论文笔记之:Playing Atari with Deep Reinforcement Learning
Playing Atari with Deep Reinforcement Learning
《Computer Science》, 2013
Abstract:
本文提出了一种深度学习方法,利用强化学习的方法,直接从高维的感知输入中学习控制策略。模型是一个卷积神经网络,利用 Q-learning的一个变种来进行训练,输入是原始像素,输出是预测将来的奖励的 value function。将此方法应用到 Atari 2600 games 上来,进行测试,发现在所有游戏中都比之前的方法有效,甚至在其中3个游戏中超过了一个人类玩家的水平。
Introduction:
从高维感知输入中学习控制agents,像视觉或者speech 是强化学习中一个长期的挑战。大部分成功的涉及到这几个领域的 RL 应用都依赖于手工设计的feature 和 线性策略函数或者策略表示的组合。明显,这种系统的性能严重的依赖于特征表示的质量。
最近深度学习的发展,对于从原始感知数据中提取高层feature 称为可能,并且在计算机视觉和语音识别上面取得了很大的进展。这些方法利用神经网络结构,包括 神经网络,多层感知机,RBM 和 RNN,已经涉及到监督学习和非监督学习领域。大家很自然的就会问,是否可以利用相似的技术来解决 RL 中感知数据的问题。
然而, RL 从深度学习的角度,体现了几个挑战:
首先,大部分成功的 深度学习算法都依赖于海量标注的数据, RL 算法,从另一个角度,必须从一个变换的奖励信号中进行学习,而且这种信号还经常是稀疏的,有噪声的,且是延迟的。动作 和 导致的奖励 之间的延迟,可能有几千步那么长,看起来在监督学习中,当直接将输入和目标联系起来非常吓人。
另一个问题是,大部分深度学习算法都假设 data samples 是相互独立的,然而, RL 经常遇到 高度相关的状态。
此外,在 RL 中数据分布随着算法学习到新的行为而改变,这对于深度学习假设固定的潜在分布是有问题的。
这篇文章表明,一个 CNN 可以克服这些挑战,并且在复杂的 RL 环境下从原始视频数据中学习到控制策略。该网络是用变种的 Q-learning 算法训练的,利用 SGD 来更新权重。为了降低相关数据和非静态分布的问题,我们使用了一种 经验重播机制 (experience replay mechanism),该机制随机的采样之前的转换,所以就在许多过去的行为上平滑了训练分布。
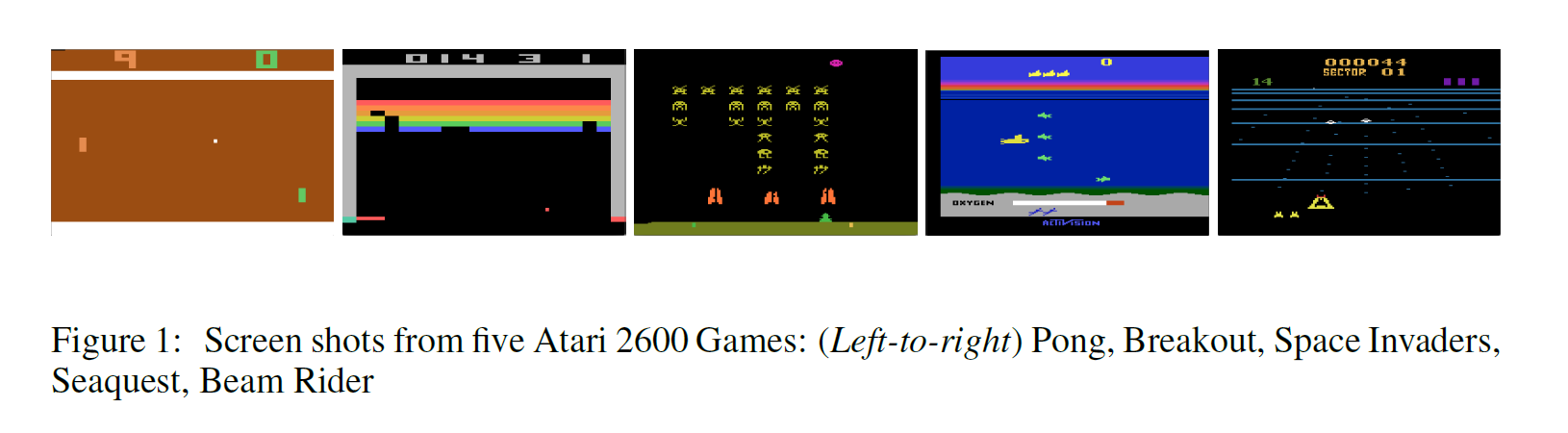
Background:
我们考虑到 agent 和 环境交互,即:Atari emulator,是一个动作,观察 和 奖励的序列。在每一个时间步骤,agent 选择一个动作 $a_t$ 从合法的动作集合 $\mathcal{A} = {1, 2, ..., K}$. 该动作被传递到模拟器,然后修改其初始状态和游戏得分。总的来说 环境可能是随机的。模拟器的中间状态, agent 是无法看到的;但是 agent 可以观察到一张图像 xt,由原始像素值构成的表示当前屏幕的向量。此外,他也接收到表示游戏得分的奖励 rt。注意到,总的来说,游戏得分依赖于动作和观察的整个序列;关于一个动作的反馈可能得在几千次时间步骤上才能收到。
由于该 agent 仅仅观察到当前屏幕的图像,所以任务是部分观察到的,许多模拟器状态是感官上有锯齿的,即:仅仅从当前的屏幕,无法完全理解当前的情形。我们所以就考虑 动作和观察的序列, $s_t = x_1, a_1, x_2, ... , a_{t-1}$,然后依赖于这些序列去学习游戏策略。模拟器中的序列都认为会在有限的时间步骤内结束。这就是说在每一个序列,一个large 但是有限的 MDP 是一个清楚的状态。结果,我们采用标准的 RL 方法来处理 MDPs,利用完整的序列 $s_t$ 作为时刻 t 的状态表示。
agent的目标是和模拟器交互,然后选择动作,使得将来的奖励最大化。我们做出假设,即:将来的奖励每一个时间步骤都会打一个折扣 $\gamma$,定义将来的时刻 t 的折扣 return 为:
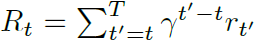
我们定义一个最优 动作-值函数 $Q^*(s, a)$ 作为采用任何策略后最大期望 return,在看了一些序列 s 然后采取了一些动作 a,
$Q^*(s, a) = max_{\pi} E [R_t|s_t = s, a_t = a, \pi]$,其中,$\pi$ 是一个从序列到动作的映射。
最优的动作值函数 服从一个重要的等式,叫做:Bellman equation. 这个基于如下的观察:如果下一个时间步骤的序列 s'的 最优值 Q^*(s', a') 对于所有可能的动作 a' 都是已知的,然后最优策略就是选择动作 a' 使得期望值 $r + \gamma Q^*(s', a')$最大化:
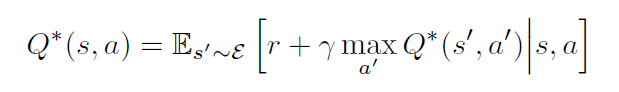
许多强化学习算法背后基本的 idea 是预测 the action-value function,利用 Bellman equation 作为一次迭代更新,
$Q_{i+1}(s, a) = E[ r + \gamma_{a'} Q_i(s, a) ]$.
如此 value iteration 算法收敛到一个最优的 动作值函数,$Q_i -> Q^*$。
实际上,这个基础的方法是完全不实用的,因为:动作值函数是对每一个序列分别预测的,而没有任何泛化。(the action-value function is estimated separately for each sequence, without any generalisation.) 相反,实用 function approximator 去预测 action-value function的值确实很常见的,即:
$Q(s, a; \theta) = Q^*(s, a)$
在强化学习领域,这通常是一个线性函数,但是有时候非线性函数估计也用,如:神经网络。我们将带有权重的神经网络函数记为:Q-network。一个Q-network 可以通过一个序列的损失函数 $L_i(\theta_i)$ 最小化来实现每一次迭代 i 的改变。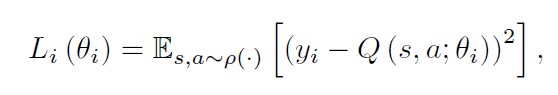
其中,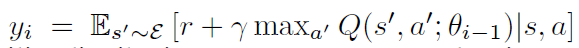 是第i次迭代的目标,也就是当做 label 来用。当优化损失函数 $L_i(\theta_i)$,前一次迭代的参数固定。注意到,target 依赖于网络的权重,这是和监督学习当中的 target对比而来的,在学习开始之前是固定的。区分开损失函数与对应的权重,我们得到如下的梯度:
是第i次迭代的目标,也就是当做 label 来用。当优化损失函数 $L_i(\theta_i)$,前一次迭代的参数固定。注意到,target 依赖于网络的权重,这是和监督学习当中的 target对比而来的,在学习开始之前是固定的。区分开损失函数与对应的权重,我们得到如下的梯度: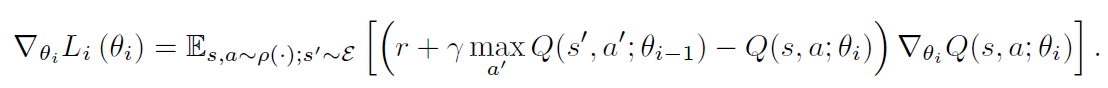
不是在上述梯度中,计算全部的期望,比较适合的方法是利用 SGD 的方法来优化损失函数。If the weights are updated after every time-step, and the expectations are replaced by single samples from the behaviour distribution and the emulator, respectively, then we arrive at the familiar Q-learning algorithm.
注意到,该算法是 "model-free"的,即:直接从模拟器中利用采样,解决了 RL 学习任务,而没有显示的构建 estimate。本算法也是“off-policy”的,即:学习贪婪策略 $a = max_a Q(s, a; \theta)$,服从一个行为分布,确保状态空间的足够探索。实际上,行为分布经常被贪婪策略选择,有 1-x 的概率进行探索,以 x 的概率随机选择一个动作。
Deep Reinforcement Learning
最近在计算机视觉和语音识别领域的突破,主要依赖于有效的深度学习在海量训练数据上的学习。最成功的方法是直接从原始输入上进行训练,基于 SGD 进行权重更新。通过喂养深度神经网络足够的数据,通常可以学习到比手工设计特征要好得多的特征表达(feature representation)。这些成功激发了我们在 RL 相关的工作。我们的目标是将 RL 算法和深度神经网络进行联系,也是直接处理 RGB 图像,并且利用 随机梯度更新来有效的处理训练数据。
和 TD-Gammon 以及类似的 online方法相对,我们利用一种称为 experience replay 的技术,我们将 agent 每一个时间步骤的经验存储起来,$e_t = (s_t, a_t, r_t, s_{t+1})$,将许多 episodes 存储进一个 replay memory。在算法内部循环中,我们采用 Q-learning 更新,或者 minibatch updates,来采样 experience,从存储的样本中随机的提取。在执行 experience replay之后,agent 根据贪婪算法,选择并且执行一个动作。由于采用任意长度的 histories 作为神经网络的输入是非常困难的,我们的 Q-function 作用在由函数作用之后,固定长度表示的 histories。算法的全称,我们称为 Deep Q-learning。
该算法与传统的 Q-learning 相比,有以下几个优势:
首先,experience 的每一个步骤都在权重更新上有潜在的应用,可以允许更好的数据效率。
第二,从连续的样本上直接进行学习是 inefficient的,由于样本之间较强的相关性;随机提取这些样本,就打算了他们之间的联系,所以减少了更新的方差。
第三,当学习 on-policy 的时候,当前参数决定了下一个数据样本( when learning on-policy the current parameters determine the next data sample that the parameters are trained on)。例如,如果最大值动作是向左移动,那么训练样本就主要由左侧的样本构成;如果最大化动作是向右移动,然后训练分布也随之改变。It is easy to see how unwanted feedback loops may arise and the parameters could get stuck in a poor local minimum, or even diverge catastrophically. 通过利用 experience replay,行为分布就在之前许多状态上取了平均,使得学习更加平滑,而不至于震荡或者不收敛的情况。
在我们的方法之中,我们的算法仅仅存储最近 N 个 experience tuples,当执行更新的时候,随机的从 D 上均匀的采样。
数据的预处理,就是对输入的图像进行降分辨率等相关处理,使得尽可能的减少计算量。
模型的结构主要是:2层卷积层,后面接2层全连接层,输出是 动作空间,即:所有的可能要采取的动作。
算法的流程如下图所示:

实验部分:
论文笔记之:Playing Atari with Deep Reinforcement Learning的更多相关文章
- Paper Reading 1 - Playing Atari with Deep Reinforcement Learning
来源:NIPS 2013 作者:DeepMind 理解基础: 增强学习基本知识 深度学习 特别是卷积神经网络的基本知识 创新点:第一个将深度学习模型与增强学习结合在一起从而成功地直接从高维的输入学习控 ...
- 深度学习课程笔记(十八)Deep Reinforcement Learning - Part 1 (17/11/27) Lectured by Yun-Nung Chen @ NTU CSIE
深度学习课程笔记(十八)Deep Reinforcement Learning - Part 1 (17/11/27) Lectured by Yun-Nung Chen @ NTU CSIE 201 ...
- 论文笔记系列-Neural Architecture Search With Reinforcement Learning
摘要 神经网络在多个领域都取得了不错的成绩,但是神经网络的合理设计却是比较困难的.在本篇论文中,作者使用 递归网络去省城神经网络的模型描述,并且使用 增强学习训练RNN,以使得生成得到的模型在验证集上 ...
- (转) Deep Reinforcement Learning: Playing a Racing Game
Byte Tank Posts Archive Deep Reinforcement Learning: Playing a Racing Game OCT 6TH, 2016 Agent playi ...
- 【资料总结】| Deep Reinforcement Learning 深度强化学习
在机器学习中,我们经常会分类为有监督学习和无监督学习,但是尝尝会忽略一个重要的分支,强化学习.有监督学习和无监督学习非常好去区分,学习的目标,有无标签等都是区分标准.如果说监督学习的目标是预测,那么强 ...
- [DQN] What is Deep Reinforcement Learning
已经成为DL中专门的一派,高大上的样子 Intro: MIT 6.S191 Lecture 6: Deep Reinforcement Learning Course: CS 294: Deep Re ...
- 18 Issues in Current Deep Reinforcement Learning from ZhiHu
深度强化学习的18个关键问题 from: https://zhuanlan.zhihu.com/p/32153603 85 人赞了该文章 深度强化学习的问题在哪里?未来怎么走?哪些方面可以突破? 这两 ...
- repost: Deep Reinforcement Learning
From: http://wanghaitao8118.blog.163.com/blog/static/13986977220153811210319/ accessed 2016-03-10 深度 ...
- 深度强化学习(Deep Reinforcement Learning)入门:RL base & DQN-DDPG-A3C introduction
转自https://zhuanlan.zhihu.com/p/25239682 过去的一段时间在深度强化学习领域投入了不少精力,工作中也在应用DRL解决业务问题.子曰:温故而知新,在进一步深入研究和应 ...
随机推荐
- Dom操作html详细
<p name='pn'>xxx</p> <p name='pn'>xxx</p> <p name='pn'>xxx</p> & ...
- Linux下tmpfs与ramfs的区别
ramfs是Linux下一种基于RAM做存储的文件系统.在使用过程中你就可以把ramfs理解为在普通的HDD上建立了一个文件系统,而现在HDD被替换成了RAM,因为是RAM做存储所以会有很高的存储 ...
- Python学习路程day7
多态 class Animal: def __init__(self, name): # Constructor of the class self.name = name def talk(self ...
- Multiple dex files define
Multiple dex files define 在项目中,有一个类的包名和引用的jar包中的类和包名一致
- FR #1题解
A. 建图跑最小费用最大流.分类讨论每种情况如何连边,费用怎么定. #include<iostream> #include<cstdio> #include<cstrin ...
- HTML的定位属性
position 用于定义一个元素是否absolute(绝对),relative(相对),static(静态),或者fixed(固定) top层距离顶点纵坐标的距离 left层距离顶点横坐标的距 ...
- 前App Store高管揭秘:关于“苹果推荐”的七大真相
相信你已经看过很多这样那样关于如何获得苹果商店推荐的攻略了,但其实很多人依然陷入了很大的误区.前不久采访了前App Store团队高管Greg Essig,向各位开发者揭示关于获得苹果推荐的真相. 在 ...
- 程序员是怎么炼成的---OC题集--练习答案与题目(2)
1.objective-c中有垃圾回收机制吗? 没有像java.C#一样的垃圾回收机制,但是有ARC自动引用计数器技术,根据对象的引用技术来判断对象是否还在使用,如果RC=0,则系统就会销毁对象,实 ...
- python+webdriver ppt
一:selenium webdriver的介绍 1.来源,优点,局限性 2.和其他自动化工具对比 3.工作原理 4.组成部分 二:webdriver的api介绍 1.driver 2.元素定位(id, ...
- Git简易的命令行入门教程
简易的命令行入门教程: Git 全局设置: git config --global user.name "imsoft" git config --global user.emai ...