IDEA配置Hadoop开发环境&编译运行WordCount程序
有关hadoop及java安装配置请见:https://www.cnblogs.com/lxc1910/p/11734477.html
1、新建Java project:
选择合适的jdk,如图所示:

将工程命名为WordCount。
2、添加WordCount类文件:
在src中添加新的Java类文件,类名为WordCount,代码如下:
- import java.io.IOException;
- import java.util.StringTokenizer;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import org.apache.hadoop.util.GenericOptionsParser;
- public class WordCount {
- public static class TokenizerMapper //定义Map类实现字符串分解
- extends Mapper<Object, Text, Text, IntWritable>
- {
- private final static IntWritable one = new IntWritable(1);
- private Text word = new Text();
- //实现map()函数
- public void map(Object key, Text value, Context context)
- throws IOException, InterruptedException
- { //将字符串拆解成单词
- StringTokenizer itr = new StringTokenizer(value.toString());
- while (itr.hasMoreTokens())
- { word.set(itr.nextToken()); //将分解后的一个单词写入word类
- context.write(word, one); //收集<key, value>
- }
- }
- }
- //定义Reduce类规约同一key的value
- public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>
- {
- private IntWritable result = new IntWritable();
- //实现reduce()函数
- public void reduce(Text key, Iterable<IntWritable> values, Context context )
- throws IOException, InterruptedException
- {
- int sum = 0;
- //遍历迭代values,得到同一key的所有value
- for (IntWritable val : values) { sum += val.get(); }
- result.set(sum);
- //产生输出对<key, value>
- context.write(key, result);
- }
- }
- public static void main(String[] args) throws Exception
- { //为任务设定配置文件
- Configuration conf = new Configuration();
- //命令行参数
- String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
- if (otherArgs.length != 2)
- { System.err.println("Usage: wordcount <in> <out>");
- System.exit(2);
- }
- Job job = Job.getInstance(conf, "word count");//新建一个用户定义的Job
- job.setJarByClass(WordCount.class); //设置执行任务的jar
- job.setMapperClass(TokenizerMapper.class); //设置Mapper类
- job.setCombinerClass(IntSumReducer.class); //设置Combine类
- job.setReducerClass(IntSumReducer.class); //设置Reducer类
- job.setOutputKeyClass(Text.class); //设置job输出的key
- //设置job输出的value
- job.setOutputValueClass(IntWritable.class);
- //设置输入文件的路径
- FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
- //设置输出文件的路径
- FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
- //提交任务并等待任务完成
- System.exit(job.waitForCompletion(true) ? 0 : 1);
- }
- }
3、添加依赖库:
点击 File -> Project Structure -> Modules,选择Dependencies,点击加号,添加以下依赖库:

4、编译生成JAR包:
点击 File -> Project Structure ->Artifacts,点击加号->JAR->from modules with dependencies,
Mainclass选择WordCount类:
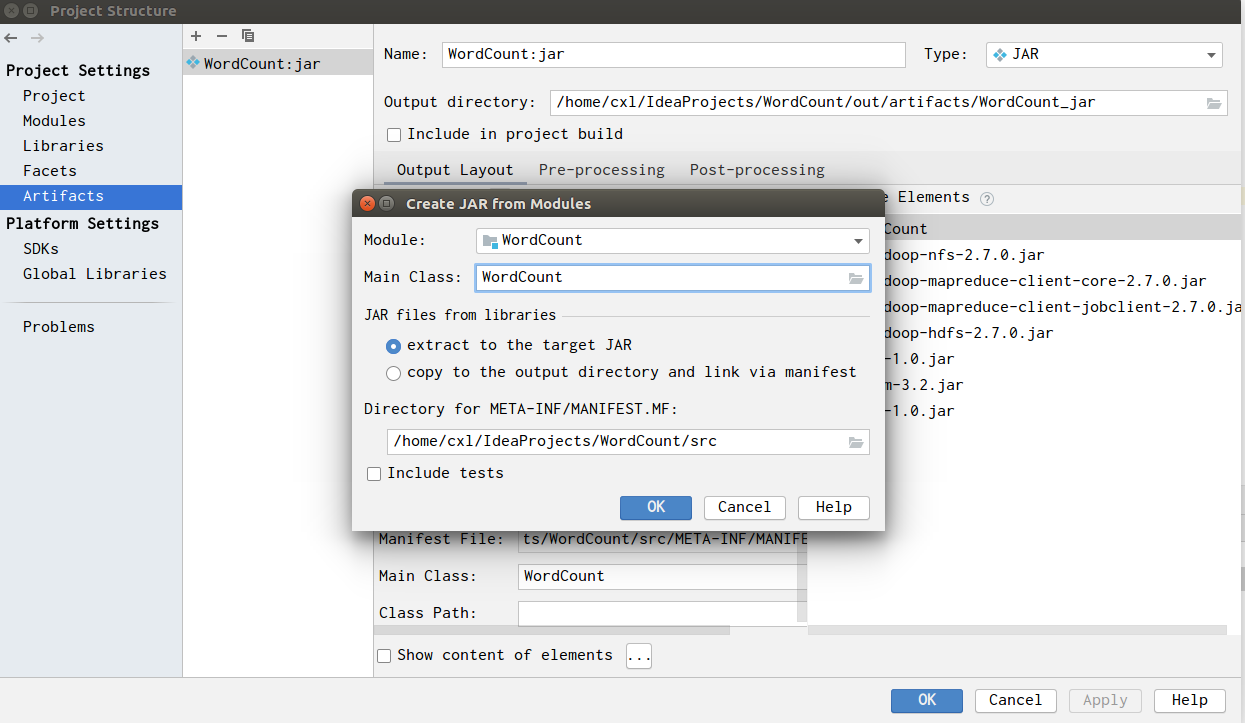
下面开始编译生成JAR包:
点击 build->build Artifacts->build,完成编译后,会发现多出一个目录output.
5、在hadoop系统中运行JAR包:
我之前在hadoop用户下安装了伪分布式的hadoop系统,因此首先把JAR包复制到hadoop用户目录下。
启动hadoop服务:(在hadoop安装目录的sbin文件夹下)
- ./start-all.sh
在hdfs下新建test-in文件夹,并放入file1.txt、file2.txt两个文件,
- hadoop fs -mkdir test-in
- hadoop fs -put file1.txt file2.txt test-in/
执行jar包:
- hadoop jar WordCount.jar test-in test-out
因为之前生成JAR包时设置了主类,所以WordCount.jar后面不需要再加WordCount.
另外需要注意运行JAR包之前hdfs中不能有test-out文件夹。
6、查看运行结果
可通过http://localhost:50070/查看hadoop系统状况,
点击Utilities->Browse the file system即可查看hdfs文件系统:
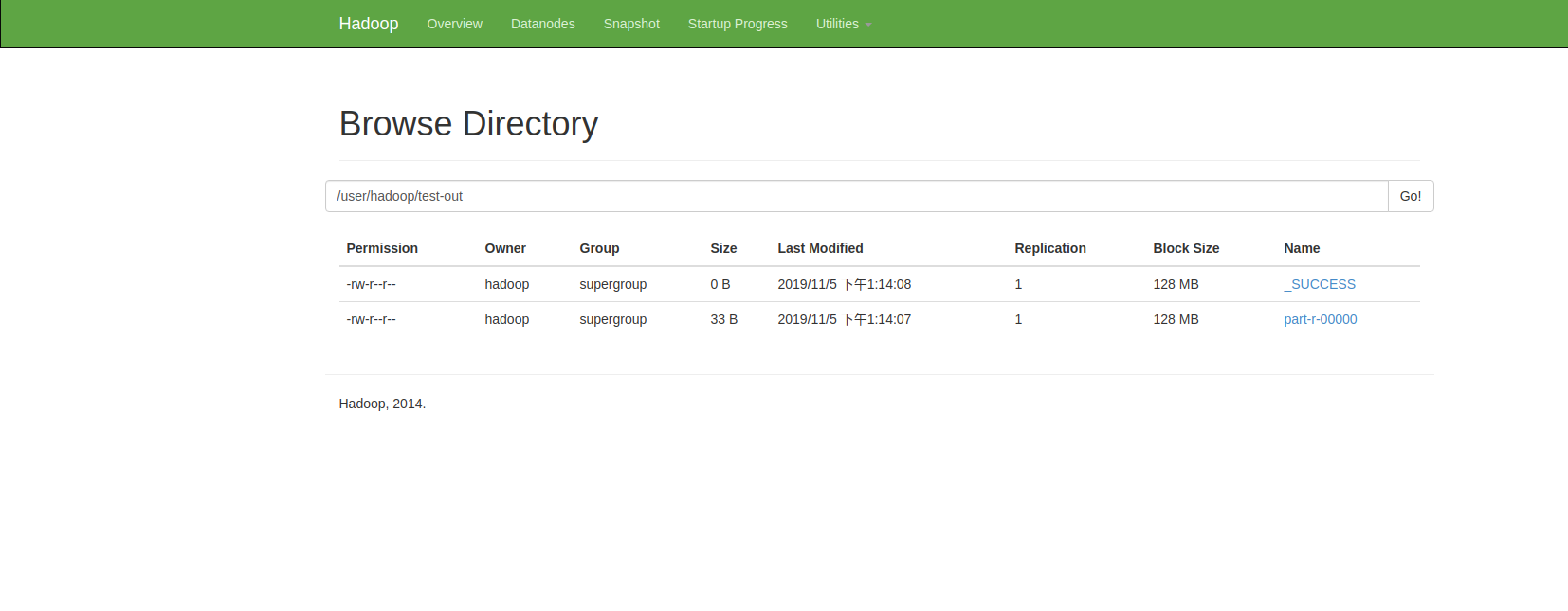
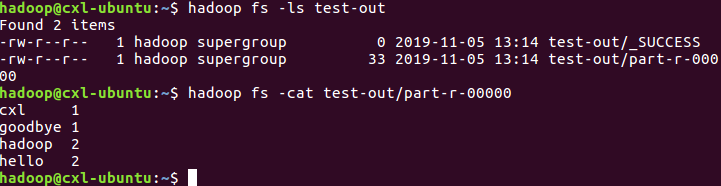
可以看到test-out文件下有输出文件,可通过命令:
- hadoop fs -cat test-out/part-r-
查看文件输出情况:
7、参考
https://blog.csdn.net/chaoping315/article/details/78904970
https://blog.csdn.net/napoay/article/details/68491469
https://blog.csdn.net/ouyang111222/article/details/73105086
IDEA配置Hadoop开发环境&编译运行WordCount程序的更多相关文章
- myeclipse配置hadoop开发环境
1.安装Hadoop开发插件 hadoop安装包contrib/目录下有个插件hadoop-0.20.2-eclipse-plugin.jar,拷贝到myeclipse根目录下/dropins目录下. ...
- Hadoop_配置Hadoop开发环境(Eclipse)
通常我们可以用Eclipse作为Hadoop程序的开发平台. 1) 下载Eclipse 下载地址:http://www.eclipse.org/downloads/ 根据操作系统类型,选择合适的版本 ...
- Eclipse配置Hadoop开发环境
Step 1:选择Hadoop版本对应的Eclipse插件jar包(可自行编译),我的Hadoop版本是hadoop-0.20.2,对应的插件应该是:hadoop-0.20.2-eclipse-plu ...
- Eclipse安装Hadoop插件配置Hadoop开发环境
一.编译Hadoop插件 首先需要编译Hadoop 插件:hadoop-eclipse-plugin-2.6.0.jar,然后才可以安装使用. 第三方的编译教程:https://github.com/ ...
- 配置Hadoop开发环境(Eclipse)
参考博文: http://blog.csdn.net/zythy/article/details/17397153 http://www.tuicool.com/articles/AjUZrq 注意事 ...
- 第五章 MyEclipse配置hadoop开发环境
1.首先要下载相应的hadoop版本的插件,我这里就给2个例子: hadoop-1.2.1插件:http://download.csdn.net/download/hanyongan300/62381 ...
- 分布式集群环境下运行Wordcount程序
1.分布式环境的Hadoop提交作业方式与本地安装的Hadoop作业提交方式相似,但有两点不同: 1)作业输入输出都存储在HDFS 2)本地Hadoop提交作业时将作业放在本地JVM执行,而分布式集群 ...
- (三)配置Hadoop1.2.1+eclipse(Juno版)开发环境,并运行WordCount程序
配置Hadoop1.2.1+eclipse(Juno版)开发环境,并运行WordCount程序 一. 需求部分 在ubuntu上用Eclipse IDE进行hadoop相关的开发,需要在Eclip ...
- 在Fedora18上配置个人的Hadoop开发环境
在Fedora18上配置个人的Hadoop开发环境 1. 背景 文章中讲述了类似于"personalcondor"的一种"personal hadoop" ...
随机推荐
- nginx 反向代理的配置
nginx中的每个server就是一个反向代理配置,可以有多个server(nginx只能处理静态资源) nginx中 server的配置 server { listen 80; server_nam ...
- 2019年6月SAP发布的未来ABAP平台的发展方向
未来ABAP平台将始终是这些产品的技术平台: S/4HANA On-Premises和Cloud将基于一个统一的ABAP codeline: SAP云平台上的ABAP编程环境: 什么是SAP Clou ...
- vue处理换行符
1.处理换行符 <tr class="unread" v-for="(item,index) in DataList" :key="index& ...
- DAY2新手选品原则及供应商选择
一.新手选品原则(主要是为了起量) 1.净利润率高(容易起量) 2.发货方便,售后方便(发货,打包方便,不易破损,退货率低) 3.具有细分市场优势(衣服->古代衣服,论文排版) 4.市场规模够大 ...
- Linux Backup: Hard Disk Clone with "dd"
Most of Windows users may know "Norton Ghost". Norton Ghost is a backup software for har ...
- 从win到多系统
相信有不少电脑爱好者喜欢折腾系统,尤其还是一个小白(感觉多系统强的不要不要的,各种崇拜),然后就走上了深渊. 首先,我一开始也是个win系统的忠实用户,没用过其他系统的我几乎不知道其他系统的存在,反正 ...
- 剑指Offer的学习笔记(C#篇)-- 孩子们的游戏(圆圈中最后剩下的数)
题目描述 每年六一儿童节,牛客都会准备一些小礼物去看望孤儿院的小朋友,今年亦是如此.HF作为牛客的资深元老,自然也准备了一些小游戏.其中,有个游戏是这样的:首先,让小朋友们围成一个大圈.然后,他随机指 ...
- C# EPPlus 导出Excel
一.Excel导出帮助类 /*引用NuGet包 EPPlus*/ /// <summary> /// Excel导出帮助类 /// </summary> public clas ...
- GDI+图像编程
一.Graphics GDI+是GDI(Windows Graphics Device Interface)的后继者,它是.NET Framework为操作图形提供的应用程序编程接口,主要用在窗体上绘 ...
- 简单的JAVAWeb选课系统
该系统管理员可以添加和删除学生.教师,教师可以修改自己信息.添加课程.浏览自己课程,学生可以修改自己的信息.选课.浏览全部课程. 首先展示文件: 然后就是一次展示代码: Guanli包中代码: pac ...