海量数据和高并发下的 Redis 业务优化实践
本文内容是我在 6 月 23 日参加的深圳 GIAC 技术大会上演讲的文字稿。
观众朋友们,我是来自掌阅的工程师钱文品,掘金小册《Redis 深度历险》的作者。今天我带来的是分享主题是:Redis 在海量数据和高并发下的优化实践。Redis 对于从事互联网技术工程师来说并不陌生,几乎所有的大中型企业都在使用 Redis 作为缓存数据库,但是对于绝大多数企业来说只会用到它的最基础的 KV 缓存功能,还有很多 Redis 的高级功能可能都未曾认真实践过。今天在这一个小时的时间我会围绕 Redis,分享在平时的日常业务开发中遇到的 9 个经典案例,希望通过此次分享可以帮助大家更好的将 Redis 的高级特性应用到日常的业务开发中来。
掌阅电子书阅读软件 ireader 的总用户量大概是 5亿左右,月活 5kw,日活近 2kw 。服务端有 1000 多个 Redis 实例,100+ 集群,每个实例的内存控制在 20g 以下。
KV 缓存
第一个是最基础也是最常用的就是 KV 功能,我们可以用 Redis 来缓存用户信息、会话信息、商品信息等等。下面这段代码就是通用的缓存读取逻辑。
def get_user(user_id):
user = redis.get(user_id)
if not user:
user = db.get(user_id)
redis.setex(user_id, ttl, user) // 设置缓存过期时间
return user
def save_user(user):
redis.setex(user.id, ttl, user) // 设置缓存过期时间
db.save_async(user) // 异步写数据库
复制代码这个过期时间非常重要,它通常会和用户的单次会话长度成正比,保证用户在单次会话内尽量一直可以使用缓存里面的数据。当然如果贵公司财力雄厚,又极致注重性能体验,可以将时间设置的长点甚至干脆就不设置过期时间。当数据量不断增长时,就使用 Codis 或者 Redis-Cluster 集群来扩容。
除此之外 Redis 还提供了缓存模式,Set 指令不必设置过期时间,它也可以将这些键值对按照一定的策略进行淘汰。打开缓存模式的指令是:config set maxmemory 20gb ,这样当内存达到 20gb 时,Redis 就会开始执行淘汰策略,给新来的键值对腾出空间。这个策略 Redis 也是提供了很多种,总结起来这个策略分为两块:划定淘汰范围,选择淘汰算法。比如我们线上使用的策略是 allkeys-lru。这个 allkeys 表示对 Redis 内部所有的 key 都有可能被淘汰,不管它有没有带过期时间,而volatile只淘汰带过期时间的。Redis 的淘汰功能就好比企业遇到经济寒冬时需要勒紧裤腰带过冬需要进行一轮残酷的人才优化。它会选择只优化临时工呢,还是所有人一律平等都可能被优化。当这个范围圈定之后,会从中选出若干个名额,怎么选择呢,这个就是淘汰算法。最常用的就是 LRU 算法,它有一个弱点,那就是表面功夫做得好的人可以逃过优化。比如你乘机赶紧在老板面前好好表现一下,然后你就安全了。所以到了 Redis 4.0 里面引入了 LFU 算法,要对平时的成绩也进行考核,只做表面功夫就已经不够用了,还要看你平时勤不勤快。最后还一种极不常用的算法 —— 随机摇号算法,这个算法有可能会把 CEO 也给淘汰了,所以一般不会使用它。
分布式锁
下面我们看第二个功能 —— 分布式锁,这个是除了 KV 缓存之外最为常用的另一个特色功能。比如一个很能干的资深工程师,开发效率很快,代码质量也很高,是团队里的明星。所以呢诸多产品经理都要来烦他,让他给自己做需求。如果同一时间来了一堆产品经理都找他,它的思路呢就会陷入混乱,再优秀的程序员,大脑的并发能力也好不到哪里去。所以呢他就在自己的办公室的门把上挂了一个请勿打扰的牌子,当一个产品经理来的时候先看看门把上有没有这个牌子,如果没有呢就可以进来找工程师谈需求,谈之前要把牌子挂起来,谈完了再把牌子摘了。这样其它产品经理也要来烦他的时候,如果看见这个牌子挂在那里,就可以选择睡觉等待或者是先去忙别的事。如是这位明星工程师从此获得了安宁。
这个分布式锁的使用方式非常简单,就是使用 Set 指令的扩展参数如下
# 加锁
set lock:$user_id owner_id nx ex=5
# 释放锁
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del", KEYS[1])
else
return 0
end
# 等价于
del_if_equals lock:$user_id owner_id
复制代码一定要设置这个过期时间,因为遇到特殊情况 —— 比如地震(进程被 kill -9,或者机器宕机),产品经理可能会选择从窗户上跳下去,没机会摘牌,导致了死锁饥饿,让这位优秀的工程师成了一位大闲人,造成严重的资源浪费。同时还需要注意这个 owner_id,它代表锁是谁加的 —— 产品经理的工号。以免你的锁不小心被别人摘掉了。释放锁时要匹配这个 owner_id,匹配成功了才能释放锁。这个 owner_id 通常是一个随机数,存放在 ThreadLocal 变量里(栈变量)。
官方其实并不推荐这种方式,因为它在集群模式下会产生锁丢失的问题 —— 在主从发生切换的时候。官方推荐的分布式锁叫 RedLock,作者认为这个算法较为安全,推荐我们使用。不过掌阅这边一直还使用上面最简单的分布式锁,为什么我们不去使用 RedLock 呢,因为它的运维成本会高一些,需要 3 台以上独立的 Redis 实例,用起来要繁琐一些。另外呢 Redis 集群发生主从切换的概率也并不高,即使发生了主从切换出现锁丢失的概率也很低,因为主从切换往往都有一个过程,这个过程的时间通常会超过锁的过期时间,也就不会发生锁的异常丢失。还有呢就是分布式锁遇到锁冲突的机会也不多,这正如一个公司里明星程序员也比较有限一样,总是遇到锁排队那说明结构上需要优化。
延时队列
下面我们继续看第三个功能 —— 延时队列。前面我们提到产品经理在遇到「请勿打扰」的牌子时可以选择多种策略,1. 干等待 2. 睡觉 2. 放弃不干了 3. 歇一会再干。干等待就是 spinlock,这会烧 CPU,飙高 Redis 的QPS。睡觉就是先 sleep 一会再试,这会浪费线程资源,还会增加响应时长。放弃不干呢就是告知前端用户待会再试,现在系统压力大有点忙,影响用户体验。最后一种呢就是现在要讲的策略 —— 待会再来,这是在现实世界里最普遍的策略。这种策略一般用在消息队列的消费中,这个时候遇到锁冲突该怎么办?不能抛弃不处理,也不适合立即重试(spinlock),这时就可以将消息扔进延时队列,过一会再处理。
有很多专业的消息中间件支持延时消息功能,比如 RabbitMQ 和 NSQ。Redis 也可以,我们可以使用 zset 来实现这个延时队列。zset 里面存储的是 value/score 键值对,我们将 value 存储为序列化的任务消息,score 存储为下一次任务消息运行的时间(deadline),然后轮询 zset 中 score 值大于 now 的任务消息进行处理。
# 生产延时消息
zadd(queue-key, now_ts+5, task_json)
# 消费延时消息
while True:
task_json = zrevrangebyscore(queue-key, now_ts, 0, 0, 1)
if task_json:
grabbed_ok = zrem(queue-key, task_json)
if grabbed_ok:
process_task(task_json)
else:
sleep(1000) // 歇 1s
复制代码当消费者是多线程或者多进程的时候,这里会存在竞争浪费问题。当前线程明明将 task_json 从 zset 中轮询出来了,但是通过 zrem 来争抢时却抢不到手。这时就可以使用 LUA 脚本来解决这个问题,将轮询和争抢操作原子化,这样就可以避免竞争浪费。
local res = nil
local tasks = redis.pcall("zrevrangebyscore", KEYS[1], ARGV[1], 0, "LIMIT", 0, 1)
if #tasks > 0 then
local ok = redis.pcall("zrem", KEYS[1], tasks[1])
if ok > 0 then
res = tasks[1]
end
end
return res
复制代码为什么我要将分布式锁和延时队列一起讲呢,因为很早的时候线上出了一次故障。故障发生时线上的某个 Redis 队列长度爆表了,导致很多异步任务得不到执行,业务数据出现了问题。后来查清楚原因了,就是因为分布式锁没有用好导致了死锁,而且遇到加锁失败时就 sleep 无限重试结果就导致了异步任务彻底进入了睡眠状态不能处理任务。那这个分布式锁当时是怎么用的呢?用的就是 setnx + expire,结果在服务升级的时候停止进程直接就导致了个别请求执行了 setnx,但是 expire 没有得到执行,于是就带来了个别用户的死锁。但是后台呢又有一个异步任务处理,也需要对用户加锁,加锁失败就会无限 sleep 重试,那么一旦撞上了前面的死锁用户,这个异步线程就彻底熄火了。因为这次事故我们才有了今天的正确的分布式锁形式以及延时队列的发明,还有就是优雅停机,因为如果存在优雅停机的逻辑,那么服务升级就不会导致请求只执行了一半就被打断了,除非是进程被 kill -9 或者是宕机。
定时任务
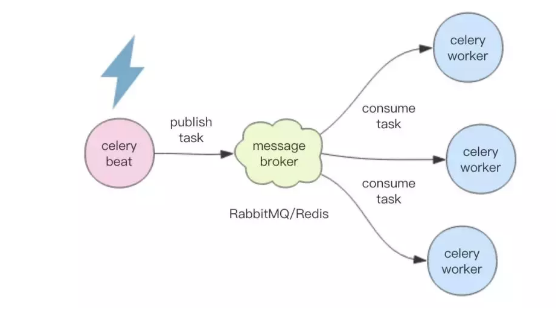
分布式定时任务有多种实现方式,最常见的一种是 master-workers 模型。master 负责管理时间,到点了就将任务消息仍到消息中间件里,然后worker们负责监听这些消息队列来消费消息。著名的 Python 定时任务框架 Celery 就是这么干的。但是 Celery 有一个问题,那就是 master 是单点的,如果这个 master 挂了,整个定时任务系统就停止工作了。
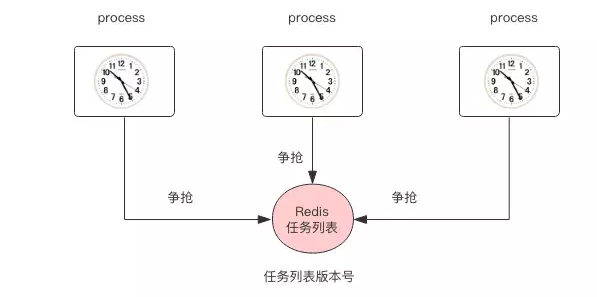
另一种实现方式是 multi-master 模型。这个模型什么意思呢,就类似于 Java 里面的 Quartz 框架,采用数据库锁来控制任务并发。会有多个进程,每个进程都会管理时间,时间到了就使用数据库锁来争抢任务执行权,抢到的进程就获得了任务执行的机会,然后就开始执行任务,这样就解决了 master 的单点问题。这种模型有一个缺点,那就是会造成竞争浪费问题,不过通常大多数业务系统的定时任务并没有那么多,所以这种竞争浪费并不严重。还有一个问题它依赖于分布式机器时间的一致性,如果多个机器上时间不一致就会造成任务被多次执行,这可以通过增加数据库锁的时间来缓解。
现在有了 Redis 分布式锁,那么我们就可以在 Redis 之上实现一个简单的定时任务框架。
# 注册定时任务
hset tasks name trigger_rule
# 获取定时任务列表
hgetall tasks
# 争抢任务
set lock:${name} true nx ex=5
# 任务列表变更(滚动升级)
# 轮询版本号,有变化就重加载任务列表,重新调度时间有变化的任务
set tasks_version $new_version
get tasks_version
复制代码如果你觉得 Quartz 内部的代码复杂的让人看不懂,分布式文档又几乎没有,很难折腾,可以试试 Redis,使用它会让你少掉点头发。
Life is Short,I use Redis
https://github.com/pyloque/taskino
复制代码频率控制
如果你做过社区就知道,不可避免总是会遇到垃圾内容。一觉醒来你会发现首页突然会某些莫名其妙的广告帖刷屏了。如果不采取适当的机制来控制就会导致用户体验收到严重影响。
控制广告垃圾贴的策略非常多,高级一点的通过 AI,最简单的方式是通过关键词扫描。还有比较常用的一种方式就是频率控制,限制单个用户内容生产速度,不同等级的用户会有不同的频率控制参数。
频率控制就可以使用 Redis 来实现,我们将用户的行为理解为一个时间序列,我们要保证在一定的时间内限制单个用户的时间序列的长度,超过了这个长度就禁止用户的行为。它可以是用 Redis 的 zset 来实现。
图中绿色的部门就是我们要保留的一个时间段的时间序列信息,灰色的段会被砍掉。统计绿色段中时间序列记录的个数就知道是否超过了频率的阈值。
下面的代码控制用户的 ugc 行为为每小时最多 N 次
hist_key = "ugc:${user_id}"
with redis.pipeline() as pipe:
# 记录当前的行为
pipe.zadd(hist_key, ts, uuid)
# 保留1小时内的行为序列
pipe.zremrangebyscore(hist_key, 0, now_ts - 3600)
# 获取这1小时内的行为数量
pipe.zcard(hist_key)
# 设置过期时间,节约内存
pipe.expire(hist_key, 3600)
# 批量执行
_, _, count, _ = pipe.exec()
return count > N
复制代码服务发现
技术成熟度稍微高一点的企业都会有服务发现的基础设施。通常我们都会选用 zookeeper、etcd、consul 等分布式配置数据库来作为服务列表的存储。它们有非常及时的通知机制来通知服务消费者服务列表发生了变更。那我们该如何使用 Redis 来做服务发现呢?
这里我们要再次使用 zset 数据结构,我们使用 zset 来保存单个服务列表。多个服务列表就使用多个 zset 来存储。zset 的 value 和 score 分别存储服务的地址和心跳的时间。服务提供者需要使用心跳来汇报自己的存活,每隔几秒调用一次 zadd。服务提供者停止服务时,使用 zrem 来移除自己。
zadd service_key heartbeat_ts addr
zrem service_key addr
复制代码这样还不够,因为服务有可能是异常终止,根本没机会执行钩子,所以需要使用一个额外的线程来清理服务列表中的过期项
zremrangebyscore service_key 0 now_ts - 30 # 30s 都没来心跳
复制代码接下来还有一个重要的问题是如何通知消费者服务列表发生了变更,这里我们同样使用版本号轮询机制。当服务列表变更时,递增版本号。消费者通过轮询版本号的变化来重加载服务列表。
if zadd() > 0 || zrem() > 0 || zremrangebyscore() > 0:
incr service_version_key
复制代码但是还有一个问题,如果消费者依赖了很多的服务列表,那么它就需要轮询很多的版本号,这样的 IO 效率会比较低下。这时我们可以再增加一个全局版本号,当任意的服务列表版本号发生变更时,递增全局版本号。这样在正常情况下消费者只需要轮询全局版本号就可以了。当全局版本号发生变更时再挨个比对依赖的服务列表的子版本号,然后加载有变更的服务列表。
位图
掌阅的签到系统做的比较早,当时用户量还没有上来,设计上比较简单,就是将用户的签到状态用 Redis的 hash 结构来存储,签到一次就在 hash 结构里记录一条,签到有三种状态,未签到、已签到和补签,分别是 0、1、2 三个整数值。
hset sign:${user_id} 2019-01-01 1
hset sign:${user_id} 2019-01-02 1
hset sign:${user_id} 2019-01-03 2
...
复制代码这非常浪费用户空间,到后来签到日活过千万的时候,Redis 存储问题开始凸显,直接将内存飚到了 30G+,我们线上实例通常过了 20G 就开始报警,30G 已经属于严重超标了。
这时候我们就开始着手解决这个问题,去优化存储。我们选择了使用位图来记录签到信息,一个签到状态需要两个位来记录,一个月的存储空间只需要 8 个字节。这样就可以使用一个很短的字符串来存储用户一个月的签到记录。
优化后的效果非常明显,内存直接降到了 10 个G。因为查询整个月的签到状态 API 调用的很频繁,所以接口的通信量也跟着小了很多。
但是位图也有一个缺点,它的底层是字符串,字符串是连续存储空间,位图会自动扩展,比如一个很大的位图 8m 个位,只有最后一个位是 1,其它位都是零,这也会占用1m 的存储空间,这样的浪费非常严重。
所以呢就有了咆哮位图这个数据结构,它对大位图进行了分段存储,全位零的段可以不用存。另外还对每个段设计了稀疏存储结构,如果这个段上置 1 的位不多,可以只存储它们的偏移量整数。这样位图的存储空间就得到了非常显著的压缩。
这个咆哮位图在大数据精准计数领域非常有价值,感兴趣的同学可以了解一下。
模糊计数
前面提到这个签到系统,如果产品经理需要知道这个签到的日活月活怎么办呢?通常我们会直接甩锅——请找数据部门。但是数据部门的数据往往不是很实时,经常前一天的数据需要第二天才能跑出来,离线计算是通常是定时的一天一次。那如何实现一个实时的活跃计数?
最简单的方案就是在 Redis 里面维护一个 set 集合,来一个用户,就 sadd 一下,最终集合的大小就是我们需要的 UV 数字。但是这个空间浪费很严重,仅仅为了一个数字要存储这样一个庞大的集合似乎非常不值当。那该怎么办?
这时你就可以使用 Redis 提供的 HyperLogLog 模糊计数功能,它是一种概率计数,有一定的误差,误差大约是 0.81%。但是空间占用很小,其底层是一个位图,它最多只会占用 12k 的存储空间。而且在计数值比较小的时候,位图使用稀疏存储,空间占用就更小了。
# 记录用户
pfadd sign_uv_${day} user_id
# 获取记录数量
pfcount sign_uv_${day}
复制代码微信公众号文章的阅读数可以使用它,网页的 UV 统计它都可以完成。但是如果产品经理非常在乎数字的准确性,比如某个统计需求和金钱直接挂钩,那么你可以考虑一下前面提到的咆哮位图。它使用起来会复杂一些,需要提前将用户 ID 进行整数序列化。Redis 没有原生提供咆哮位图的功能,但是有一个开源的 Redis Module 可以拿来即用。
布隆过滤器
最后我们要讲一下布隆过滤器,如果一个系统即将会有大量的新用户涌入时,它就会非常有价值,可以显著降低缓存的穿透率,降低数据库的压力。这个新用户的涌入不一定是业务系统的大规模铺开,也可能是因为来自外部的缓存穿透攻击。
def get_user_state0(user_id):
state = cache.get(user_id)
if not state:
state = db.get(user_id) or {}
cache.set(user_id, state)
return state
def save_user_state0(user_id, state):
cache.set(user_id, state)
db.set_async(user_id, state)
复制代码比如上面就是这个业务系统的用户状态查询接口代码,现在一个新用户过来了,它会先去缓存里查询有没有这个用户的状态数据,因为是新用户,所以肯定缓存里没有。然后它就要去查数据库,结果数据库也没有。如果这样的新用户大批量瞬间涌入,那么可以预见数据库的压力会比较大,会存在大量的空查询。
我们非常希望 Redis 里面有这样的一个 set,它存放了所有用户的 id,这样通过查询这个 set 集合就知道是不是新用户来了。当用户量非常庞大的时候,维护这样的一个集合需要的存储空间是很大的。这时候就可以使用布隆过滤器,它相当于一个 set,但是呢又不同于 set,它需要的存储空间要小的多。比如你存储一个用户 id 需要 64 个字节,而布隆过滤器存储一个用户 id 只需要 1个字节多点。但是呢它存的不是用户 id,而是用户 id 的指纹,所以会存在一定的小概率误判,它是一个具备模糊过滤能力的容器。
当它说用户 id 不在容器中时,那么就肯定不在。当它说用户 id 在容器里时,99% 的概率下它是正确的,还有 1% 的概率它产生了误判。不过在这个案例中,这个误判并不会产生问题,误判的代价只是缓存穿透而已,相当于有 1% 的新用户没有得到布隆过滤器的保护直接穿透到数据库查询,而剩下的 99% 的新用户都可以被布隆过滤器有效的挡住,避免了缓存穿透。
def get_user_state(user_id):
exists = bloomfilter.is_user_exists(user_id)
if not exists:
return {}
return get_user_state0(user_id)
def save_user_state(user_id, state):
bloomfilter.set_user_exists(user_id)
save_user_state0(user_id, state)
复制代码布隆过滤器的原理有一个很好的比喻,那就是在冬天一片白雪覆盖的地面上,如果你从上面走过,就会留下你的脚印。如果地面上有你的脚印,那么就可以大概率断定你来过这个地方,但是也不一定,也许别人的鞋正好和你穿的一模一样。可是如果地面上没有你的脚印,那么就可以 100% 断定你没来过这个地方。
作者:老錢
链接:https://juejin.im/post/5d0f3c2be51d45595319e355
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
支持删除么
目前我们知道布隆过滤器可以支持 add 和 isExist 操作,那么 delete 操作可以么,答案是不可以,例如上图中的 bit 位 4 被两个值共同覆盖的话,一旦你删除其中一个值例如 “tencent” 而将其置位 0,那么下次判断另一个值例如 “baidu” 是否存在的话,会直接返回 false,而实际上你并没有删除它。
如何解决这个问题,答案是计数删除。但是计数删除需要存储一个数值,而不是原先的 bit 位,会增大占用的内存大小。这样的话,增加一个值就是将对应索引槽上存储的值加一,删除则是减一,判断是否存在则是看值是否大于0。
如何选择哈希函数个数和布隆过滤器长度
很显然,过小的布隆过滤器很快所有的 bit 位均为 1,那么查询任何值都会返回“可能存在”,起不到过滤的目的了。布隆过滤器的长度会直接影响误报率,布隆过滤器越长其误报率越小。
另外,哈希函数的个数也需要权衡,个数越多则布隆过滤器 bit 位置位 1 的速度越快,且布隆过滤器的效率越低;但是如果太少的话,那我们的误报率会变高。

k 为哈希函数个数,m 为布隆过滤器长度,n 为插入的元素个数,p 为误报率。
至于如何推导这个公式,我在知乎发布的文章有涉及,感兴趣可以看看,不感兴趣的话记住上面这个公式就行了。
另外,既然你使用布隆过滤器来加速查找和判断是否存在,那么性能很低的哈希函数不是个好选择,推荐 MurmurHash、Fnv 这些。
大Value拆分
Redis 因其支持 setbit 和 getbit 操作,且纯内存性能高等特点,因此天然就可以作为布隆过滤器来使用。但是布隆过滤器的不当使用极易产生大 Value,增加 Redis 阻塞风险,因此生成环境中建议对体积庞大的布隆过滤器进行拆分。
拆分的形式方法多种多样,但是本质是不要将 Hash(Key) 之后的请求分散在多个节点的多个小 bitmap 上,而是应该拆分成多个小 bitmap 之后,对一个 Key 的所有哈希函数都落在这一个小 bitmap 上。
作者:YoungChen__
链接:https://www.jianshu.com/p/2104d11ee0a2
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
海量数据和高并发下的 Redis 业务优化实践的更多相关文章
- Redis与Java - 实践
Redis与Java - 实践 标签 : Java与NoSQL Transaction Redis事务(transaction)是一组命令的集合,同命令一样也是Redis的最小执行单位, Redis保 ...
- PHP+Redis链表解决高并发下商品超卖问题
目录 实现原理 实现步骤 上一篇文章聊了一下使用Redis事务来解决高并发商品超卖问题,今天我们来聊一下使用Redis链表来解决高并发商品超卖问题. 实现原理 使用redis链表来做,因为pop操作是 ...
- php结合redis实现高并发下的抢购、秒杀功能
抢购.秒杀是如今很常见的一个应用场景,主要需要解决的问题有两个:1 高并发对数据库产生的压力2 竞争状态下如何解决库存的正确减少("超卖"问题)对于第一个问题,已经很容易想到用缓存 ...
- (高级篇)php结合redis实现高并发下的抢购、秒杀功能
抢购.秒杀是如今很常见的一个应用场景,主要需要解决的问题有两个:1 高并发对数据库产生的压力2 竞争状态下如何解决库存的正确减少("超卖"问题)对于第一个问题,已经很容易想到用缓存 ...
- php结合redis实现高并发下的抢购、秒杀功能 (转载)
抢购.秒杀是如今很常见的一个应用场景,主要需要解决的问题有两个: 1 高并发对数据库产生的压力 2 竞争状态下如何解决库存的正确减少("超卖"问题) 对于第一个问题,已经很容易想到 ...
- redis实现高并发下的抢购/秒杀功能
之前写过一篇文章,高并发的解决思路(点此进入查看),今天再次抽空整理下实际场景中的具体代码逻辑实现吧:抢购/秒杀是如今很常见的一个应用场景,那么高并发竞争下如何解决超抢(或超卖库存不足为负数的问题)呢 ...
- PHP和Redis实现在高并发下的抢购及秒杀功能示例详解
抢购.秒杀是平常很常见的场景,面试的时候面试官也经常会问到,比如问你淘宝中的抢购秒杀是怎么实现的等等. 抢购.秒杀实现很简单,但是有些问题需要解决,主要针对两个问题: 一.高并发对数据库产生的压力二. ...
- 【转】php结合redis实现高并发下的抢购、秒杀功能
抢购.秒杀是如今很常见的一个应用场景,主要需要解决的问题有两个:1 高并发对数据库产生的压力2 竞争状态下如何解决库存的正确减少("超卖"问题)对于第一个问题,已经很容易想到用缓存 ...
- php 结合redis实现高并发下的抢购、秒杀功能
抢购.秒杀是如今很常见的一个应用场景,主要需要解决的问题有两个:1 高并发对数据库产生的压力2 竞争状态下如何解决库存的正确减少("超卖"问题)对于第一个问题,已经很容易想到用缓存 ...
随机推荐
- logback导入依赖 NoSuchMethodException
1.我遇到的问题是Spring版本和logback低版本冲突的问题 如何解决:把logback.classic和logback.core等依赖换成1.2.2以上版本的依赖
- 【Python之路】特别篇--Python内置函数
abs() 求绝对值 i = abs(-100) print(i) # 100 all() 循环里面的参数 如果每个元素都为真,那么all返回值为真 假: 0 False None "&q ...
- 【Python之路】特别篇--Python装饰器
前情提要 1. 作用域 在python中,函数会创建一个新的作用域.python开发者可能会说函数有自己的命名空间,差不多一个意思.这意味着在函数内部碰到一个变量的时候函数会优先在自己的命名空间里面去 ...
- [Docker]docker搭建私有仓库(ssl、身份认证)
docker搭建私有仓库(ssl.身份认证) 环境:CentOS 7.Docker 1.13.1 CentOS 7相关: https://www.cnblogs.com/ttkl/p/11041124 ...
- Struts增删改查
1.导入相关的pom依赖(struts.自定义标签库的依赖) <dependency> <groupId>jstl</groupId> <artifactId ...
- NOI2019 游记
day-1 广二真好看QAQ (要是我也能在这里读书就好了) 提供的餐饮好评QAQ 发现室友是雅礼集训时候的室友,衡水小姐姐zyn. 但是寝室没有网没有信号没有桌子真的不良心啊...... 发现小卖部 ...
- Latex里引用多个公式,如何将公式合并?
如果是想要的效果:(1)-(3),怎么操作?类似于用\cite引用多个文献那样吗? 1. \eqref{lable 1, lable 2, label 3}? 得到的结果:3个问号 ??? 2.\eq ...
- 2、记录代码----Ajax
$.ajax({ url:'/content-engine/index.php/tracker/confirmSendEmail', async: false, //默认为true,同意异步传输 da ...
- koa 基础(十)原生node.js 在 koa 中获取表单提交的数据
1.app.js // 引入模块 const Koa = require('koa'); const router = require('koa-router')(); /*引入是实例化路由 推荐*/ ...
- 一句话说明Facbook React证书的矛盾点
这项专利授权说,如果您要使用我们根据这项授权发布的软件,假如您因为专利侵权而提起诉讼,您将失去我们的专利许可.