SIGAI深度学习第六集 受限玻尔兹曼机
讲授玻尔兹曼分布、玻尔兹曼机的网络结构、实际应用、训练算法、深度玻尔兹曼机等。受限玻尔兹曼机(RBM)是一种概率型的神经网络。和其他神经网络的区别:神经网络的输出是确定的,而RBM的神经元的输出值是不确定的,以某种概率取到某一个值、以另一种概率取到另一个值,神经元的输出值。各个神经元的输入值服从某种概率分布,所有神经元的输出值服从玻尔兹曼分布。
大纲:
玻尔兹曼分布
网络结构
计算隐藏单元的值
用于特征提取
训练算法
深度玻尔兹曼机
本集总结
玻尔兹曼分布:
玻尔兹曼分布是统计物理中的一种概率分布,描述系统处于某种状态x的概率分布: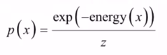 ,z是归一化因子,即x分布的概率之和为1,x是离散型随机变量。
,z是归一化因子,即x分布的概率之和为1,x是离散型随机变量。
网络结构:
可见单元-输入数据(已知)
隐藏单元-设计得到的结果
二部图-图的节点集合被划分成两个不相交的子集,这两个子集内的节点之间没有边连接,子集之间的节点之间有边连接,子集之间的节点之间有边连接。
可见单元和隐藏单元的值服从玻尔兹曼机分布(v是可见单元,h是隐藏单元):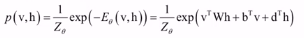 ,其中能量由状态(可见单元v和隐藏单元h的值)决定定义:
,其中能量由状态(可见单元v和隐藏单元h的值)决定定义: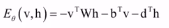 ,归一化因子:
,归一化因子: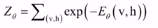
RBM特征自动提取任务:根据v的值得到模型的参数W、h确定之后,根据p(v,h)求出h的值和对应的概率分布(只取0或1的值),这些h的概率取值组成的向量[0,1,0,0,1,...]就是提取出来的特征向量。
受限玻尔兹曼机的三个要点:
1.随机性的神经网络,每个神经元以某种概率分布取值,只取0或1,如取1概率0.3,或0概率0.7。
2.由可见单元和隐藏单元组成二部图,即连接受限。
3.所有神经元v、h的值(0或1)的取值概率服从玻尔兹曼分布。
实际例子:即v和h的离散型概率分布,每一行表示已知输入向量和一个特征向量和特征向量取该值时的概率。
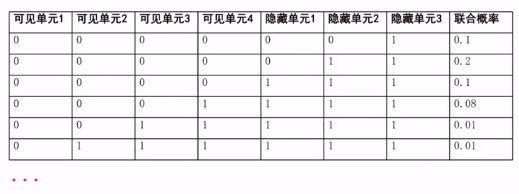
计算隐藏单元的条件:
v一般是输入数据X,h是从X提出的一个特征向量Y,即给定一个输入X提出的特征向量不是确定的有很多可能,即Y服从某个概率分布,因此要求(v,h)概率分布。
计算隐藏单元的值:实际使用时,给定可见变量的值,根据模型参数可以得到隐藏变量的条件概率密度函数,根据条件概率的计算公式: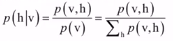 ,将p(v,h)的定义带入上式得:
,将p(v,h)的定义带入上式得:
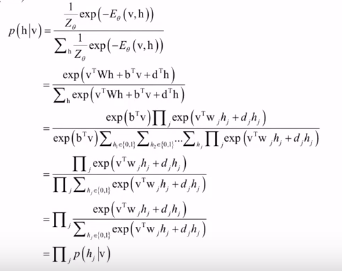
一旦知道了p(v|h),就可以生成特征向量h了。
计算单个隐藏单元的条件概率:
隐含节点之间没有连接,因此这些随机变量是相互独立的,即p(h|v)=p(h1|v)...p(hn|v)。
已知可见变量时某一个隐含变量的值为1的概率:
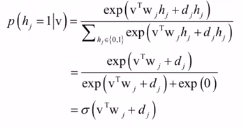
会发现该概率服从逻辑斯蒂回归预测函数,二分类问题。
用于特征提取:
可见单元作为输入数据,隐藏单元作为特征向量
计算隐藏层神经元的激励能量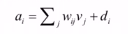
计算该隐藏单元的条件概率值,即状态为1的概率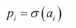
以pi的概率将隐藏层神经元的状态值设置为1,以1-pi的概率将其设置为0。
训练算法:
P(v,h)~(W,b,d),一般概率分布参数值用最大似然估计,但是这里h不知道,因此不可以用,这里用Contrastive Divergence算法,此算法用的不多不必深究。

深度玻尔兹曼机:
同深层自动编码器类似,可以将多个受限玻尔兹曼机层叠加起来使用,通过多层的受限玻尔兹曼机,可以完成数据在不同层次上的特征提取和抽象。
v——>h——>v——>h——>...,一个层的h层作为一次层v的输入值,训练时,也是从前往后逐层训练。
本集总结:
自动编码器、受限玻尔兹曼机,在实际应用中用的很少了,主要是深度学习发展早期的理论性的方法,只需记住他们的精髓就行了。
SIGAI深度学习第六集 受限玻尔兹曼机的更多相关文章
- SIGAI深度学习第四集 深度学习简介
讲授机器学习面临的挑战.人工特征的局限性.为什么选择神经网络.深度学习的诞生和发展.典型的网络结构.深度学习在机器视觉.语音识别.自然语言处理.推荐系统中的应用 大纲: 机器学习面临的挑战 特征工程的 ...
- SIGAI深度学习第八集 卷积神经网络2
讲授Lenet.Alexnet.VGGNet.GoogLeNet等经典的卷积神经网络.Inception模块.小尺度卷积核.1x1卷积核.使用反卷积实现卷积层可视化等. 大纲: LeNet网络 Ale ...
- SIGAI深度学习第五集 自动编码器
深度学习模型-自动编码器(AE),就是一个神经网络的映射函数,f(x)——>y,把输入的一个原始信号,如图像.声音转换为特征. 大纲: 自动编码器的基本思想 网络结构 损失函数与训练算法 实际使 ...
- SIGAI深度学习第七集 卷积神经网络1
讲授卷积神经网络核心思想.卷积层.池化层.全连接层.网络的训练.反向传播算法.随机梯度下降法.AdaGrad算法.RMSProp算法.AdaDelta算法.Adam算法.迁移学习和fine tune等 ...
- SIGAI深度学习第三集 人工神经网络2
讲授神经网络的理论解释.实现细节包括输入与输出值的设定.网络规模.激活函数.损失函数.初始化.正则化.学习率的设定.实际应用等 大纲: 实验环节: 理论层面的解释:两个方面,1.数学角度,映射函数h( ...
- SIGAI深度学习第一集 机器学习与数学基础知识
SIGAI深度学习课程: 本课程全面.系统.深入的讲解深度学习技术.包括深度学习算法的起源与发展历史,自动编码器,受限玻尔兹曼机,卷积神经网络,循环神经网络,生成对抗网络,深度强化学习,以及各种算法的 ...
- SIGAI深度学习第二集 人工神经网络1
讲授神经网络的思想起源.神经元原理.神经网络的结构和本质.正向传播算法.链式求导及反向传播算法.神经网络怎么用于实际问题等 课程大纲: 神经网络的思想起源 神经元的原理 神经网络结构 正向传播算法 怎 ...
- 深度学习(六)keras常用函数学习
原文作者:aircraft 原文链接:https://www.cnblogs.com/DOMLX/p/9769301.html Keras是什么? Keras:基于Theano和TensorFlow的 ...
- SIGAI机器学习第十六集 支持向量机3
讲授线性分类器,分类间隔,线性可分的支持向量机原问题与对偶问题,线性不可分的支持向量机原问题与对偶问题,核映射与核函数,多分类问题,libsvm的使用,实际应用 大纲: 多分类问题libsvm简介实验 ...
随机推荐
- Linux下安装redis 3.0及C语言中客户端实现demo
1.获取安装文件 wget http://download.redis.io/redis-stable.tar.gz 2.解压文件 tar xzvf redis-stable.tar.gz 3.进入目 ...
- 把cgrep mgrep集成到bashrc
https://android.googlesource.com/platform/build/+/android-4.4.3_r1/envsetup.sh 在~/.bashrc里面增加: #Andr ...
- python3 字符集的应用
python3的字符集测试 s_test=u"严" print(s_test.encode('gbk')) print([s_test]) #print(s_test[]) #pr ...
- 利用Python进行数据分析_Pandas_汇总和计算描述统计
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. In [1]: import numpy as np In [2]: impo ...
- 缓冲区Buffer和缓存区Cache的区别
1.buffer 将数据写入到内存里,这个数据的内存空间在Linux系统里一般被称为缓冲区(buffer),例如:写入到内存buffer缓冲区,即写缓冲. 为了提高写操作性能,数据在写入最终介质或下一 ...
- zcat +文件名.gz | grep "查找内容"
linux gz查看 zcat +文件名.gz | grep "查找内容" 解压 rar x xxxx.rar
- redis哈希表数据类型键的设置
命令名称:hset 语法:hset key field value 功能: 1)将哈希表key中的域field的值设为value. 2)如果key不存在,一个新的哈希表被创建并进行hset操作. 3) ...
- 使用vue-cli创建vue工程
在Windows环境下,打开命令行窗口,跳转至想创建工程的路径. 如:D:\MyWork\22_Github\rexel-cn\rexel-jarvis 创建vue工程,命令:vue create r ...
- Shell脚本基础学习
Shell脚本基础学习 当你在类Unix机器上编程时, 或者参与大型项目如k8s等, 某些框架和软件的安装都是使用shell脚本写的. 学会基本的shell脚本使用, 让你走上人生巅峰, 才怪. 学会 ...
- pcntl
<?php function my_pcntl_wait($childProcessCode){ $pid = pcntl_fork(); if($pid>0){ pcntl_wait($ ...