KNN分类算法
K邻近算法、K最近邻算法、KNN算法(k-Nearest Neighbour algorithm):是数据挖掘分类技术中最简单的方法之一
KNN的工作原理
所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。KNN算法的核心思想是如果一个样本在特征空间中的K个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 可以简单理解为:由那些离X最近的K个点来投票决定X归为哪一类。KNN方法在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合
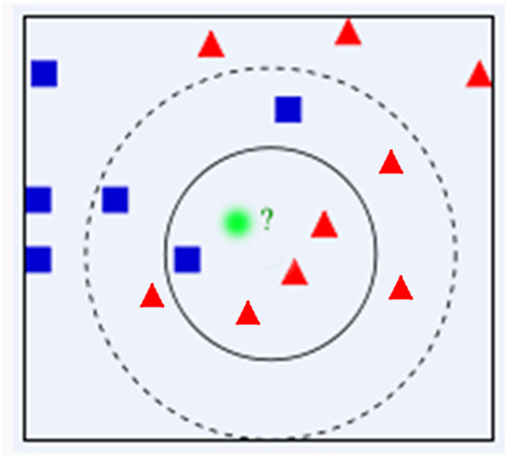
图中有红色三角和蓝色方块两种类别,我们现在需要判断绿色圆点属于哪种类别当k=3时,绿色圆点属于红色三角这种类别;当k=5时,绿色圆点属于蓝色方块这种类别
KNN的算法步骤
- 计算已知类别数据集中的点与当前点之间的距离
- 按照距离递增次序排序
- 选取与当前点距离最小的k个点
- 确定前k个点所在类别的出现频率
- 返回前k个点出现频率最高的类别作为当前点的预测类别
KNN的算法优缺点
优点
- 思想简单
- 易于理解
- 容易实现
- 通过对K的选择可具备丢噪音数据的健壮性
缺点
- 需要大量空间储存所有已知实例
- 算法复杂度高(需要比较所有已知实例与要分类的实例)
- 当其样本分布不平衡时,比如其中一类样本过大(实例数量过多)占主导的时候,新的未知实例容易被归类为这个主导样本,因为这类样本实例的数量过大,但这个新的未知实例实际并未接近目标样本
KNN的Python实现
在了解k-近邻算法的原理及实施步骤之后,我们用python将这些过程实现
Python实现步骤
import numpy as np
import matplotlib.pyplot as plt # 原始集合
# 数据集:特征
raw_data_X = [[3.393533211, 2.331273381],
[3.110073483, 1.781539638],
[1.343808831, 3.368360954],
[3.582294042, 4.679179110],
[2.280362439, 2.866990263],
[7.423436942, 4.696522875],
[5.745051997, 3.533989803],
[9.172168622, 2.511101045],
[7.792783481, 3.424088941],
[7.939820817, 0.791637231]]
# 数据集:所属类别
raw_data_y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
# 训练集合
X_train = np.array(raw_data_X) # 将x转化为数组
y_train = np.array(raw_data_y) # 将y转化为数组
# 要预测的点
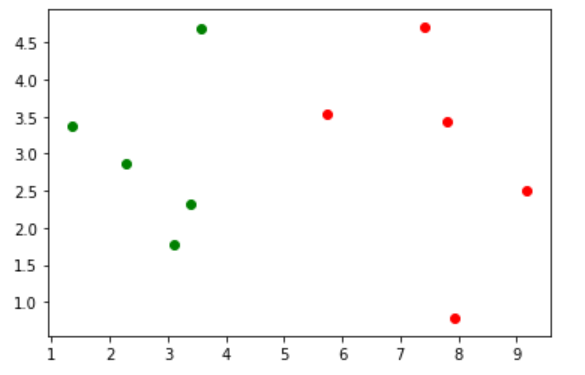
预测
x = np.array([8.093607318, 3.365731514]) # 样本传入
"""
绘制数据集及要预测的点
y_train == 0, 0 --> 返回布尔值
"""
plt.scatter(X_train[y_train == 0, 0], X_train[y_train == 0, 1], color='g') # 绘画0类数据
plt.scatter(X_train[y_train == 1, 0], X_train[y_train == 1, 1], color='r') # 绘画1类数据
plt.show()
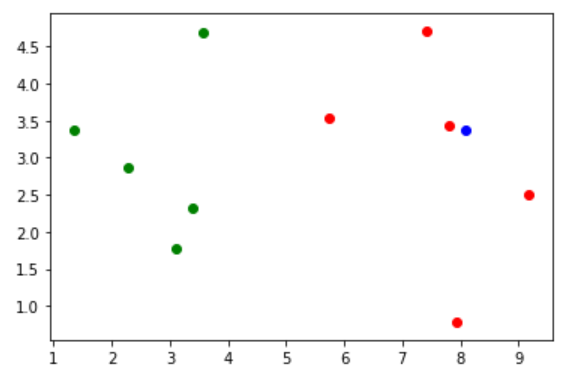 KNN实现过程
KNN实现过程
from math import sqrt
import numpy as np
# 算新的样本点与现有样本点之间的距离
# 对所有数据集循环,再对差的平方求和,即距离
"""
distances = []
for x_train in X_train:
d = sqrt(np.sum((x_train - x)**2))
distances.append(d)
"""
distances = [sqrt(np.sum((x_train - x)**2)) for x_train in X_train] # 最近邻样本个数
k=6
# 返回排序后的结果的索引,也就是距离测试点距离最近的点的排序坐标数组
nearest = np.argsort(distances) # 投票
# 求出距离测试点最近的6个点的类别
topK_y = [y_train[neighbor] for neighbor in nearest[:k]]
# collections的Counter方法可以求出一个数组的相同元素的个数,返回一个dict{key=元素名, value= 元素个数}
from collections import Counter
votes = Counter(topK_y)
# most_common方法求出最多的元素对应的那个键值对
votes.most_common(1)
predict_y = votes.most_common(1)[0][0]
KNN算法封装
import numpy as np
from math import sqrt
from collections import Counter def KNN_classify(X_train,Y_train,x,k):
"""
dist = []
for x_train in X_train:
d = sqrt(np.sum((x_train - x) ** 2))
dist.append(d)
"""
dist = [sqrt(np.sum((x_train - x) ** 2)) for x in x_train ]
nearest = np.argsort(dist); # 取得排序后的索引列表
topk_y = [Y_train[i] for i in nearest[:k]] # 分别取得6个点并获取Y类对应索引的数据
votes = Counter(topk_y)
v = votes.most_common(1)[0][0] # 从产生的字典中获取key,就是对应的类别
return v # 特征
raw_data_x= [
[3.393533211,2.331273381],
[2.110073483,1.781539638],
[1.343808831,3.368360954],
[3.582294042,4.679179110],
[2.280362439,2.866990263],
[7.423436942,4.696522875],
[5.745051997,3.533989803],
[9.172168622,2.511101045],
[7.792783481,3.424088941],
[7.939820817,0.791637231]
]
# 所述类别
raw_data_y = [0,0,0,0,0,1,1,1,1,1]
X_train = np.array(raw_data_x)
y_train = np.array(raw_data_y)
# 要预测的点
x = np.array([8.093607318,3.365731514]) # 调用方法
predict_y = KNN_classify(X_train , y_train , x, 6)
print(predict_y)
机器学习套路
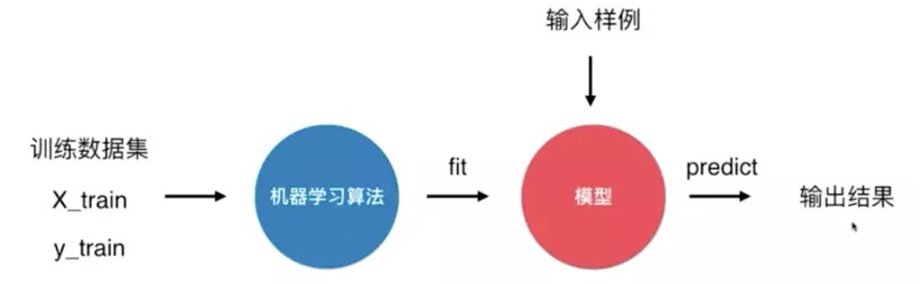
可以说KNN是一个不需要训练过程的算法 K近邻算法是非常特殊的,可以被认为是没有模型的算法 为了和其他算法统一,可以认为训练数据集就是模型
SKLEARN库中的KNN算法实现
from sklearn.neighbors import KNeighborsClassifier
import numpy as np raw_data_x =[[3.393533211, 2.331273381],
[3.110073483, 1.781539638],
[1.343808831, 3.368360954],
[3.582294042, 4.679179110],
[2.280362439, 2.866990263],
[7.423436942, 4.696522875],
[5.745051997, 3.533989803],
[9.172168622, 2.511101045],
[7.792783481, 3.424088941],
[7.939820817, 0.791637231]]
raw_data_y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
# 要预测的点
x = np.array([8.093607318, 3.365731514]) #测试数据 KNN_classfiy = KNeighborsClassifier(n_neighbors=6)
KNN_classfiy.fit(raw_data_x,raw_data_y)
#predict_y = KNN_classfiy.predict(x) #注意要将X转为一个矩阵
predict_y = KNN_classfiy.predict(x.reshape(1,-1))
print(predict_y[0])
封装自己的KNN
import numpy as np
from math import sqrt
from collections import Counter class KNNClassifier:
def __init__(self, k):
"""初始化kNN分类器"""
assert k >= 1, "k must be valid"
self.k = k
self._X_train = None
self._y_train = None def fit(self, X_train, y_train):
"""根据训练数据集X_train和y_train训练kNN分类器""" assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must equal to the size of y_train"
assert self.k <= X_train.shape[0], \
"the size of X_train must be at least k."
self._X_train = X_train
self._y_train = y_train
return self def predict(self, X_predict):
"""给定待预测数据集X_predict,返回标示X_predict的结果向量"""
assert self._X_train is not None and self._y_train is not None, \
"mush fit before predict"
assert self._X_train.shape[1] == X_predict.shape[1], \
"the feature number of x must be equal to X_train"
y_predict = [self._predict(x) for x in X_predict]
return np.array(y_predict) def _predict(self, x):
"""给定单个待预测数据x,返回x的预测结果值"""
distances = [sqrt(np.sum((x_train - x) ** 2)) for x_train in self._X_train]
nearset = np.argsort(distances)
topK_y = [self._y_train[i] for i in nearset[:self.k]]
votes = Counter(topK_y)
return votes.most_common(1)[0][0] kNN_classifier = KNNClassifier(6)
# 特征
raw_data_x = [
[3.393533211, 2.331273381],
[2.110073483, 1.781539638],
[1.343808831, 3.368360954],
[3.582294042, 4.679179110],
[2.280362439, 2.866990263],
[7.423436942, 4.696522875],
[5.745051997, 3.533989803],
[9.172168622, 2.511101045],
[7.792783481, 3.424088941],
[7.939820817, 0.791637231]
]
# 所述类别
raw_data_y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
X_train = np.array(raw_data_x)
y_train = np.array(raw_data_y)
# 要预测的点
x = np.array([8.093607318, 3.365731514])
kNN_classifier.fit(X_train, y_train)
X_predict = x.reshape(1, -1)
kNN_classifier.predict(X_predict)
y_predict = kNN_classifier.predict(X_predict)
print(y_predict[0])
鸢尾花结果评估测试
import numpy as np
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
# 加载数据集
iris = datasets.load_iris();
# 数据
x = iris.data
# 分类标签
y = iris.target
# 训练集,测试集
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.6,random_state=666)
# 分类器
KNN_classfiy = KNeighborsClassifier(n_neighbors=6)
# 训练
KNN_classfiy.fit(x_train,y_train)
y_predict=KNN_classfiy.predict(x_test)
print(sum(y_test==y_predict)/len(y_test))
数据归一化处理
推荐一个在线公式编辑器:http://latex.codecogs.com/eqneditor/editor.php
如果计算两点间的距离,发现样本间的距离被时间所主导。解决方案:将所有的数据映射到同一尺度
- 最终归一化:把所有数据映射到0-1之间
$x_{scale}=\frac{x-x_{min}}{x_{max}-x_{min}}$
适用于分布有明显边界的情况
- 均值方差归一化:把所有数据归一到均值为0方差为1的分布中
数据分布没有明显边界,有可能存在极端数据值
$x_{scale}=\frac{x-x_{mean}}{S}$
划分训练集和测试集
前面概述部分我们有提到,为了测试分类器的效果,我们可以把原始数据集分为训练集和测试集两部分,训练集用来训练模型,测试集用来验证模型准确率。
关于训练集和测试集的切分函数,Scikit Learn官网上也有相应的函数比如model selection 类中的train_test_split 函数也可以完成训练集和测试集的切分。
通常来说,我们只提供已有数据的90%作为训练样本来训练模型,其余10%的数据用来测试模型。这里需要注意的10%的测试数据一定要是随机选择出来的,由于海伦提供的数据并没有按照特定的目的来排序,所以我们这里可以随意选择10%的数据而不影响其随机性
算法总结
k-近邻
算法功能 分类(核心),回归
|
算法类型 |
有监督学习 - 惰性学习,距离类模型 |
|
包含数据标签y,且特征空间中至少包含k个训练样本(k>=1) |
|
|
数据输入 |
特征空间中各个特征的量纲需统一,若不统一则需要进行归一化处理 |
|
自定义的超参数k (k>=1) |
|
|
模型输出 |
在KNN分类中,输出是标签中的某个类别 |
|
在KNN回归中,输出是对象的属性值,该值是距离输入的数据最近的k个训练样本标签的平均值 |
优点
- 简单好用,容易理解,精度高,理论成熟,既可以用来做分类也可以用来做回归
- 可用于数值型数据和离散型数据
- 无数据输入假定
- 适合对稀有事件进行分类
缺点
- 计算复杂性高;空间复杂性高
- 计算量太大,所以一般数值很大的时候不用这个,但是单个样本又不能太少,否则容易发生误分
- 样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少)
- 可理解性比较差,无法给出数据的内在含义
KNN分类算法的更多相关文章
- knn分类算法学习
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一.该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的 ...
- KNN分类算法实现手写数字识别
需求: 利用一个手写数字“先验数据”集,使用knn算法来实现对手写数字的自动识别: 先验数据(训练数据)集: ♦数据维度比较大,样本数比较多. ♦ 数据集包括数字0-9的手写体. ♦每个数字大约有20 ...
- KNN分类算法及python代码实现
KNN分类算法(先验数据中就有类别之分,未知的数据会被归类为之前类别中的某一类!) 1.KNN介绍 K最近邻(k-Nearest Neighbor,KNN)分类算法是最简单的机器学习算法. 机器学习, ...
- 机器学习---K最近邻(k-Nearest Neighbour,KNN)分类算法
K最近邻(k-Nearest Neighbour,KNN)分类算法 1.K最近邻(k-Nearest Neighbour,KNN) K最近邻(k-Nearest Neighbour,KNN)分类算法, ...
- 后端程序员之路 12、K最近邻(k-Nearest Neighbour,KNN)分类算法
K最近邻(k-Nearest Neighbour,KNN)分类算法,是最简单的机器学习算法之一.由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重 ...
- 在Ignite中使用k-最近邻(k-NN)分类算法
在本系列前面的文章中,简单介绍了一下Ignite的线性回归算法,下面会尝试另一个机器学习算法,即k-最近邻(k-NN)分类.该算法基于对象k个最近邻中最常见的类来对对象进行分类,可用于确定类成员的关系 ...
- KNN分类算法--python实现
一.kNN算法分析 K最近邻(k-Nearest Neighbor,KNN)分类算法可以说是最简单的机器学习算法了.它采用测量不同特征值之间的距离方法进行分类.它的思想很简单:如果一个样本在特征空间中 ...
- OpenCV——KNN分类算法 <摘>
KNN近邻分类法(k-Nearest Neighbor)是一个理论上比较成熟的方法,也是最简单的机器学习算法之一. 这个算法首先贮藏所有的训练样本,然后通过分析(包括选举,计算加权和等方式)一个新样本 ...
- KNN分类算法补充
KNN补充: 1.K值设定为多大? k太小,分类结果易受噪声点影响:k太大,近邻中又可能包含太多的其它类别的点. (对距离加权,可以降低k值设定的影响) k值通常是采用交叉检验来确定(以k=1为基准) ...
随机推荐
- centos7 httpd配置
centos7 httpd配置 标签(空格分隔): 未分类 隐藏server信息 修改httpd.conf 设置,添加如下两行 ServerSignature Off ServerTokens Pro ...
- vue工程中,如何查询用户访问的地理位置 + vue中的jsonp
有一个需求,就是当用户访问你们公司的网站时,需要查到这位用户的地理位置(通过电脑ip来访问) 试了很多方法,感觉使用腾讯的位置服务api最好,返回的信息最全,包括经纬度,国家城市地区等.而其他绝大多数 ...
- mysql数据库之事务与存储过程
事务 什么是事务? 事务是指一些SQL语句的集合,这些语句同时执行成功完成某项功能 事务的CAID特性: 原子性:一个事务的执行是整体性的,要么内部所有语句都执行成功,要么一个都别想成功 一致性:事务 ...
- PHP抽奖代码。亲测可用
$prize_arr = array( '0' => array('id' => 1, 'title' => 'iphone5s', 'v' => 5), '1' => ...
- Kick Start 2019 Round H. Elevanagram
设共有 $N = \sum_{i=1}^{9} A_i$ 个数字.先把 $N$ 个数字任意分成两组 $A$ 和 $B$,$A$ 中有 $N_A = \floor{N/2}$ 个数字,$B$ 中有 $N ...
- 大数据学习(2)- export、source(附带多个服务器一起启动服务器)
linux环境中, A=1这种命名方式,变量作用域为当前线程 export命令出的变量作用域是当前进程及其子进程. 可以通过source 脚本,将脚本里面的变量放在当前进程中 附带自己写的tomcat ...
- 超链接hover切换效果
<!DOCTYPE html> <html> <head> <meta charset="UTF-8" /> <meta na ...
- js循环遍历性能
定length for循环 (有length) 不定length for循环(使用数组length) 不定length for循环(判断数组length是否存在) forEach(Array自带,对某 ...
- 异常-try...catch的方式处理异常2
package cn.itcast_02; /* * A:一个异常 * B:二个异常的处理 * a:每一个写一个try...catch * b:写一个try,多个catch * try{ * ... ...
- 【题解】P3391 文艺平衡树
用pb_ds库中的rope水过去的,忽然发现这玩意能水好多模拟题. 详见这个博客:背景的小姐姐真的好看 声明 #include <ext/rope> using namespace __g ...