python爬取昵称并保存为csv
代码:
import sys
import io
import re
sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
import requests
from bs4 import BeautifulSoup def html_save(s):
with open('Name.csv','a')as f:
f.write(s+'\n')
# soup = BeautifulSoup(html,'index')
def getName_link():
lst=[]
soup = BeautifulSoup(open('Girl.html'))
for div in soup.find_all('div',{'class':'babynology_textevidence babynology_bg_grey babynology_shadow babynology_radius left overflow_scroll'}):
for strong in div.find_all('strong'):
print(strong.find_all('a')[0].text.replace(' ','').replace(' ','').replace('\n',''))
# print(strong.find_all('a')[0].get('href').replace('\n',''))
i=strong.find_all('a')[0].text.replace(' ','').replace(' ','').replace('\n','')
# j=strong.find_all('a')[0].get('href').replace('\n','')
# lst.append(j)
html_save(i)
# html_save(j)
# print(lst)
# return lst
getName_link()
运行结果:
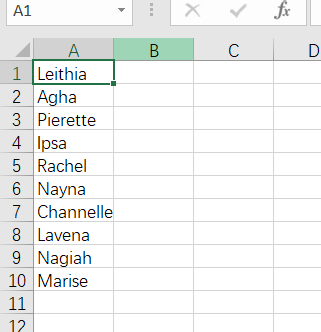
python爬取昵称并保存为csv的更多相关文章
- python爬取信息并保存至csv
import csv import requests from bs4 import BeautifulSoup res=requests.get('http://books.toscrape.com ...
- python爬取网站数据保存使用的方法
这篇文章主要介绍了使用Python从网上爬取特定属性数据保存的方法,其中解决了编码问题和如何使用正则匹配数据的方法,详情看下文 编码问题因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这 ...
- python爬取网站视频保存到本地
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: Woo_home PS:如有需要Python学习资料的小伙伴可以加点 ...
- python爬取当当网的书籍信息并保存到csv文件
python爬取当当网的书籍信息并保存到csv文件 依赖的库: requests #用来获取页面内容 BeautifulSoup #opython3不能安装BeautifulSoup,但可以安装Bea ...
- python爬取某个网站的图片并保存到本地
python爬取某个网站的图片并保存到本地 #coding:utf- import urllib import re import sys reload(sys) sys.setdefaultenco ...
- 票房和口碑称霸国庆档,用 Python 爬取猫眼评论区看看电影《我和我的家乡》到底有多牛
今年的国庆档电影市场的表现还是比较强势的,两名主力<我和我的家乡>和<姜子牙>起到了很好的带头作用. <姜子牙>首日破 2 亿,一举刷新由<哪吒之魔童降世&g ...
- 使用python爬取MedSci上的期刊信息
使用python爬取medsci上的期刊信息,通过设定条件,然后获取相应的期刊的的影响因子排名,期刊名称,英文全称和影响因子.主要过程如下: 首先,通过分析网站http://www.medsci.cn ...
- Python爬取豆瓣指定书籍的短评
Python爬取豆瓣指定书籍的短评 #!/usr/bin/python # coding=utf-8 import re import sys import time import random im ...
- 萌新学习Python爬取B站弹幕+R语言分词demo说明
代码地址如下:http://www.demodashi.com/demo/11578.html 一.写在前面 之前在简书首页看到了Python爬虫的介绍,于是就想着爬取B站弹幕并绘制词云,因此有了这样 ...
随机推荐
- Linux中ps -elf和ps aux的区别
一.前言 Linux下输入命令man ps查看: 加横线是 standard syntax -- 比如ps -elf 不加横线是 BSD syntax -- 比如ps aux To see ...
- 你必须知道的Dockerfile
本篇已加入<.NET Core on K8S学习实践系列文章索引>,可以点击查看更多容器化技术相关系列文章. 一.关于Dockerfile 在Docker中创建镜像最常用的方式,就是使用D ...
- 【docker构建】基于docker构建rabbitmq消息队列管理服务
1. 拉取镜像 # 可以在官网查看版本 [root@VM_0_10_centos wordpress]# docker pull rabbitmq:3.7.7-management 2. 根据拉取的镜 ...
- python通过多线程并获取返回值
以下是多线程获取返回值的一种实现方式 # -*-coding:utf-8-*- from time import ctime, sleep import threading import numpy ...
- Java描述设计模式(02):简单工厂模式
本文源码:GitHub·点这里 || GitEE·点这里 一.生活场景简介 1.引入场景 订餐流程简单描述 1).食品抽象类,规定食品的基础属性操作 2).鱼类,鸡肉类食品类扩展 3).订餐流程类,根 ...
- (五十六)c#Winform自定义控件-瓶子(工业)-HZHControls
官网 http://www.hzhcontrols.com 前提 入行已经7,8年了,一直想做一套漂亮点的自定义控件,于是就有了本系列文章. GitHub:https://github.com/kww ...
- swool安装(centos7)
1:获取swoole https://github.com/swoole/swoole-src/releases http://pecl.php.net/package/swoole http://g ...
- socket经典案例-发送数据
一:客户端向服务端发送数据. 服务端: package com.company.s; import java.io.*; import java.net.ServerSocket; import ja ...
- ArcGIS api for JavaScript 3.27 FindTask查询功能
在ArcGIS API中查询功能是经常使用的,常用的三个查询分别是FindTask,QueryTask,IdentifyTask.它们各自都有自己的特点. 查询功能分为属性查询和空间查询 FindTa ...
- HTML中特殊符号编码对照表,html特殊符号编码都有哪些?
HTML中一些无法打出来的符号可以用相应的代码进行代替显示,本文提供了一些HTML特殊符号相应的代码供开发者参考. 特殊符号 命名实体 十进制编码 特殊符号 命名实体 十进制编码 特殊符号 命名实体 ...