word2vec 构建中文词向量
词向量作为文本的基本结构——词的模型,以其优越的性能,受到自然语言处理领域研究人员的青睐。良好的词向量可以达到语义相近的词在词向量空间里聚集在一起,这对后续的文本分类,文本聚类等等操作提供了便利,本文将详细介绍如何使用word2vec构建中文词向量。
一、中文语料库
本文采用的是搜狗实验室的搜狗新闻语料库,数据链接 http://www.sogou.com/labs/resource/cs.php
下载下来的文件名为: news_sohusite_xml.full.tar.gz
二、数据预处理
2.1 解压并查看原始数据
cd 到原始文件目录下,执行解压命令:
tar -zvxf news_sohusite_xml.full.tar.gz
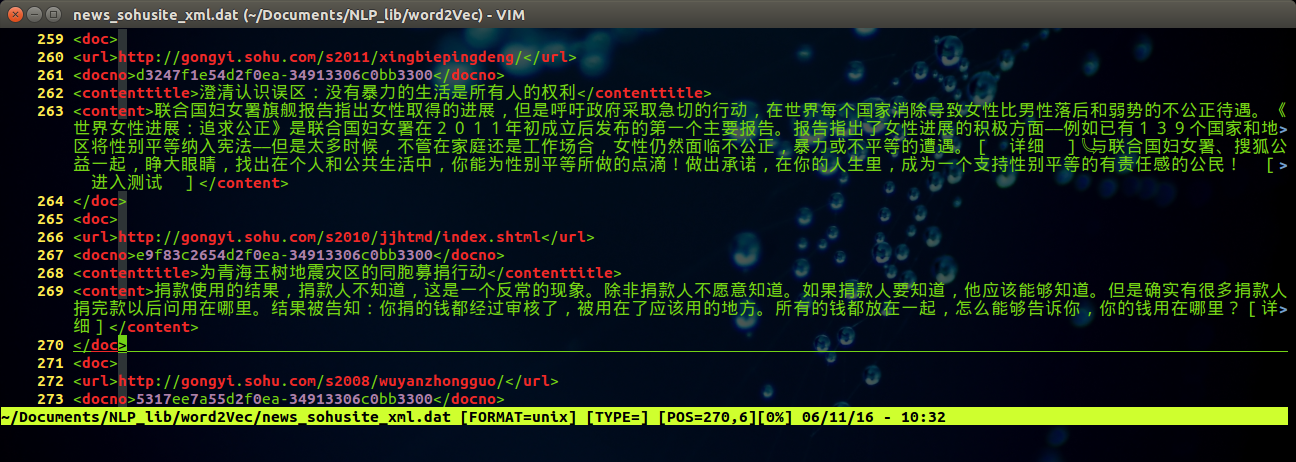
得到文件 news_sohusite_xml.dat, 用vim打开该文件,
vim news_sohusite_xml.dat
得到如下结果:
2.2 取出内容
取出<content> </content> 中的内容,执行如下命令:
cat news_tensite_xml.dat | iconv -f gbk -t utf-8 -c | grep "<content>" > corpus.txt
得到文件名为corpus.txt的文件,可以通过vim 打开
vim corpus.txt
得到如下效果:

2.3 分词
注意,送给word2vec的文件是需要分词的,分词可以采用jieba分词实现,安装jieba 分词
pip install jieba
对原始文本内容进行分词,python 程序如下:
##!/usr/bin/env python
## coding=utf-8
import jieba filePath='corpus.txt'
fileSegWordDonePath ='corpusSegDone.txt'
# read the file by line
fileTrainRead = []
#fileTestRead = []
with open(filePath) as fileTrainRaw:
for line in fileTrainRaw:
fileTrainRead.append(line) # define this function to print a list with Chinese
def PrintListChinese(list):
for i in range(len(list)):
print list[i],
# segment word with jieba
fileTrainSeg=[]
for i in range(len(fileTrainRead)):
fileTrainSeg.append([' '.join(list(jieba.cut(fileTrainRead[i][9:-11],cut_all=False)))])
if i % 100 == 0 :
print i # to test the segment result
#PrintListChinese(fileTrainSeg[10]) # save the result
with open(fileSegWordDonePath,'wb') as fW:
for i in range(len(fileTrainSeg)):
fW.write(fileTrainSeg[i][0].encode('utf-8'))
fW.write('\n')
可以得到文件名为 corpusSegDone.txt 的文件,需要注意的是,对于读入文件的每一行,使用结巴分词的时候并不是从0到结尾的全部都进行分词,而是对[9:-11]分词 (如行22中所示: fileTrainRead[i][9:-11] ),这样可以去掉每行(一篇新闻稿)起始的<content> 和结尾的</content>。
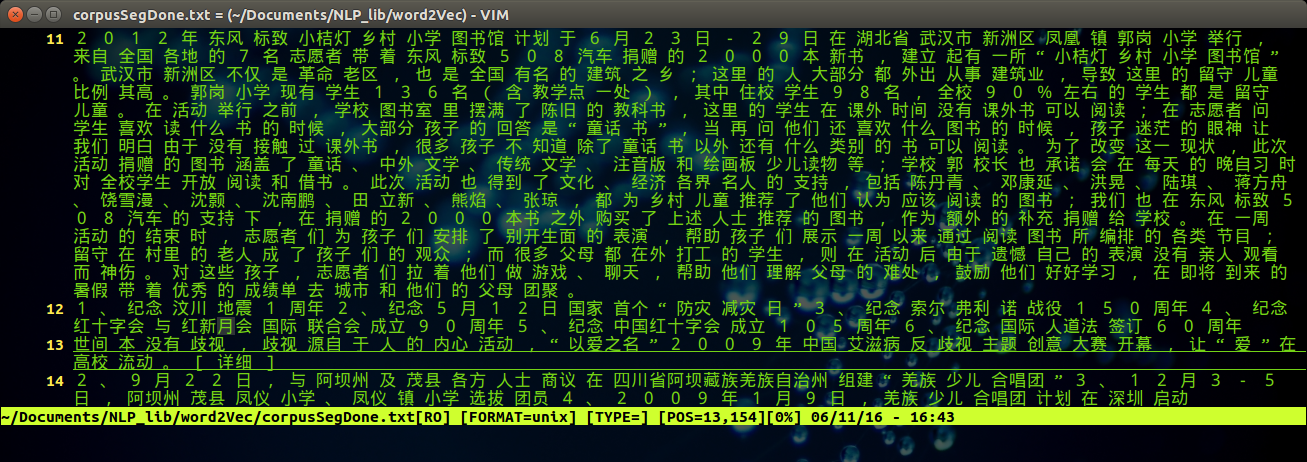
同样的,可以通过vim 打开分词之后的文件,执行命令:
vim corpusSegDone.txt
得到如下图所示的结果:
三、构建词向量
3.1 安装word2vec
pip install word2vec
3.2 构建词向量
执行以下程序:
import word2vec
word2vec.word2vec('corpusSegDone.txt', 'corpusWord2Vec.bin', size=300,verbose=True)
即可构建词向量,得到结果放在文件名为 corpusWord2Vec.bin的文件中。可以通过设定size 的大小来指定词向量的维数。用vim打开生成的二进制文件会出现乱码,目前不知道解决方法。
3.3 显示并使用词向量
3.3.1 查看词向量
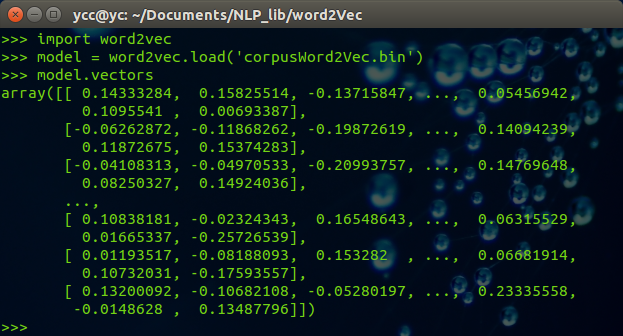
import word2vec
model = word2vec.load('corpusWord2Vec.bin')
print (model.vectors)
可以得到如下结果:
3.3.2 查看词表中的词
import word2vec
model = word2vec.load('corpusWord2Vec.bin')
index = 1000
print (model.vocab[index]
得到结果如下:

可以得到词表中第1000个词为 确保。
3.3.3 显示空间距离相近的词
一个好的词向量可以实现词义相近的一组词在词向量空间中也是接近的,可以通过显示词向量空间中相近的一组词并判断它们语义是否相近来评价词向量构建的好坏。代码如下:
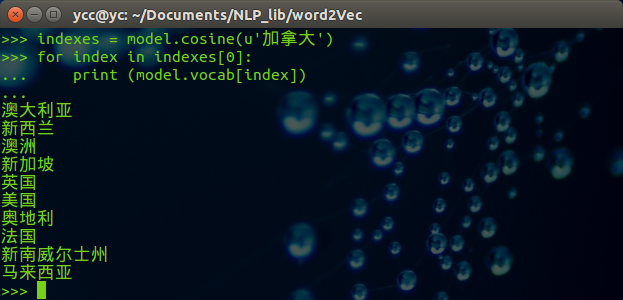
import word2vec
model = word2vec.load('corpusWord2Vec.bin')
indexes = model.cosine(u'加拿大')
for index in indexes[0]:
print (model.vocab[index])
得到的结果如下:
可以修改希望查找的中文词,例子如下:
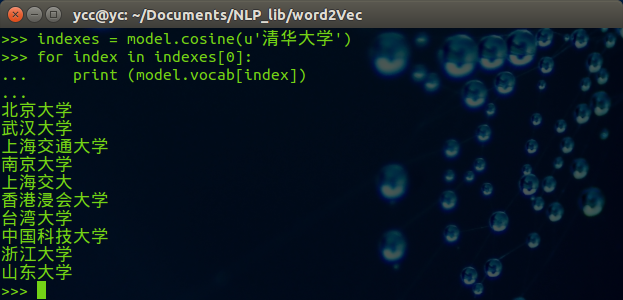
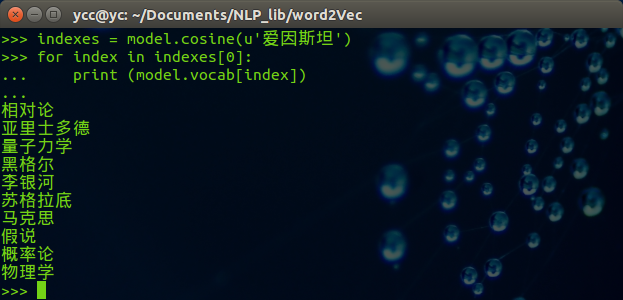
四、二维空间中显示词向量
将词向量采用PCA进行降维,得到二维的词向量,并打印出来,代码如下:
#!/usr/bin/env python
# coding=utf-8
import numpy as np
import matplotlib
import matplotlib.pyplot as plt from sklearn.decomposition import PCA
import word2vec
# load the word2vec model
model = word2vec.load('corpusWord2Vec.bin')
rawWordVec=model.vectors # reduce the dimension of word vector
X_reduced = PCA(n_components=2).fit_transform(rawWordVec) # show some word(center word) and it's similar words
index1,metrics1 = model.cosine(u'中国')
index2,metrics2 = model.cosine(u'清华')
index3,metrics3 = model.cosine(u'牛顿')
index4,metrics4 = model.cosine(u'自动化')
index5,metrics5 = model.cosine(u'刘亦菲') # add the index of center word
index01=np.where(model.vocab==u'中国')
index02=np.where(model.vocab==u'清华')
index03=np.where(model.vocab==u'牛顿')
index04=np.where(model.vocab==u'自动化')
index05=np.where(model.vocab==u'刘亦菲') index1=np.append(index1,index01)
index2=np.append(index2,index03)
index3=np.append(index3,index03)
index4=np.append(index4,index04)
index5=np.append(index5,index05) # plot the result
zhfont = matplotlib.font_manager.FontProperties(fname='/usr/share/fonts/truetype/wqy/wqy-microhei.ttc')
fig = plt.figure()
ax = fig.add_subplot(111) for i in index1:
ax.text(X_reduced[i][0],X_reduced[i][1], model.vocab[i], fontproperties=zhfont,color='r') for i in index2:
ax.text(X_reduced[i][0],X_reduced[i][1], model.vocab[i], fontproperties=zhfont,color='b') for i in index3:
ax.text(X_reduced[i][0],X_reduced[i][1], model.vocab[i], fontproperties=zhfont,color='g') for i in index4:
ax.text(X_reduced[i][0],X_reduced[i][1], model.vocab[i], fontproperties=zhfont,color='k') for i in index5:
ax.text(X_reduced[i][0],X_reduced[i][1], model.vocab[i], fontproperties=zhfont,color='c') ax.axis([0,0.8,-0.5,0.5])
plt.show()
中文的显示需要做特殊处理,详见代码 line: 37
下图是执行结果:

源自: https://www.cnblogs.com/Newsteinwell/p/6034747.html
word2vec 构建中文词向量的更多相关文章
- 使用word2vec训练中文词向量
https://www.jianshu.com/p/87798bccee48 一.文本处理流程 通常我们文本处理流程如下: 1 对文本数据进行预处理:数据预处理,包括简繁体转换,去除xml符号,将单词 ...
- AAAI 2018 论文 | 蚂蚁金服公开最新基于笔画的中文词向量算法
AAAI 2018 论文 | 蚂蚁金服公开最新基于笔画的中文词向量算法 2018-01-18 16:13蚂蚁金服/雾霾/人工智能 导读:词向量算法是自然语言处理领域的基础算法,在序列标注.问答系统和机 ...
- 使用 DL4J 训练中文词向量
目录 使用 DL4J 训练中文词向量 1 预处理 2 训练 3 调用 附录 - maven 依赖 使用 DL4J 训练中文词向量 1 预处理 对中文语料的预处理,主要包括:分词.去停用词以及一些根据实 ...
- 文本分类实战(一)—— word2vec预训练词向量
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- gensim的word2vec如何得出词向量(python)
首先需要具备gensim包,然后需要一个语料库用来训练,这里用到的是skip-gram或CBOW方法,具体细节可以去查查相关资料,这两种方法大致上就是把意思相近的词映射到词空间中相近的位置. 语料库t ...
- 开源共享一个训练好的中文词向量(语料是维基百科的内容,大概1G多一点)
使用gensim的word2vec训练了一个词向量. 语料是1G多的维基百科,感觉词向量的质量还不错,共享出来,希望对大家有用. 下载地址是: http://pan.baidu.com/s/1boPm ...
- word2vec预训练词向量
NLP中的Word2Vec讲解 word2vec是Google开源的一款用于词向量计算 的工具,可以很好的度量词与词之间的相似性: word2vec建模是指用CBoW模型或Skip-gram模型来计算 ...
- 文本分布式表示(二):用tensorflow和word2vec训练词向量
看了几天word2vec的理论,终于是懂了一些.理论部分我推荐以下几篇教程,有博客也有视频: 1.<word2vec中的数学原理>:http://www.cnblogs.com/pegho ...
- 斯坦福NLP课程 | 第1讲 - NLP介绍与词向量初步
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
随机推荐
- java的动态绑定和多态
public class Shape { public void area() { System.out.println("各种形状的面积..."); } public stati ...
- django项目日志
接口中,写一条日志: 日志工具文件如下:
- 联合查询:union
1.联合查询:union 1.1 作用:将多条select语句的结果,合并到一起,称之为联合操作. 1.2 语法:( ) union ( ); 例子:(select name from info_or ...
- 中国科技股赴美IPO的游戏结束了吗?
编辑 | 于斌 出品 | 于见(mpyujian) 有关斗鱼直播的消息,一直层出不求.最近前几天又有捷报传出,斗鱼走出国门,在美国上市,开始了自己的新征程. 但据悉,斗鱼国际控股有限公司可能刚刚达到外 ...
- 【Python collections】
目录 namedtuple deque Counter OrderedDict defaultdict "在内置数据类型(dict.list.set.tuple)的基础上,collectio ...
- 无法创建“System.Object”类型的常量值。此上下文仅支持基元类型或枚举类型
Entity FreamWork 无法创建“System.Object”类型的常量值.此上下文仅支持基元类型或枚举类型错误解决: 最近在开发中把我原来抄的架构里面的主键由固定的Guid改成了可以泛型指 ...
- 如何安装和使用Maven
今天我们来学习一下如何安装Maven,把步骤分享给大家,希望能对大家有帮助! 我的博客地址:https://www.cnblogs.com/themysteryofhackers/p/11996550 ...
- web应用程序上传文件 超过了最大请求长度
具体问题如下图 具体问题描述:在web应用程序中,上传了200M的文件,出现了如上图的问题,上传较小文件的时候,没有任何的问题.但是,测试的能力,不容小觑,真真的会测试的很全面.测试到了这个问题,好吧 ...
- if语句的汇编表示
转自:https://blog.csdn.net/u011608357/article/details/22586137 demo: C语言: int max(int x,int y) { if (x ...
- Python爬虫教程:requests模拟登陆github
1. Cookie 介绍 HTTP 协议是无状态的.因此,若不借助其他手段,远程的服务器就无法知道以前和客户端做了哪些通信.Cookie 就是「其他手段」之一. Cookie 一个典型的应用场景,就是 ...