》系列技巧篇(二十五)-java+ selenium自动化测试-FluentWait(详细教程)
1.简介 其实今天介绍也讲解的也是一种等待的方法,有些童鞋或者小伙伴们会问宏哥,这也是一种等待方法,为什么不在上一篇文章中竹筒倒豆子一股脑的全部说完,反而又在这里单独写了一篇.那是因为这个比较重要,所 ...
- 《手把手教你》系列技巧篇(二十七)-java+ selenium自动化测试- quit和close的区别(详解教程)
1.简介 尽管有的小伙伴或者童鞋们觉得很简单,不就是关闭退出浏览器,但是宏哥还是把两个方法的区别说一下,不然遇到坑后根本不会想到是这里的问题. 2.源码 本文介绍webdriver中关于浏览器退出操作 ...
- 《手把手教你》系列技巧篇(五十二)-java+ selenium自动化测试-处理面包屑(详细教程)
1.简介 面包屑(Breadcrumb),又称面包屑导航(BreadcrumbNavigation)这个概念来自童话故事"汉赛尔和格莱特",当汉赛尔和格莱特穿过森林时,不小心迷路了 ...
- BAT脚本编写教程简单入门篇
BAT脚本编写教程简单入门篇 批处理文件最常用的几个命令: echo表示显示此命令后的字符 echo on 表示在此语句后所有运行的命令都显示命令行本身 echo off 表示在此语句后所有运行的命 ...
- BAT脚本编写教程入门提高篇
BAT脚本编写教程入门提高篇 批处理文件的参数 批处理文件还可以像C语言的函数一样使用参数(相当于DOS命令的命令行参数),这需要用到一个参数表示符“%”. %[1-9]表示参数,参数是指在运行批处理 ...
- X86逆向15:OD脚本的编写技巧
本章节我们将学习OD脚本的使用与编写技巧,脚本有啥用呢?脚本的用处非常的大,比如我们要对按钮事件进行批量下断点,此时使用自动化脚本将大大减小我们的工作量,再比如有些比较简单的压缩壳需要脱壳,此时我们也 ...
- LoadRunner脚本编写之二
LoadRunner脚本编写之二 编程基本语法必须要记牢.程序的思想也很重要. 下面来回顾一下嵌套循环例子. Action() { int i,j; //生命两个变量 for ( ...
- 《手把手教你》系列技巧篇(二十三)-java+ selenium自动化测试-webdriver处理浏览器多窗口切换下卷(详细教程)
1.简介 上一篇讲解和分享了如何获取浏览器窗口的句柄,那么今天这一篇就是讲解获取后我们要做什么,就是利用获取的句柄进行浏览器窗口的切换来分别定位不同页面中的元素进行操作. 2.为什么要切换窗口? Se ...
随机推荐
- C# 基础知识系列- 4 面向对象
面向对象 面向对象是一个抽象的概念,其本质就是对事物以抽象的方式建立对应的模型. 简单来讲,比如我有一只钢笔,那么我就可以通过分析,可以得到 这只钢笔的材第是塑料,品牌是个杂牌 ,里面装的墨是黑色的, ...
- AQS机制
一,Lock接口 锁是用来控制多个线程访问共享资源的方式,一般来说,一个锁能够防止多个线程同时访问共享资源(但是有些锁可以允许多个线程并发的访问共享资源,比如读写锁).在Lock接口出现之前,Java ...
- NeurIPS审稿引发吐槽大会,落选者把荒唐意见怼了个遍:“我谢谢你们了”
七月份的尾巴,机器学习顶会NeurIPS 2019的初步结果已经来了. 一年一度的吐槽盛会也由此开始. "有评审问我啥是ResNet." "有评审问我为啥没引用X论文.我 ...
- iOS 内置图片瘦身
一.iOS 内置资源的集中方式 1.1 将图片存放在 bundle 这是一种很常见的方式,项目中各类文件分类放在各个 bundle 下,项目既整洁又能达到隔离资源的目的.采用 bundle 的加载方式 ...
- 模块 schedule 定时任务
schedule模块实现定时任务 2018-08-29 15:01:51 更多 一.官方示例 import schedule import time def job(): print("I' ...
- ICPC训练联盟周赛Preliminaries for Benelux Algorithm Programming Contest 2019
I题 求 a 数组平方的前缀和和求 a 数组后缀和,遍历一遍即可 AC代码 #include<iostream>#include<cmath>using namespace s ...
- WebView中Java与JavaScript的交互
原文首发于微信公众号:jzman-blog,欢迎关注交流! Android 开发过程中 WebView 的使用比较广泛,常用来加载网页,比如使用 WebView 加载新闻页面.使用 WebView 打 ...
- Material Design 组件之 CollapsingToolbarLayout
CollapsingToolbarLayout 主要用于实现一个可折叠的标题栏,一般作为 AppBarLayout 的子 View 来使用,下面总结一下 CollapsingToolbarLayout ...
- Java实现tif/tiff/bmp图片转换png图片
package org.analysisitem20181016.test; import java.io.File; import java.io.FileOutputStream; import ...
- 通过jsDelivr + github 搭建一个简易图床
应用场景: 在大型项目里需要很多图片时,不会直接把图片存储在项目文件夹里,也不推荐直接用数据库存储,而是用第三方存储,cdn,也可以自己搭个存储图片的服务器,等等方式,如果时自己练练手,做做博客,写写 ...