HDFS NameNode详解
1. namenode介绍
namenode管理文件系统的命名空间。它维护着文件系统树及整棵树内所有的文件和目录。这些信息以两个文件形式永久保存在本地磁盘上:命名空间镜像文件fsimage和编辑日志文件edits。NameNode也记录着每个文件中各个块所在的数据节点信息,但它并不永久保存块的位置信息,因为这些信息在系统启动时由数据节点重建。
namenode主要负责三个功能,分别是
管理元数据
维护目录树
响应客户请求
2. namenode关键文件夹
位于/opt/software/hadoop277/tmp/dfs/name/current目录中
(初次启动之前需要对namenode目录格式化:hadoop namenode -format)
seen_txid文件保存的是一个数字,就是最后一个edits_的数字
fsimage文件:HDFS文件系统元数据的一个永久性的检查点,其中包含HDFS文件系统的所有目录和文件idnode的序列化信息
edits文件:存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到edits文件中
version: 该文件为namenode中一些版本号的信息
3. 元数据
3.1元数据格式
/jdk/jdk18.zip, 3, {blk_1,blk_2}, [{blk_1:[dd1,dd2,dd4]}, {blk_2:[dd0,dd1,dd3]}]
/jdk/jdk18.zip:这个文件在hdfs文件系统中的路径
3:这个文件的副本数(hdfs-site.xml可修改)
{blk_1,blk_2}:这个文件分成的块(默认满128M分成一个块)
dd0,dd1...:datanode节点,比如blk_1的3个副本分别存储在dd1,dd2,dd4中
3.2元数据的合并
3.2.1原因
1、随着集群的运行,edit logs文件逐步增大,管理该文件需要消耗资源
2、Namenode合并fsimage文件需要消耗资源
3、Namenode宕机后,再次恢复时会丢失一部分操作
2.2.2解决办法
使用secondarynamenode对元数据进行合并
2.2.3触发条件(其中之一即可)
到达检查点周期,默认1个小时。可通过 dfs.namenode.checkpoint.period属性手动配置。
一分钟检查一次操作次数,到达设置事务数量,默认一百万条。可通过dfs.namenode.checkpoint.txns属性配置
2.2.3合并过程
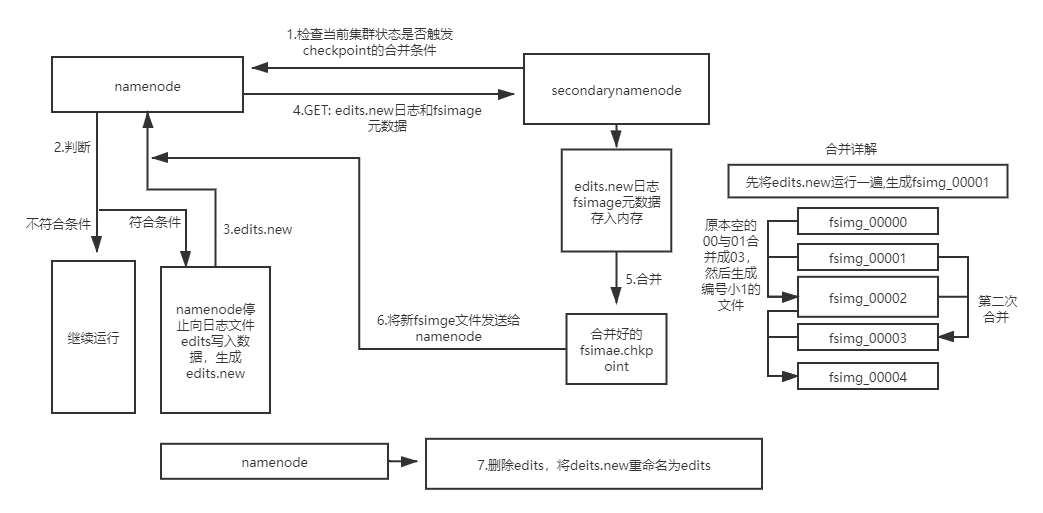
1、secondarynamenode检查当前集群状态是否触发checkpoint的合并条件
2、若未触发则继续运行,否则开始元数据合并
3、namenode停止向日志文件edits写入数据,并生成一个新的edits文件用于存储在合并期间产生的操作
4、secondarynamenode通过Http GET方式从namenode处下载edits文件和fsimage文件,并将fsimage文件载入内存
5、secondarynamenode逐条执行edits文件的更新操作,使内存中的fsimage文件保存最新的操作日志,结束后生成一个新fsimaget文件
6、secondarynamenode复制发送新fsimaget文件给namenode,然后删除edits.new
7、两个新文件替换前两个旧文件,等待下一次合并
HDFS NameNode详解的更多相关文章
- hadoop hdfs uri详解
body{ font-family: "Microsoft YaHei UI","Microsoft YaHei",SimSun,"Segoe UI& ...
- hadoop之hdfs命令详解
本篇主要对hadoop命令和hdfs命令进行阐述,yarn命令会在之后的文章中体现 hadoop fs命令可以用于其他文件系统,不止是hdfs文件系统内,也就是说该命令的使用范围更广可以用于HDFS. ...
- hadoop之hdfs架构详解
本文主要从两个方面对hdfs进行阐述,第一就是hdfs的整个架构以及组成,第二就是hdfs文件的读写流程. 一.HDFS概述 标题中提到hdfs(Hadoop Distribute File Syst ...
- HDFS架构详解-非官档
Namenode 1.namenode是一个中心服务器,单一节点(简化系统的设计和实现),负责管理文件系统的命名空间(namespace)以及客户端对文件的访问. 2.文件操作:namenode负责对 ...
- flume hdfs配置详解
flume采集中HDFS参数解析 就是个备忘录,方便以后直接查阅,不用再网上找了!!!! 配置解析 Flume中的HDFS Sink应该是非常常用的,其中的配置参数也比较多,在这里记录备忘一下. ch ...
- kettle连接hadoop&hdfs图文详解
1 引言: 项目最近要引入大数据技术,使用其处理加工日上网话单数据,需要kettle把源系统的文本数据load到hadoop环境中 2 准备工作: 1 首先 要了解支持hadoop的Kettle版本情 ...
- HDFS入门详解
一. 前提和设计目标 1. 硬件错误是常态,因此需要冗余,这是深入到HDFS骨头里面去了 HDFS可能由成百上千的服务器所构成,每个服务器上存储着文件系统的部分数据.我们面对的现实是构成系统的组件数目 ...
- Hadoop分布式文件系统(HDFS)详解
HDFS简介: 当数据集的大小超过一台独立物理计算机的存储能力时,就有必要对它进行分区 (partition)并存储到若干台单独的计算机上.管理网络中跨多台计算机存储的文件系统成为分布式文件系统 (D ...
- hadoop1中hdfs原理详解
HDFS是Hadoop Distribute File System的简称,也是Hadoop的一个分布四文件系统 一.HDFS的主要设计理念 1.存储超大文件 这里的 “超大文件” 是指几百MB .G ...
随机推荐
- [LC] 32. Longest Valid Parentheses
Given a string containing just the characters '(' and ')', find the length of the longest valid (wel ...
- Mac使用sublime text3的快捷键
符号说明⌘:command⌃:control⌥:option⇧:shift↩:enter⌫:delete 打开/关闭/前往⌘⇧N 打开一个新的sublime窗口⌘N 新建文件⌘⇧W 关闭sublime ...
- MOOC(3)- python发送请求,返回的json数据被转码
https://www.cnblogs.com/yoyoketang/p/10339210.html 问题:发送post请求,对post请求返回的json数据格式化,但是返回的结果被转码了 json. ...
- 写个匹配某段html dom代码某属性的正则匹配方法
private static string GetHtmlDomAttr(string html, string id, string attrname) { string xmatchstring ...
- LG_2051_[AHOI2009]中国象棋
题目描述 这次小可可想解决的难题和中国象棋有关,在一个N行M列的棋盘上,让你放若干个炮(可以是0个),使得没有一个炮可以攻击到另一个炮,请问有多少种放置方法.大家肯定很清楚,在中国象棋中炮的行走方式是 ...
- 吴裕雄--天生自然 R语言开发学习:回归(续一)
#------------------------------------------------------------# # R in Action (2nd ed): Chapter 8 # # ...
- JDK1.8新特性Lambda表达式
/** * Lambda * @date 2019/8/2 10:03 */ public class Lamda { public static void main(String[] args){ ...
- RocketMQ borker配置文件
master节点:serverSelectorThreads = 3 brokerRole = SYNC_MASTER serverSocketRcvBufSize = 131072 osPageCa ...
- android应用程序源码结构分析
工程; 1. src文件夹存放源码. 2. gen下有跟src中一样的包文件,内部有一个名为R.java类,它是自动生成的一个类:该目录不用我们开发人员维护, 但又非常重要的目录 . 该目录用来存放由 ...
- Java编程Tips
原文: Java编程中"为了性能"尽量要做到的一些地方 作者: javatgo 最近的机器内存又爆满了,除了新增机器内存外,还应该好好review一下我们的代码,有很多代码编写过于 ...