Word2Vector 中的 Hierarchical Softmax
Overall Introduction
之前我们提过基于可以使用CBOW或者SKIP-GRAM来捕捉预料中的token之间的关系,然后生成对应的词向量。
常规做法是我们可以直接feed DNN进去训练,但是如果语料很多的话,那直接就爆机了。所以这时候,我们生成词向量的时候,换了一种其他的做法,也就是利用霍夫曼树。夫曼树的叶子节点起到输出层神经元的作用,叶子节点的个数即为词汇表的小大。 而内部节点则起到隐藏层神经元的作用。
霍夫曼树
霍夫曼树的建立其实并不难,过程如下:
输入:权值为(w1,w2,...wn)(w1,w2,...wn)的nn个节点
输出:对应的霍夫曼树
1)将(w1,w2,...wn)(w1,w2,...wn)看做是有nn棵树的森林,每个树仅有一个节点。
2)在森林中选择根节点权值最小的两棵树进行合并,得到一个新的树,这两颗树分布作为新树的左右子树。新树的根节点权重为左右子树的根节点权重之和。
3) 将之前的根节点权值最小的两棵树从森林删除,并把新树加入森林。
4)重复步骤2)和3)直到森林里只有一棵树为止。
下面我们用一个具体的例子来说明霍夫曼树建立的过程,我们有(a,b,c,d,e,f)共6个节点,节点的权值分布是(20,4,8,6,16,3)。
首先是最小的b和f合并,得到的新树根节点权重是7.此时森林里5棵树,根节点权重分别是20,8,6,16,7。此时根节点权重最小的6,7合并,得到新子树,依次类推,最终得到下面的霍夫曼树。
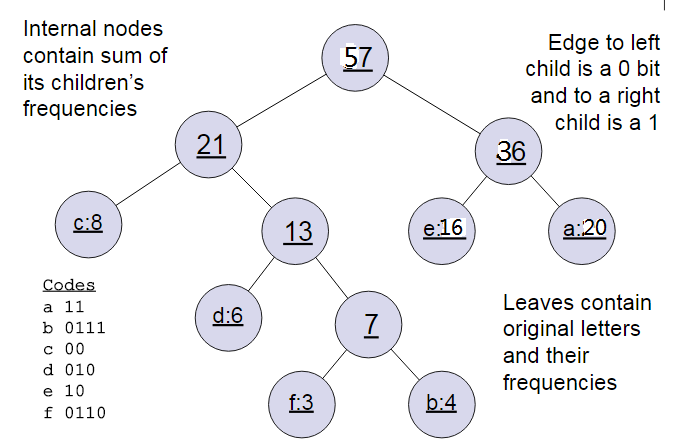
那么霍夫曼树有什么好处呢?一般得到霍夫曼树后我们会对叶子节点进行霍夫曼编码,由于权重高的叶子节点越靠近根节点,而权重低的叶子节点会远离根节点,这样我们的高权重节点编码值较短,而低权重值编码值较长。这保证的树的带权路径最短,也符合我们的信息论,即我们希望越常用的词拥有更短的编码。如何编码呢?一般对于一个霍夫曼树的节点(根节点除外),可以约定左子树编码为0,右子树编码为1.如上图,则可以得到c的编码是00。在word2vec中,约定编码方式和上面的例子相反,即约定左子树编码为1,右子树编码为0,同时约定左子树的权重不小于右子树的权重。
基于Hierarchical Softmax的模型概述
传统的神经网络词向量语言模型,里面一般有三层,输入层(词向量),隐藏层和输出层(softmax层)。里面最大的问题在于从隐藏层到输出的softmax层的计算量很大,因为要计算所有词的softmax概率,再去找概率最大的值。这个模型如下图所示。其中VV是词汇表的大小
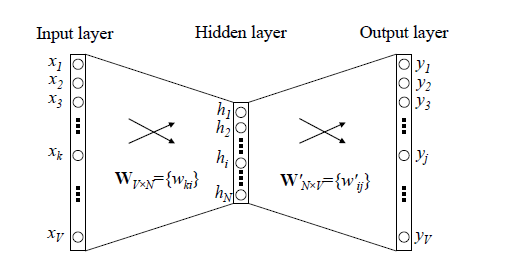
word2vec对这个模型做了改进,首先,对于从输入层到隐藏层的映射,没有采取神经网络的线性变换加激活函数的方法,而是采用简单的对所有输入词向量求和并取平均的方法。比如输入的是三个4维词向量:(1,2,3,4),(9,6,11,8),(5,10,7,12)(1,2,3,4),(9,6,11,8),(5,10,7,12),那么我们word2vec映射后的词向量就是(5,6,7,8)(5,6,7,8)。由于这里是从多个词向量变成了一个词向量。
第二个改进就是从隐藏层到输出的softmax层这里的计算量个改进。为了避免要计算所有词的softmax概率,word2vec采样了霍夫曼树来代替从隐藏层到输出softmax层的映射。我们在上一节已经介绍了霍夫曼树的原理。如何映射呢?这里就是理解word2vec的关键所在了。
由于我们把之前所有都要计算的从输出softmax层的概率计算变成了一颗二叉霍夫曼树,那么我们的softmax概率计算只需要沿着树形结构进行就可以了。如下图所示,我们可以沿着霍夫曼树从根节点一直走到我们的叶子节点的词w2。
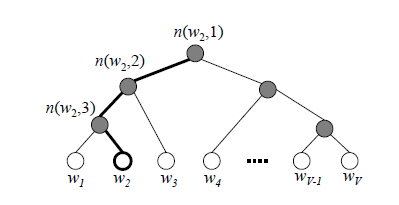
和之前的神经网络语言模型相比,我们的霍夫曼树的所有内部节点就类似之前神经网络隐藏层的神经元,其中,根节点的词向量对应我们的投影后的词向量,而所有叶子节点就类似于之前神经网络softmax输出层的神经元,叶子节点的个数就是词汇表的大小。在霍夫曼树中,隐藏层到输出层的softmax映射不是一下子完成的,而是沿着霍夫曼树一步步完成的,因此这种softmax取名为"Hierarchical Softmax"。
如何“沿着霍夫曼树一步步完成”呢?在word2vec中,我们采用了二元逻辑回归的方法,即规定沿着左子树走,那么就是负类(霍夫曼树编码1),沿着右子树走,那么就是正类(霍夫曼树编码0)。判别正类和负类的方法是使用sigmoid函数,即:
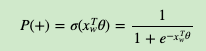
其中xw是当前内部节点的词向量,而θ则是我们需要从训练样本求出的逻辑回归的模型参数。
使用霍夫曼树有什么好处呢?首先,由于是二叉树,之前计算量为V,现在变成了log2V。第二,由于使用霍夫曼树是高频的词靠近树根,这样高频词需要更少的时间会被找到,这符合我们的贪心优化思想。
容易理解,被划分为左子树而成为负类的概率为P(−)=1−P(+)P(−)=1−P(+)。在某一个内部节点,要判断是沿左子树还是右子树走的标准就是看P(−),P(+)P(−),P(+)谁的概率值大。而控制P(−),P(+)P(−),P(+)谁的概率值大的因素一个是当前节点的词向量,另一个是当前节点的模型参数θ。
对于上图中的w2,如果它是一个训练样本的输出,那么我们期望对于里面的隐藏节点n(w2,1)n(w2,1)的P(−)P(−)概率大,n(w2,2)n(w2,2)的P(−)P(−)概率大,n(w2,3)n(w2,3)的P(+)P(+)概率大。
回到基于Hierarchical Softmax的word2vec本身,我们的目标就是找到合适的所有节点的词向量和所有内部节点θ, 使训练样本达到最大似然。那么如何达到最大似然呢?
基于Hierarchical Softmax的模型梯度计算
我们使用最大似然法来寻找所有节点的词向量和所有内部节点θ。先拿上面的w2例子来看,我们期望最大化下面的似然函数:
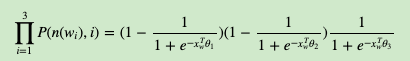
对于所有的训练样本,我们期望最大化所有样本的似然函数乘积。
为了便于我们后面一般化的描述,我们定义输入的词为w,其从输入层词向量求和平均后的霍夫曼树根节点词向量为xw, 从根节点到w所在的叶子节点,包含的节点总数为lw, w在霍夫曼树中从根节点开始,经过的第i个节点表示为pw,对应的霍夫曼编码为dwi∈{0,1}diw∈{0,1},其中i=2,3,...lwi=2,3,...lw。而该节点对应的模型参数表示为θwiθiw, 其中i=1,2,...lw−1i=1,2,...lw−1,没有i=i=lw是因为模型参数仅仅针对于霍夫曼树的内部节点
定义w经过的霍夫曼树某一个节点j的逻辑回归概率为P(dwj|xw,θwj−1)P(djw|xw,θj−1w),其表达式为:
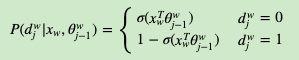
那么对于某一个目标输出词w,其最大似然为:
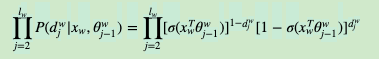
在word2vec中,由于使用的是随机梯度上升法,所以并没有把所有样本的似然乘起来得到真正的训练集最大似然,仅仅每次只用一个样本更新梯度,这样做的目的是减少梯度计算量。这样我们可以得到w的对数似然函数LL如下:
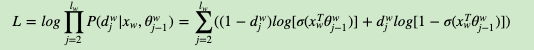
要得到模型中w词向量和内部节点的模型参数θ, 我们使用梯度上升法即可。首先我们求模型参数θ的梯度:

同样的方法,可以求出xw的梯度表达式如下:
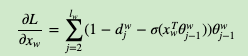
基于Hierarchical Softmax的CBOW模型
由于word2vec有两种模型:CBOW和Skip-Gram,我们先看看基于CBOW模型时, Hierarchical Softmax如何使用。
首先我们要定义词向量的维度大小M,以及CBOW的上下文大小2c,这样我们对于训练样本中的每一个词,其前面的c个词和后面的c个词作为了CBOW模型的输入,该词本身作为样本的输出,期望softmax概率最大。
在做CBOW模型前,我们需要先将词汇表建立成一颗霍夫曼树。
对于从输入层到隐藏层(投影层),这一步比较简单,就是对w周围的2c个词向量求和取平均即可,即:
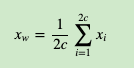
第二步,通过梯度上升法来更新我们的θwj−1和xw,注意这里的xwxw是由2c2c个词向量相加而成,我们做梯度更新完毕后会用梯度项直接更新原始的各个xi(i=1,2,,,,2c)xi(i=1,2,,,,2c),即:
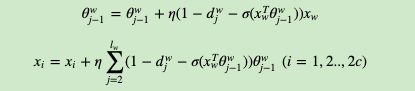
其中η为梯度上升法的步长。
这里总结下基于Hierarchical Softmax的CBOW模型算法流程,梯度迭代使用了随机梯度上升法:
输入:基于CBOW的语料训练样本,词向量的维度大小M,CBOW的上下文大小2c,步长η
输出:霍夫曼树的内部节点模型参数θ,所有的词向量w
1. 基于语料训练样本建立霍夫曼树。
2. 随机初始化所有的模型参数θ,所有的词向量w
3. 进行梯度上升迭代过程,对于训练集中的每一个样本(context(w),w)做如下处理:
a) e=0, 计算xw=12c∑i=12cxixw=12c∑i=12cxi
b) for j = 2 to lw, 计算:
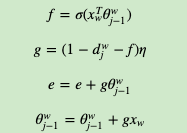
c) 对于context(w)中的每一个词向量xi(共2c个)进行更新:
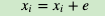
d) 如果梯度收敛,则结束梯度迭代,否则回到步骤3继续迭代。
基于Hierarchical Softmax的Skip-Gram模型
现在我们先看看基于Skip-Gram模型时, Hierarchical Softmax如何使用。此时输入的只有一个词ww,输出的为2c个词向量context(w)。
我们对于训练样本中的每一个词,该词本身作为样本的输入, 其前面的c个词和后面的c个词作为了Skip-Gram模型的输出,,期望这些词的softmax概率比其他的词大。
Skip-Gram模型和CBOW模型其实是反过来的,在上一篇已经讲过。
在做CBOW模型前,我们需要先将词汇表建立成一颗霍夫曼树。
对于从输入层到隐藏层(投影层),这一步比CBOW简单,由于只有一个词,所以,即xw就是词w对应的词向量。
第二步,通过梯度上升法来更新我们的θwj−1和xw,注意这里的xw周围有2c个词向量,此时如果我们期望P(xi|xw),i=1,2...2cP(xi|xw),i=1,2...2c最大。此时我们注意到由于上下文是相互的,在期望P(xi|xw),i=1,2...2cP(xi|xw),i=1,2...2c最大化的同时,反过来我们也期望P(xw|xi),i=1,2...2cP(xw|xi),i=1,2...2c最大。那么是使用P(xi|xw)P(xi|xw)好还是P(xw|xi)P(xw|xi)好呢,word2vec使用了后者,这样做的好处就是在一个迭代窗口内,我们不是只更新xw一个词,而是xi,i=1,2...2cxi,i=1,2...2c共2c个词。这样整体的迭代会更加的均衡。因为这个原因,Skip-Gram模型并没有和CBOW模型一样对输入进行迭代更新,而是对2c个输出进行迭代更新。
这里总结下基于Hierarchical Softmax的Skip-Gram模型算法流程,梯度迭代使用了随机梯度上升法:
输入:基于Skip-Gram的语料训练样本,词向量的维度大小M,Skip-Gram的上下文大小2c,步长η
输出:霍夫曼树的内部节点模型参数θ,所有的词向量w
1. 基于语料训练样本建立霍夫曼树。
2. 随机初始化所有的模型参数θ,所有的词向量w,
3. 进行梯度上升迭代过程,对于训练集中的每一个样本(w,context(w))做如下处理:
a) for i =1 to 2c:
i) e=0
ii)for j = 2 to lw, 计算:

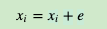
b)如果梯度收敛,则结束梯度迭代,算法结束,否则回到步骤a继续迭代。
Word2Vector 中的 Hierarchical Softmax的更多相关文章
- word2vec 中的数学原理具体解释(四)基于 Hierarchical Softmax 的模型
word2vec 是 Google 于 2013 年开源推出的一个用于获取 word vector 的工具包,它简单.高效,因此引起了非常多人的关注.因为 word2vec 的作者 Tomas M ...
- DL4NLP——词表示模型(三)word2vec(CBOW/Skip-gram)的加速:Hierarchical Softmax与Negative Sampling
上篇博文提到,原始的CBOW / Skip-gram模型虽然去掉了NPLM中的隐藏层从而减少了耗时,但由于输出层仍然是softmax(),所以实际上依然“impractical”.所以接下来就介绍一下 ...
- word2vec原理(二) 基于Hierarchical Softmax的模型
word2vec原理(一) CBOW与Skip-Gram模型基础 word2vec原理(二) 基于Hierarchical Softmax的模型 word2vec原理(三) 基于Negative Sa ...
- Hierarchical softmax(分层softmax)简单描述.
最近在做分布式模型实现时,使用到了这个函数. 可以说非常体验非常的好. 速度非常快,效果和softmax差不多. 我们知道softmax在求解的时候,它的时间复杂度和我们的词表总量V一样O(V),是性 ...
- 层次softmax函数(hierarchical softmax)
一.h-softmax 在面对label众多的分类问题时,fastText设计了一种hierarchical softmax函数.使其具有以下优势: (1)适合大型数据+高效的训练速度:能够训练模型“ ...
- Word2Vec实现原理(Hierarchical Softmax)
由于word2vec有两种改进方法,一种是基于Hierarchical Softmax的,另一种是基于Negative Sampling的.本文关注于基于Hierarchical Softmax的改进 ...
- [DeeplearningAI笔记]序列模型2.6Word2Vec/Skip-grams/hierarchical softmax classifier 分级softmax 分类器
5.2自然语言处理 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.6 Word2Vec Word2Vec相对于原先介绍的词嵌入的方法来说更加的简单快速. Mikolov T, Chen ...
- word2vec改进之Hierarchical Softmax
首先Hierarchical Softmax是word2vec的一种改进方式,因为传统的word2vec需要巨大的计算量,所以该方法主要有两个改进点: 1. 对于从输入层到隐藏层的映射,没有采取神经网 ...
- 词表征 2:word2vec、CBoW、Skip-Gram、Negative Sampling、Hierarchical Softmax
原文地址:https://www.jianshu.com/p/5a896955abf0 2)基于迭代的方法直接学 相较于基于SVD的方法直接捕获所有共现值的做法,基于迭代的方法一次只捕获一个窗口内的词 ...
随机推荐
- laravel中的表单请求类型和CSRF防护(六)
laravel中为我们提供了绑定不同http请求类型的函数. Route::get('/test', function () {}); Route::post('/test', function () ...
- 手写SpringMVC实现过程
1. Spring Boot,Spring MVC的底层实现都是Servlet的调用. 2. Servlet的生命周期里面首先是类的初始化,然后是类的方法的调用,再次是类的销毁. 3. 创建一个spr ...
- [反汇编] 获取上一个栈帧的ebp
使用代码 lea ecx, [ebp+4+参数长度] 就可以实现. 如下图,理解栈帧的结构,很好理解. 虽然也是 push param的,但这部分在恢复时被调用函数会恢复的,因此这并不算esp的值. ...
- GO Map的初步使用
一.集合(Map) 1.1 什么是Map 张三:13910101201 李四:13801010134 map是Go中的内置类型,它将一个值与一个键关联起来.可以使用相应的键检索值. Map 是一种无序 ...
- OA传SAP设置(备忘)
package com.seeyon.apps.ext.kk.flow.hc; import java.rmi.RemoteException; import java.text.SimpleDate ...
- python基础(22):模块、包
1. 模块 1.1 什么是模块 别人写好的函数.变量.方法放在一个文件里 (这个文件可以被我们直接使用)这个文件就是个模块 常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模 ...
- 初识Lock与AbstractQueuedSynchronizer(AQS)
本人免费整理了Java高级资料,涵盖了Java.Redis.MongoDB.MySQL.Zookeeper.Spring Cloud.Dubbo高并发分布式等教程,一共30G,需要自己领取.传送门:h ...
- Spring Boot 中如何支持异步方法
本人免费整理了Java高级资料,涵盖了Java.Redis.MongoDB.MySQL.Zookeeper.Spring Cloud.Dubbo高并发分布式等教程,一共30G,需要自己领取.传送门:h ...
- Java生鲜电商平台-商品分类表和商品类型表的区别与数据库设计
Java生鲜电商平台-商品分类表和商品类型表的区别与数据库设计 二者服务的对象不一样 目的也是不一样的 商品分类是为商品服务的 用来管理商品 商品类型是为扩展属性服务的 用来管理属性 举例:[转] ...
- 史上最全Winform中使用ZedGraph教程与资源汇总整理(附资源下载)
场景 C#窗体应用中使用ZedGraph曲线插件绘制图表: https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/99716066 Win ...