一文看懂 K8s 日志系统设计和实践
上一篇中我们介绍了为什么需要一个日志系统、为什么云原生下的日志系统如此重要以及云原生下日志系统的建设难点,相信DevOps、SRE、运维等同学看了是深有体会的。本篇文章单刀直入,会直接跟大家分享一下如何在云原生的场景下搭建一个灵活、功能强大、可靠、可扩容的日志系统。
需求驱动架构设计
技术架构,是将产品需求转变为技术实现的过程。对于所有的架构师而言,能够将产品需求分析透彻是非常基本也是非常重要的一点。很多系统刚建成没多久就要被推翻,最根本的原因还是没有解决好产品真正的需求。
我所在的日志服务团队在日志这块有近10年的经验,几乎服务阿里内部所有的团队,涉及电商、支付、物流、云计算、游戏、即时通讯、IoT等领域,多年来的产品功能的优化和迭代都是基于各个团队的日志需求变化。
有幸我们最近几年在阿里云上实现了产品化,服务了数以万计的企业用户,包括国内各大直播类、短视频、新闻媒体、游戏等行业Top1互联网客户。产品功能从服务一个公司到服务上万家公司会有质的差别,上云促使我们更加深入的去思考:究竟哪些功能是日志这个平台需要去为用户去解决的,日志最核心的诉求是什么,如何去满足各行各业、各种不同业务角色的需求...
需求分解与功能设计
上一节中我们分析了公司内各个不同角色对于日志的相关需求,总结起来有以下几点:
- 支持各种日志格式、数据源的采集,包括非K8s
- 能够快速的查找/定位问题日志
- 能够将各种格式的半结构化/非结构化日志格式化,并支持快速的统计分析、可视化
- 支持通过日志进行实时计算并获得一些业务指标,并支持基于业务指标实时的告警(其实本质就是APM)
- 支持对于超大规模的日志进行各种维度的关联分析,可接受一定时间的延迟
- 能够便捷的对接各种外部系统或支持自定义的获取数据,例如对接第三方审计系统
- 能够基于日志以及相关的时序信息,实现智能的告警、预测、根因分析等,并能够支持自定义的离线训练方式以获得更好的效果
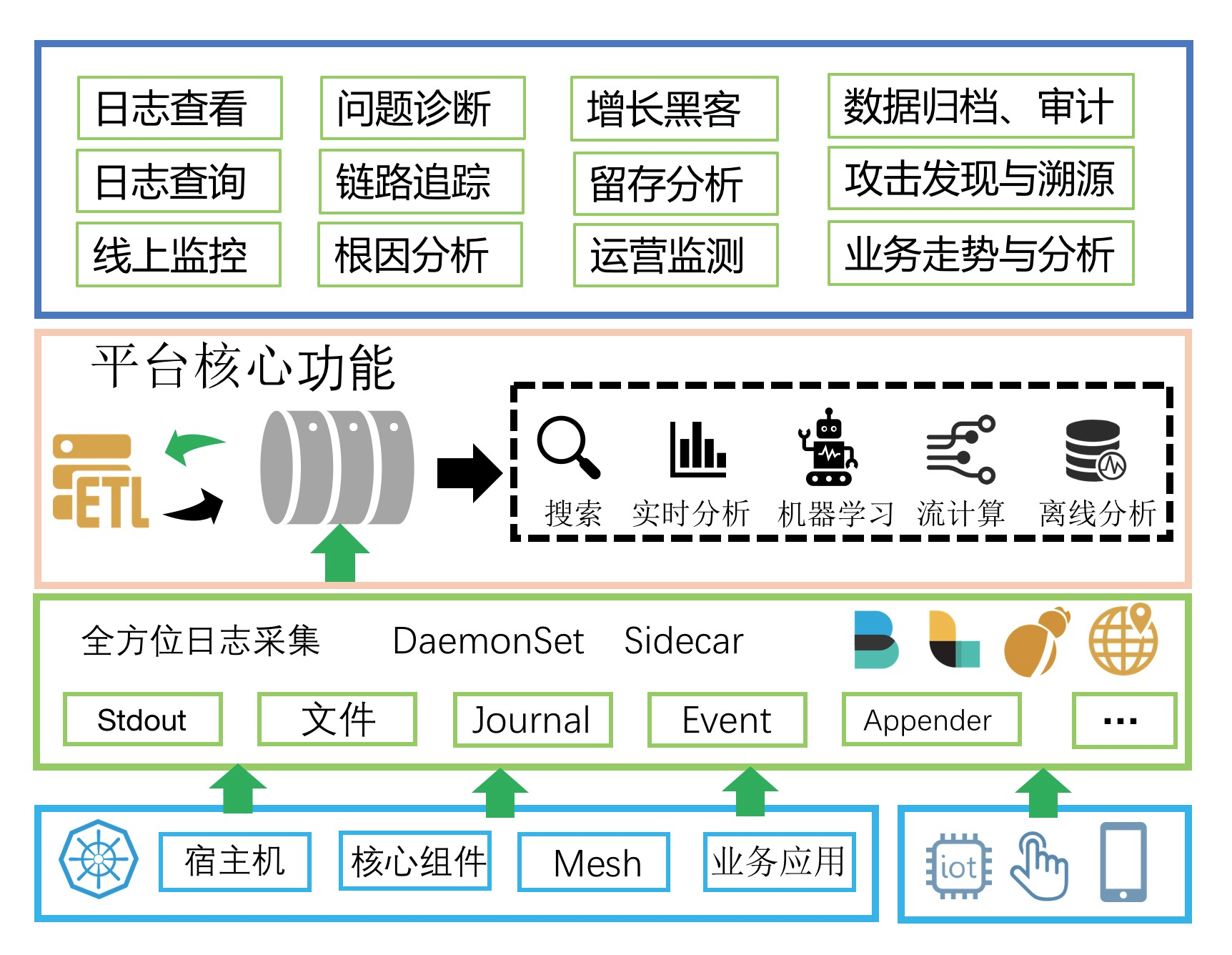
为满足上述这些功能需求,日志平台上必须具备的功能功能模块有:
- 全方位日志采集,支持DaemonSet、Sidecar各种采集方式以应对不同的采集需求,同时支持Web、移动端、IoT、物理机/虚拟机各种数据源的采集;
- 日志实时通道,这个是为了对接上下游所必备的功能,保证日志能够被多种系统所便捷的使用;
- 数据清洗(ETL: Extract,Transform,Load),对各种格式的日志进行清洗,支持过滤、富化、转换、补漏、分裂、聚合等;
- 日志展现与搜索,这是所有日志平台必须具备的功能,能够根据关键词快速的定位到日志并查看日志上下文,看似简单的功能却最难做好;
- 实时分析,搜索只能完成一些定位到问题,而分析统计功能可以帮助快速分析问题的根因,同时可以用于快速的计算一些业务指标;
- 流计算,通常我们都会使用流计算框架(Flink、Storm、Spark Stream等)来计算一些实时的指标或对数据进行一些自定义的清洗等;
- 离线分析,运营、安全相关的需求都需要对大量的历史日志进行各种维度的关联计算,目前只有T+1的离线分析引擎能够完成;
- 机器学习框架,能够便捷、快速的将历史的日志对接到机器学习框架进行离线训练,并将训练后的结果加载到线上实时的算法库中。
开源方案设计
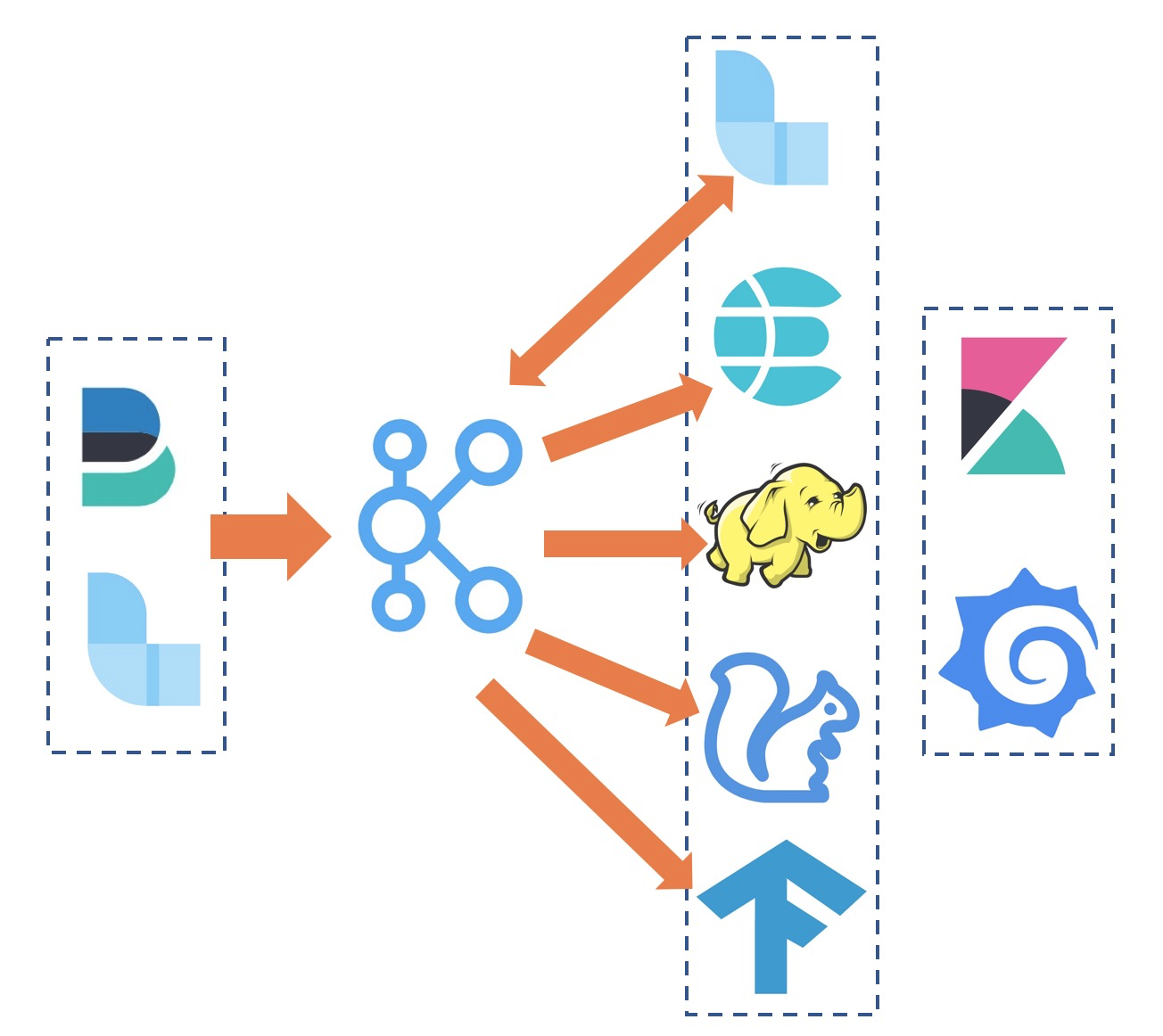
借助于强大的开源社区,我们可以很容易基于开源软件的组合来实现这样一套日志平台,上图是一个非常典型的以ELK为核心的日志平台方案:
- 利用FileBeats、Fluentd等采集Agent实现容器上的数据统一收集。
- 为了提供更加丰富的上下游以及缓冲能力,可以使用kafka作为数据采集的接收端。
- 采集到的原始数据还需要进一步的清洗,可以使用Logstash或者Flink订阅Kafka中的数据,清洗完毕后再写入kafka中。
- 清洗后的数据可以对接ElasticSearch来做实时的查询检索、对接Flink来计算实时的指标和告警、对接Hadoop来做离线的数据分析、对接TensorFlow来做离线模型训练。
- 数据的可视化可以使用grafana、kibana等常用的可视化组件。
为什么我们选择自研
采用开源软件的组合是非常高效的方案,得益于强大的开源社区以及庞大用户群体的经验积累,我们可以很快搭建出这样一套系统,并且可以满足我们绝大部分的需求。
当我们把这套系统部署好,能够把日志从容器上采集上来、elasticsearch上能够查到、Hadoop上能够成功执行SQL、Grafana上能看到图、告警短信能收到......完成上述流程打通后,加加班可能只需要花费几天的时间,当系统终于跑通的时候,这时候终于可以长舒一口气,躺在办公椅上放松放松。
然而理想很丰满现实很骨感,当我们预发通了,测试完了上到生产,开始接入第一个应用,逐渐更多的应用接入,越来越多的人开始使用......这时候很多问题都可能暴露出来:
- 随着业务量的上涨,日志量也越来越大,Kakfa和ES要不断扩容,同时同步Kafka到ES的Connector也需要扩容,最烦的是采集Agent,每台机器上部署的DaemonSet Fluentd根本没办法扩容,到了单Agent瓶颈就没办法了,只能换Sidecar,换Sidecar工作量大不说,还会带来一系列其他的问题,比如怎么和CICD系统集成、资源消耗、配置规划、stdout采集不支持等等。
- 从刚开始上的边缘业务,慢慢更多的核心业务接入,对于日志的可靠性要求越来越高,经常有研发反应从ES上查不到数据、运营说统计出来的报表不准、安全说拿到的数据不是实时的......每次问题的排查都要经过采集、队列、清洗、传输等等非常多的路径,排查代价非常高。同时还要为日志系统搭建一套监控方案,能够即时发现问题,而且这套方案还不能基于日志系统,不能自依赖。
- 当越来越多的开发开始用日志平台调查问题时,经常会出现因为某1-2个人提交一个大的查询,导致系统整体负载上升,其他人的查询都会被Block,甚至出现Full GC等情况。这时候一些大能力的公司会对ES进行改造,来支持多租户隔离;或者为不同的业务部门搭建不同的ES集群,最后又要运维多个ES集群,工作量还是很大。
- 当投入了很多人力,终于能够把日志平台维持日常使用,这时候公司财务找过来了,说我们用了非常多的机器,成本太大。这时候开始要优化成本,但是思来想去就是需要这么多台机器,每天大部分的机器水位都在20%-30%,但是高峰的水位可能到70%,所以不能撤,撤了高峰顶不住,这时候只能搞搞削峰填谷,又是一堆工作量。
上述这些是一家中等规模的互联网企业在日志平台建设中经常会遇到的问题,在阿里这些问题会放大非常多倍:
- 比如面对双十一的流量,市面上所有的开源软件都无法满足我们那么大流量的需求。
- 面对阿里内部上万个业务应用,几千名工程师同时使用,并发和多租户隔离我们必须要做到极致。
- 面对非常多核心的订单、交易等场景,整个链路的稳定性必须要求3个9甚至4个9的可用性。
- 每天如此大的数据量,对于成本的优化显得极为重要,10%的成本优化带来的收益可能就有上亿。
阿里K8s日志方案
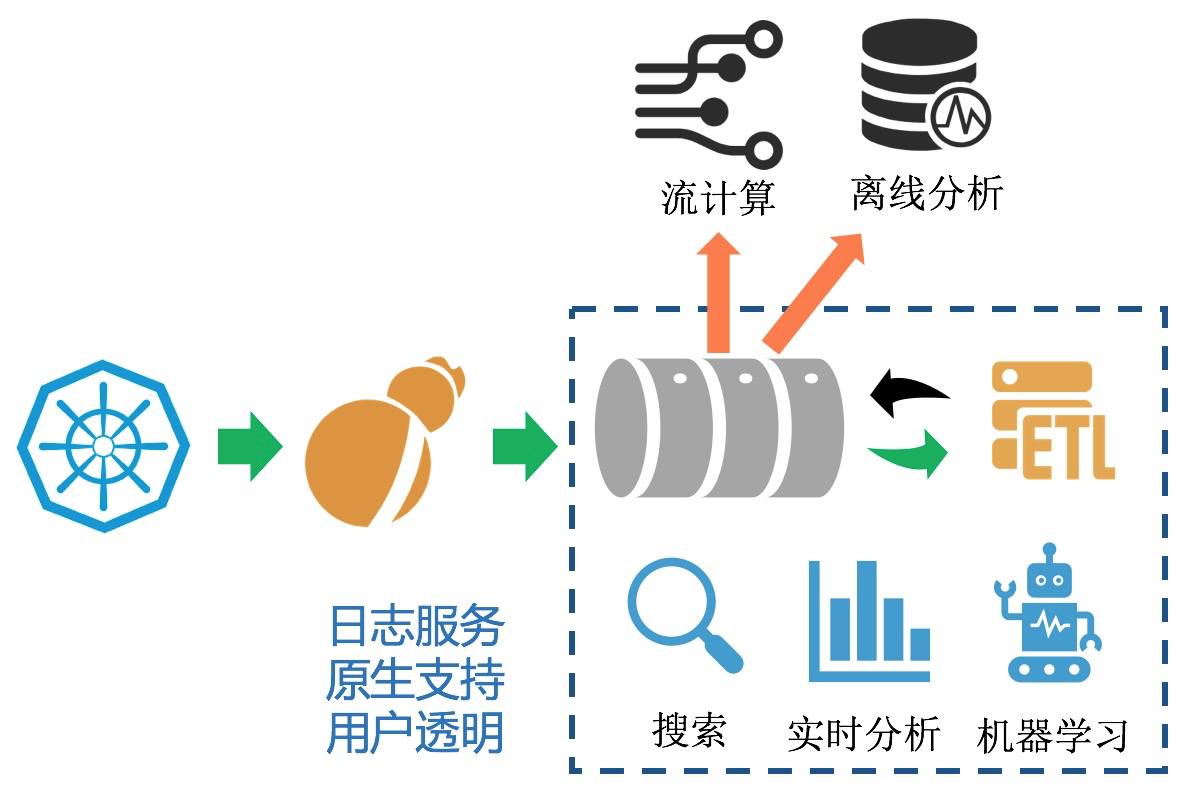
针对上述的一些问题,我们经过多年的时间,开发并打磨出这样一套K8s日志方案:
- 使用我们自研的日志采集Agent Logtail实现K8s全方位的数据采集,目前Logtail在集团内有数百万的全量部署,性能、稳定性经过多次双十一金融级考验。
- 化繁为简,数据队列、清洗加工、实时检索、实时分析、AI算法等原生集成,而不是基于各种开源软件搭积木的形式实,大大降低了数据链路长度,链路长度的降低也意味着出错可能性的减少。
- 队列、清洗加工、检索、分析、AI引擎等全部针对日志场景深度定制优化,满足大吞吐、动态扩容、亿级日志秒级可查、低成本、高可用性等需求。
- 对于流式计算、离线分析场景这种通用需求,无论是开源还是阿里内部都有非常成熟的产品,我们通过无缝对接的方式来支持,目前日志服务支持了数十种下游的开源、云上产品的对接。
这套系统目前支撑了整个阿里集团、蚂蚁集团、云上上万家企业的日志分析,每天写入的数据量16PB+,开发、运维这样一套系统问题和挑战非常多,这里就不再展开,有兴趣的同学可以参考我们团队的技术分享:阿里10PB/天日志系统设计和实现。
总结
本篇主要从架构层面去介绍如何搭建一套K8s的日志分析平台,包括开源方案以及我们阿里自研的一套方案。然而实际这套系统落地到生产环境并有效运行还有很多工作要做:
- K8s上以什么样的姿势来打日志?
- K8s上的日志采集方案选择,DaemonSet or Sidecar?
- 日志方案如何与CICD去集成?
- 微服务下各个应用的日志存储如何划分?
- 如何基于K8s系统的日志去做K8s监控?
- 如何去监控日志平台的可靠性?
- 如何去对多个微服务/组件去做自动的巡检?
- 如何自动的监控多个站点并实现流量异常时的快速定位?
后续文章我们会一步一步来和大家分享如何把这套系统落地,敬请期待。
“ 阿里巴巴云原生微信公众号(ID:Alicloudnative)关注微服务、Serverless、容器、Service Mesh等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的技术公众号。”
一文看懂 K8s 日志系统设计和实践的更多相关文章
- 一文看懂https如何保证数据传输的安全性的【转载、收藏】
一文看懂https如何保证数据传输的安全性的 一文看懂https如何保证数据传输的安全性的 大家都知道,在客户端与服务器数据传输的过程中,http协议的传输是不安全的,也就是一般情况下http是明 ...
- 转载来自朱小厮博客的 一文看懂Kafka消息格式的演变
转载来自朱小厮博客的 一文看懂Kafka消息格式的演变 ✎摘要 对于一个成熟的消息中间件而言,消息格式不仅关系到功能维度的扩展,还牵涉到性能维度的优化.随着Kafka的迅猛发展,其消息格式也在 ...
- 一文看懂web服务器、应用服务器、web容器、反向代理服务器区别与联系
我们知道,不同肤色的人外貌差别很大,而双胞胎的辨识很难.有意思的是Web服务器/Web容器/Web应用程序服务器/反向代理有点像四胞胎,在网络上经常一起出现.本文将带读者对这四个相似概念如何区分. 1 ...
- [转帖]一文看懂web服务器、应用服务器、web容器、反向代理服务器区别与联系
一文看懂web服务器.应用服务器.web容器.反向代理服务器区别与联系 https://www.cnblogs.com/vipyoumay/p/7455431.html 我们知道,不同肤色的人外貌差别 ...
- [转帖] 一文看懂:"边缘计算"究竟是什么?为何潜力无限?
一文看懂:"边缘计算"究竟是什么?为何潜力无限? 转载cnbeta 云计算 雾计算 边缘计算... 知名创投调研机构CB Insights撰文详述了边缘计算的发展和应用前景 ...
- 一文看懂Stacking!(含Python代码)
一文看懂Stacking!(含Python代码) https://mp.weixin.qq.com/s/faQNTGgBZdZyyZscdhjwUQ
- Nature 为引,一文看懂个体化肿瘤疫苗前世今生
进入2017年,当红辣子鸡PD-1疗法,一路横扫多个适应症.而CAR-T治疗的“小车”在获得FDA专委会推荐后也已经走上高速路,成为免疫治疗又一里程碑事件.PD-1.CAR-T之后,下一个免疫治疗产品 ...
- 一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了
一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了 转载: 大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的.你可以把它 ...
- 【转帖】一文看懂docker容器技术架构及其中的各个模块
一文看懂docker容器技术架构及其中的各个模块 原创 波波说运维 2019-09-29 00:01:00 https://www.toutiao.com/a6740234030798602763/ ...
随机推荐
- java命令行导出、导入sql文件
@IocBean public class SqlCommandModel{ //用户名 @Inject("java:$conf.get('jdbc.username')") pr ...
- python中生成器与迭代器
可迭代对象:一个实现了iter方法的对象是可迭代的 迭代器:一个实现了iter方法和next方法的对象就是迭代器 生成器都是Iterator对象,但list.dict.str虽然是Iterable(可 ...
- 工厂模式在mvc模型中的应用
在web开发中我们常用mvc模式进行web应用的开发 当应用进入service 层的时候我们根据不同的业务多逻辑进行处理 当有数据进入controller的时候 public class Virtua ...
- 《HelloGitHub》第 43 期
兴趣是最好的老师,HelloGitHub 就是帮你找到兴趣! 简介 分享 GitHub 上有趣.入门级的开源项目. 这是一个面向编程新手.热爱编程.对开源社区感兴趣 人群的月刊,月刊的内容包括:各种编 ...
- java23种设计模式(三)单例模式
原文地址:https://zhuanlan.zhihu.com/p/23713957 一.概述 1.什么是单例模式? 百度百科是这样定义的:单例模式是一种常用的软件设计模式.在它的核心结构中只包含一个 ...
- MySQL 分页查询优化——延迟关联优化
目录 1. InnoDB表的索引的几个概念 2. 覆盖索引和回表 3. 分页查询 4. 延迟关联优化 写在前面 下面的介绍均是在选用MySQL数据库和Innodb引擎的基础开展.我们先 ...
- spring boot打印sql语句-mybatis
spring boot打印sql语句-mybatis 概述 当自己编写的程序出现了BUG等等,找了很久 调试运行了几遍到mapper层也进去调试进了源码,非常麻烦 我就想打印出sql语句,好进行解决B ...
- C++沉思录笔记 —— 序幕
#include <stdio.h> class Trace{public: void print(const char* s) { printf("%s\n", ...
- Python 破解Linux密码
简介:因为Linux的密码都是加密过的(例如:$6$X.0bBN3w$NfM7YYHevVfCnZAVruItAEydaMJCF.muefZsxsgLK5DQoahW8Pqs1BSmoAFfi5J/b ...
- Echarts导出为pdf echarts导出图表(包含背景)
Echarts好像是只支持png和jpg的导出,不支持pdf导出.我就想着只能够将png在后台转为pdf了. 首先介绍一下jsp界面的代码. var thisChart = echarts.init( ...