数据挖掘--K-means
K-Means方法是MacQueen1967年提出的。给定一个数据集合X和一个整数K(n),K-Means方法是将X分成K个聚类并使得在每个聚类中所有值与该聚类中心距离的总和最小。
K-Means聚类方法分为以下几步:
[1] 给K个cluster选择最初的中心点,称为K个Means。
[2] 计算每个对象和每个中心点之间的距离。
[3] 把每个对象分配给距它最近的中心点做属的cluster。
[4] 重新计算每个cluster的中心点。
[5] 重复2,3,4步,直到算法收敛。
以下几张图动态展示了这几个步骤:
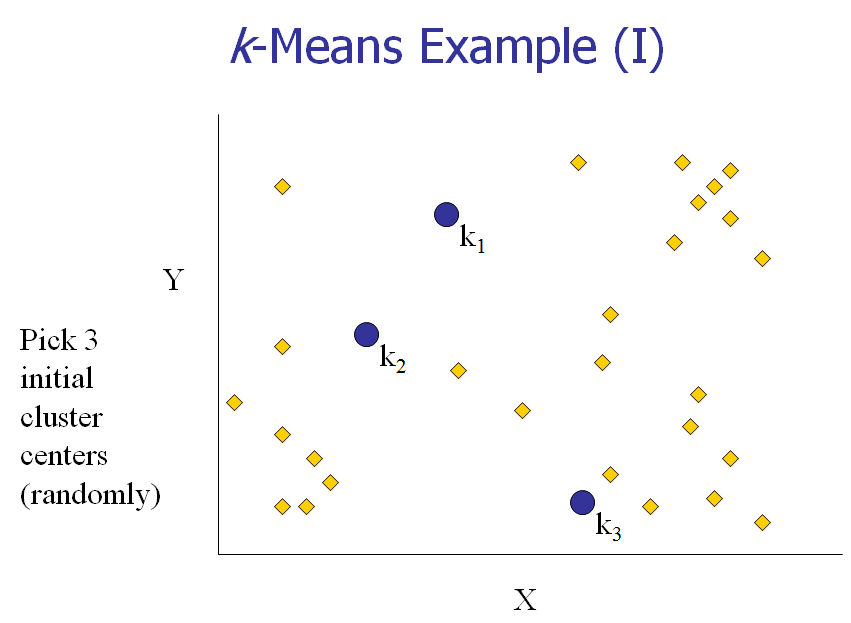
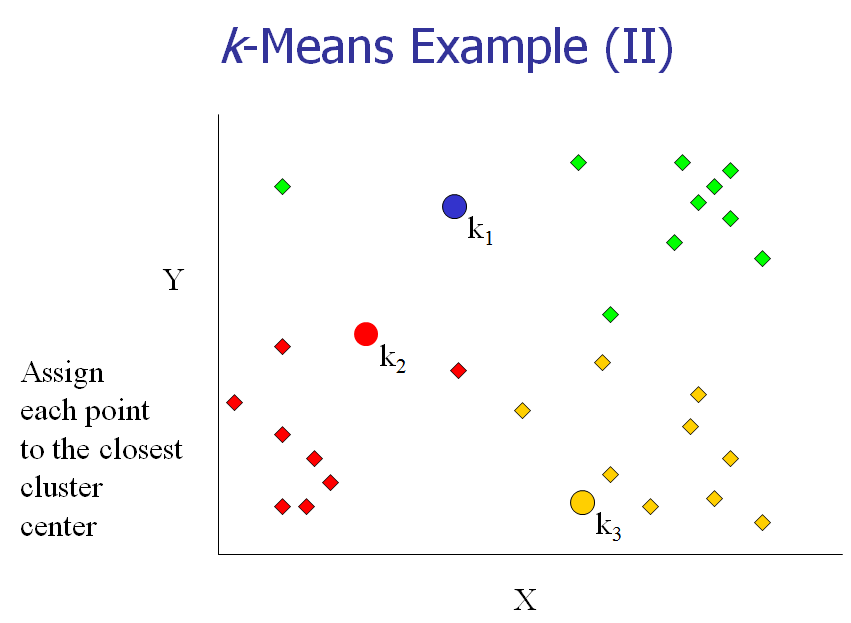


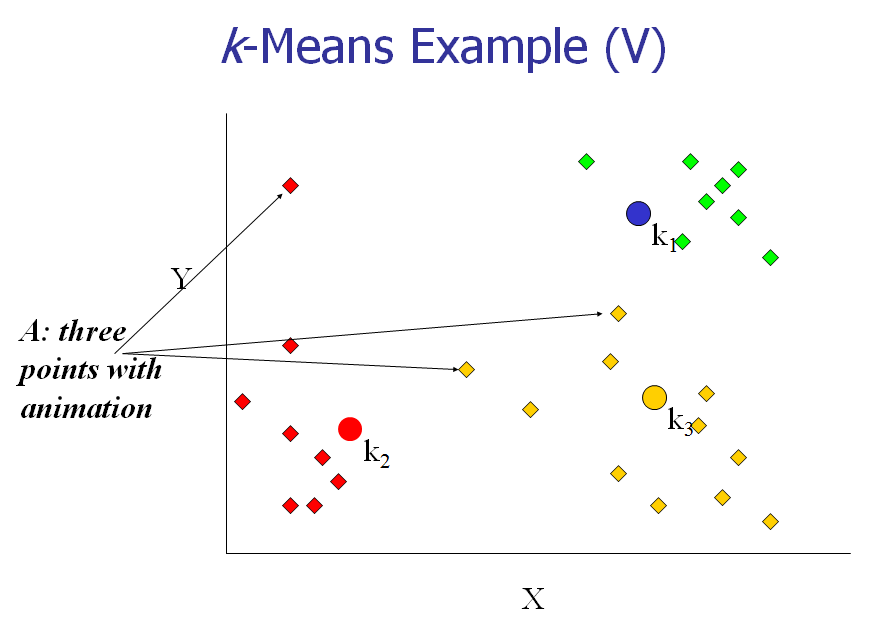


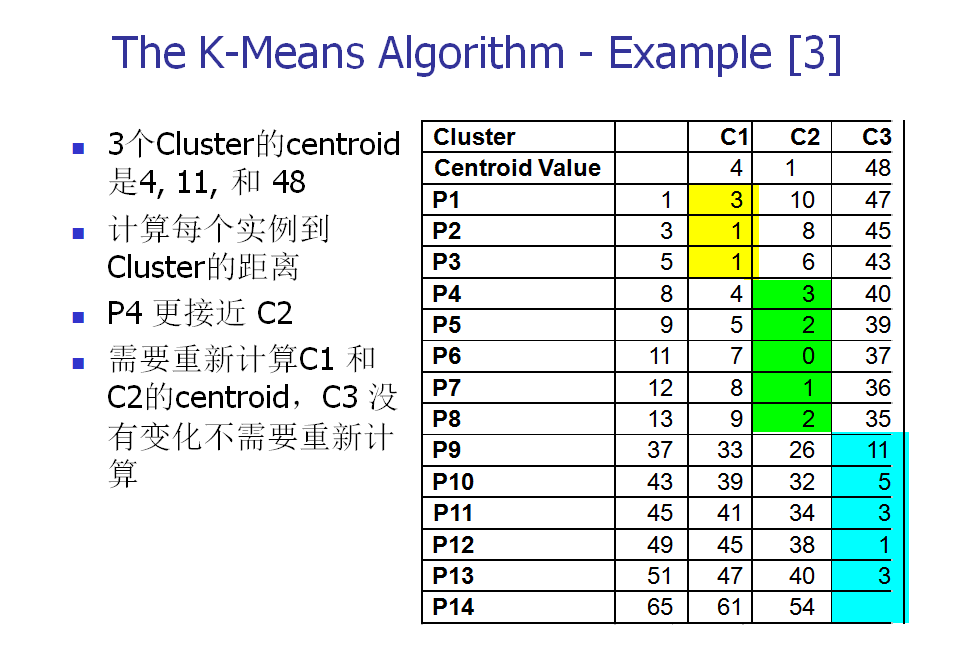
下面,我们以一个具体的例子来说明一下K-means算法的实现。
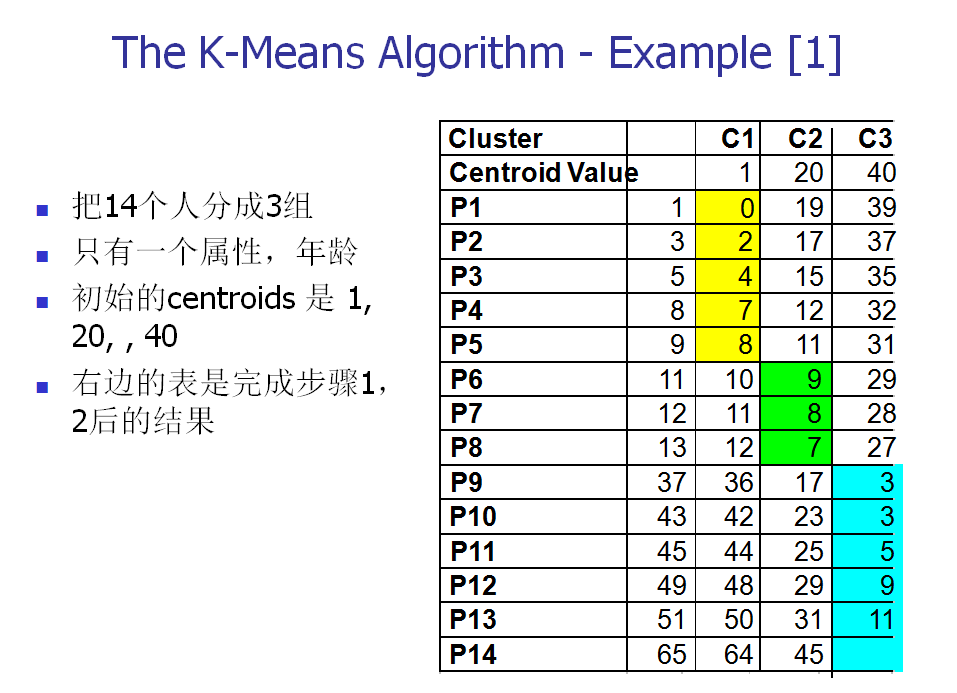


K-means算法的优缺点:
优点:
(1)对于处理大数据量具有可扩充性和高效率。算法的复杂度是O(tkn),其中n是对象的个数,k是cluster的个数,t是循环的次数,通常k,t<<n。
(2)可以实现局部最优化,如果要找全局最优,可以用退火算法或者遗传算法
缺点:
(1)Cluster的个数必须事先确定,在有些应用中,事先并不知道cluster的个数。
(2)K个中心点必须事先预定,而对于有些字符属性,很难确定中心点。
(3)不能处理噪音数据。
(4)不能处理有些分布的数据(例如凹形)
K-Means方法的变种
(1) K-Modes :处理分类属性
(2) K-Prototypes:处理分类和数值属性
(3) K-Medoids
它们与K-Means方法的主要区别在于:
(1)最初的K个中心点的选择不同。
(2)距离的计算方式不同。
(3)计算cluster的中心点的策略不同。
数据挖掘--K-means的更多相关文章
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- 软件——机器学习与Python,聚类,K——means
K-means是一种聚类算法: 这里运用k-means进行31个城市的分类 城市的数据保存在city.txt文件中,内容如下: BJ,2959.19,730.79,749.41,513.34,467. ...
- 快速查找无序数组中的第K大数?
1.题目分析: 查找无序数组中的第K大数,直观感觉便是先排好序再找到下标为K-1的元素,时间复杂度O(NlgN).在此,我们想探索是否存在时间复杂度 < O(NlgN),而且近似等于O(N)的高 ...
- 数据挖掘十大算法--K-均值聚类算法
一.相异度计算 在正式讨论聚类前,我们要先弄清楚一个问题:怎样定量计算两个可比較元素间的相异度.用通俗的话说.相异度就是两个东西区别有多大.比如人类与章鱼的相异度明显大于人类与黑猩猩的相异度,这是能 ...
- 网络费用流-最小k路径覆盖
多校联赛第一场(hdu4862) Jump Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Ot ...
- numpy.ones_like(a, dtype=None, order='K', subok=True)返回和原矩阵一样形状的1矩阵
Return an array of ones with the same shape and type as a given array. Parameters: a : array_like Th ...
- K-MEANS算法总结
K-MEANS算法 摘要:在数据挖掘中,K-Means算法是一种 cluster analysis 的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法. 在数据挖掘中,K-M ...
- 关于K-Means算法
在数据挖掘中,K-Means算法是一种cluster analysis的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法. 问题 K-Means算法主要解决的问题如下图所示. ...
- 当我们在谈论kmeans(3)
本系列意在长期连载分享,内容上可能也会有所删改: 因此如果转载,请务必保留源地址,非常感谢! 博客园:http://www.cnblogs.com/data-miner/(暂时公式显示有问题) ...
- K-Means 算法(转载)
K-Means 算法 在数据挖掘中, k-Means 算法是一种 cluster analysis 的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法. 问题 K-Means ...
随机推荐
- windows双网卡绑定
windows双网卡绑定 开门贱山: 以下内容纯属抄袭,如有雷同,也是醉了~~!! ————————————— ...
- MySQL 部署分布式架构 MyCAT (五)
分片(水平拆分) 4.全局表 业务使用场景: 如果你的业务中有些数据类似于数据字典,比如配置文件的配置, 常用业务的配置或者数据量不大很少变动的表,这些表往往不是特别大, 而且大部分的业务场景都会用到 ...
- Python的 Datetime 、 Logging 模块
Datetime模块 datetime是python处理时间和日期的标准库 类名 date类 日期对象,常用的属性有 year . month . day time类 时间 ...
- 08 在设备树里描述platform_device【转】
转自:https://blog.csdn.net/jklinux/article/details/78575281 版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原 ...
- jieba、NLTK学习笔记
中文分词 - jiebaimport re import jieba news_CN = ''' 央视315晚会曝光湖北省知名的神丹牌.莲田牌“土鸡蛋”实为普通鸡蛋冒充,同时在商标上玩猫腻, 分别注册 ...
- 肖哥讲jquery:
jquery 是一个模块 一个库 js封装的一个库 导入jq <script src="jquery.js"></script> <script ...
- JDK的小Bug你了解么?
用了这么长时间的JDK了,有没有老铁发现JDK的bug呢?从最早版本的JDK1.2到现在普及开的JDK1.8以来,JAVA经历了这么多年的风风雨雨,依然坚持在一线上,是不是感觉很神奇,但是,有没有多 ...
- Spring Security OAuth2学习
什么是 oAuth oAuth 协议为用户资源的授权提供了一个安全的.开放而又简易的标准.与以往的授权方式不同之处是 oAuth 的授权不会使第三方触及到用户的帐号信息(如用户名与密码),即第三方无需 ...
- MySQL统计信息简介
作者:王小龙@网易乐得DBA 原文地址: http://mp.weixin.qq.com/s/698g5lm9CWqbU0B_p0nLMw MySQL执行SQL会经过SQL解析和查询优化的过程,解析器 ...
- flask 第一章
1.安装flask 首先安装python的虚拟环境,每个环境之间的包并不会产生冲突 ,相当于一个单独的 小空间. 由于自己使用的是windows开发环境 所以安装虚拟包的命令如下 pip inst ...