Hadoop_03_Hadoop分布式集群搭建
一:Hadoop集群简介:
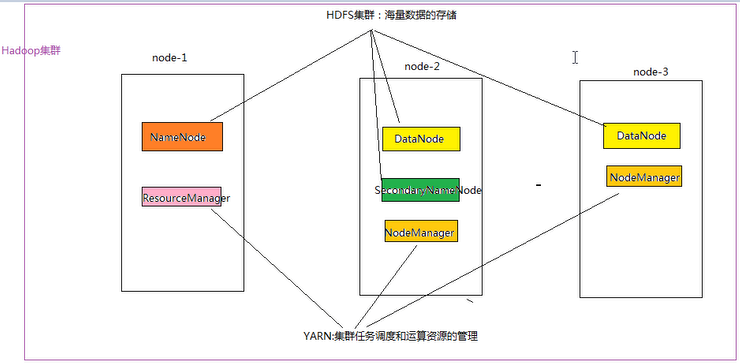
Hadoop 集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起;
HDFS集群:负责海量数据的存储,集群中的角色主要有: NameNode、DataNode、SecondaryNameNode;
YARN集群:负责海量数据运算时的资源调度,集群中的角色主要有: ResourceManager、NodeManager;
那么 Mapreduce 是什么呢:它其实是一个分布式运算编程框架,是应用程序开发包,由用户按照编程规范进行程序开发,
然后打包运行在 HDFS 集群上,并受到 YARN 集群的资源调度管理,由 YARN 为Mapreduce 程序分配运算硬件资源;
二:Hadoop集群部署:
Hadoop包含HDFS集群和YARN集群。部署Hadoop就是部署HDFS和YARN集群
Hadoop部署方式分为三种,Standalone mode(独立模式)、Pseudo-Distributed mode(伪分布式模式)、Cluster rmode
(群集模式),其中前两种都是在单机部署
1. 独立模式又称为单机模式,仅1个机器运行1个java进程,主要用于调试
2. 伪分布模式也是在1个机器上运行 HDFS 的NameNode和DataNode、YARN的ResourceManger和NodeManager,但分别启
动单独的java进程,主要用于调试
3. 集群模式主要用于生产坏境部署,会使用N台主机组成一个Hadoop集群。这种部署模式下,主节点和从节点会分开部署在
不同的机器上
4. 本集群搭建案例,以4节点为例进行搭建,角色分配如下:
| 主机名 | IP | 角色 |
|---|---|---|
| shizhan2 | 192.168.232.201 | Name Node:9000 Resource Manager |
| shizhan3 | 192.168.232.205 | Data Node Node Manager |
| shizhan5 | 192.168.232.207 | Data Node Node Manager |
| shizhan6 | 192.168.232.208 | Data Node Node Manager |
示例图:
三:Hadoop集群安装:
1.上传安装文件到虚拟机:我使用FTP传输
2.解压文件到指定目录: tar -zxvf cenos-6.5-hadoop-2.6.4.tar.gz -C /usr/local/src/
3.修改配置文件:
3.1.hadoop-env.sh:
vi /usr/local/src/hadoop-2.6.4/etc/hadoop/hadoop-env.sh
然后配置JAVA_HOME,可以先用echo $JAVA_HOME命令取得JAVA_HOME的位置:/usr/java/jdk1.7.0_45
export JAVA_HOME=/usr/java/jdk1.7.0_45
3.2.core-site.xml:
vi /usr/local/src/hadoop-2.6.4/etc/hadoop/core-site.xml
<configuration>
<!-- 指定 Hadoop 所使用的文件系统schema(URI),HDFS的老大(NameNode:为客户提供服务,首先被访问)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://shizhan2:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/src/hadoop-2.6.4/hdpdata</value>
</property>
</configuration>
3.3.hdfs-site.xml:
vi /usr/local/src/hadoop-2.6.4/etc/hadoop/hdfs-site.xml
<configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
3.4.mapred-site.xml:
vi /usr/local/src/hadoop-2.6.4/etc/hadoop/mapred-site.xml.template
mv mapred-site.xml.template mapred-site.xml
<configuration>
<!-- 指定mapreduce运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value> //不填写默认local
</property>
</configuration>
3.5.yarn-site.xml:
vi /usr/local/src/hadoop-2.6.4/etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>shizhan2</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
4.将Hadoop拷贝到其他虚拟机:
scp -r /usr/local/src/hadoop-2.6.4 shizhan3:/usr/local/src/
scp -r /usr/local/src/hadoop-2.6.4 shizhan5:/usr/local/src/
scp -r /usr/local/src/hadoop-2.6.4 shizhan6:/usr/local/src/
5.将hadoop添加到环境变量:
vim /etc/proflie
export JAVA_HOME=/usr/java/jdk1.7.0_65
export HADOOP_HOME=/usr/local/src/hadoop-2.6.4
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
6.格式化 HDFS文件系统:(对namenode进行初始化,生成相应目录)
首先把Hadoop配置到环境变量里面去,然后执行命令:hdfs namenode -format (hadoop namenode -format)
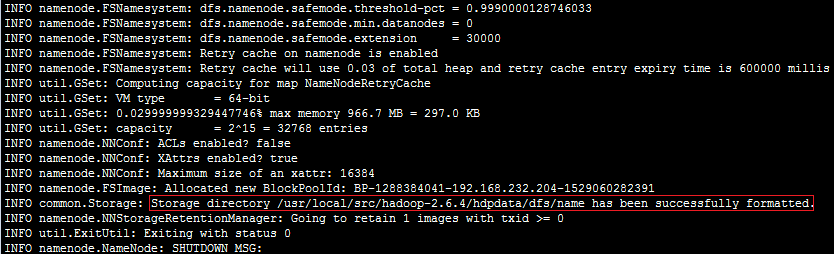
创建了NameNode的工作目录
7.修改NameNode中的slaves配置(供自动化启动脚本使用):vi /usr/local/src/hadoop-2.6.4/etc/hadoop/slaves
shizhan3
shizhan5
shizhan6
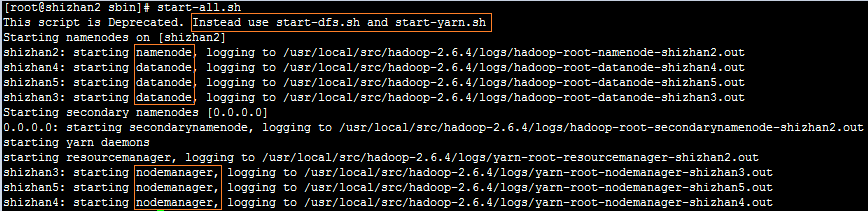
8.在NameNode节点上启动Hadoop:Hadoop/sbin/start-all.sh(先启动HDFS再启动YARN)
分开进行启动:先启动HDFS:sbin/start-dfs.sh ,再启动YARN:sbin/start-yarn.sh
然后在NameNode上运行jps命令,应该包含下面的结果:
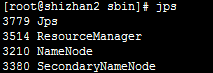
在其他节点上运行jps命令,应该包含下面的结果:
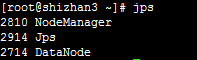
四:配置ssh免登陆:
1.ssh-keygen -t rsa(四个回车),执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
2.将公钥拷贝到要免密登陆的目标机器上:ssh-copy-id shizhan2/shizhan3/shizhan5/shizhan6
五:验证是否启动成功:
HDFS管理界面:访问http://shizhan2:50070,可以看到如下图所示的结果:

YARN管理界面,访问http://shizhan2:8088,可以看到如下图所示的结果:
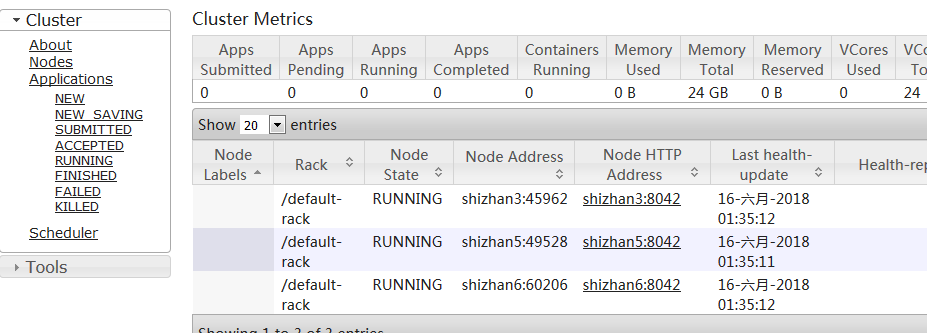
五:出现的问题:
Hadoop dataNode正常启动,但是live Nodes中确缺少节点:
解决方案:修改vi /usr/local/src/hadoop-2.6.4/etc/hadoop/core-site.xml配置文件
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/src/hadoop-2.6.4/hdpdata</value>
</property>
之前因为配置的数据存放路径相同,所以报告中认为只有一个DataNode,所以在Web控制台dataNodes数目显示不全;
Hadoop_03_Hadoop分布式集群搭建的更多相关文章
- Hadoop上路-01_Hadoop2.3.0的分布式集群搭建
一.配置虚拟机软件 下载地址:https://www.virtualbox.org/wiki/downloads 1.虚拟机软件设定 1)进入全集设定 2)常规设定 2.Linux安装配置 1)名称类 ...
- hadoop伪分布式集群搭建与安装(ubuntu系统)
1:Vmware虚拟软件里面安装好Ubuntu操作系统之后使用ifconfig命令查看一下ip; 2:使用Xsheel软件远程链接自己的虚拟机,方便操作.输入自己ubuntu操作系统的账号密码之后就链 ...
- Hadoop分布式集群搭建
layout: "post" title: "Hadoop分布式集群搭建" date: "2017-08-17 10:23" catalog ...
- hbase分布式集群搭建
hbase和hadoop一样也分为单机版.伪分布式版和完全分布式集群版本,这篇文件介绍如何搭建完全分布式集群环境搭建. hbase依赖于hadoop环境,搭建habase之前首先需要搭建好hadoop ...
- 分布式实时日志系统(四) 环境搭建之centos 6.4下hbase 1.0.1 分布式集群搭建
一.hbase简介 HBase是一个开源的非关系型分布式数据库(NoSQL),它参考了谷歌的BigTable建模,实现的编程语言为 Java.它是Apache软件基金会的Hadoop项目的一部分,运行 ...
- kafka系列二:多节点分布式集群搭建
上一篇分享了单节点伪分布式集群搭建方法,本篇来分享一下多节点分布式集群搭建方法.多节点分布式集群结构如下图所示: 为了方便查阅,本篇将和上一篇一样从零开始一步一步进行集群搭建. 一.安装Jdk 具体安 ...
- MinIO 分布式集群搭建
MinIO 分布式集群搭建 分布式 Minio 可以让你将多块硬盘(甚至在不同的机器上)组成一个对象存储服务.由于硬盘分布在不同的节点上,分布式 Minio 避免了单点故障. Minio 分布式模式可 ...
- 阿里云ECS服务器部署HADOOP集群(二):HBase完全分布式集群搭建(使用外置ZooKeeper)
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建,多添加了一个 datanode 节点 . 1 节点环境介绍: 1.1 环境介绍: 服务器:三台阿里 ...
- 阿里云ECS服务器部署HADOOP集群(三):ZooKeeper 完全分布式集群搭建
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建,多添加了一个 datanode 节点 . 1 节点环境介绍: 1.1 环境介绍: 服务器:三台阿里 ...
随机推荐
- CentOS7或CentOS8 安装VirtualBox Guest Addon缺少kernel-headers的解决办法
CentOS7或CentOS8 在Oracle VM VirtualBox中安装Guest Addon时,如果缺少kernel-headers和相应的编译库,会提示出错. "kernel h ...
- React Native使用Mobx总结
参考博客: http://www.jianshu.com/p/505d9d9fe36a 这是我看的学习Mobx目前为止觉得最详细学习的博客了. 下面只是记录下我的学习和一些简单的使用: 需要引入 ...
- SQL Server 中 ROWLOCK 行级锁
一.ROWLOCK的使用 1.ROWLOCK行级锁确保,在用户取得被更新的行,到该行进行更新,这段时间内不被其它用户所修改.因而行级锁即可保证数据的一致性,又能提高数据操作的并发性. 2.ROWLOC ...
- 论文阅读 | Text Processing Like Humans Do: Visually Attacking and Shielding NLP Systems
[code&data] [pdf] 主要工作 文章首先证明了对抗攻击对NLP系统的影响力,然后提出了三种屏蔽方法: visual character embeddings adversaria ...
- [转帖]云服务器使用CentOS、Debian、Ubuntu的哪个版本
云服务器使用CentOS.Debian.Ubuntu的哪个版本 2018-09-09 12:32:45作者:ywnz稿源:云网牛站 https://ywnz.com/linuxyffq/2986.ht ...
- Linux:shift 命令可以将参数依次向左移动一个位置
在脚本中,命令行参数可以依据其在命令行中的位置来访问.第一个参数是 $1 ,第二个参数 是 $2 ,以此类推. 下面的语句可以显示出前3个命令行参数: echo $1 $2 $3 更为常见的处理方式是 ...
- Linux切换root超级用户问题
具体方法如下: Ubuntu 1.使用终端工具的快捷键Ctrl + Alt +T 打开终端. 2.终端工具打开后如下图所示,操作就在这个窗口中进行 3.切换root用户的的方式一 执行命令 sudo ...
- 【LOJ】#3030. 「JOISC 2019 Day1」考试
LOJ#3030. 「JOISC 2019 Day1」考试 看起来求一个奇怪图形(两条和坐标轴平行的线被切掉了一个角)内包括的点个数 too naive! 首先熟练的转化求不被这个图形包含的个数 -- ...
- java持续添加内容至本地文件
package com.lcc.commons; import com.lcc.commons.dto.FileLogDTO; import java.io.*; import java.util.A ...
- X86逆向6:易语言程序的DIY
易语言程序在中国的用户量还是很大的,广泛用于外挂的开发,和一些小工具的编写,今天我们就来看下如何给易语言程序DIY,这里是用的易语言演示,当然这门技术也是可以应用到任何一门编译型语言中的,只要掌握合适 ...