简单聊聊TiDB中sql优化的一个规则---左连接消除(Left Out Join Elimination)
我们看看 TiDB 一段代码的实现 --- 左外连接(Left Out Join)的消除;
select 的优化一般是这样的过程:

在逻辑执行计划的优化阶段, 会有很多关系代数的规则, 需要将逻辑执行计划(LogicalPlan)树应用到各个规则中, 尝试进行优化改写;
我们看看其中的一条优化规则: outerJoinEliminator
TiDB作为优秀的开源项目, 代码的注释也非常优秀, 里面提到了满足这些条件的 Left Outer Join 可以消除右表;
// tryToEliminateOuterJoin will eliminate outer join plan base on the following rules
// 1. outer join elimination: For example left outer join, if the parent only use the
// columns from left table and the join key of right table(the inner table) is a unique
// key of the right table. the left outer join can be eliminated.
// 2. outer join elimination with duplicate agnostic aggregate functions: For example left outer join.
// If the parent only use the columns from left table with 'distinct' label. The left outer join can
// be eliminated.
我们这里只讨论第一种情况, 第二种情况请您自行查看源码;
我们构造满足第一种情况的查询:
左表:
t1(
id int primary key not null auto_increment,
a int,
b int
);
右表:
t2(
id int primary key not null auto_increment,
a int,
b int
);
查询语句:
select t1.id, t1.a from t1 left join t2 on t1.id = t2.id;
我们看看优化规则之前的逻辑执行计划:
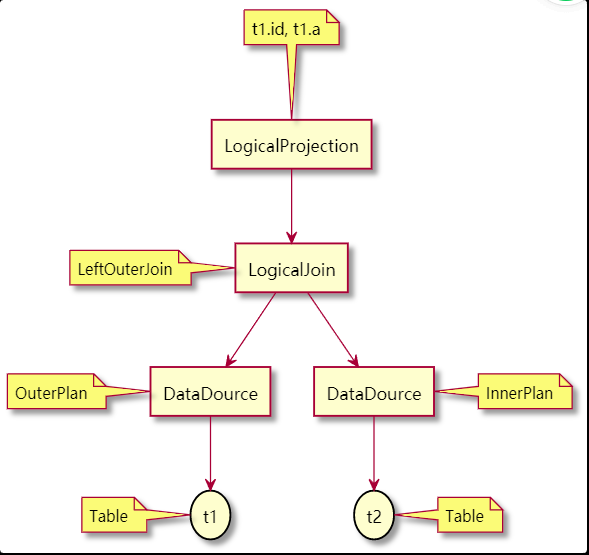
这个执行计划是这样的:
顶层的算子是投影(Projection)操作, 取 t1.id 和 t1.a 这两列;
接下来是 连接(Join) 操作, 类型是: LeftOuterJoin;
接下来左边是 OuterPlan, 左表; 右边是 InnerPlan, 右表;
左边的算子是扫 t1 的数据, 右边的算子是扫 t2 表的数据;
底层的算子将数据返回给上层的算子, 来完成计划的执行;
注, 这种数据自底向上的流动方式有点像火山喷发, 所以这种执行模型叫做火山模型(Volcano);
主要代码逻辑在这里:
outerJoinEliminator::doOptimize
这是一个递归的操作, 不断的获取 parentCols, 并对 LeftOuterJoin 或者 RightOuterJoin 尝试进行消除;
如果是LeftOuterJoin , 尝试消除右表, 如果是RightOuterJoin, 尝试消除左表;
因为我们这里只有 Projection算子 和 LeftOuterJoin算子, 所以代码调用逻辑基本是这样的:
* 获取Projection的列
* 对下面的LeftOuterJoin进行判断
* 获取左表的列: outerPlan.Schema().Columns
* 判断上层 Projection 用到的列是否全部来自左表: o.isColsAllFromOuterTable(parentCols, outerUniqueIDs)
* 获取 Join 连接的列: innerJoinKeys := o.extractInnerJoinKeys(p, innerChildIdx); 这即是右表的 t2.id
* 判断连接的列是否被包含在右表的主键: o.isInnerJoinKeysContainUniqueKey(innerPlan, innerJoinKeys)
* 满足条件, 将 LeftOutJoin 替换掉;
我们展示一下这个转换:

上图中灰色的执行计划会被消除掉;
变成了下面的执行计划:
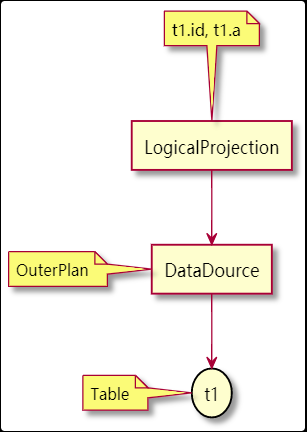
最终, 上面给出的sql 的例子等价于下面的语句:
select t1.id, t1.a from t1;
有兴趣的读者可以看看其他的满足条件的左外连接消除的逻辑, 这里就不讲了;
逻辑优化的过程一般被叫做RBO(rule based optimization);
逻辑规则的优化是基于关系代数的等价推导和证明;
大部分数据库(例如mysql, Oracle, SQLServer)的逻辑优化规则都类似, 可以互相参考;
物理优化的过程一般被叫做CBO(cost based optimization);
不同的数据库的物理优化规则不一定是一样的, 这个可能根据数据和索引的存放特点来进行针对性的处理;
简单聊聊TiDB中sql优化的一个规则---左连接消除(Left Out Join Elimination)的更多相关文章
- sql优化实例(用左连接)
改为 也就是说用左连接代替where条件,这样的话效率会提高很多.
- 简单聊聊java中的final关键字
简单聊聊java中的final关键字 日常代码中,final关键字也算常用的.其主要应用在三个方面: 1)修饰类(暂时见过,但是还没用过); 2)修饰方法(见过,没写过); 3)修饰数据. 那么,我们 ...
- 简单聊聊CSS中的3D技术之“立方体”
简单聊聊CSS中的3D技术之“立方体” 大家好,我是今天的男一号,我叫小博主. 今天来聊一下我在前端“逆战班”学习中遇到的颇为有趣的3D知识.前端学习3周,见识稀疏,在下面的分享中如有不对的地方请大家 ...
- [转帖]关于Java中SQL语句的拼接规则
关于Java中SQL语句的拼接规则 自学demo 的时候遇到的问题 结果应该是 '"+e.getName()+"' 注意 一共有三组标点符号 (除去 方法函数后面的括号) 实现目标 ...
- oracle中sql优化
问题描述:刚开始做项目的时候没啥感觉,只用能出来结果,sql随便写,但是后来用户的数据量达到几万条是,在访问系统,发现很多功能加载都很慢,有的页面一个简单的关联 查询居然要花费30多秒,实在是不能忍, ...
- oracle11g中SQL优化(SQL TUNING)新特性之Adaptive Cursor Sharing (ACS)
1. ACS简介 Oracle Database 11g提供了Adaptive Cursor Sharing (ACS)功能,以克服以往不该共享的游标被共享的可能性.ACS使用两个新指标:sens ...
- Java并发(10)- 简单聊聊JDK中的七大阻塞队列
引言 JDK中除了上文提到的各种并发容器,还提供了丰富的阻塞队列.阻塞队列统一实现了BlockingQueue接口,BlockingQueue接口在java.util包Queue接口的基础上提供了pu ...
- 对oracle中SQL优化的理解
Oracle数据库里SQL优化的终极目标就是要缩短目标SQL语句的执行时间.要达到上述目的,我们通常只有如下三种方法可以选择:1.降低目标SQL语句的资源消耗.2.并行执行目标SQL语句.3.平衡系统 ...
- SQL优化之列裁剪和投影消除
列裁剪 对于没用到的列,则没有必要读取它们的数据去浪费无谓的IO 比如我们有一张表table1,它含有四列数据(a,b,c,d).当我们执行查询select a from table1 where c ...
随机推荐
- python 2.7 环境配置
原文地址:Python 2.7的安装(64位win10) Python 2.7.12 下载地址:https://www.python.org/downloads/ 安装路径D:\Program Fil ...
- Java基础笔试练习(四)
1.编译Java Application 源程序文件将产生相应的字节码文件,这些字节码文件的扩展名为( ). A.java B.class C.html D.exe 答案: B 解析: Java源程序 ...
- (一)SpringBoot Demo之 Hello World
文章目录 最终效果 pom文件编写 编写资源类 编写控制器 运行项目 原文 : https://spring.io/guides/gs/rest-service/ 类型:官网入门指南 要求:JDK1. ...
- 了解CAdoSqlserver
include <vector> 表示引用了vector类, vector是STL中的一种数据结构,或者叫容器,功能相当于数组,但是功能强大很多.vector在C++标准模板库中的部分内容 ...
- LINUX驱动笔记 目录
笔记参考了宋宝华老师的<Linux设备驱动开发详解:基于最新的Linux 4.0内核>以及韦东山老师的嵌入式驱动教程 笔记开发环境: 单板:第一章到第八章使用TINY4412-1611:第 ...
- 生成ftp文件的目录树
依赖 <dependency> <groupId>commons-net</groupId> <artifactId>commons-net</a ...
- netty--buffer分配策略
AdaptiveRecvByteBufAllocator 动态分配buffer大小的类. 如果前一次读取完全填满了分配的缓冲区,它将逐渐增加预期的可读字节数.(增加的方式:初始化类的时候,会预先设置好 ...
- Linux Nginx的权限——访问本地目录报错403
在安装好FastDFS并成功上传图片文件后,根据FastDFS返回的文件地址无法通过HTTP(即浏览器)访问到,报错404或者403. 不管是Error 404还是Error 403,基本都是Ngin ...
- codeforce 849D. Make a Permutation!
D. Make a Permutation! time limit per test 2 seconds memory limit per test 256 megabytes input stand ...
- Linux mount/unmount 挂载和卸载指令
对于Linux用户来讲,不论有几个分区,分别分给哪一个目录使用,它总归就是一个根目录.一个独立且唯一的文件结构 Linux中每个分区都是用来组成整个文件系统的一部分,她在用一种叫做“挂载”的处理方法, ...