mybatis源码学习:从SqlSessionFactory到代理对象的生成
一、根据XML配置文件构建SqlSessionFactory
一、首先读取类路径下的配置文件,获取其字节输入流。
二、创建SqlSessionFactoryBuilder对象,调用内部的build方法。factory = new SqlSessionFactoryBuilder().build(in);
三、根据字节输入流创建XMLConfigBuilder即解析器对象parser。XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);
public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties) {
try {
//根据字节输入流创建XMLConfigBuilder即解析器对象parser
XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);
//返回的Configuration配置对象作为build的参数
return build(parser.parse());
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error building SqlSession.", e);
} finally {
ErrorContext.instance().reset();
try {
inputStream.close();
} catch (IOException e) {
// Intentionally ignore. Prefer previous error.
}
}
}
四、调用parser对象的parse方法,parser.parse(),该结果将返回一个Configuration配置对象,作为build方法的参数。
五、parse()方法中,调用parseConfiguration方法将Configuration元素下的所有配置信息封装进Parser对象的成员Configuration对象之中。
public Configuration parse() {
if (parsed) {
throw new BuilderException("Each XMLConfigBuilder can only be used once.");
}
parsed = true;
//将configuration的配置信息一一封装到configuration中
parseConfiguration(parser.evalNode("/configuration"));
return configuration;
}
六、其中进行解析xml元素的方式是将通过evalNode方法获取对应名称的节点信息。如:parseConfiguration(parser.evalNode("/configuration"));,此时parser.evalNode("/configuration")即为Configuration下的所有信息。
七、parseConfiguration方法相当于将里面每个元素的信息都单独封装到Configuration中。
值得一提的是,我们之后要分析基于代理模式产生dao的代理对象涉及到mappers的封装,其实也在配置文件读取封装的时候就已经完成,也就是在parseConfiguration方法之中:mapperElement(root.evalNode("mappers"));。他的作用就是,读取我们主配置文件中<mappers>的元素内容,也就是我们配置的映射配置文件。
<!-- 配置映射文件的位置 -->
<mappers>
<package name="com.smday.dao"></package>
</mappers>
private void mapperElement(XNode parent)方法将mappers配置下的信息获取,此处获取我们resources包下的com.smday.dao包名。

接着就调用了configuration的addMappers方法,其实还是调用的是mapperRegistry。
public void addMappers(String packageName) {
mapperRegistry.addMappers(packageName);
}
读到这里,我们就会渐渐了解MapperRegistry这个类的职责所在,接着来看,这个类中进行的一些工作,在每次添加mappers的时候,会利用ResolverUtil类查找类路径下的该包名路径下,是否有满足条件的类,如果有的话,就将Class对象添加进去,否则报错。
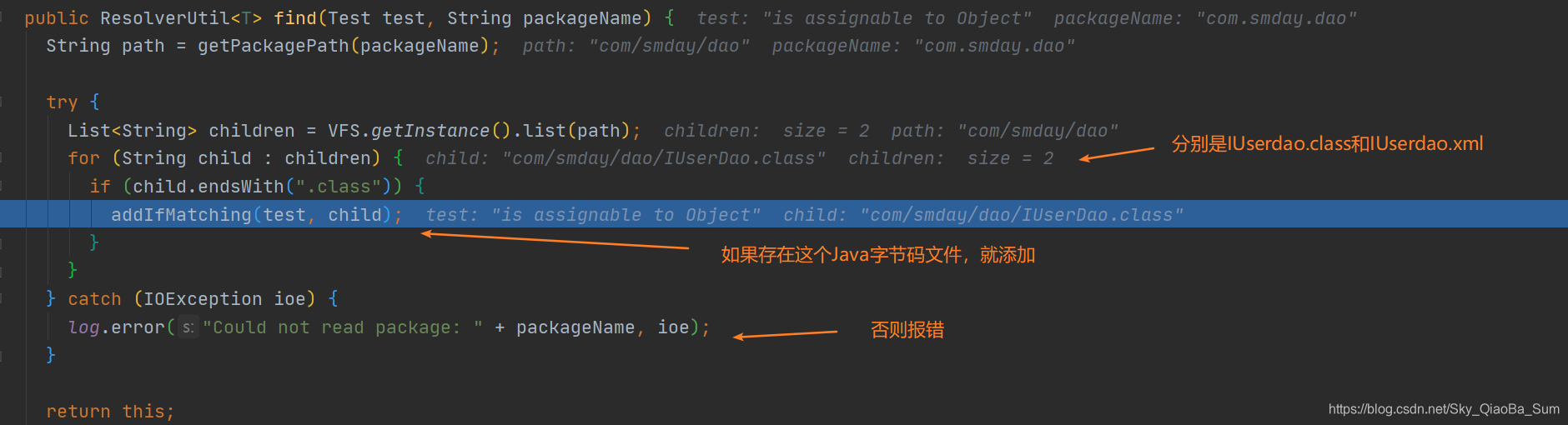
紧接着,就到了一步比较重要的部分,当然只是我个人觉得,因为第一遍看的时候,我没有想到,这步居然可以封装许许多多的重要信息,我们来看一看:
public <T> void addMapper(Class<T> type) {
if (type.isInterface()) {
//如果已经绑定,则抛出异常
if (hasMapper(type)) {
throw new BindingException("Type " + type + " is already known to the MapperRegistry.");
}
boolean loadCompleted = false;
try {
//将接口类作为键,将MapperProxyFactory作为值存入
knownMappers.put(type, new MapperProxyFactory<T>(type));
// 在运行解析器之前添加类型十分重要,否则可能会自动尝试绑定映射器解析器
// 如果类型已知,则不会尝试
MapperAnnotationBuilder parser = new MapperAnnotationBuilder(config, type);
//解析mapper映射文件,封装信息
parser.parse();
loadCompleted = true;
} finally {
if (!loadCompleted) {
knownMappers.remove(type);
}
}
}
}
映射配置文件的读取依靠namespace,我们可以通过查看源码发现读取映射配置文件的方法是loadXmlResouce(),所以namespace命名空间至关重要:
private void loadXmlResource() {
// Spring may not know the real resource name so we check a flag
// to prevent loading again a resource twice
// this flag is set at XMLMapperBuilder#bindMapperForNamespace
// 防止加载两次,可以发现这句 判断在许多加载资源文件的时候出现
if (!configuration.isResourceLoaded("namespace:" + type.getName())) {
String xmlResource = type.getName().replace('.', '/') + ".xml";
InputStream inputStream = null;
try {
inputStream = Resources.getResourceAsStream(type.getClassLoader(), xmlResource);
} catch (IOException e) {
// ignore, resource is not required
}
if (inputStream != null) {
XMLMapperBuilder xmlParser = new XMLMapperBuilder(inputStream, assistant.getConfiguration(), xmlResource, configuration.getSqlFragments(), type.getName());
//最终解析
xmlParser.parse();
}
}
}
//xmlPaser.parse()
public void parse() {
if (!configuration.isResourceLoaded(resource)) {
//读取映射配置文件信息的主要代码
configurationElement(parser.evalNode("/mapper"));
//加载完成将该路径设置进去,防止再次加载
configuration.addLoadedResource(resource);
bindMapperForNamespace();
}
parsePendingResultMaps();
parsePendingCacheRefs();
parsePendingStatements();
}
可以看到,对映射文件解析之后,mappedStatements对象中出现了以下内容:

至此,主配置文件和映射配置文件的配置信息就已经读取完毕。
八、最后依据获得的Configuration对象,创建一个new DefaultSqlSessionFactory(config)。
public SqlSessionFactory build(Configuration config) {
return new DefaultSqlSessionFactory(config);
}
总结:
解析配置文件的信息,并保存在Configuration对象中。
返回包含Configuration的DefaultSqlSession对象。
二、通过SqlSessionFactory创建SqlSession
一、调用SqlSessionFactory对象的openSession方法,其实是调用private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit)方法,通过参数就可以知道,分别是执行器的类型,事务隔离级别和设置是否自动提交,因此,我们就可以得知,我们在创建SqlSession的时候可以指定这些属性。
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
//获取Environment信息
final Environment environment = configuration.getEnvironment();
//获取TransactionFactory信息
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
//创建Transaction对象
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
//创建执行器对象Executor
final Executor executor = configuration.newExecutor(tx, execType);
//创建DefaultSqlSession对象并返回
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
二、从configuration中获取environment、dataSource和transactionFactory信息,创建事务对象Transaction。
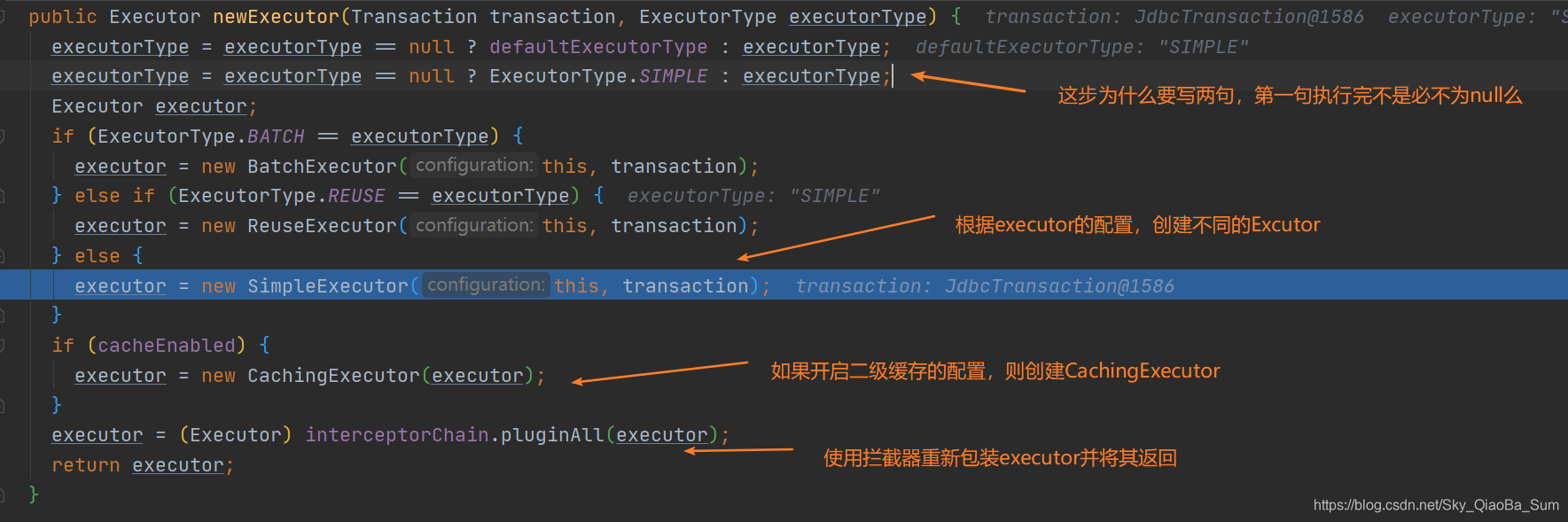
补充:后续看了一些博客,说是保证executor不为空,因为defaultExecutorType有可能为空。
三、根据配置信息,执行器信息和自动提交信息创建DefaultSqlSession。
三、getMapper获取动态代理对象
下面这句话意思非常明了,就是通过传入接口类型对象,获取接口代理对象。
IUserDao userDao1 = sqlSession1.getMapper(IUserDao.class);
具体的过程如下:
一、首先,调用SqlSession的实现类DefaultSqlSession的getMapper方法,其实是在该方法内调用configuration的getMapper方法,将接口类对象以及当前sqlsession对象传入。
//DefaultSqlSession.java
@Override
public <T> T getMapper(Class<T> type) {
//调用configuration的getMapper
return configuration.<T>getMapper(type, this);
}
二、接着调用我们熟悉的mapperRegistry,因为我们知道,在读取配置文件,创建sqlSession的时候,接口类型信息就已经被存入到其内部维护的Map之中。
//Configuration.java
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
return mapperRegistry.getMapper(type, sqlSession);
}

三、我们来看看getMapper方法具体的实现如何:
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
//根据传入的类型获取对应的键,也就是这个代理工厂
final MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory<T>) knownMappers.get(type);
if (mapperProxyFactory == null) {
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
}
try {
//最终返回的是代理工厂产生的一个实例对象
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception e) {
throw new BindingException("Error getting mapper instance. Cause: " + e, e);
}
}
四、紧接着,我们进入MapperProxyFactory,真真实实地发现了创建代理对象的过程。
protected T newInstance(MapperProxy<T> mapperProxy) {
//创建MapperProxy代理对象
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);
}
public T newInstance(SqlSession sqlSession) {
//MapperProxy是代理类,
final MapperProxy<T> mapperProxy = new MapperProxy<T>(sqlSession, mapperInterface, methodCache);
return newInstance(mapperProxy);
}

mybatis源码学习:从SqlSessionFactory到代理对象的生成的更多相关文章
- mybatis源码分析(四)---------------代理对象的生成
在mybatis两种开发方式这边文章中,我们提到了Mapper动态代理开发这种方式,现在抛出一个问题:通过sqlSession.getMapper(XXXMapper.class)来获取代理对象的过程 ...
- mybatis源码学习:基于动态代理实现查询全过程
前文传送门: mybatis源码学习:从SqlSessionFactory到代理对象的生成 mybatis源码学习:一级缓存和二级缓存分析 下面这条语句,将会调用代理对象的方法,并执行查询过程,我们一 ...
- myBatis源码学习之SqlSessionFactory
上一篇博客 SqlSessionFactoryBuilder 中介绍了它的作用就是获得DefaultSqlSessionFactory SqlSessionFactory是一个接口,其具体实现类是De ...
- mybatis源码学习:插件定义+执行流程责任链
目录 一.自定义插件流程 二.测试插件 三.源码分析 1.inteceptor在Configuration中的注册 2.基于责任链的设计模式 3.基于动态代理的plugin 4.拦截方法的interc ...
- mybatis源码学习(一) 原生mybatis源码学习
最近这一周,主要在学习mybatis相关的源码,所以记录一下吧,算是一点学习心得 个人觉得,mybatis的源码,大致可以分为两部分,一是原生的mybatis,二是和spring整合之后的mybati ...
- mybatis源码学习:一级缓存和二级缓存分析
目录 零.一级缓存和二级缓存的流程 一级缓存总结 二级缓存总结 一.缓存接口Cache及其实现类 二.cache标签解析源码 三.CacheKey缓存项的key 四.二级缓存TransactionCa ...
- Mybatis源码学习第六天(核心流程分析)之Executor分析
今Executor这个类,Mybatis虽然表面是SqlSession做的增删改查,其实底层统一调用的是Executor这个接口 在这里贴一下Mybatis查询体系结构图 Executor组件分析 E ...
- Mybatis源码学习之整体架构(一)
简述 关于ORM的定义,我们引用了一下百度百科给出的定义,总体来说ORM就是提供给开发人员API,方便操作关系型数据库的,封装了对数据库操作的过程,同时提供对象与数据之间的映射功能,解放了开发人员对访 ...
- mybatis源码分析(1)——SqlSessionFactory实例的产生过程
在使用mybatis框架时,第一步就需要产生SqlSessionFactory类的实例(相当于是产生连接池),通过调用SqlSessionFactoryBuilder类的实例的build方法来完成.下 ...
- Spring mybatis源码学习指引目录
前言: 分析了很多方面的mybatis的源码以及与spring结合的源码,但是难免出现错综的现象,为了使源码陶冶更为有序化.清晰化,特作此随笔归纳下分析过的内容.博主也为mybatis官方提供过pul ...
随机推荐
- 更新statsmodels出现的一系列问题
在statsmodels的开发12版本文档上正好看到使用三因子模型进行rolling regression,但是代码来自最新版本,而我的是老版本,运行下列代码会出现这个问题: No module na ...
- WePY的开发环境的安装
2020-03-24 1.安装Node.js 官网:https://nodejs.org/ 两个版本 LTS为稳定的长期支持版本 Current为最新的版本 安装完毕后,cmd下输入 node -v ...
- Ubuntu系统在Anaconda中安装Python3.6的虚拟环境
原因:Anaconda的python版本是3.7的,TensorFlow尚不支持此版本,于是我们创建一个Python的虚拟环境以支持TensorFlow 创建tf环境 conda create --n ...
- Vertica的这些事(三)——Vertica中实现Oracle中的ws_concat功能
vertica中没有类似Oracle中的ws_concat函数功能,需要开发UDF,自己对C++不熟悉,所有只有想其他方法解决了. 上代码: SELECT node_state, MAX(DECODE ...
- linux下使用笔记本的相关设置
目录 无线连接 Wi-Fi 蓝牙 触摸板 电源管理 电源管理工具 电源相关行为的响应动作 按键和盖子的响应动作 电池低电量的响应动作 处理器调整 调频工具 关闭睿频 intel_pstate 休眠配置 ...
- 用Fiddler抓取手机APP数据包
Fiddler下载地址 1.允许远程连接 2.允许监听https 3.重启Fiddler 这步很重要,不要忘了 4.手机配置 用ipconfig命令查询当前PC的局域网IP 将手机连接上同一个WIFI ...
- Windows命令help的基本使用
- Nginx 是如何处理 HTTP 头部的?
Nginx 处理 HTTP 头部的过程 Nginx 在处理 HTTP 请求之前,首先需要 Nginx 的框架先和客户端建立好连接,然后接收用户发来的 HTTP 的请求行,比如方法.URL 等,然后接收 ...
- ERC20代币(ETH)空投工具-创建代币
代币空投工具地址:http://tool.ethhelp.cn 适用币种: ETH和ERC20代币 使用建议: ERC代币空投,直投,ETH批量转小号 优势介绍: 1.可节省30%手续费 2.转几千地 ...
- MTK Android Driver :Key
MTK Android Driver :Key 1.按键配置(根据原理图):DCT(Driver Customization Tool): ..\mediatek\custom\prj\kernel\ ...