ELK之 elasticsearch ES集群 head安装
最近项目用到 jenkins ELK 也在一次重新学习了一次 jenkins 不用说了 玩得就是 插件 + base---shell , ELK 这几年最流得log收集平台,当然不止我们运维在用!开发也在用来做client 位置定位 还有网站搜索 elasticsearch , logstash kibana 三个组件组成
来一段简介吧:
ElasticSearch: 是一个实时的分布式搜索和分析引擎,它可以用于全文搜索,结构化搜索以及分析。这是一个建立在全文搜索引擎 Apache Lucene基础上的搜索引擎。
Logstash: 是一个具有实时渠道能力的数据收集引擎,主要用于日志的收集,过滤与解析,并将其存入ElasticSearch中。
Kibana: 是一款 基于Apache开源协议,为ElasticSearch提供分析和可视化的Web平台,它可以在Elasticsearch的索引中查找,交互数据,并生成各种维度的表图。
其实难点我感觉是在logstash--filter 对log 得格式处理上 索引 拆分 格式转换上,这还是要好好去摸索一翻! 好吧 start
给几张网上ELK 架构图 : elasticsearch logstash 支持十几种接口 所以搭配起来也是非常灵活
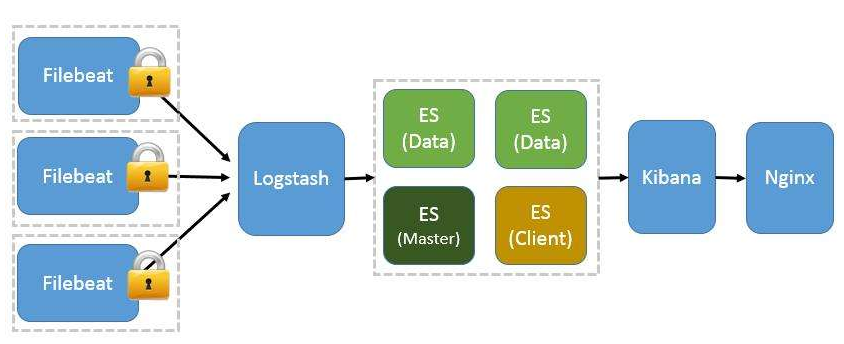
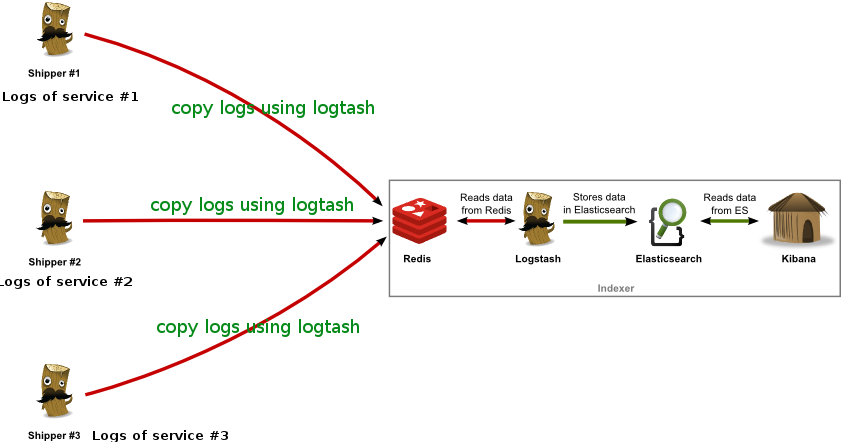
最后一张刚画得
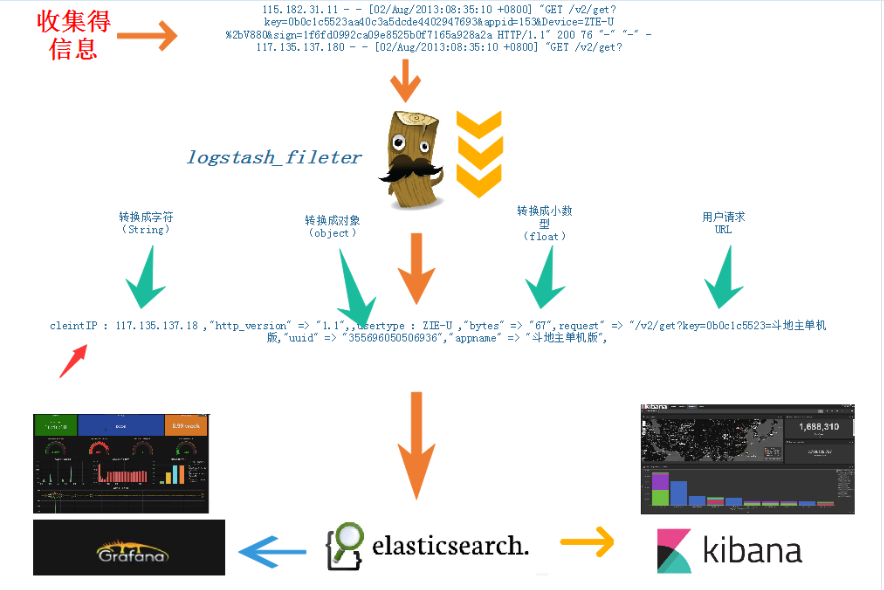
实例: filebeat+redis+logstash+elasticsearch+kibana nginx log收集
service 清单:
172.16.1.9 (elasticsearch[master]+haed) + jdk_1.8.0
172.16.1.10(elasticsearch-slave+kibana) + jdk_1.8.0
172.16.1.6 ( redis )
172.16.1.7( logstash +nginx) + jdk_1.8.0
172.16.1.8(filebeat)
yum -y install java-1.8.0-openjdk*
#验证java安装成功
java -version
java version "1.8.0_131"
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode) #download es
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.4.0.tar.gz -d /opt
tar -zxvf ./elasticsearch-6.4.0.tar.gz && mv elasticsearch-6.4.0 /usr/local/elasticsearch
useradd -m es -p 237356573
mkdir /usr/local/elasticsearch/data && chown -R es:es /usr/local/elasticsearch
mkdir -p /var/log/es && chown -R es:es /var/log/es
#设置es用户最大可创建文件数
# vi /etc/security/limits.conf
* hard nofile 65536
* soft nofile 65536
* soft nproc 2048
* hard nproc 4096
es soft memlock unlimited
es hard memlock unlimited vim /etc/sysctl.conf 添加下面这一行 #用户最大可创建线程数太小
vm.max_map_count=262144
并执行命令:sysctl -p 继续再修改一个参数 #(ES最少要求为2048)
vim /etc/security/limits.d/20-nproc.conf
es soft nproc unlimited
# 10(slave) es 配置文件 cat /usr/local/elasticsearch/config/elasticsearch.yml
cluster.name: my-es
node.name: node-10
path.data: /usr/local/elasticsearch/data
path.logs: /var/log/es
bootstrap.memory_lock: true
network.host: 0.0.0.0
http.port: 9200
http.port: 9300
discovery.zen.ping.unicast.hosts: ["172.16.1.9", "172.16.1.10"]
http.cors.enabled: true
http.cors.allow-origin: "*"
# 9(master) es 配置文件 cat /usr/local/elasticsearch/config/elasticsearch.yml
cluster.name: my-es #集群名称 两台必须一样
node.name: master #节点名称
path.data: /usr/local/elasticsearch/data #es 数据目录
path.logs: /var/log/es #es log 日记
bootstrap.memory_lock: true #配置内存使用用交换分区
network.host: 0.0.0.0 #监听的网络地址
http.port: 9200 #es 监听端口
transport.tcp.port: 9300 #集群监听端口
discovery.zen.ping.unicast.hosts: ["172.16.1.9", "172.16.1.10"] #集群表单
http.cors.enabled: true
http.cors.allow-origin: "*" #跨站请求
启动 9,10 两台同时启动
#关闭防火墙
iptables -I INPUT -p tcp --dport 9200 -j ACCEPT
iptables -I INPUT -p tcp --dport 9300 -j ACCEPT
su es
/usr/local/elasticsearch/bin/elasticsearch -d # -d 后台运行
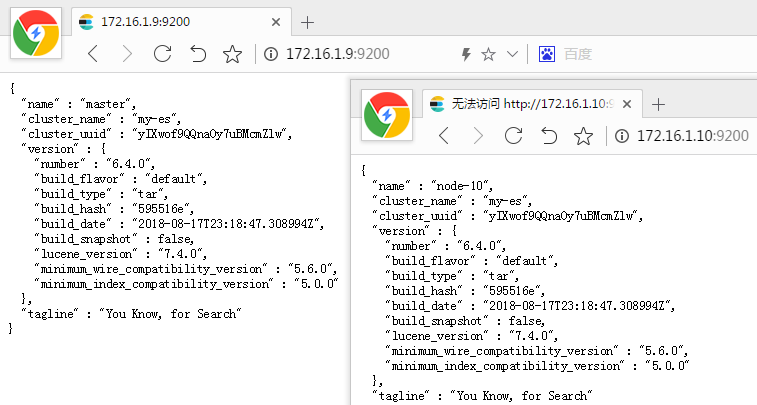
10(master)主机 ES-head 插件安装
安装elasticsearch-head插件 安装docker镜像或者通过github下载elasticsearch-head项目都是可以的,1或者2两种方式选择一种安装使用即可 . 使用docker的集成好的elasticsearch-head
# docker run -p : mobz/elasticsearch-head: docker容器下载成功并启动以后,运行浏览器打开http://localhost:9100/ . 使用git安装elasticsearch-head #npm 源 epel-release 内有 epel-release 源 163 阿里源 都有
# yum install -y npm
npm -v
[root@ES-master ~]# npm -v
3.10.10
3 #安装 phantomjs
yum install -y bzip2 && wget https://bitbucket.org/ariya/phantomjs/downloads/phantomjs-2.1.1-linux-x86_64.tar.bz2 -d /opt
tar -jxvf phantomjs-2.1.1-linux-x86_64.tar.bz2 && mv ./phantomjs-2.1.1-linux-x86_64 /usr/local/phantomjs
ln -s /usr/local/phantomjs/bin/phantomjs /usr/sbin/phantomjs && phantomjs -v
2.1.1
3.1: 直接在线安装head:
npm install --unsafe-perm
#启动 elasticsearch-head 后台
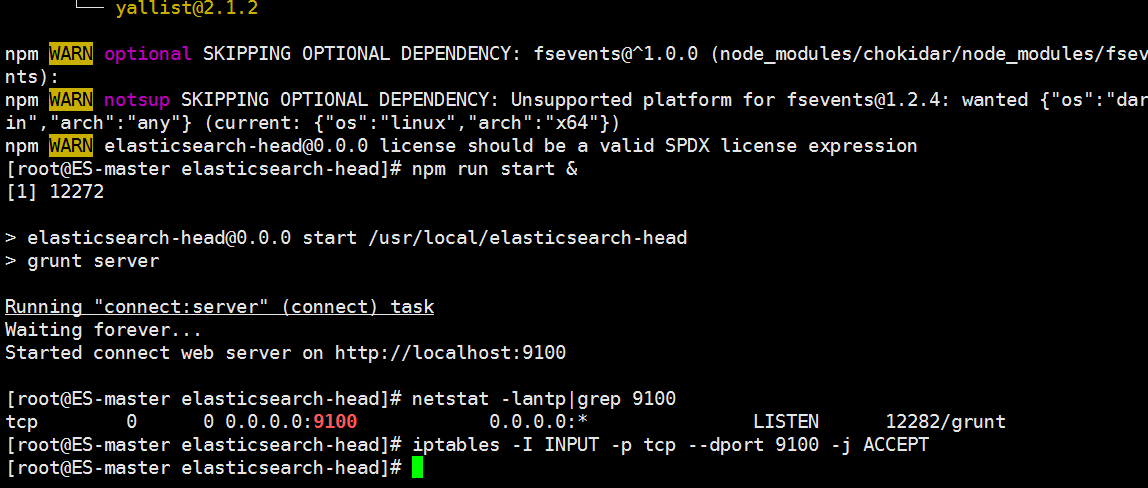
npm run start &
#检查端口是否起来
netstat -antp |grep 9100
#开放端口
iptables -I INPUT -p tcp --dport 9100 -j ACCEPT
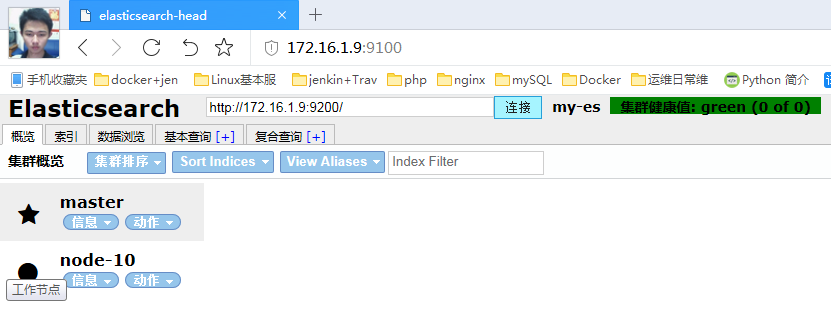
浏览器访问测试是否正常
http://172.16.1.9:9100/
ELK之 elasticsearch ES集群 head安装的更多相关文章
- elasticsearch(es) 集群恢复触发配置(Local Gateway参数)
elasticsearch(es) 集群恢复触发配置(Local Gateway) 当你集群重启时,几个配置项影响你的分片恢复的表现. 首先,我们需要明白如果什么也没配置将会发生什么. 想象一下假设你 ...
- Docker部署ELK 7.0.1集群之Elasticsearch安装介绍
elk介绍这里不再赘述,本系列教程多以实战干货为主,关于elk工作原理介绍,详情查看官方文档. 一.环境规划 主机名 IP 角色 节点名 centos01 10.10.0.10 es node-10 ...
- ELK学习笔记之简单适用的ES集群监控工具cerebro安装使用
安装指导及使用简介 1. 下载安装包: https://github.com/lmenezes/cerebro/releases/download/v0.7.3/cerebro-0.7.3. ...
- elasticsearch系列八:ES 集群管理(集群规划、集群搭建、集群管理)
一.集群规划 搭建一个集群我们需要考虑如下几个问题: 1. 我们需要多大规模的集群? 2. 集群中的节点角色如何分配? 3. 如何避免脑裂问题? 4. 索引应该设置多少个分片? 5. 分片应该设置几个 ...
- elk中es集群web管理工具cerebro
cerebo是kopf在es5上的替代者 安装es虽然不能再root下运行,但是cerebro 可以 run as root is ok wget https://github.com/lmeneze ...
- 搭建ELK日志分析平台(上)—— ELK介绍及搭建 Elasticsearch 分布式集群
笔记内容:搭建ELK日志分析平台(上)-- ELK介绍及搭建 Elasticsearch 分布式集群笔记日期:2018-03-02 27.1 ELK介绍 27.2 ELK安装准备工作 27.3 安装e ...
- 01篇ELK日志系统——升级版集群之elasticsearch集群的搭建
[ 前言:以前搭了个简单的ELK日志系统,以我个人的感觉来说,ELK日志系统还是非常好用的.以前没有弄这个ELK日志系统的时候,线上的项目出了bug,报错了,要定位错误是什么,错误出现在哪个java代 ...
- ELK——Elasticsearch 搭建集群经验
本文内容 背景 ES集群中第一个master节点 ES slave节点 本文总结 Elasticsearch(以下简称ES)搭建集群的经验.以 Elasticsearch-rtf-2.2.1 版本为例 ...
- ElasticSearch和Kibana 5.X集群的安装
ElasticSearch和Kibana 5.X集群的安装 1.准备工作 1.1.下载安装包 1.2.系统的准备 2.ElasticSearch集群的安装 2.1.修改 config/elastics ...
随机推荐
- Linux系统的发展历史和学习前景介绍
2020年了,我想来跟大家聊聊Linux运维这一行业,从几个方面说下行业的现状.如何学好Linux和如何成为专业运维人员以及云服务对于Linux运维的影响. 一.linux行业状况 我们都知道从199 ...
- android原始sqlite中query的复杂用法
android直接执行sql是execSQL(String sql). 这个方法可以执行任意sql语句.但是改变这个不够灵活. query这个方法可以很好的解决这个问题. 执行query查询指定的数据 ...
- nodejs中this详解
最近在用Nodejs进行APP运维服务管理系统开发时发现,nodejs中的this经常会变,查了下资料后发现this在不同的代码位置中代表不同的涵义,在实际运用过程中可以用var self = thi ...
- 解决Python2中文ascii编码的方法
在YiiChina签到的时候,经常会看到有人在说说里面发群主是最帅的,yii 是 PHP 最好的框架,没有之一,就想到使用一言,在每天签到的时候也发一句话 同时使用方糖将内容推送到微信,防止有什么不对 ...
- apache服务器本质上说是一个TCP socket服务
apache服务器本质上说是一个TCP socket服务,socket模型如下: 下面以worker MPM来说明apache代码中相应处理的位置在哪里: (以apache httpd 2.2.23 ...
- iOS下JS与OC互相调用
背景情况: app项目中有几个界面是需要经常变动的(不仅是内容还有UI布局等),比如活动宣传界面就是属于这一类.但是由于AppStore提交审核也是需要时间的,就算审核快,也不至于每次都为了这点事频繁 ...
- 第2节 storm路由器项目开发:8 - 9、集群监控软件ganglia的安装和使用
Ganglia监控Hadoop集群的安装部署 详情请参见 http://boendev.iteye.com/blog/1750615 一. 安装环境 CentOS6.5x86_64 安装gmetad的 ...
- Django:验证email或者name是否已被注册
灵感: http://blog.csdn.net/xxm524/article/details/48369623 使用表单的dajngo的clean()方法实现
- ROS学习笔记9-创建ros消息和服务
该节内容主要来自于官方文档的两个小节:1.使用rosed来编辑2.创建ros消息的服务 先来看rosed: rosedrosed命令是rosbash的一部分,使用rosed可以直接编辑包中的一个文件, ...
- redis学习笔记-03:redis安装
一.redis的安装和配置 1.下载redis-5.0.4.tar.gz到/opt目录下,解压命令 :tar -zxvf redis-5.0.4.tar.gz,解压后出现redis-5.0.4的文件夹 ...