雅虎日本如何用 Pulsar 构建日均千亿的消息平台
雅虎日本是一家雅虎和软银合资的日本互联网公司,是日本最受欢迎的门户网站之一。雅虎日本的互联网服务在日本市场占主导地位。
下图从三个维度显示了雅虎日本的经营规模。第一个是服务数量,雅虎日本提供上百种互联网服务;第二个是服务器数量,雅虎日本使用超过 150,000 台服务器(大多为裸机服务器)全天候支持这上百种互联网服务的正常运作;第三个是每月总页面浏览量,2017 年的数据显示,雅虎日本每月浏览量超过 700 亿。由此可见,雅虎日本的服务规模之大。

## 挑战
运营规模巨大对雅虎日本来说是个挑战。高性能和可扩展的服务才能满足海量用户的需求。同时还需要提供多租户支持来满足运营众多服务的需求。有时需要处理敏感消息或关键任务,因此持久性也很重要。此外,雅虎拥有众多的数据中心,对跨地域复制有强烈的需求。在诸多方面,我们面临着巨大挑战,希望找到一个稳定且可扩展的消息平台,能满足上述需求并大规模地运行服务,同时能确保数据的完整性。
## 为什么选择 Apache Pulsar
为了解决这些挑战,我们开始调研各种消息平台。
### Apache Pulsar vs Apache Kafka
首先,我们比较了 Apache Pulsar 和 Apache Kafka,这两个业界不同的消息系统,结果如下。
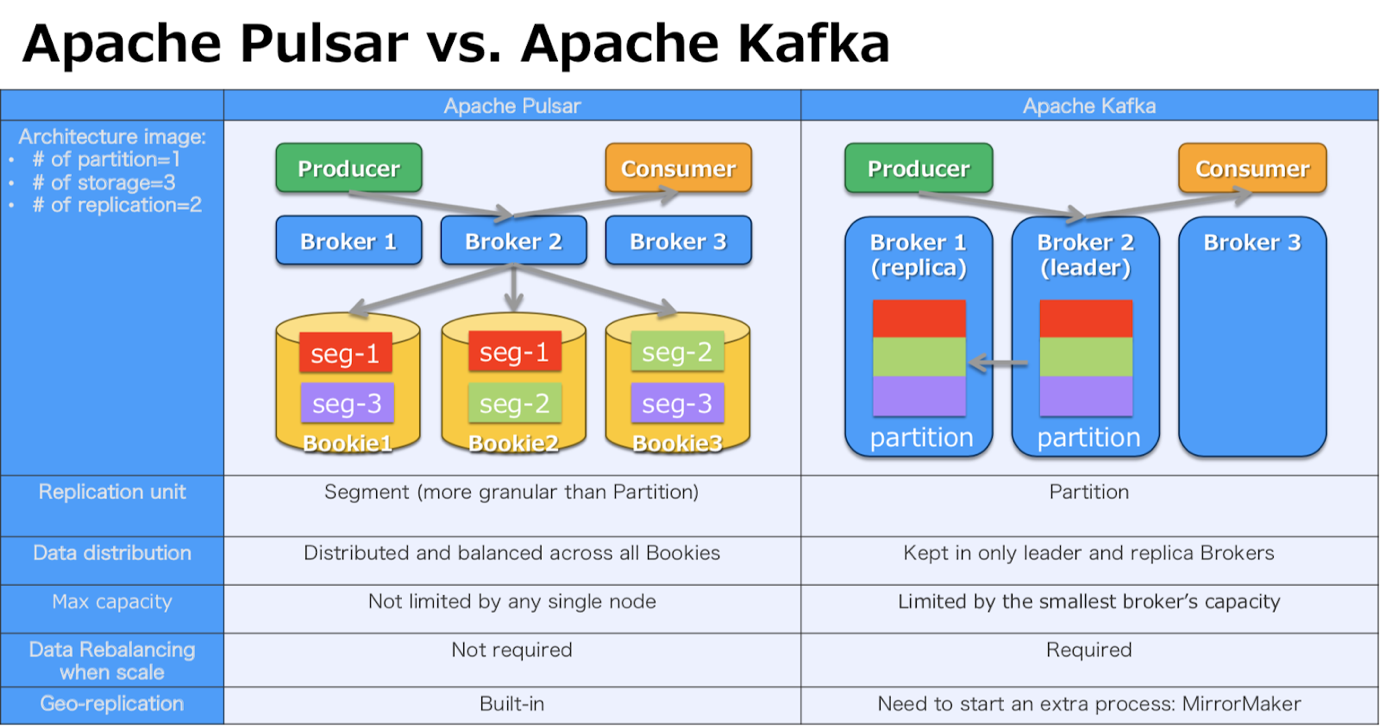
这两个系统最主要的不同在于数据分布。在数据负载均衡方面,Pulsar 比 Kafka 处理得更胜一筹。以下图为例,图中有 1 个分区,3 个存储节点,每个分区数据存储两个副本。Kafka 中,分区中的所有数据都保存在 leader broker(Broker 2)中,然后复制到另一个 follower broker(Broker 1)中。Broker 3 既不是 leader 也不是 follower,因此没有任何数据。在 Kafka 中,由于一个分区中的所有数据都由一个 broker 保存,因此分区的容量受 broker 的容量限制。一旦要扩展分区,就需要重新分布数据;否则就会出现负载不均衡的情况。而 Pulsar 中,分区中的数据被划分为粒度更细的单元,称为分片(segment)。它们均匀地分布和保存在 bookies 中,分区容量不受单个 bookie 节点容量的限制,扩展分区时不需要重新分布数据。因此,Pulsar 比 Kafka 更灵活,更容易扩展。
另一个区别是跨地域复制。Kafka 使用 MirrorMaker 来处理跨地域复制,但需要使用额外的机器来运行和管理 MirrorMaker。而 Pulsar 内置了跨地域复制功能,不需要额外部署跨地域复制组件。
### OpenMessaging Benchmark
使用 OpenMessaging Benchmark 可以很容易比较不同消息处理系统。据报道,Apache Pulsar 处理吞吐量和延迟的性能更好。图中蓝线代表 Pulsar,红线代表 Kafka。左图显示吞吐量,上方线条说明吞吐量更高。右图显示延迟,下方线条说明延迟更低。
雅虎日本如何用Pulsar构建日均千亿的消息平台?
### 为什么 Apache Pulsar 最适合
这些对比说明 Apache Pulsar 比 Apache Kafka 更好,所以我们决定进一步研究 Apache Pulsar,并总结了 Pulsar 更适合我们的原因。
#### 高性能
即使主题数量巨大,还要保证数据的可靠性,Apache Pulsar 也能实现高吞吐和低延迟。例如,Oath Inc. 每天要处理 230 万个 topic,1000 亿条消息。在这个巨大的体量下,要确保消息不能丢失且必须按顺序处理。Apache Pulsar 不仅能满足这些需求,还实现了 1,000,000 吞吐量(msg / s)和 5 ms 的延迟。
#### 易扩展
Apache Pulsar 扩展性很好。要实现扩容,只需添加服务器即可。Pulsar 的服务层和存储层是分开的,可以根据数据路径灵活地添加 broker 或 bookie。如果需要提升服务容量,添加 broker 即可。如果需要扩大存储容量,添加 bookie 即可。
#### 多租户
多租户是指多种服务共用一个 Pulsar 系统。每个服务和应用程序作为 “租户” 使用 Pulsar。因此,不同的服务无需单独维护各自消息系统。Apache Pulsar 有不同的认证和授权机制,可保护消息不被拦截。可以配置认证和授权机制,并共享到命名空间或主题,从而保护消息。因此,可以在一个 Pulsar 系统上运行多种服务,有效降低维护和劳动力成本。
#### 跨地域复制
雅虎日本在多个数据中心运行很多服务。Pulsar 提供内置的跨地域复制功能,在数据中心之间复制消息,可以有效处理灾备,恢复数据,提高服务质量。更重要的是,跨地域复制是 Pulsar 的内置功能,方便启用和使用。
#### Pulsar Functions
Pulsar Functions 是轻量级计算框架(如 AWS lambda 或 Google Cloud Functions),不需要外部系统(如 Apache Heron,Apache Storm,Apache Spark 或其他类似系统)。只需构造逻辑并部署至 Pulsar 集群。Pulsar Functions 支持 Java、Python 和 Go 语言。
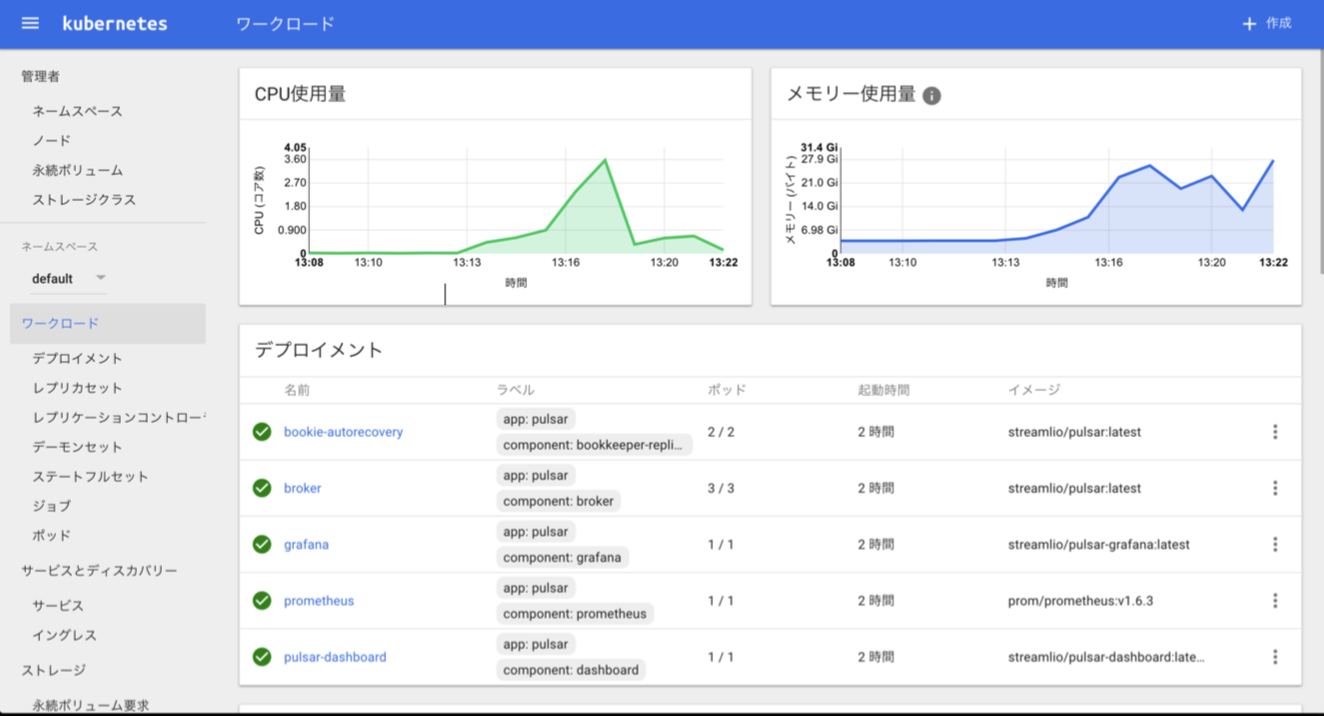
#### Pulsar on Kubernetes
Kubernetes 有众多用户,雅虎日本也是其中之一。在 Kubernetes 集群上部署 Pulsar 很容易。下图展示了 Pulsar 在 Kubernetes 引擎上的使用状态。
经过详细调研,我们发现 Apache Pulsar 不仅比 Apache Kafka 的性能更好,还能够满足我们企业运行的所有需求,在 Kubernetes 上容易部署,所以我们最终决定采用 Apache Pulsar 作为内部消息平台。
## Apache Pulsar 在雅虎日本的应用
雅虎日本在生产环境中使用 Pulsar 已经好几年了。我来分享下 Apache Pulsar 在雅虎日本的应用场景。
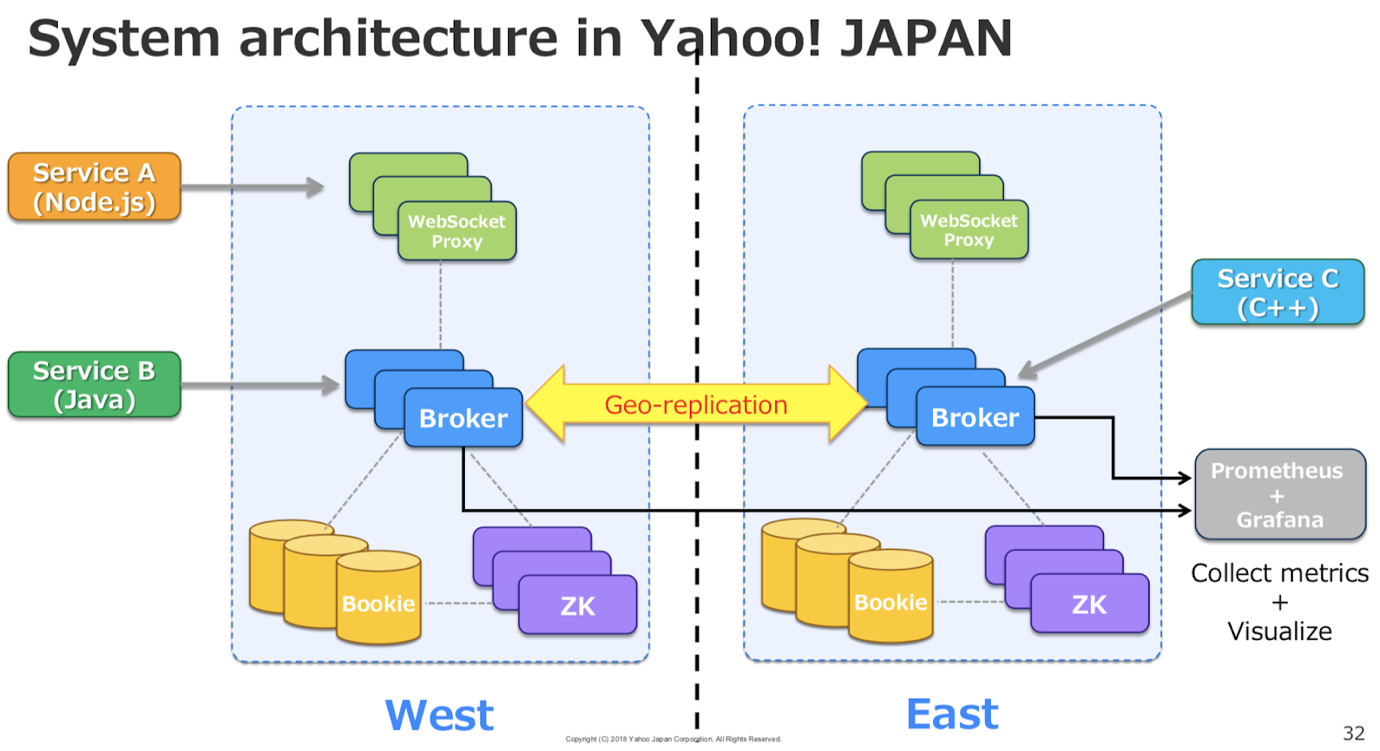
下图是雅虎日本的系统构架。我们有两个数据中心:一个在东部,一个在西部。每个数据中心都有 broker、bookie、ZooKeeper 和 WebSocket 代理服务器。我们使用 Prometheus 收集指标,并通过 Grafana 将其可视化。
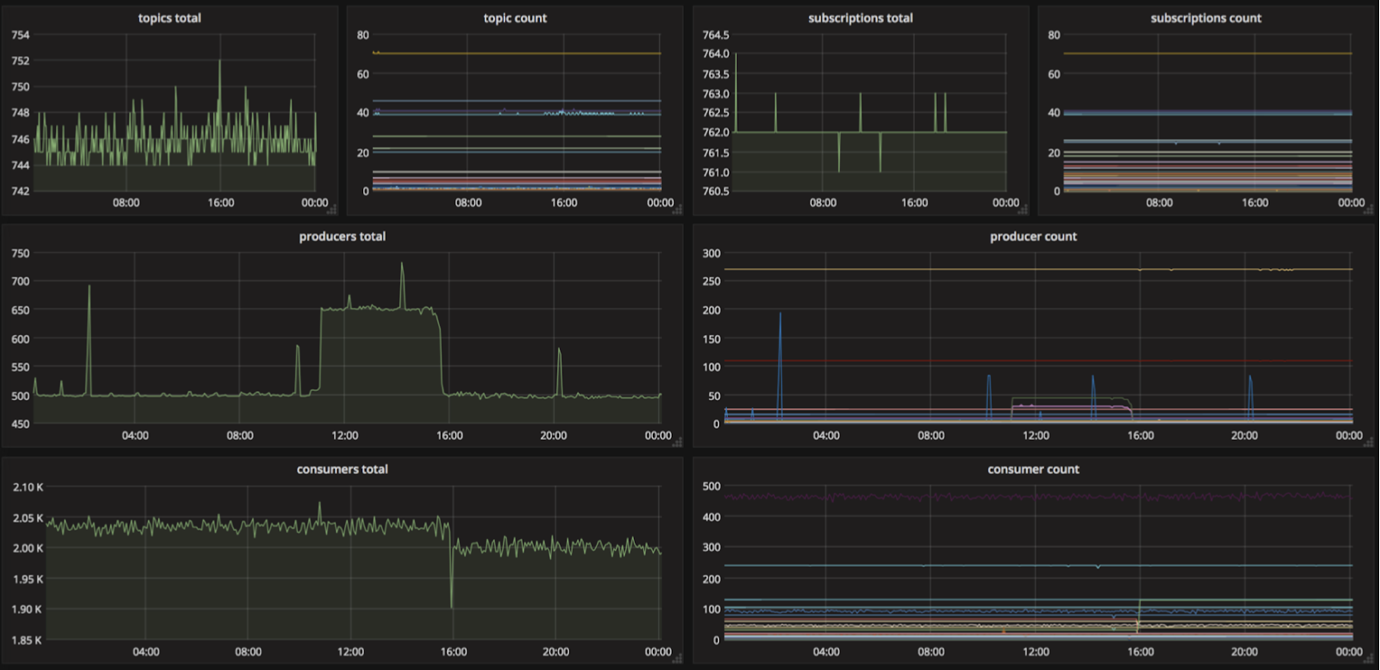
Prometheus 可以用来监控 topic、生产者和消费者的数量,如下图所示。
### 自助服务工具
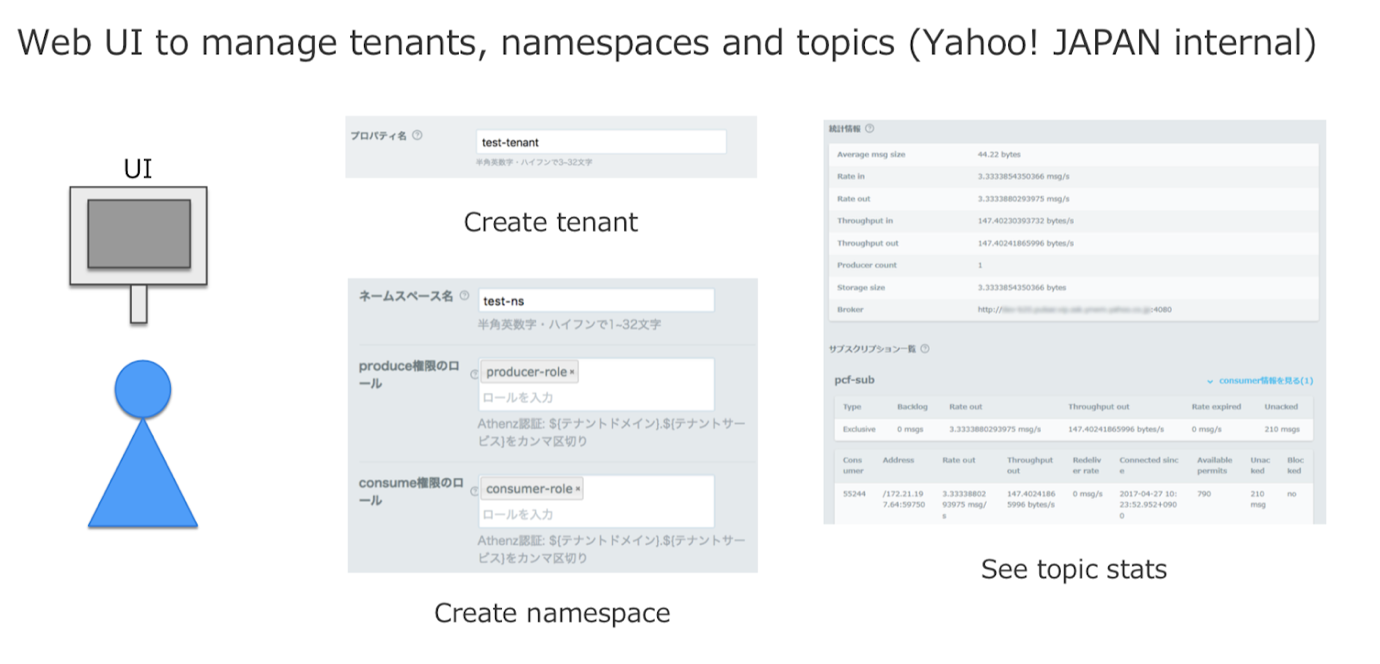
在雅虎日本,我们开发了一套工具,用来创建和管理租户、命名空间和主题。用户可以在 UI 界面自己创建租户和命名空间,并配置设置。目前,这个 UI 仅在雅虎日本内部使用,所以是日语的,没有开源。使用这个 UI,可以创建租户和命名空间,并查看 topic 的统计信息,如吞吐量、平均消息规模等。
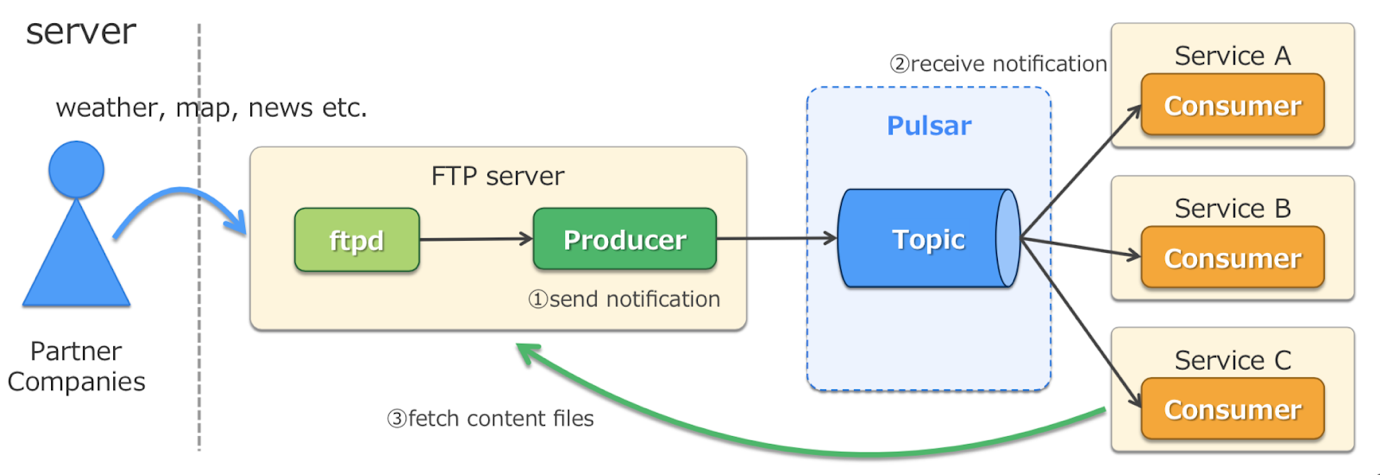
### 案例 1: 内容更新通知
我们把 Apache Pulsar 作为通知服务系统使用。各种内容文件(例如天气,地图或新闻数据)从合作伙伴公司推送到雅虎日本。服务需要了解这些更新的内容,所以服务把文件当作 topic。内容更新时会向 topic 发送通知。服务一旦收到通知,就会从文件服务器获取更新的内容文件。
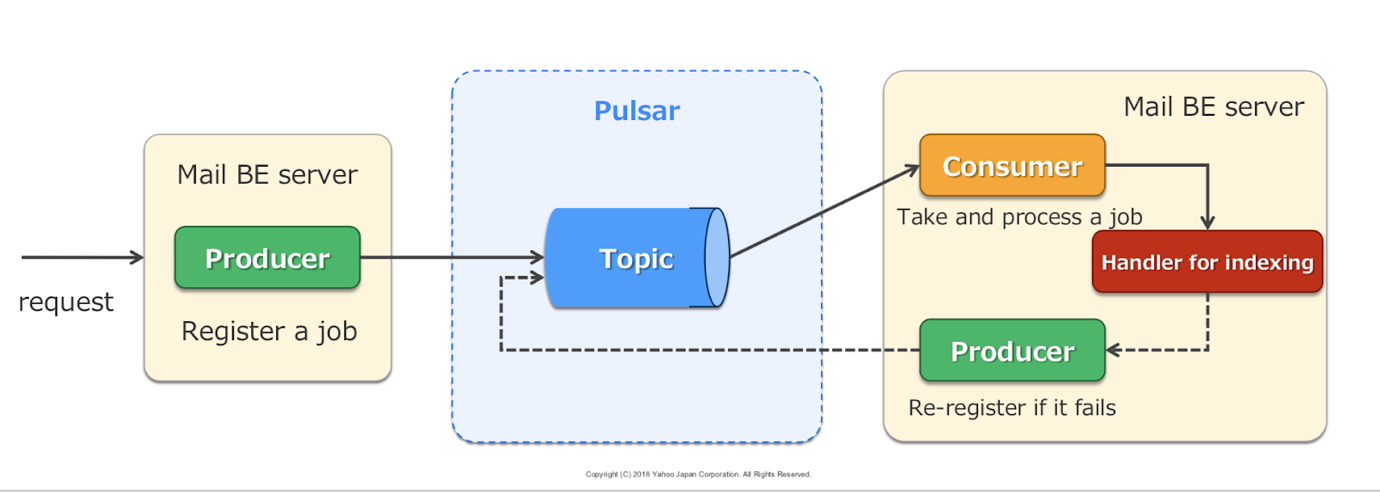
### 案例 2: 邮件服务中的工作队列
我们使用 Apache Pulsar 构建异步工作队列。邮件索引工作繁重,所以异步执行。首先,Mail BE 服务器中的生产者在 Pulsar 中注册 job,消费者按照自己的节奏从 Pulsar 获取 job。如果索引失败,生产者会重新注册。
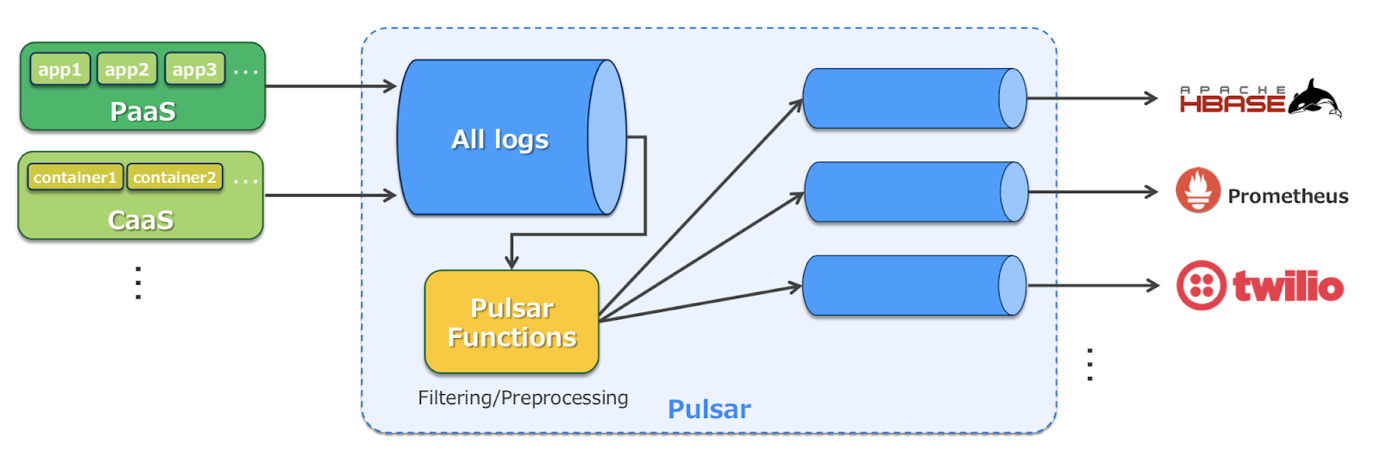
### 案例 3: 日志管道
我们使用 Apache Pulsar 收集日志。雅虎日本几乎所有的服务和应用程序都运行 PaaS 平台(如 Heron)或 CaaS 平台(如 Kubernetes),我们想从中收集日志。首先,日志发布到 Pulsar 后会分成 topic。根据使用 Pulsar Functions 的最终目的地和服务,日志最终会发送到其他数据库或平台,例如 HBase、Prometheus 和 Twilio。下图是雅虎日本的日志收集架构。
## 结论
Apache Pulsar 是一个快速、持久、可扩展的 pub-sub 消息系统,配备很多有用的内置功能,如跨地域复制、多租户、Pulsar Functions 等。
多年来,雅虎日本使用 Apache Pulsar,关注 Pulsar 社区的新闻,更新和活动,在应用场景中使用 Pulsar 新功能,Pulsar 的稳定性一直很好。
Pulsar 社区虽然年轻,但发展迅猛,在不同的应用场景下不断有新的案例落地。我们会持续关注并和 Apache Pulsar 社区深入合作,进一步完善、优化 Pulsar 的特性和功能。
## 相关信息
以下是 Apache Pulsar 的相关信息:
- Apache Pulsar: https://pulsar.apache.org/
- 联系: https://apache-pulsar.slack.com/
users@pulsar.apache.org
dev@pulsar.apache.org
- 在线视频: https://www.oreilly.com/library/view/oscon-2018-/9781492026075/video321374.html
- 演示文稿: https://conferences.oreilly.com/oscon/oscon-or-2018/public/schedule/detail/69704
## 关于作者
Nozomi Kurihara, 雅虎日本消息平台团队经理、Apache Pulsar 项目 committer。负责创建基于 Apache Pulsar pub-sub 为中心的消息处理平台,该平台能够处理海量服务和应用程序流量。
- 作者 | Nozomi Kurihara
- 审校 | Jennifer + Sijie + Irene
- 编辑 | Irene
雅虎日本如何用 Pulsar 构建日均千亿的消息平台的更多相关文章
- 千亿级平台技术架构:为了支撑高并发,我把身份证存到了JS里
@ 目录 一.用户信息安全规范 1.1 用户信息.敏感信息定义及判断依据 1.1.1 个人信息 1.1.2 个人敏感信息 1.2 用户信息存储的注意事项 二.框架技术实现 2.1 用户敏感信息自 ...
- 构建日均千万PV Web站点1
如何构建日均千万PV Web站点 (一) 其实大多数互联网网站起初的网站架构都是(Linux+Apache+MySQL+PHP). 不过随着时代的发展,科技的进步.互联网进入寻常百姓家的生活.所谓的用 ...
- 如何构建日均千万PV Web站点 (一)
其实大多数互联网网站起初的网站架构都是(Linux+Apache+MySQL+PHP). 不过随着时代的发展,科技的进步.互联网进入寻常百姓家的生活.所谓的用户的需求,铸就了一个个互联网大牛: htt ...
- 横瓜先生如何用MDB和XLS等低性能数据库来处理千亿级数据量。
横瓜先生如何用MDB和XLS等低性能数据库来处理千亿级数据量. 横瓜先生曾经用ACCESS做数据库,开发出高性能CMS来处理过TB级的文本数据量,任何请求都可以在10MS内完成,基本就是硬盘延迟的时间 ...
- 千亿级SaaS市场:企业级服务的必争之地
2015年企业级服务融资案例数量飙升,大额融资频现.不少企业纷纷涉足企业级服务市场,其中,以IM为主打的阿里钉钉,以企业CRM为主的纷享逍客高调进入人们的视野,以产品管理为核心.集成多种工具服务的iC ...
- AI反欺诈:千亿的蓝海,烫手的山芋|甲子光年
不久前,一家业界领先的机器学习公司告诉「甲子光年」:常有客户带着迫切的反欺诈需求主动找来,但是,我们不敢接. 难点何在? 作者|晕倒羊 编辑|甲小姐 设计|孙佳栋 生死欺诈 企业越急速发展,越容易产生 ...
- 转载:四两拨千斤:借助Spark GraphX将QQ千亿关系链计算提速20倍
四两拨千斤:借助Spark GraphX将QQ千亿关系链计算提速20倍 时间 2016-07-22 16:57:00 炼数成金 相似文章 (5) 原文 http://www.dataguru.cn/ ...
- 挑战海量数据:基于Apache DolphinScheduler对千亿级数据应用实践
点亮 ️ Star · 照亮开源之路 GitHub:https://github.com/apache/dolphinscheduler 精彩回顾 近期,初灵科技的大数据开发工程师钟霈合在社区活动的线 ...
- 基于BootStrap框架构建快速响应的GPS部标监控平台
最近一个客户要求将gps部标平台移植到bootStrap框架作为前端框架,符合交通部796部标只是他们的一个基本要求,重点是要和他们的冷链云物流平台进行适配.我自己先浏览了客户的云物流平台的界面,采用 ...
随机推荐
- Asp.net内置对象用途说明
Asp.net 内置对象 1.Session当客户第一次请求网页,session创建.当客户最后一次请求页面,一段时间后,session销毁.默认30分钟. 一般存用户信息,即登陆成功后,在sessi ...
- RAID 10 配置流程
1.在虚拟机中再添加5块硬盘: 2.fdisk -l 可以查看当前虚拟机中的磁盘情况. 3.使用mdadm命令创建RAID10,名称为”/dev/md0″. -C代表创建操作,-v显示创建过程,-a ...
- C#用抽象类定义几何图形
using System;/*using System.Data;*/namespace tx{ abstract class tx { public double chan ...
- PowerSploit-CodeExecution(代码执行)脚本渗透实战
首先介绍一下国外大牛制作的Powershell渗透工具PowerSploit,上面有很多powershell攻击脚本,它们主要被用来渗透中的信息侦察.权限提升.权限维持. 项目地址:https://g ...
- 关于thinkphp框架中模型笔记
模型这一块,感觉学习的不是很清楚,单独水一贴thinkphp中模型的学习笔记. 0x01 模型类简介 数据库中每一张表对应一个模型,类名就是表名,类里面的成员变量就是列名, 把一张表对应为一个类,其中 ...
- 并发编程之Fork/Join
并发与并行 并发:多个进程交替执行. 并行:多个进程同时进行,不存在线程的上下文切换. 并发与并行的目的都是使CPU的利用率达到最大.Fork/Join就是为了尽可能提高硬件的使用率而应运而生的. 计 ...
- Spring 基础知识学习
Spring 总结 在Spring框架的发布版本中,共包含了20个不同的模块,可以划分为6类不同的功能. Spring整体架构图 为了降低Java开发的复杂性,Spring采取了以下4种关键策略: 基 ...
- 百万年薪python之路 -- 面向对象之:类空间问题以及类之间的关系
面向对象之:类空间问题以及类之间的关系 1.从空间角度研究类 1.何处添加对象属性 class A: def __init__(self,name): self.name = name def fun ...
- SQlserver高效分页,还在使用row_number(),top之类的?
row_number() ,还是top 这些分页的方法比较老了,效率不是很高效的, Sqlserve2012就有了,效率对比比较明显,尤其是数据比较大的情况下(我们可以观看查询执行计划) Offset ...
- 设计模式(十一)Composite模式
Composite模式模式能够使容器与内容具有一致性,创造出递归结构.有时,与将文件夹和文件都作为目录条目看待一样,将容器和内容作为同一种东西看待,可以帮助我们方便地处理问题.在容器中既可以放入内容, ...