入门大数据---Spark开发环境搭建
一、安装Spark
1.1 下载并解压
官方下载地址:http://spark.apache.org/downloads.html ,选择 Spark 版本和对应的 Hadoop 版本后再下载:
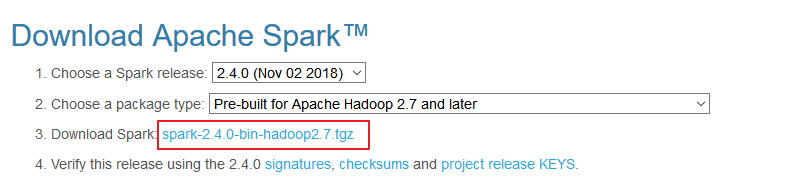
解压安装包:
# tar -zxvf spark-2.2.3-bin-hadoop2.6.tgz
1.2 配置环境变量
# vim /etc/profile
添加环境变量:
export SPARK_HOME=/usr/app/spark-2.2.3-bin-hadoop2.6
export PATH=${SPARK_HOME}/bin:$PATH
使得配置的环境变量立即生效:
# source /etc/profile
1.3 Local模式
Local 模式是最简单的一种运行方式,它采用单节点多线程方式运行,不用部署,开箱即用,适合日常测试开发。
# 启动spark-shell
spark-shell --master local[2]
- local:只启动一个工作线程;
- local[k]:启动 k 个工作线程;
- local[*]:启动跟 cpu 数目相同的工作线程数。
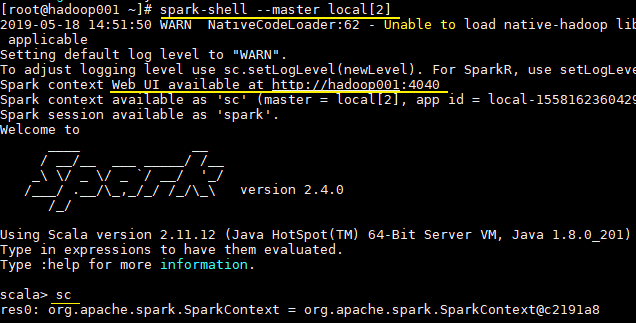
进入 spark-shell 后,程序已经自动创建好了上下文 SparkContext,等效于执行了下面的 Scala 代码:
val conf = new SparkConf().setAppName("Spark shell").setMaster("local[2]")
val sc = new SparkContext(conf)
二、词频统计案例
安装完成后可以先做一个简单的词频统计例子,感受 spark 的魅力。准备一个词频统计的文件样本 wc.txt,内容如下:
hadoop,spark,hadoop
spark,flink,flink,spark
hadoop,hadoop
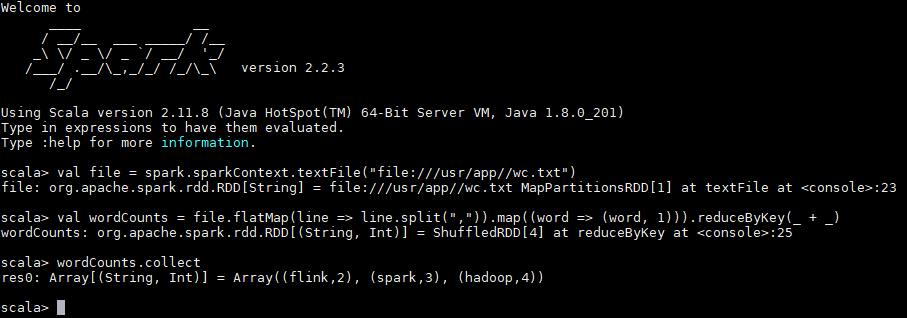
在 scala 交互式命令行中执行如下 Scala 语句:
val file = spark.sparkContext.textFile("file:///usr/app/wc.txt")
val wordCounts = file.flatMap(line => line.split(",")).map((word => (word, 1))).reduceByKey(_ + _)
wordCounts.collect
执行过程如下,可以看到已经输出了词频统计的结果:
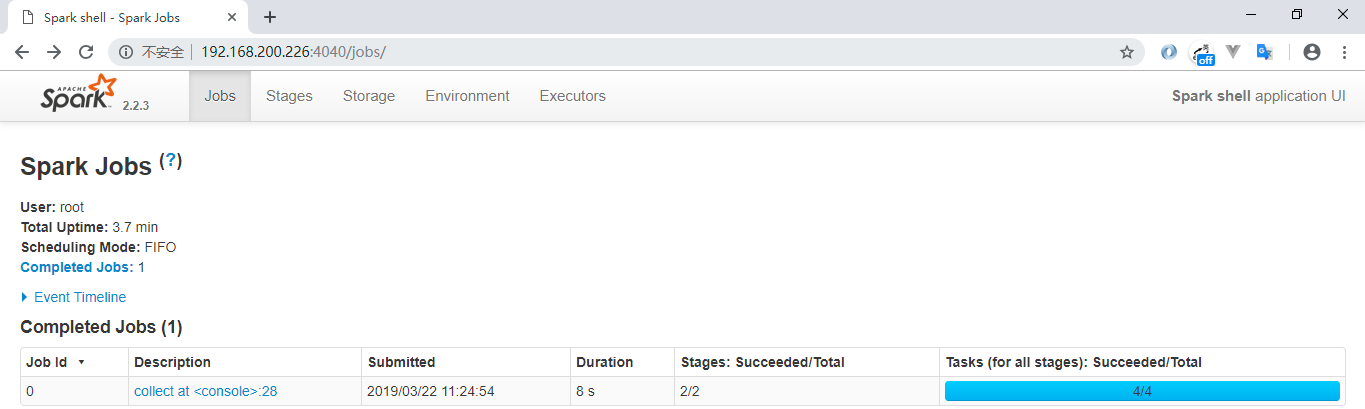
同时还可以通过 Web UI 查看作业的执行情况,访问端口为 4040:
三、Scala开发环境配置
Spark 是基于 Scala 语言进行开发的,分别提供了基于 Scala、Java、Python 语言的 API,如果你想使用 Scala 语言进行开发,则需要搭建 Scala 语言的开发环境。
3.1 前置条件
Scala 的运行依赖于 JDK,所以需要你本机有安装对应版本的 JDK,最新的 Scala 2.12.x 需要 JDK 1.8+。
3.2 安装Scala插件
IDEA 默认不支持 Scala 语言的开发,需要通过插件进行扩展。打开 IDEA,依次点击 File => settings=> plugins 选项卡,搜索 Scala 插件 (如下图)。找到插件后进行安装,并重启 IDEA 使得安装生效。
3.3 创建Scala项目
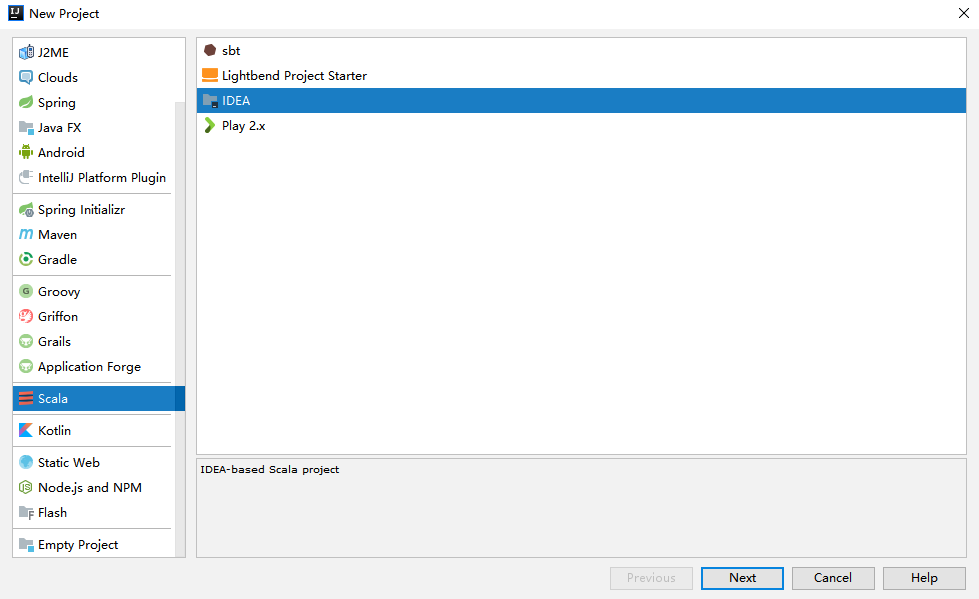
在 IDEA 中依次点击 File => New => Project 选项卡,然后选择创建 Scala—IDEA 工程:
3.4 下载Scala SDK
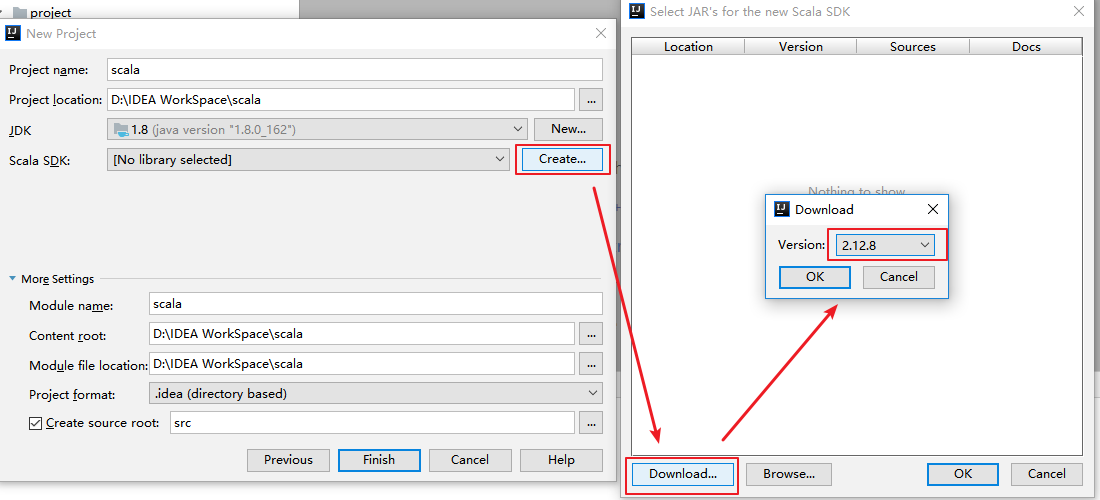
1. 方式一
此时看到 Scala SDK 为空,依次点击 Create => Download ,选择所需的版本后,点击 OK 按钮进行下载,下载完成点击 Finish 进入工程。
2. 方式二
方式一是 Scala 官方安装指南里使用的方式,但下载速度通常比较慢,且这种安装下并没有直接提供 Scala 命令行工具。所以个人推荐到官网下载安装包进行安装,下载地址:https://www.scala-lang.org/download/
这里我的系统是 Windows,下载 msi 版本的安装包后,一直点击下一步进行安装,安装完成后会自动配置好环境变量。
由于安装时已经自动配置好环境变量,所以 IDEA 会自动选择对应版本的 SDK。
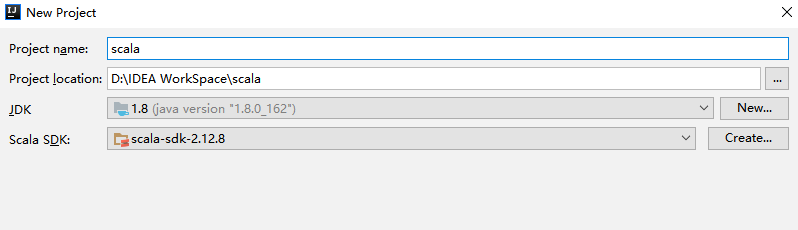
3.5 创建Hello World
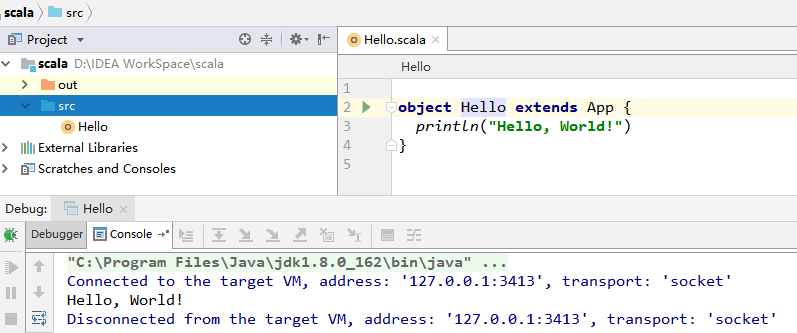
在工程 src 目录上右击 New => Scala class 创建 Hello.scala。输入代码如下,完成后点击运行按钮,成功运行则代表搭建成功。
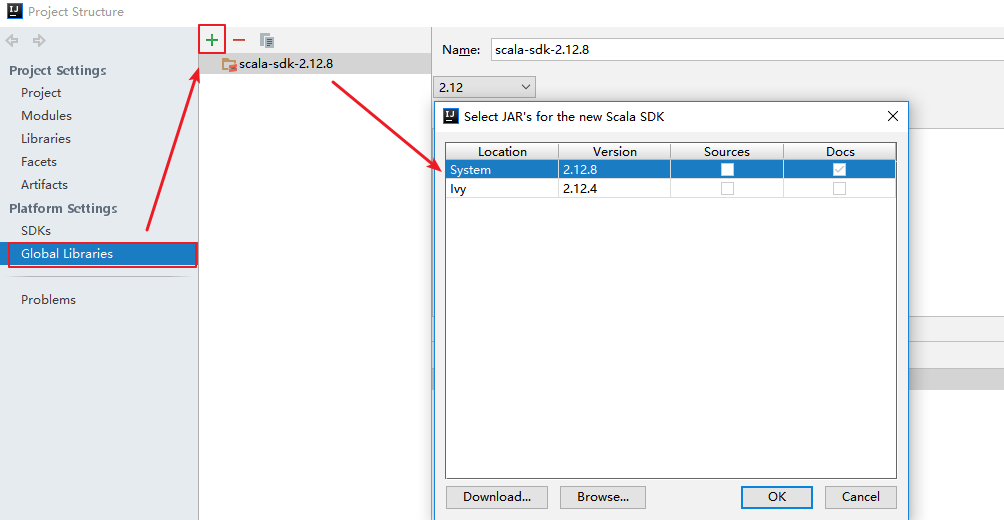
3.6 切换Scala版本
在日常的开发中,由于对应软件(如 Spark)的版本切换,可能导致需要切换 Scala 的版本,则可以在 Project Structures 中的 Global Libraries 选项卡中进行切换。
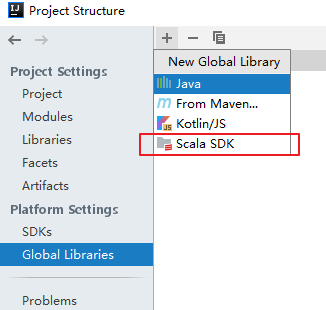
3.7 可能出现的问题
在 IDEA 中有时候重新打开项目后,右击并不会出现新建 scala 文件的选项,或者在编写时没有 Scala 语法提示,此时可以先删除 Global Libraries 中配置好的 SDK,之后再重新添加:
另外在 IDEA 中以本地模式运行 Spark 项目是不需要在本机搭建 Spark 和 Hadoop 环境的。
入门大数据---Spark开发环境搭建的更多相关文章
- 入门大数据---Flink开发环境搭建
一.安装 Scala 插件 Flink 分别提供了基于 Java 语言和 Scala 语言的 API ,如果想要使用 Scala 语言来开发 Flink 程序,可以通过在 IDEA 中安装 Scala ...
- 【原创干货】大数据Hadoop/Spark开发环境搭建
已经自学了好几个月的大数据了,第一个月里自己通过看书.看视频.网上查资料也把hadoop(1.x.2.x).spark单机.伪分布式.集群都部署了一遍,但经历短暂的兴奋后,还是觉得不得门而入. 只有深 ...
- 【JAVA零基础入门系列】Day1 开发环境搭建
[JAVA零基础入门系列](已完结)导航目录 Day1 开发环境搭建 Day2 Java集成开发环境IDEA Day3 Java基本数据类型 Day4 变量与常量 Day5 Java中的运算符 Day ...
- Spark编译及spark开发环境搭建
最近需要将生产环境的spark1.3版本升级到spark1.6(尽管spark2.0已经发布一段时间了,稳定可靠起见,还是选择了spark1.6),同时需要基于spark开发一些中间件,因此需要搭建一 ...
- HBase、Hive、MapReduce、Hadoop、Spark 开发环境搭建后的一些步骤(export导出jar包方式 或 Ant 方式)
步骤一 若是,不会HBase开发环境搭建的博文们,见我下面的这篇博客. HBase 开发环境搭建(Eclipse\MyEclipse + Maven) 步骤一里的,需要补充的.如下: 在项目名,右键, ...
- Spark开发环境搭建和作业提交
Spark高可用集群搭建 在所有节点上下载或上传spark文件,解压缩安装,建立软连接 配置所有节点spark安装目录下的spark-evn.sh文件 配置slaves 配置spark-default ...
- Spark 开发环境搭建
原文见 http://xiguada.org/spark-develop/ 本文基于Spark 0.9.0,由于它基于Scala 2.10,因此必须安装Scala 2.10,否则将无法运行Spar ...
- Spark学习之路(二)—— Spark开发环境搭建
一.安装Spark 1.1 下载并解压 官方下载地址:http://spark.apache.org/downloads.html ,选择Spark版本和对应的Hadoop版本后再下载: 解压安装包: ...
- Spark 系列(二)—— Spark开发环境搭建
一.安装Spark 1.1 下载并解压 官方下载地址:http://spark.apache.org/downloads.html ,选择 Spark 版本和对应的 Hadoop 版本后再下载: 解压 ...
随机推荐
- LayUI laydate日期选择器自定义 快捷选中今天、昨天 、本周、本月等等
1. 引入laydata插件 下载 https://blog-static.cnblogs.com/files/zhangning187/laydate.js laydate.js 替换laydate ...
- Rocket - diplomacy - LazyModuleImpLike
https://mp.weixin.qq.com/s/gDbUto1qd7uWbpnxovr5pg 介绍LazyModuleImpLike类的实现. 1. wrapper LazyMo ...
- JVM虚拟机 与 GC 垃圾回收
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 一.JVM体系结构概述 1.JVM 与系统.硬件 JVM是运行在操作系统之上的,它与硬件没有直接的交 ...
- Java实现 LeetCode 268 缺失数字
268. 缺失数字 给定一个包含 0, 1, 2, -, n 中 n 个数的序列,找出 0 - n 中没有出现在序列中的那个数. 示例 1: 输入: [3,0,1] 输出: 2 示例 2: 输入: [ ...
- Java实现 蓝桥杯VIP 算法提高 阮小二买彩票
算法提高 阮小二买彩票 时间限制:1.0s 内存限制:512.0MB 问题描述 在同学们的帮助下,阮小二是变的越来越懒了,连算账都不愿意自己亲自动手了,每天的工作就是坐在电脑前看自己的银行账户的钱是否 ...
- Java实现 蓝桥杯 历届试题 连号区间数
问题描述 小明这些天一直在思考这样一个奇怪而有趣的问题: 在1~N的某个全排列中有多少个连号区间呢?这里所说的连号区间的定义是: 如果区间[L, R] 里的所有元素(即此排列的第L个到第R个元素)递增 ...
- java实现第三届蓝桥杯数量周期
数量周期 [结果填空](满分9分) 复杂现象背后的推动力,可能是极其简单的原理.科学的目标之一就是发现纷繁复杂的自然现象背后的简单法则.爱因斯坦的相对论是这方面的典范例证. 很早的时候,生物学家观察某 ...
- Linux 用户管理命令-userdel和su
userdel [选项] 用户名,可以删除用户,常用选项 -r :删除用户的同时删除用户的家目录,一般都要用,例如:userdel -r xbb 新建用户和删除用户的本质也就是修改了 /etc/sha ...
- 浅谈python中的赋值、浅拷贝与深拷贝:
1.赋值----------是对原对象的引用,指向同一片内存地址 浅拷贝和深拷贝对于容器类型对象才有意义 2.浅拷贝----------对于一个对象的顶层进行拷贝 浅拷贝有三种方式: (1)切片 (2 ...
- 洛谷 P1115 最大子序和
**原题链接** ##题目描述 给出一段序列,选出其中连续且非空的一段使得这段和最大. **解法**: 1.暴力枚举 时间:O(n^3) 2.简单优化 时间:O(n ...