scrapy架构流程
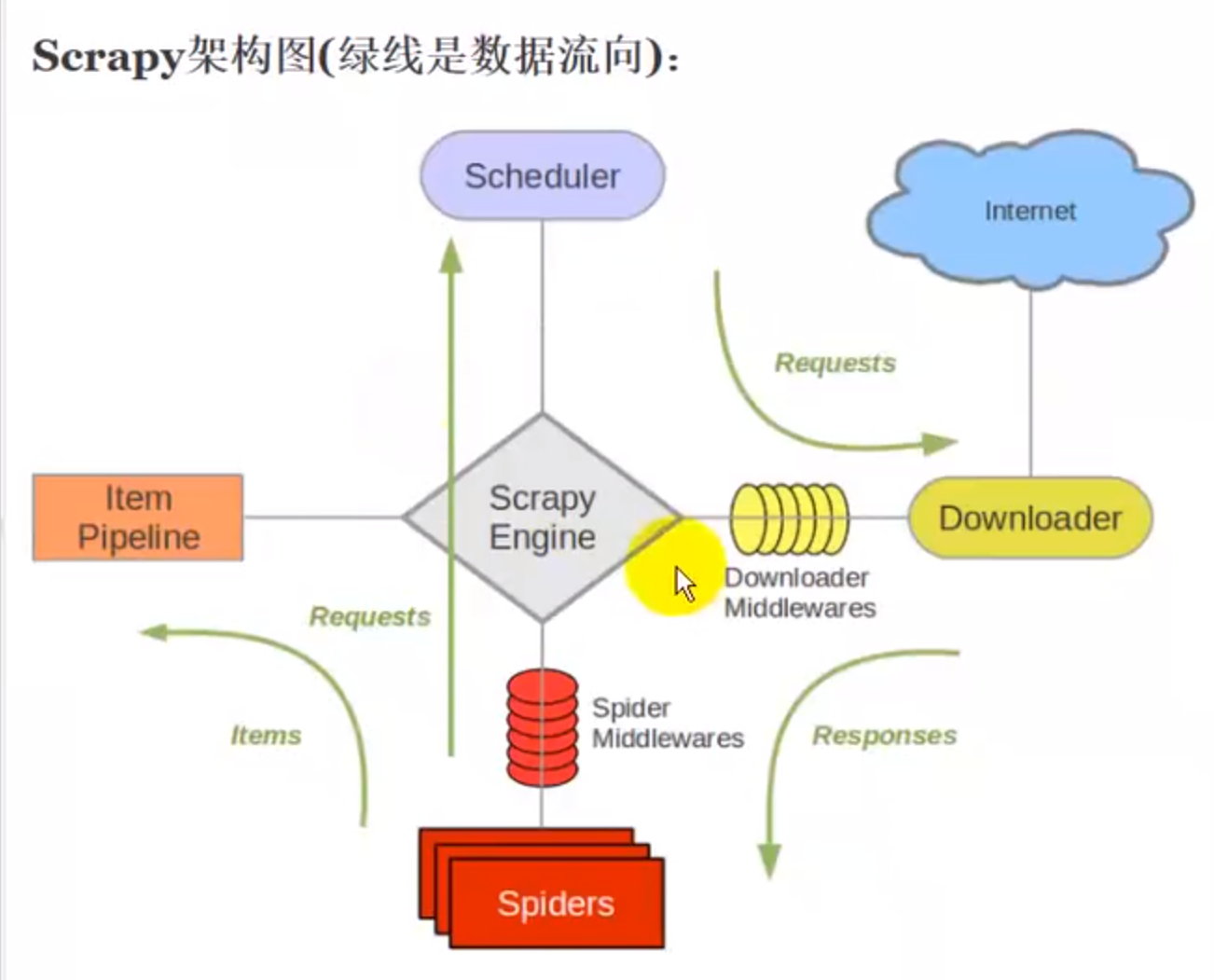
1.爬虫spiders将请求通过引擎传递给调度器scheduler
2.scheduler有个请求队列,在请求队列中拿出请求给下载器,downloader
3.downloader从Internet的服务器端请求数据,下载下来
4.下载下来的响应体交还给我们自己写的spiders,对响应体做相应的处理
5.响应体处理后有两种情况,1):如果是数据,交给pipeline管道,处理数据 2):如果是请求,接着交给调度器放到请求队列中等待处理,然后交给下载器处理,如此循环,直到没有请求产生
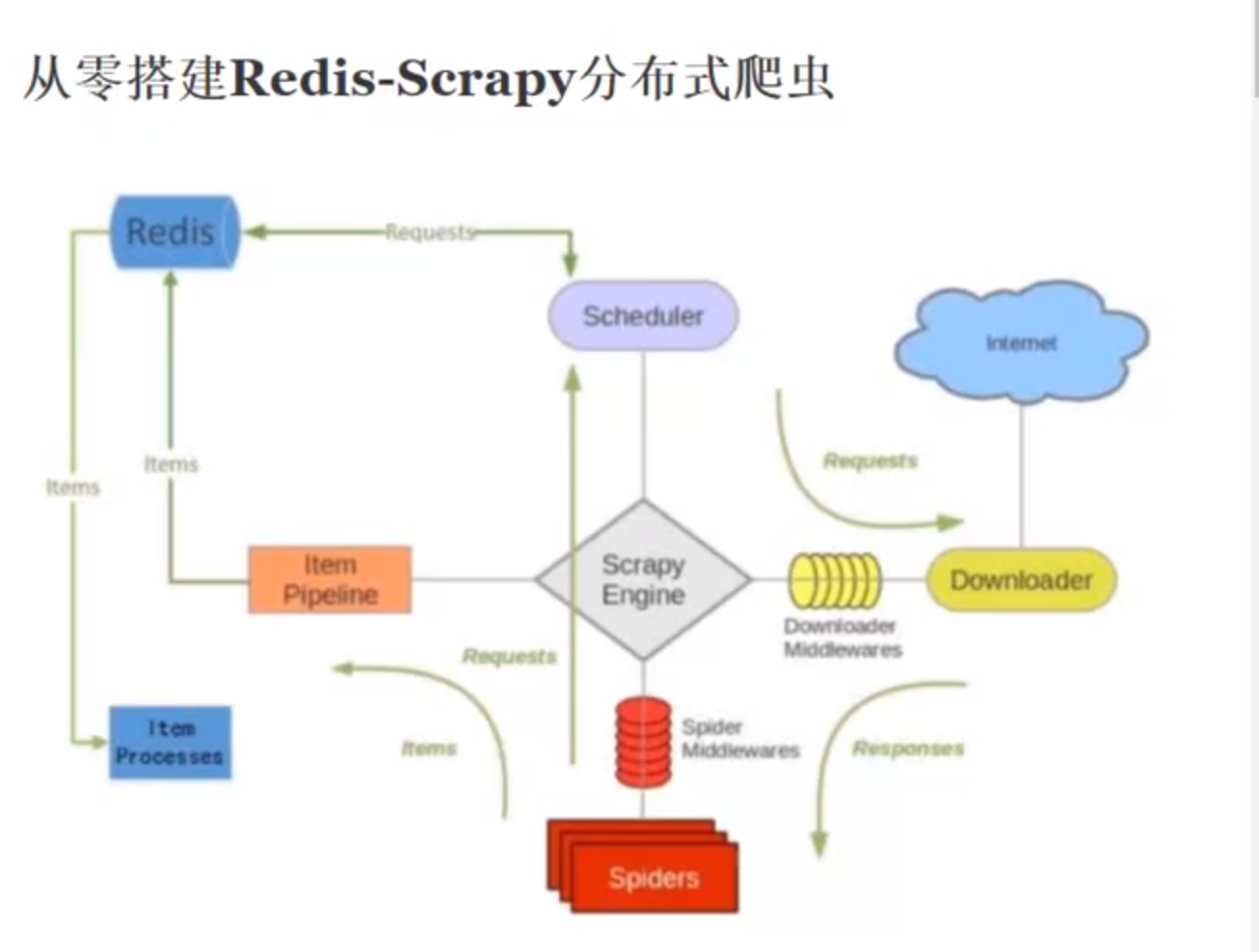
redis-scrapy是基于scrapy框架的一套组件
scrapy是一个通用的爬虫框架,不支持分布式操作,scrapy-redis是为了更方便的是scrapy进行分布式的爬取,而提供了一些以redis为基础的组件(仅有组件)
scrapy提供了四种组件(components),四种组件也就意味这四个模块都要做相应的修改:
- scheduler
- duplication filter
- item pipeline
- base spider
scrapy的去重是在内存中执行的,如果请求量非常大的时候,scrapy占用的内存会非常高,如果我们把这个去重的指纹队列放到redis数据库中的话就会很方便了
scrapy中的数据是交给pipeline来处理的,在scrapy-redis中,数据是直接存储到redis数据库中的,然后我们对数据进行处理持久化到mongodb中或者mysql中,因为redis也是基于内存的存储,不适合持久化数据
Scheduler:
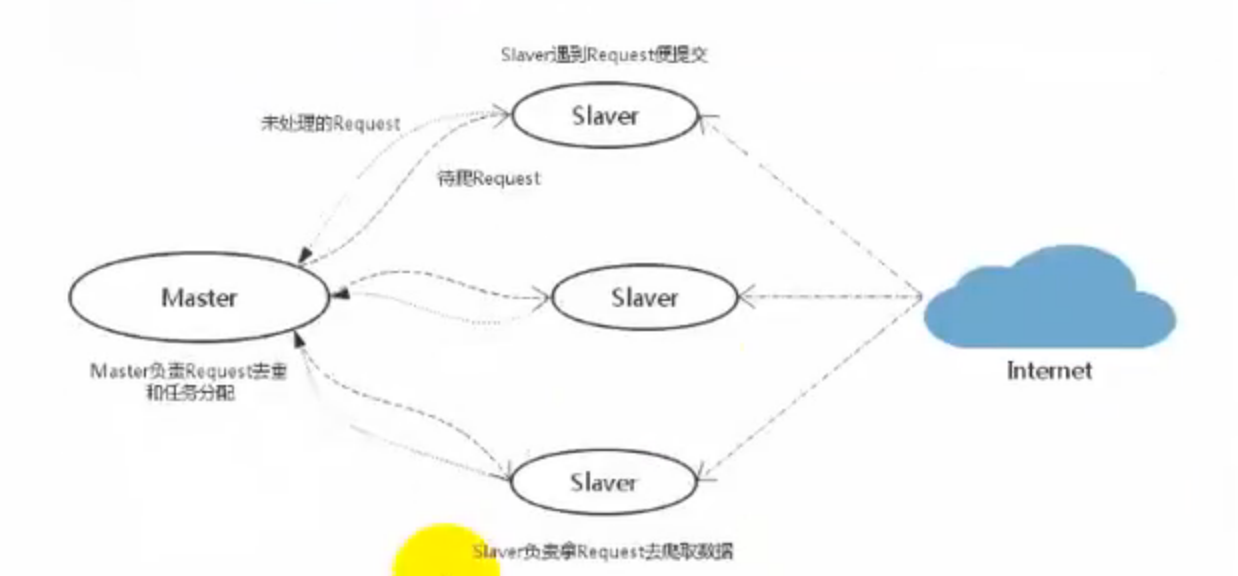
scrapy改造了python本来的collection.deque(双向队列)形成了自己的scrapy queue,但是scrapy多个spider不能共享待爬取队列scrapy queue,即scrapy本身不支持爬取分布式,scrapy-redis的解决是把这个scrapy queue换成redis数据库(也是指redis队列),从同一个redis-server存放要爬取的request,便能让多个spider从同一个数据库中读取。
scrapy中跟待爬队列直接相关的就是调度器scheduler,它把新的request进行入列操作,放到scrapy queue中,把要爬取的request取出,从scrapy queue中取出,它把待爬队列按照优先级建立了一种字典结构
{
优先级0:队列0
优先级1:队列1
优先级2:队列2
}
然后根据request中的优先级,来决定该入到哪个队列中,出列时则是按照优先级较小的优先出列。对于这个较高级别的队列结构,scrapy要提供一系列的方法来管理它,原有的scrapy scheduler以无法满足,此时需要使用scrapy-redis中的scheduler组件。
duplication filter:
scrapy中用集合来实现request的去重功能。scrapy中将已经发送的request指纹信息放入到set中,然后把将要发送的request指纹信息和set中的进行比较,如果存在则返回,否则继续进行操作。核心实现功能代码如下:
def request_seen(self,request):
#self.request_figerprints就是一个指纹集合
fp=self.request_fingerprint(request) #这就是判重的核心操作
if fp in self.fingerprints:
return True
self.fingerprints.add(fp)
if self.file:
self.file.write(fp+os.linesep)



scrapy架构流程的更多相关文章
- scrapy架构初探
scrapy架构初探 引言 Python即时网络爬虫启动的目标是一起把互联网变成大数据库.单纯的开放源代码并不是开源的全部,开源的核心是"开放的思想",聚合最好的想法.技术.人员, ...
- Scrapy架构概述
Scrapy架构概述 1, 从最初自己编写的spiders,获取到start_url,并且封装成Request对象. 2,通过engine(引擎)调度给SCHEDULER(Requests管理调度器) ...
- scrapy架构简介
一.scrapy架构介绍 1.结构简图: 主要组成部分:Spider(产出request,处理response),Pipeline,Downloader,Scheduler,Scrapy Engine ...
- 第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图 1.基本概念 2.反爬虫的目的 3.爬虫和反爬的对抗过程以及策略 scra ...
- Python -- Scrapy 架构概览
架构概览 本文档介绍了Scrapy架构及其组件之间的交互. 概述 接下来的图表展现了Scrapy的架构,包括组件及在系统中发生的数据流的概览(绿色箭头所示). 下面对每个组件都做了简单介绍,并给出了详 ...
- 二十四 Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
1.基本概念 2.反爬虫的目的 3.爬虫和反爬的对抗过程以及策略 scrapy架构源码分析图
- 一:SpringMVC架构流程
架构流程: 1.用户发送请求至前端控制器DispatcherServlet 2.DispatcherServlet收到请求调用HandlerMapping处理器映射器. 3.处理器映射器根据请求url ...
- 爬虫---scrapy架构和原理
scrapy是一个为了爬取网站数据, 提取结构性数据而编写的应用框架, 它是基于Twisted框架开发而来, 而Twisted框架是事件驱动的, 比较适合异步代码. 对会阻塞线程的操作, 包括访问数据 ...
- scrapy架构与目录介绍、scrapy解析数据、配置相关、全站爬取cnblogs数据、存储数据、爬虫中间件、加代理、加header、集成selenium
今日内容概要 scrapy架构和目录介绍 scrapy解析数据 setting中相关配置 全站爬取cnblgos文章 存储数据 爬虫中间件和下载中间件 加代理,加header,集成selenium 内 ...
随机推荐
- HDU-3400Line belt-三分再三分-求距离中要加esp
传送门:Line belt 参考:http://blog.csdn.net/hcbbt/article/details/39375763 题意:在一个平面途中,有一条路ab,还有一条路cd:假设在ab ...
- lightoj 1119 - Pimp My Ride(状压dp)
题目链接:http://www.lightoj.com/volume_showproblem.php?problem=1119 题解:状压dp存一下车有没有被搞过的状态就行. #include < ...
- R:ggplot2数据可视化——进阶(1)
,分为三个部分,此篇为Part1,推荐学习一些基础知识后阅读~ Part 1: Introduction to ggplot2, 覆盖构建简单图表并进行修饰的基础知识 Part 2: Customiz ...
- Disruptor中shutdown方法失效,及产生的不确定性源码分析
版权声明:原创作品,谢绝转载!否则将追究法律责任. Disruptor框架是一个优秀的并发框架,利用RingBuffer中的预分配内存实现内存的可重复利用,降低了GC的频率. 具体关于Disrupto ...
- Mysql的事务及行级锁
转自:http://www.cnblogs.com/edwinchen/p/4171866.html 以签到为例,每个用户每天只能签到一次,那么怎么去判断某个用户当天是否签到呢?因为当初表设计的时候, ...
- 【Spring】 IOC Base
一.关于容器 1. ApplicationContext和BeanFactory 2. 配置文件 XML方式 Java-configuration 方式 @Configuration 3. 初始化容器 ...
- Storm VS Flink ——性能对比
1.背景 Apache Flink 和 Apache Storm 是当前业界广泛使用的两个分布式实时计算框架.其中 Apache Storm(以下简称"Storm")在美团点评实时 ...
- ELKBR部署检测项目日志
ELK filebeat:具有日志收集功能,相比logstash,+filebeat更轻量,占用资源更少,适合客户端使用. redis消息队列选型:Redis 服务器通常都是用作 NoSQL 数据库, ...
- Java开发者薪资最低?程序员只能干到30岁?国外真的没有996?Intellij真的比Eclipse受欢迎?
Stack Overflow作为全球最大的程序设计领域的问答网站,每年都会出据一份开发者调查报告.近日,Stack Overflow公布了其第9次年度开发者调查报告(https://insights. ...
- elasticsearch集群扩容和容灾
elasticsearch专栏:https://www.cnblogs.com/hello-shf/category/1550315.html 一.集群健康 Elasticsearch 的集群监控信息 ...