从卷积拆分和分组的角度看CNN模型的演化
写在前面
如题,这篇文章将尝试从卷积拆分的角度看一看各种经典CNN backbone网络module是如何演进的,为了视角的统一,仅分析单条路径上的卷积形式。
形式化
方便起见,对常规卷积操作,做如下定义,
- \(I\):输入尺寸,长\(H\) 宽\(W\) ,令长宽相同,即\(I = H = W\)
- \(M\):输入channel数,可以看成是tensor的高
- \(K\):卷积核尺寸\(K \times K\),channel数与输入channel数相同,为\(M\)
- \(N\):卷积核个数
- \(F\):卷积得到的feature map尺寸\(F \times F\),channel数与卷积核个数相同,为\(N\)
所以,输入为\(M \times I \times I\)的tensor,卷积核为\(N \times M \times K \times K\)的tensor,feature map为\(N \times F \times F\)的tensor,所以常规卷积的计算量为
\]
特别地,如果仅考虑SAME padding且\(stride = 1\)的情况,则\(F = I\),则计算量等价为
\]
可以看成是\((K \times K \times M) \times (N \times I \times I)\),前一个括号为卷积中一次内积运算的计算量,后一个括号为需要多少次内积运算。
参数量为
\]
网络演化
总览SqueezeNet、MobileNet V1 V2、ShuffleNet等各种轻量化网络,可以看成对卷积核\(M \times K \times K\) 进行了各种拆分或分组(同时引入激活函数),这些拆分和分组通常会减少参数量和计算量,这就为进一步增加卷积核数量\(N\)让出了空间,同时这种结构上的变化也是一种正则,通过上述变化来获得性能和计算量之间的平衡。
这些变化,从整体上看,相当于对原始\(FLOPS = K \times K \times M \times N \times I \times I\)做了各种变换。
下面就从这个视角进行一下疏理,简洁起见,只列出其中发生改变的因子项,
Group Convolution(AlexNet),对输入进行分组,卷积核数量不变,但channel数减少,相当于
\[M \rightarrow \frac{M}{G}
\]
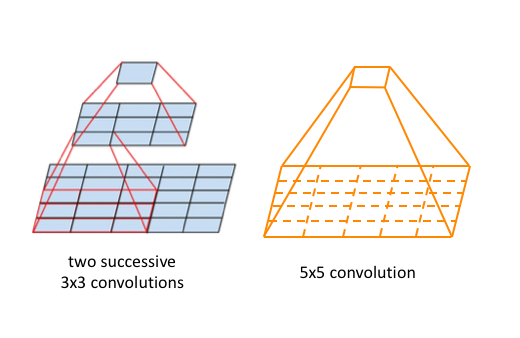
大卷积核替换为多个堆叠的小核(VGG),比如\(5\times 5\)替换为2个\(3\times 3\),\(7\times 7\)替换为3个\(3\times 3\),保持感受野不变的同时,减少参数量和计算量,相当于把 大数乘积 变成 小数乘积之和,
\[(K \times K) \rightarrow (k \times k + \dots + k \times k)
\]
Factorized Convolution(Inception V2),二维卷积变为行列分别卷积,先行卷积再列卷积,
\[(K \times K) \rightarrow (K \times 1 + 1 \times K)
\]
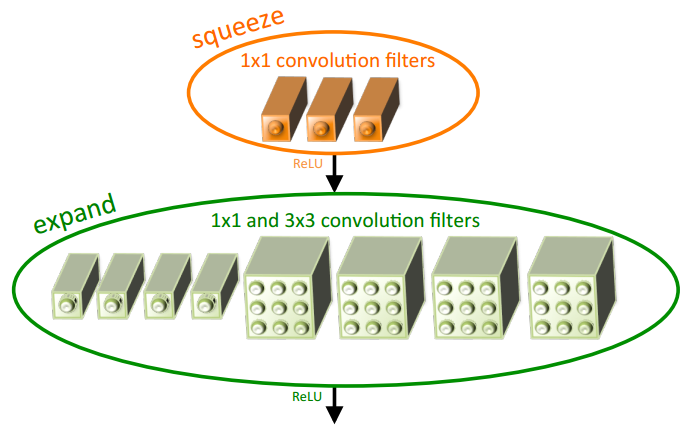
Fire module(SqueezeNet),pointwise+ReLU+(pointwise + 3x3 conv)+ReLU,pointwise降维,同时将一定比例的\(3\times 3\)卷积替换为为\(1 \times 1\),
\[(K \times K \times M \times N) \rightarrow (M \times \frac{N}{t} + \frac{N}{t} \times (1-p)N + K \times K \times \frac{N}{t} \times pN) \\
K = 3
\]
Bottleneck(ResNet),pointwise+BN ReLU+3x3 conv+BN ReLU+pointwise,类似于对channel维做SVD,
\[(K \times K \times M \times N) \rightarrow (M \times \frac{N}{t} + K \times K \times \frac{N}{t} \times \frac{N}{t} + \frac{N}{t} \times N) \\
t = 4
\]
ResNeXt Block(ResNeXt),相当于引入了group \(3\times 3\) convolution的bottleneck,
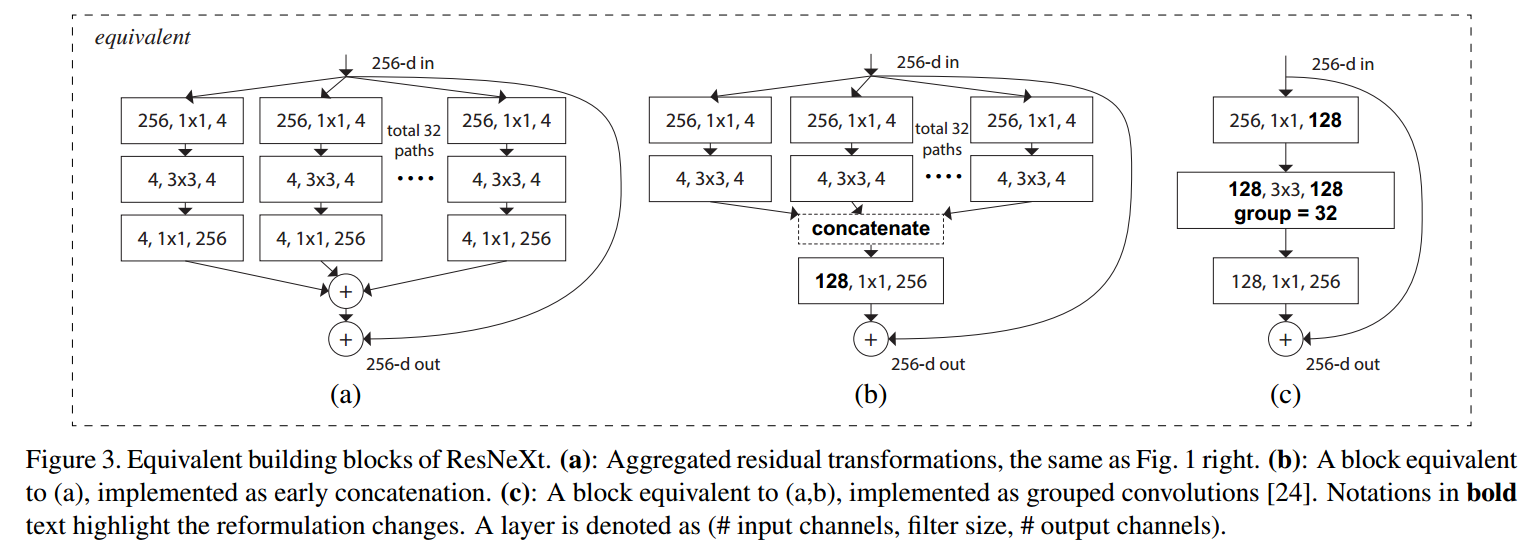 \[(K \times K \times M \times N) \rightarrow (M \times \frac{N}{t} + K \times K \times \frac{N}{tG} \times \frac{N}{t} + \frac{N}{t} \times N) \\
\[(K \times K \times M \times N) \rightarrow (M \times \frac{N}{t} + K \times K \times \frac{N}{tG} \times \frac{N}{t} + \frac{N}{t} \times N) \\
t = 2, \ G = 32
\]Depthwise Separable Convolution(MobileNet V1),depthwise +BN ReLU + pointwise + BN ReLU,
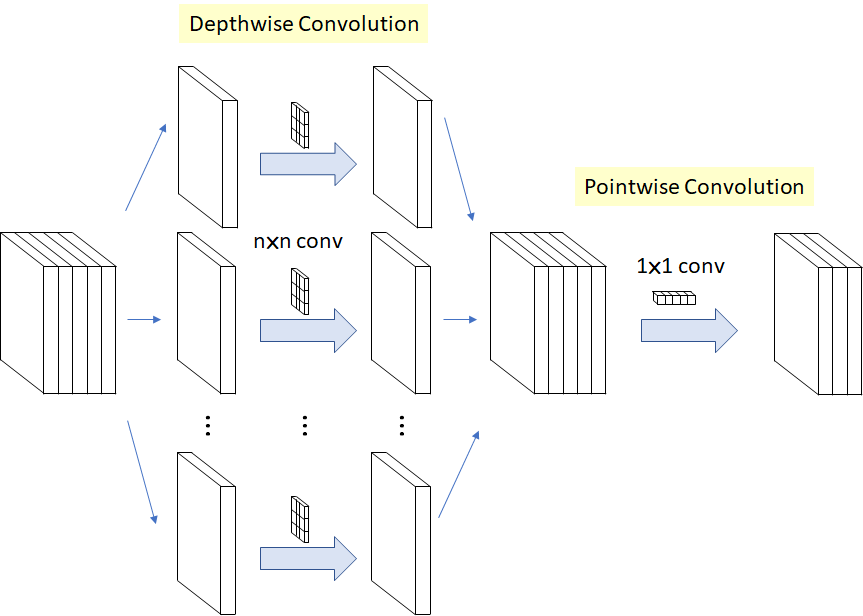
相当于将channel维单独分解出去,
\[(K \times K \times N) \rightarrow (K \times K + N)
\]Separable Convolution(Xception),pointwise + depthwise + BN ReLU,
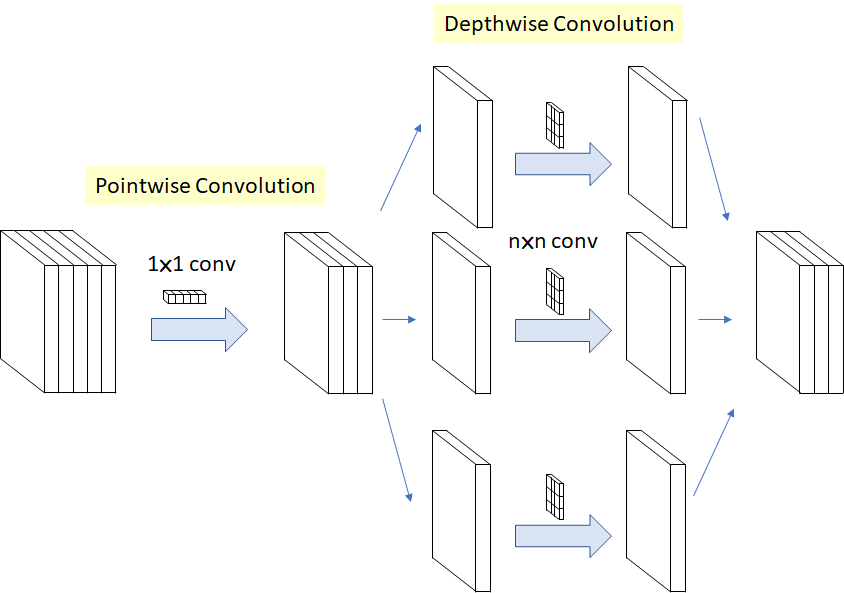
也相当于将channel维分解出去,但前后顺序不同(但因为是连续堆叠,其实跟基本Depthwise Separable Convolution等价),同时移除了两者间的ReLU,
\[(K \times K \times M) \rightarrow (M + K \times K)
\]但实际在实现上是depthwise + pointwise + ReLU。
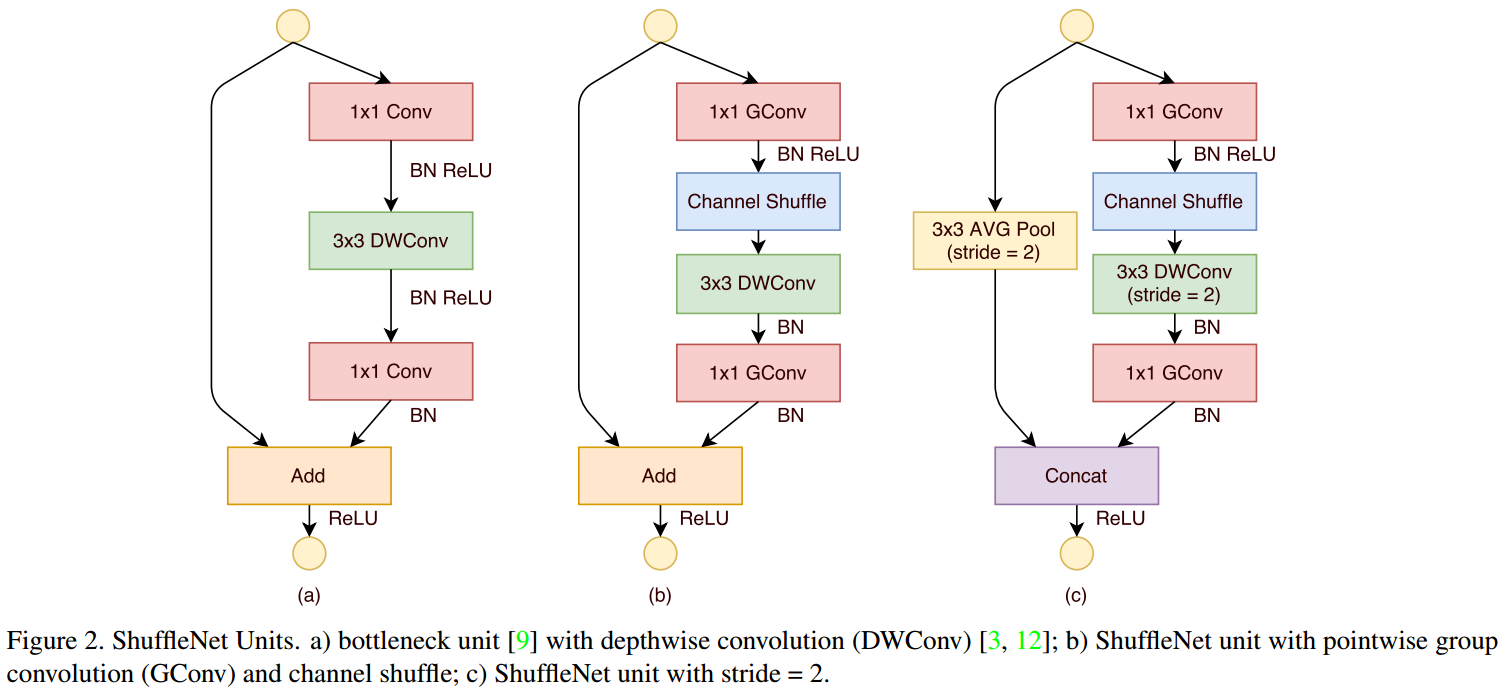
pointwise group convolution and channel shuffle(ShuffleNet),group pointwise+BN ReLU+Channel Shuffle+depthwise+BN+group pointwise+BN,相当于bottleneck中2个pointwise引入相同的group,同时\(3\times 3\) conv变成depthwise,也就是说3个卷积层都group了,这会阻碍不同channel间(分组间)的信息交流,所以在第一个group pointwise后加入了channel shuffle,即
\[(K \times K \times M \times N) \rightarrow (\frac{M}{G} \times \frac{N}{t} + channel \ shuffle +K \times K \times \frac{N}{t} + \frac{N}{tG} \times N)
\]
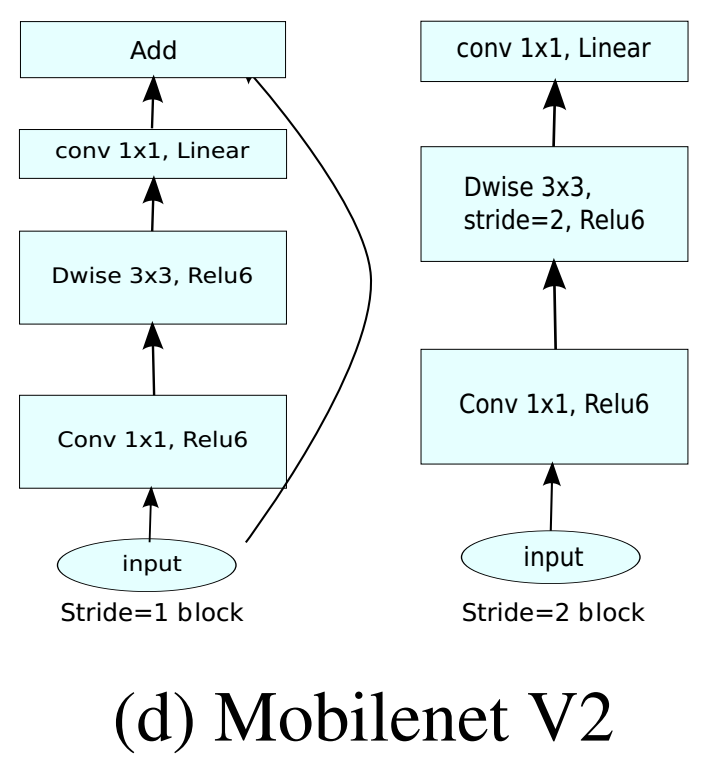
Inverted Linear Bottleneck(MobileNet V2),bottleneck是先通过pointwise降维、再卷积、再升维,Inverted bottleneck是先升维、再卷积、再降维,pointwise+BN ReLU6+depthwise+BN ReLU6+pointwise+BN,
\[(K \times K \times M \times N) \rightarrow (M \times tM + K \times K \times tM + tM \times N) \\t = 6
\]
小结
最后小结一下,早期的CNN由一个个常规卷积层堆叠而成,而后,开始模块化,由一个个 module构成,module的演化,可以看成是不停地在常规卷积的计算量\(FLOPS = K \times K \times M \times N \times I \times I\)上做文章。
- 拆分:卷积核是个3 D 的tensor,可以在不同维度上进行拆分,行列可拆分,高上也可拆分,高上还可以多段拆分(类似SVD)。
- 分组:如果多个卷积核放在一起,可以构成4D的tensor,增加的这一数量维上可以分组group。
不同拆分和分组的方式排列组合就构成了各种各样的module。
从卷积拆分和分组的角度看CNN模型的演化的更多相关文章
- 聊聊Netty那些事儿之从内核角度看IO模型
从今天开始我们来聊聊Netty的那些事儿,我们都知道Netty是一个高性能异步事件驱动的网络框架. 它的设计异常优雅简洁,扩展性高,稳定性强.拥有非常详细完整的用户文档. 同时内置了很多非常有用的模块 ...
- 对博弈活动中蕴含的信息论原理的讨论,以及从熵角度看不同词素抽象方式在WEBSHELL文本检测中的效果区别
1. 从赛马说起 0x1:赛马问题场景介绍 假设在一场赛马中有m匹马参赛,令第i匹参赛马获胜的概率为pi,如果第i匹马获胜,那么机会收益为oi比1,即在第i匹马上每投资一美元,如果赢了,会得到oi美元 ...
- Android IOS WebRTC 音视频开发总结(四八)-- 从商业和技术的角度看视频行业的机会
本文主要从不同角度介绍视频行业的机会,文章来自博客园RTC.Blacker,支持原创,转载必须说明出处,欢迎关注个人微信公众号blacker ----------------------------- ...
- 【阿里云产品公测】以开发者角度看ACE服务『ACE应用构建指南』
作者:阿里云用户mr_wid ,z)NKt# @I6A9do 如果感觉该评测对您有所帮助, 欢迎投票给本文: UO<claV RsfTUb)< 投票标题: 28.[阿里云 ...
- [置顶] 从引爆点的角度看360随身wifi的发展
从引爆点的角度看360随身wifi的发展 不到一个月的时间,随身wifi预定量就数百万.它的引爆点在哪里,为什么相同的产品这么多它却能火起来,通过对随身wifi的了解和我知识层面分析,主要是因为随身w ...
- 站在Java的角度看LinkedList
站在Java的角度看,玩队列不就是玩对象引用对象嘛! public class LinkedList<E> implements List<E>, Deque<E> ...
- 从源码的角度看 React JS 中批量更新 State 的策略(下)
这篇文章我们继续从源码的角度学习 React JS 中的批量更新 State 的策略,供我们继续深入学习研究 React 之用. 前置文章列表 深入理解 React JS 中的 setState 从源 ...
- 从线程模型的角度看Netty的高性能
转载:Netty(二) 从线程模型的角度看 Netty 为什么是高性能的? 传统 IO 在 Netty 以及 NIO 出现之前,我们写 IO 应用其实用的都是用 java.io.* 下所提供的包. 比 ...
- INDEX--从数据存放的角度看索引2
在上次<INDEX--从数据存放的角度看索引>中,我们说到"唯一非聚集索引"和“非唯一非聚集索引”在存储上有一个明显的差别:唯一非聚集索引的非叶子节点上不会包含RID的 ...
随机推荐
- python与excel的关系;铁打的python流水的excel
现在很多行业,都离不开用Excel: 做财务的,要用Excel做报表:做物流的,会用Excel来跟踪订单情况:做HR的,会用Excel算工资:做分析的,会用Excel计算数据做报表.不知道你有没有这样 ...
- docker环境常用命令
Ubuntu 安装docker及docker-compose 安装: apt-get install docker apt-get install docker-compose 启动docker环境: ...
- [Laravel] 自带分页实现以及links方法不存在错误
自带分页实现其实挺简单的,但是我在实现的时候报错!找了很久才找出原因! 废话不说上码 控制器LeeController.php层 <?php namespace App\Http\control ...
- JDBC教程——检视阅读
JDBC教程--检视阅读 参考 JDBC教程--W3Cschool JDBC教程--一点教程,有高级部分 JDBC教程--易百 JDBC入门教程 – 终极指南 略读 三层架构详解,JDBC在数据访问层 ...
- input框处理大全
1.去掉谷歌input记住账号或密码时默认出现的黄色背景: 直接用css的内阴影来覆盖黄色(代码中 white可换成其他颜色) input:-webkit-autofill { -webkit-box ...
- Data Flow Diagram with Examples - Customer Service System
Data Flow Diagram with Examples - Customer Service System Data Flow Diagram (DFD) provides a visual ...
- Spring5参考指南:基于注解的容器配置
文章目录 @Required @Autowired @primary @Qualifier 泛型 @Resource @PostConstruct和@PreDestroy Spring的容器配置可以有 ...
- 高性能服务器开发基础系列 (二)Reactor模式
系列目录 第01篇 主线程与工作线程的分工 第02篇 Reactor模式 第03篇 一个服务器程序的架构介绍 第04篇 如何将socket设置为非阻塞模式 第05篇 如何编写高性能日志 第06篇 关于 ...
- Linux 搭建nginx的PID
pid logs/nginx.pid 安装的时候就是没有,其实在启动 nginx 时自动生成的 里面存放的是 当前 nginx 住进程的 ID 号:所以在配置文件中指定pidpid /usr/loca ...
- 【20180129】java进程经常OOM,扩容swap。
导读:线上一台服务器专门做为公司内部apk打包服务,由于app的业务和功能与时俱增,apk打包需要依赖的资源越来越多,最近这几天每次apk打包的时候都会由于OOM导致打包失败.由于apk打包业务并不是 ...