考试安排查询脚本(CUP)
去年热情高涨的时候心血来潮做了个简易的查询脚本,限于当时技术水平(菜),实现得不是很好,这几天终于想起来填坑了。环境依赖:
brew install python3
pip3 install requests
pip3 install tkinter
pip3 install fuzzywuzzy
pip3 install xlrd
首先,CUP教务处考试安排通知一般是发布在网站的“考试通知”专栏里的。比如:
这样的一个通知,通常内部会有一个考试通知的xls表格文件。
打开以后:
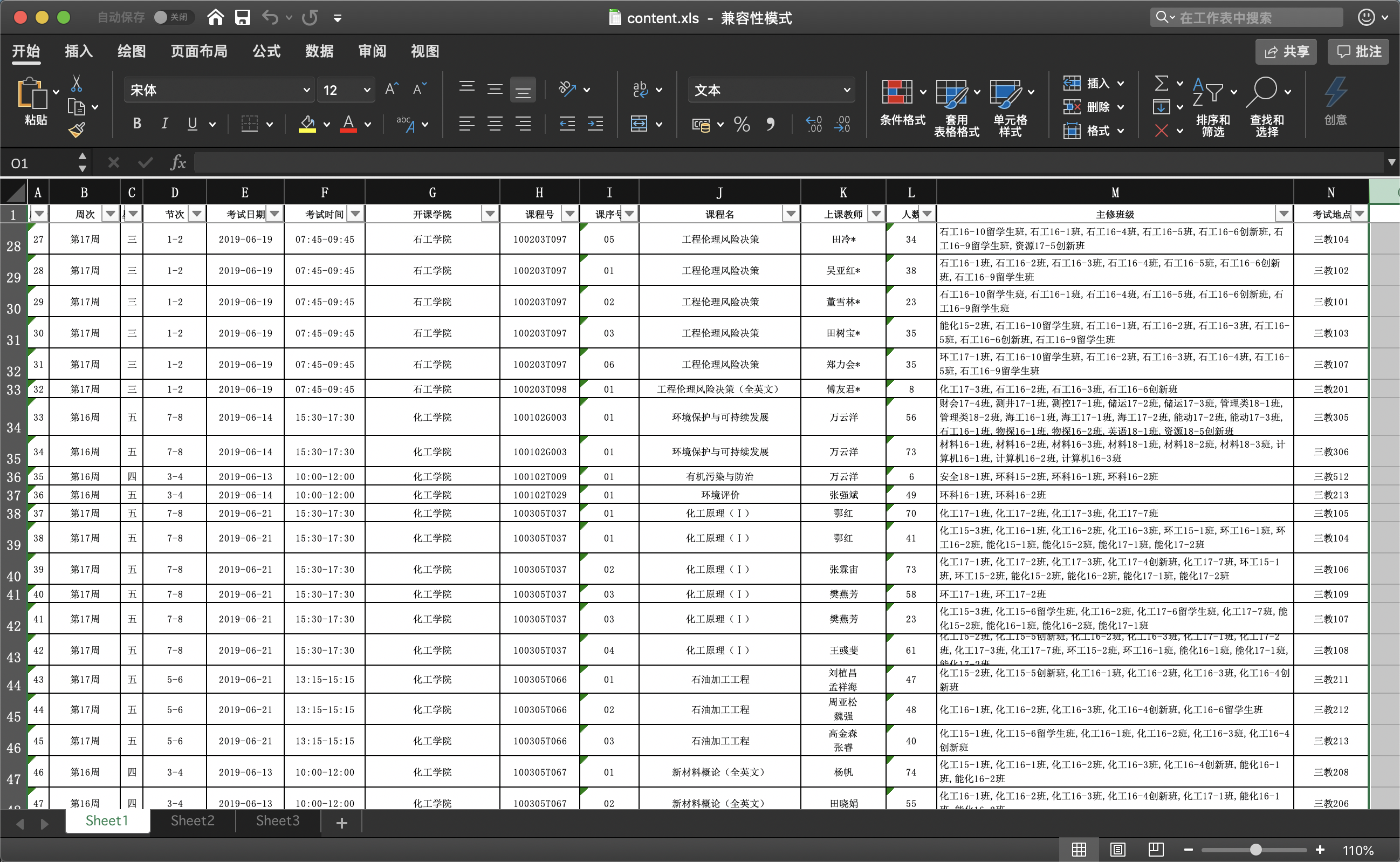
每次考试通知的格式都是一致的。
基于此,思路就来了,先输入考试通知发布网页的地址,然后程序自动获取到文件的下载地址,再自动将文件下载下来,得到考试安排信息。
代码:
def get_one_page(url, headers):
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
response.encoding = response.apparent_encoding
return response.text
return None
except RequestException:
return None def countPoint(UrlPart):
cnt = 0
for i in UrlPart:
if i != '.':
break
cnt += 1
return cnt def getNewXls(url):
html = get_one_page(url, headers=headers)
if not html:
return False
als = re.findall('<a.*?href="(.*?)"', html, re.S)
for a in als:
if a.endswith('xls'):
cnt = countPoint(a)
url = '/'.join(url.split('/')[:-cnt]) + a[cnt:]
break
content = requests.get(url, headers).content
with open('content.xls', 'wb') as f:
f.write(content)
return True
在得到考试安排信息后,我分析可以通过“课程&教师&班级”三种条件可以比较精确的搜索到要查询的考试安排。
通过这三个列名,可以建立一个简易的搜索字典:
data = {'课程名': {}, '上课老师': {}, '主修班级': {}}
def init():
xls = xlrd.open_workbook('content.xls')
global name_col, teacher_col, sc_col, sheet
sheet = xls.sheet_by_index(0)
keys = sheet.row_values(0)
for i in range(len(keys)):
if keys[i] == '课程名':
name_col = i
elif keys[i] == '上课教师':
teacher_col = i
elif keys[i] == '主修班级':
sc_col = i
if not name_col or not teacher_col or not sc_col:
exit('Unknown xls layout')
ls = sheet.col_values(name_col)
for i in range(1, len(ls)):
if ls[i] not in data['课程名']:
data['课程名'][ls[i]] = set()
data['课程名'][ls[i]].add(i)
ls = sheet.col_values(teacher_col)
for i in range(1, len(ls)):
if ls[i] not in data['上课老师']:
data['上课老师'][ls[i]] = set()
data['上课老师'][ls[i]].add(i)
ls = sheet.col_values(sc_col)
for i in range(1, len(ls)):
cls = ls[i].split(',')
for cl in cls:
if cl not in data['主修班级']:
data['主修班级'][cl] = set()
data['主修班级'][cl].add(i)
而考虑查询方便,必然不可能让用户(我)每次都输入精准的信息才能查到结果,这太不酷了。
所以我考虑间隔匹配+模糊匹配的方式来得到搜索结果。
间隔匹配:
def fm(string, ls):
res = []
match = '.*?'.join([i for i in string])
for i in ls:
if re.findall(match, i):
res.append((i, 100))
return res
模糊匹配:(这里使用了一个叫fuzzywuzzy的第三方库,只有间隔匹配失败后才会使用模糊匹配)
res = fm(aim, data[keys[i]].keys())
if not res:
res = process.extract(aim, data[keys[i]].keys(), limit=3)
那么如果用户提供了多个搜索条件怎么处理呢?答案是利用集合的并交运算来处理。
比如搜索表达式: xx&yy&zz。显然我们通过搜索算法可以得到三个独立集合分别为xx,yy和zz的结果,那么对这三个集合取交即可得到正解。
def search(exp):
if not pre_check():
return None
keys = ['课程名', '上课老师', '主修班级']
res_set = set()
flag = False
for i in range(len(exp)):
if i < 3:
aim = exp[i].strip()
if not aim:
continue
res = fm(aim, data[keys[i]].keys())
if not res:
res = process.extract(aim, data[keys[i]].keys(), limit=3)
ts = set()
for mth in res:
if mth[1]:
ts = ts.union(data[keys[i]][mth[0]])
if flag:
res_set = res_set.intersection(ts)
else:
res_set = res_set.union(ts)
flag = True
else:
break
res = ''
for line_num in res_set:
line = sheet.row_values(line_num)
res += '-' * 50 + '\n'
res += '课程名称:' + line[name_col] + '\n'
res += '授课教师:' + line[teacher_col].replace('\n', ',') + '\n'
cls = line[sc_col].split(',')
linkstr = ''
for i in range(len(cls)):
linkstr += cls[i]
if i + 1 == len(cls):
break
elif (i + 1) % 5 == 0:
linkstr += '\n' + ' ' * 9
else:
linkstr += ','
res += '主修班级:' + linkstr + '\n'
day = "%04d年%02d月%02d日" % xldate_as_tuple(line[4], 0)[:3]
res += '考试时间:' + day + '(周%s) ' % line[2] + line[5] + '\n'
res += '考试地点:' + line[-1].replace('\n', ',') + '\n'
return res
到这,脚本的硬核部分就结束了~
然后我们基于这份代码,撸一个GUI出来。
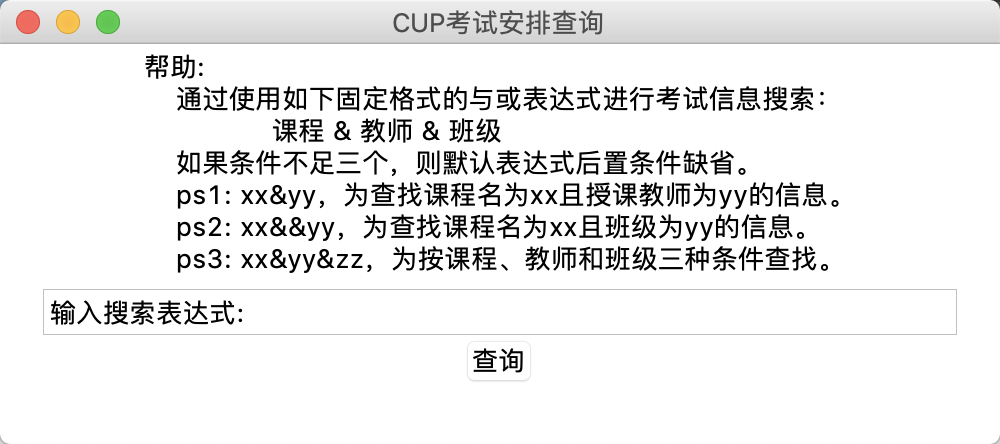
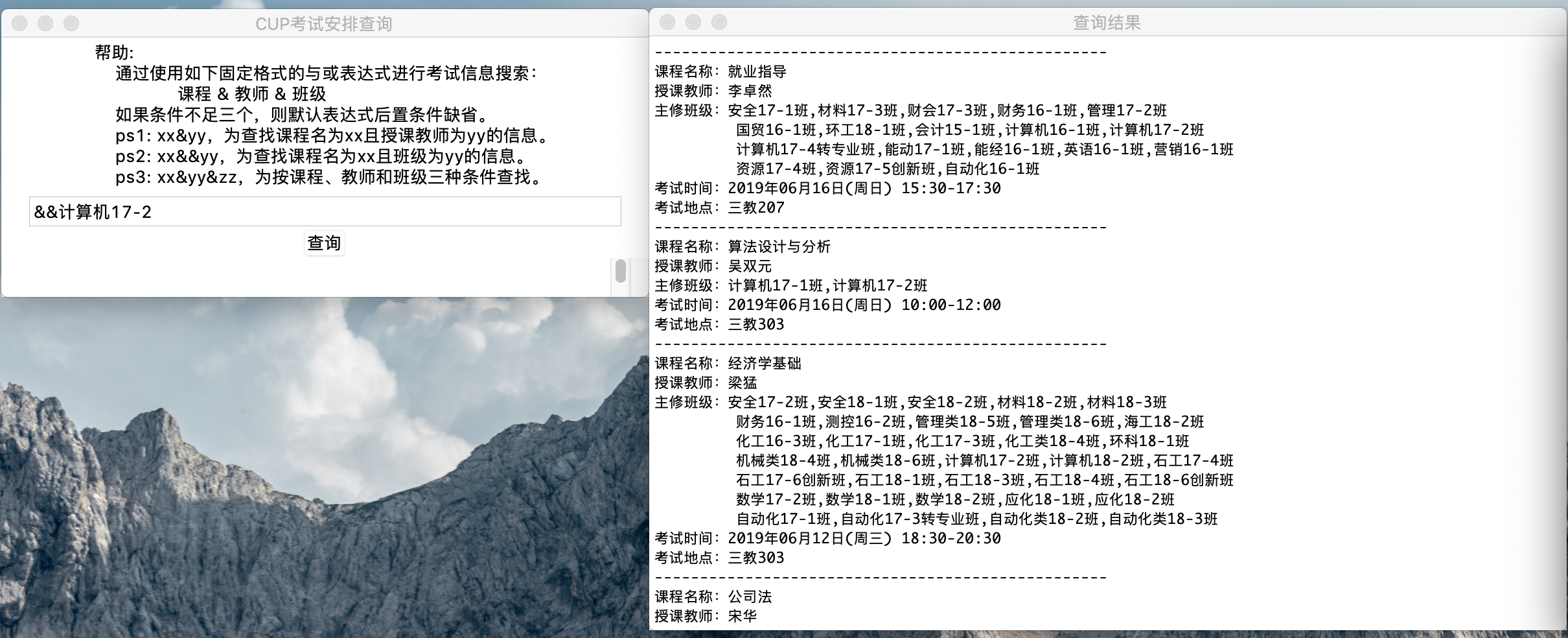
大功告成~!
GitHub开源地址:https://github.com/Rhythmicc/CUP_EXAM
考试安排查询脚本(CUP)的更多相关文章
- SQL2008数据表空间大小查询脚本
--尽量少用触发器,否则数据库增长很快,特别是关于登陆的数据表字段不要用出发器,一周左右能使得数据库增长1G的空间. --数据库表空间大小查询脚本 IF EXISTS (SELECT * FROM ...
- Oracle DBA 必须掌握的 查询脚本:
Oracle DBA 必须掌握的 查询脚本: 0:启动与关闭 orcle 数据库的启动与关闭 1:连接数据库 2:数据库开启状态的实现步骤: 2-1:启动数据库 2- ...
- 【Python】子域名查询脚本
脚本学习,多写写就会啦,来一发个人编写的超级无敌low的子域名查询脚本 #coding:utf-8 import re import requests import urllib import url ...
- 2019年计算机技术与软件专业技术资格(水平)考试安排v
根据<关于2019年度专业技术人员资格考试计划及有关问题的通知>(人社厅发[2018]142号)要求,2019年度计算机技术与软件专业技术资格(水平)考试(以下简称计算机软件资格考试)安排 ...
- MYSQL 查询脚本优化
业务需要,优化一段多表查询脚本. 总结下来,采取以下步骤. 分析语句 分析语句,了解逻辑,是否可以先优化逻辑. 查询语句的查询范围,是否是全表查询,如果是,尽量优化为按索引查询. 查看语句数量,是否有 ...
- 虚拟机压力测试延迟高的可能原因及 ILPIP 配置 / 查询脚本
测试初期 Client VM 的延迟结果正常: 测试后期 Client VM 的延迟偶尔突增/连接失败,越后期超高延迟(比如 30 秒)出现越多: 问题分析 造成这一现象的根本原因很可能是 SNAT( ...
- [SQL] 常用查询脚本
查询哪些存储过程使用了某个表 select b.name from syscomments a,sysobjects b where a.id=b.id and a.text LIKE '%ftblo ...
- django系列5.5--分组查询,聚合查询,F查询,Q查询,脚本中调用django环境
一.聚合查询 aggregate(*args, **args) 先引入需要的包,再使用聚合查询 #计算所有图书的平均价格 from django.db.models import Avg Book.o ...
- Oracle查询脚本优化
发现生产环境的Oracle数据库cpu使用率上升超过70%,其中一条查询语句达到每秒调用40多次.现在我们来观摩下该语句: select t.id,t.level,t.policy, t.type,t ...
随机推荐
- 宜信开源|手把手教你安装第一个LAIN应用
LAIN是宜信公司大数据创新中心开发的开源PaaS平台.在金融的场景下,LAIN 是为解放各个团队和业务线的生产力而设计的一个云平台.LAIN 为宜信大数据创新中心各个团队提供了统一的测试和生产环境, ...
- Spark学习之路(二)—— Spark开发环境搭建
一.安装Spark 1.1 下载并解压 官方下载地址:http://spark.apache.org/downloads.html ,选择Spark版本和对应的Hadoop版本后再下载: 解压安装包: ...
- spring boot + druid + mybatis + atomikos 多数据源配置 并支持分布式事务
文章目录 一.综述 1.1 项目说明 1.2 项目结构 二.配置多数据源并支持分布式事务 2.1 导入基本依赖 2.2 在yml中配置多数据源信息 2.3 进行多数据源的配置 三.整合结果测试 3.1 ...
- 《JavaScript 高级程序设计》读书笔记
文章目录 第三章 基本语法 第四章 变量.作用域和内存问题 第五章 应用类型 1. Array 类型 2. RegExp 类型 3. Function 类型 4. String 类型 第六章 面向对象 ...
- 新手怎么学JS?JavaScript基础入门
新手应该怎么学习JS?JavaScript入门 - 01 准备工作 在正式的学习JavaScript之前,我们先来学习一些小工具,帮助我们更好的学习和理解后面的内容. js代码位置 首先是如何编写Ja ...
- PHP输出缓冲及其应用
缓冲(buffer)是为了协调吞吐速度相差很大的设备之间数据传送而采用的技术,用来存放缓冲数据的区域叫缓冲区,在计算机科学领域,当数据从一个地方传送到另一个地方时,缓冲区被用来临时存储数据.与缓冲相似 ...
- centos7搭建基于SAMBA的网络存储
学习目标: 通过本实验理解Linux系统下SAMBA服务器和客户端的配置,实现客户机可自动挂载服务端的共享存储. 操作步骤: 1. SAMBA服务器搭建 2. SAMBA客户端配置 参考命令: ...
- 一篇文章让你理解Ceph的三种存储接口(块设备、文件系统、对象存储)
“Ceph是一个开源的.统一的.分布式的存储系统”,这是我们宣传Ceph时常说的一句话,其中“统一”是说Ceph可以一套存储系统同时提供块设备存储.文件系统存储和对象存储三种存储功能.一听这句话,具有 ...
- 第一个SpringBoot
Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程.该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置.用我 ...
- 分布式个人理解概述和dubbo实现简述
什么是分布式?为什么使用分布式? 个人有一些浅薄的理解希望可以批评指正,从概念和应用 两个方面概述: 一.概念:分布式也叫分布式服务,也就是说 他是 一种面向服务思想的程序设计和架构风格,典 ...