java读源码 之 map源码分析(HashMap,图解)一
开篇之前,先说几句题外话,写博客也一年多了,一直没找到一种好的输出方式,博客质量其实也不高,很多时候都是赶着写出来的 ,最近也思考了很多,以后的博客也会更注重质量,同时也尽量写的不那么生硬,能让大家在轻松的氛围中学习到知识才是最好的
,最近也思考了很多,以后的博客也会更注重质量,同时也尽量写的不那么生硬,能让大家在轻松的氛围中学习到知识才是最好的
好了,闲话不再多说,进入我们今天的主题,HashMap能说的东西太多了,不管是其数据接口,算法,还是单纯的源码分析,不过我们还是直接从源码入手,进而分析其数据结构及算法
通过本篇,你将了解以下问题:
1.HashMap的结构是什么?
2.HashMap的存储数据的逻辑是什么?
在分析之前,我们先要对HashMap的接口有一个大概的了解,这要可以帮我们更好的理解源码,然后通过源码的学习,我们又能对它所持有的数据接口有更深的理解,嗯?是不是很有道理?
HashMap实际上是一个散列表的数据结构,即数组和链表的结合体。这样的结构结合了链表在增删方面的高效和数组在寻址上的优势
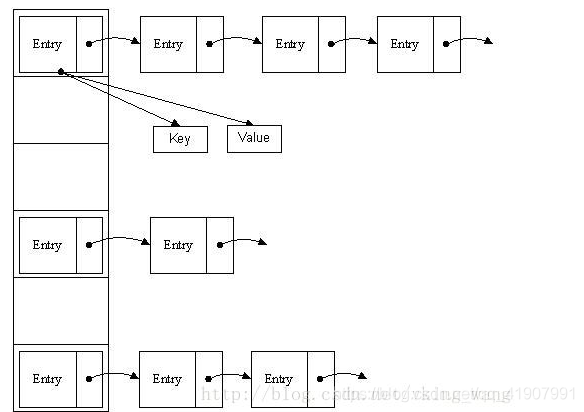
如上所示,当我们添加一个元素到HashMap中时,首先经过一定算法,计算出该元素应该放到数组中哪个位置,如果在该位置上已经有元素了,就将其链接到元素的尾部,这样就形成了一个链表的结构。
HashMap的源码体积比较大,如果还按之前我们分析其他容易那种方法的话,实在不知道从何写起,所以这篇文章,我们从实际的例子出发,一步步深入进去了解HashMap
public class HashMain {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("1", "java");
map.put("2", "c++");
map.put("3", "c#");
map.put("4", "python");
map.put("5", "php");
map.put("6", "js");
System.out.println(map);
}
}
我们打个断点看下:
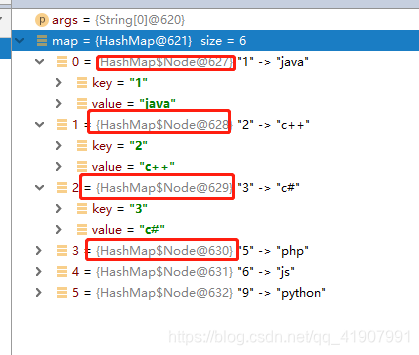
可以看到,HashMap中存储元素的是它的一个内部类Node,我们一起来看下这到底是个什么玩意儿?
static class Node<K,V> implements Map.Entry<K,V> {
// key对应的hash值
final int hash;
final K key;
V value;
// 通过next指针,保存了下个节点的元素,看到这个我们也能知道,
// 不同于LinkedList,这是个单向链表
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
// 通过键值的hash值进行异或操作得到这个Node的hashCode
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
// 必须要为 Map.Entry 且 key跟value都相等的时候才会返回true
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
我们可以看到Node接口实现, Map接口中的一个内部类Entry,我们继续看看Entry又是个什么东西呢?
interface Entry<K,V> {
/**
* 返回了这个Entry对应的key
*/
K getKey();
/**
* 返回对应的value
*/
V getValue();
/**
* 覆盖老的value值
*/
V setValue(V value);
boolean equals(Object o);
int hashCode();
/**
* 1.8新增的方法,返回一个采用自然排序比较key的比较器
*/
public static <K extends Comparable<? super K>, V> Comparator<Map.Entry<K,V>> comparingByKey() {
// 这个与操作代表了返回的这个比较器实现了Serializable接口,是可序列化的
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> c1.getKey().compareTo(c2.getKey());
}
/**
* 1.8新增的方法,返回一个采用自然排序比较value的比较器
*/
public static <K, V extends Comparable<? super V>> Comparator<Map.Entry<K,V>> comparingByValue() {
// 这个与操作代表了返回的这个比较器实现了Serializable接口,是可序列化的
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> c1.getValue().compareTo(c2.getValue());
}
/**
* 1.8新增的方法,返回一个采用给定比较器比较key的比较器
*/
public static <K, V> Comparator<Map.Entry<K, V>> comparingByKey(Comparator<? super K> cmp) {
Objects.requireNonNull(cmp);
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> cmp.compare(c1.getKey(), c2.getKey());
}
/**
* 1.8新增的方法,返回一个采用给定比较器比较value的比较器
*/
public static <K, V> Comparator<Map.Entry<K, V>> comparingByValue(Comparator<? super V> cmp) {
Objects.requireNonNull(cmp);
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> cmp.compare(c1.getValue(), c2.getValue());
}
}
分析完Node之后,我们可以知道,Node就是我们之前所说的数组+链表中的“链表”,并且它还是一个单向的链表。
OK,为了更好的理解其数据结构,我们现在来分析它存入数据的方法,也就是put方法,看看一次数据的存储到底经过了什么?
// 将KV键值对存入map中,如果map中已经包含了这个key,那么value会被替换
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* @param key的hash值
* @param key
* @param value
* @param onlyIfAbsent 如果为true的话,不去改变已经存在的value
* @param evict 在HashMap中这个值没什么用,我们分析LinkedHashMap时会用到它
* @return
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 如果HashMap中的table尚未初始化或者长度为0,则将其进行扩容到初始长度
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 如果计算出新增节点的将要放入的位置上还没有被占用,就直接创建一个新的节点放入
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
// 如果位置已经被占用,但将要放入的元素key跟原本的元素相等
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
// 之后会根据onlyIfAbsent进行判断,如果为false的话,会对原节点的value直接进行覆盖
e = p;
else if (p instanceof TreeNode)
// 如果是一个TreeNode,调用对应的方法,这个在之后的文章中再分析
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 说明是一个Node
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
// 链接到当前节点的尾部
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
// 如果长度过长,进行树化,这个在之后的文章分析,比较复杂
treeifyBin(tab, hash);
break;
}
// 在遍历过程中发现了跟已经存在的key相等的话,就直接break
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
// 如果onlyIfAbsent为false,或者旧值为null的话,进行替换
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
分析完后, 我们总结下它的逻辑:
- 对key的hashCode()做一次散列(hash函数,具体内容下一篇讲解),然后根据这个散列值计算index(i = (n - 1) & hash)这个表达式我们再ArrayDequeue中已经介绍过了,相当于模运算
- 如果没有发生碰撞(哈希冲突),则直接放到数组中;
- 如果碰撞了,以链表的形式挂在数组对应的元素后;
- 如果因为碰撞导致链表过长(大于等于TREEIFY_THRESHOLD),就把链表转换成红黑树;
- 如果节点已经存在就替换old value(保证key的唯一性)
- 如果数组中存储的元素达到了阈值(超过负载因子*当前容量),就要resize(重新调整大小并重新散列)。
接下来,我们来分析它的get方法
public V get(Object key) {
Node<K,V> e;
// 通过key的hash值找到对应的Node节点,如果没有的话返回null,存在的话返回node节点的value
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 如果table已经完成了初始化,并且经过散列后的位置上的元素不为null的话
if (first.hash == hash &&
((k = first.key) == key || (key != null && key.equals(k))))
// 正好key的值跟散列后数组上对应位置的节点的key相等,直接返回这个节点
return first;
if ((e = first.next) != null) {
// 如果是TreeNode,去树中查找
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
// 否则,遍历链接查找
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
我们也分析下获取元素时的逻辑:
- 根据传入key进行hash运算,将运算后的值跟数组长度进行模运算,得出这个key对应数组的位置
- 如果key的hash值正好等于数组上这个元素的key的hash值的话,直接返回数组上这个位置的元素
- 如果不相等,就在这个节点下挂的树或者链表中查询对应的key(有树或链表的情况下)
- 都不符合,返回null
这篇文章到这里就暂时结束啦~,HashMap比较难讲清楚,这篇文章也只是做一个开篇,能让大家对其大概有一个认设就是再好不过了,后续还会继续写HashMap,希望大家多多指教,动动小手点个赞啦
java读源码 之 map源码分析(HashMap,图解)一的更多相关文章
- Java 数据类型:集合接口Map:HashTable;HashMap;IdentityHashMap;LinkedHashMap;Properties类读取配置文件;SortedMap接口和TreeMap实现类:【线程安全的ConcurrentHashMap】
Map集合java.util.Map Map用于保存具有映射关系的数据,因此Map集合里保存着两个值,一个是用于保存Map里的key,另外一组值用于保存Map里的value.key和value都可以是 ...
- java读源码 之 map源码分析(HashMap)二
在上篇文章中,我已经向大家介绍了HashMap的一些基础结构,相信看过文章的同学们,应该对其有一个大致了了解了,这篇文章我们继续探究它的一些内部机制,包括构造函数,字段等等~ 字段分析: // 默 ...
- Java并发指南10:Java 读写锁 ReentrantReadWriteLock 源码分析
Java 读写锁 ReentrantReadWriteLock 源码分析 转自:https://www.javadoop.com/post/reentrant-read-write-lock#toc5 ...
- Java读源码之ReentrantLock
前言 ReentrantLock 可重入锁,应该是除了 synchronized 关键字外用的最多的线程同步手段了,虽然JVM维护者疯狂优化 synchronized 使其已经拥有了很好的性能.但 R ...
- Java读源码之ReentrantLock(2)
前言 本文是 ReentrantLock 源码的第二篇,第一篇主要介绍了公平锁非公平锁正常的加锁解锁流程,虽然表达能力有限不知道有没有讲清楚,本着不太监的原则,本文填补下第一篇中挖的坑. Java读源 ...
- Java读源码之CountDownLatch
前言 相信大家都挺熟悉 CountDownLatch 的,顾名思义就是一个栅栏,其主要作用是多线程环境下,让多个线程在栅栏门口等待,所有线程到齐后,栅栏打开程序继续执行. 案例 用一个最简单的案例引出 ...
- 源码分析— java读写锁ReentrantReadWriteLock
前言 今天看Jraft的时候发现了很多地方都用到了读写锁,所以心血来潮想要分析以下读写锁是怎么实现的. 先上一个doc里面的例子: class CachedData { Object data; vo ...
- 给jdk写注释系列之jdk1.6容器(6)-HashSet源码解析&Map迭代器
今天的主角是HashSet,Set是什么东东,当然也是一种java容器了. 现在再看到Hash心底里有没有会心一笑呢,这里不再赘述hash的概念原理等一大堆东西了(不懂得需要先回去看下Has ...
- 转:微信开发之使用java获取签名signature(贴源码,附工程)
微信开发之使用java获取签名signature(贴源码,附工程) 标签: 微信signature获取签名 2015-12-29 22:15 6954人阅读 评论(3) 收藏 举报 分类: 微信开发 ...
随机推荐
- 【Java】 Variable 变量
什么是Variable变量? - 变量是内存中的一个存储区域 - 这个存储区域内的数据允许在同一类型范围内不断变化 - 是程序最基本的存储单元,包含三个要素[变量类型][变量名][存储的值] 为什么需 ...
- codeforces Equalizing by Division (easy version)
output standard output The only difference between easy and hard versions is the number of elements ...
- python爬虫面试题集锦及答案
1.爬取数据后使用哪个数据库存储数据的,为什么? - 2.你用过的爬虫框架或者模块有哪些?优缺点? - 3.写爬虫是用多进程好?还是多线程好? - 4.常见的反爬虫和应对方法? - 5.需要登录的网页 ...
- 立体匹配-----NCC视差匹配
目录 一.立体匹配算法 1.立体匹配算法分类 二.NCC 视差匹配方法 1.原理 2.NCC计算公式 3.算法流程 4.代码实现 5.不同场景运行 三.结论 四.遇到的问题及解决方法 一.立体 ...
- Java 多线程 -- 指令重排(HappenBefore)
指令重排是指:代码执行顺序和预期不一致. 代码运行一般步骤为: 1.从内存中获取指令解码 2.计算值 3.执行代码操作 4.把结果写回内存 而写回内存的操作比较耗时,CPU为了性能,可能不会等它完成, ...
- Python(4)
lst = [1,2,4,8,16,32,64,128,256,512,1024,32769,65536,4294967296] # 输出 { 1:[1,2,3,8], 2:[16,32,64], 3 ...
- docker-数据管理(3)
Docker 容器中管理数据主要有两种方式: 数据卷(Data volumes) 数据卷容器(Data volumes containers 数据卷是一个可供一个或者多个容器使用的特殊目录,它绕过UF ...
- Cannot find or open the PDB file
打开VS:工具 --> 选项 --> 调试-->符号接下来就是选择Microsoft,然后确认
- Linux中的常用符号
>, 1> 输出重定向符stdout,代码为1,重定向内容到文件,清除已有的内容,然后加入新内容,如果文件不存在还会创建文件 >>, 1>> 追加输出重 ...
- mac OS nvm 常用命令
nvm install stable ## 安装最新稳定版 node,当前是node v10.15.0 (npm v6.4.1) nvm install <version> ## 安装指定 ...