药店商品销量分析(python)
一、数据分析的步骤
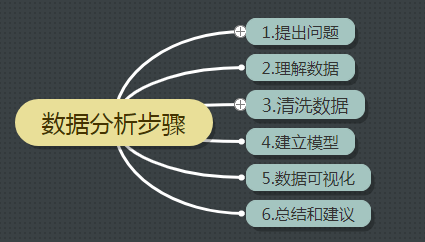
二、提出问题
分析药店商品销售情况
1)月均消费次数
2)月均消费金额
3)客单价
4)消费趋势
5)热销商品、滞销商品
三、理解数据

销售数据源为excel文件
字段的含义:
共有6579条销售数据
共有7个字段分别为:购买时间、社保卡号、商品编码、商品名称、销售数量、应收金额、实收金额
四、清洗数据

本次分析采用Jupyter Notebook分析,数据集为本地excel文件
(1)选择子集
本次分析的excel工作簿里面只有一个工作表
#导入数据分析包
import pandas as pd
salesDf = pd.read_excel('./朝阳医院2018年销售数据.xlsx')
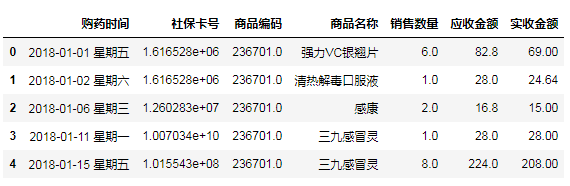
# head()打印前5行
# df = pd.read_excel(path,sheet_name=4,header=6)# 指定序号为4的工作簿,用第6行做为行索引
"""sheet_name,工作簿的序号从0开始 """
#header从0开始计数
print(salesDf.head())
(2)列表重命名
#字典:旧列名和新列名对应关系
colNameDict = {'购药时间':'销售时间'} '''
inplace=False,数据框本身不会变,而会创建一个改动后新的数据框,
默认的inplace是False
inplace=True,数据框本身会改动
'''
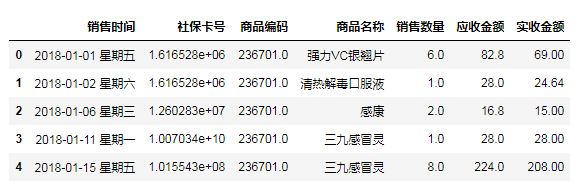
salesDf.rename(columns = colNameDict,inplace=True)
salesDf.head()
(3)删除重复值
print('删除重复值前大小',salesDf.shape)
# 删除重复销售记录
salesDf = salesDf.drop_duplicates()
print('删除重复值后大小',salesDf.shape)
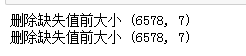
删除前后数据进行对比,发现本数据集没有重复值
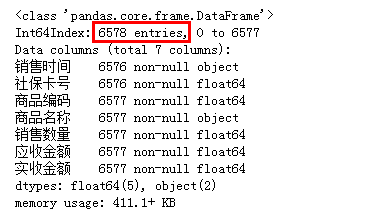
(4)缺失值处理 info也可以查看字段的数据类型
"""整体观察"""
df.info()
"""如果缺失的数据很少,可以直接进行删除"""
"""如果缺失的数据量较大,超过了10%,要根据业务情况,进行删除或填充"""
"""填充数据时,可以采用均值,中位数进行填充"""
"""如果数据记录之间有明显的顺序关系,可以采用附近相邻的数据进行填充"""
总共有6578行数据只有2个缺失值,可以直接删除
"""删除缺失值"""
df.dropna()# 删除出现缺失值得行
# df.dropna(axis=1) df.dropna(how='all') # 当整行数据都为nan 时才删除
df.dropna(how='any') # 只要出现缺失值就删除
df.dropna(subset=['房价'])# 指定列出现缺失值才删除
print('删除缺失后大小',salesDf.shape)
# 查询是否有空值
print(salesDf.isnull().any())

处理后,结果显示没有缺失值
(5)一致化处理
#查看每一列的数据类型
salesDf.dtypes

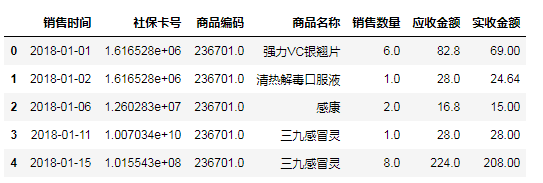
只需要将销售时间改为:字符串转换为日期数据类型
#获取“销售时间”这一列
timeSer=salesDf.loc[:,'销售时间']
#对字符串进行分割,获取销售日期
timeList=[]
for value in timeSer:
#例如2018-01-01 星期五,分割后为:2018-01-01
dateStr=value.split(' ')[0]
timeList.append(dateStr) #将列表转行为一维数据Series类型
timeSer=pd.Series(timeList)
print(timeSer.head())

#修改销售时间这一列的值
salesDf.loc[:,'销售时间']=dateSer
salesDf.head()
'''
数据类型转换:字符串转换为日期
'''
#errors='coerce' 如果原始数据不符合日期的格式,转换后的值为空值NaT
#format 是你原始数据中日期的格式
salesDf.loc[:,'销售时间']=pd.to_datetime(salesDf.loc[:,'销售时间'],
format='%Y-%m-%d',
errors='coerce')
# 查询是否有空值
print(salesDf.isnull().any())
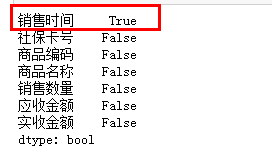
'''
转换日期过程中不符合日期格式的数值会被转换为空值,
这里删除列(销售时间)中为空的行
'''
salesDf=salesDf.dropna(subset=['销售时间'],how='any') # 查询是否有空值
print(salesDf.isnull().any())

(6)数据排序
按照销售时间进行排序
'''
by:按哪几列排序
ascending=True 表示升序排列,
ascending=True表示降序排列
na_position=first表示排序的时候,把空值放到前列,这样可以比较清晰的看到哪些地方有空值
官网文档:https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.sort_values.html
'''
#按销售日期进行升序排列
salesDf=salesDf.sort_values(by='销售时间',
ascending=True,
na_position='first')
print('排序后的数据集')
salesDf.head(3)

#重命名行名(index):排序后的列索引值是之前的行号,需要修改成从0到N按顺序的索引值
salesDf=salesDf.reset_index(drop=True)
salesDf.head()
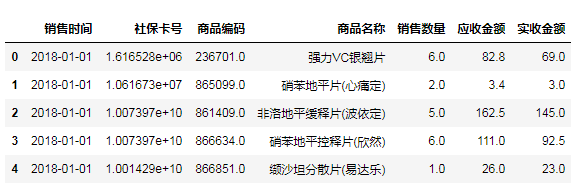
(7)异常值处理
#描述指标:查看出“销售数量”值不能小于0
salesDf.describe()
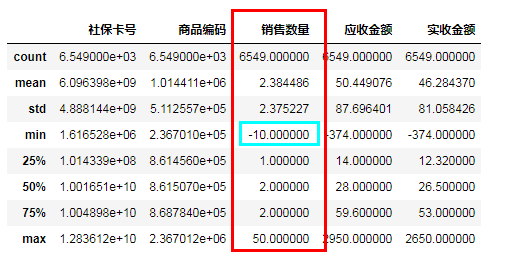
#删除异常值:通过条件判断筛选出数据
#查询条件
querySer=salesDf.loc[:,'销售数量']>0
#应用查询条件
print('删除异常值前:',salesDf.shape) # 筛选数据 salesDf=salesDf.loc[querySer,:] print('删除异常值后:',salesDf.shape)
print(salesDf.head())

五、构建模型
(1)业务指标1:月均消费次数=总消费次数 / 月份数
'''
总消费次数:同一天内,同一个人发生的所有消费算作一次消费
#根据列名(销售时间,社区卡号),如果这两个列值同时相同,只保留1条,将重复的数据删除
''' kpi1_Df=salesDf.drop_duplicates(
subset=['销售时间', '社保卡号']
) #总消费次数:有多少行
# shape几行几列
totalI=kpi1_Df.shape[0] print('总消费次数=',totalI)
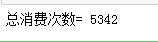
'''
计算月份数:时间范围
'''
#第1步:按销售时间升序排序
kpi1_Df=kpi1_Df.sort_values(by='销售时间',
ascending=True)
#重命名行名(index)
kpi1_Df=kpi1_Df.reset_index(drop=True)
#第2步:获取时间范围
#最小时间值
startTime=kpi1_Df.loc[0,'销售时间']
#最大时间值 totallI总行数
endTime=kpi1_Df.loc[totalI-1,'销售时间'] #第3步:计算月份数
#天数
daysI=(endTime-startTime).days
#月份数: 运算符“//”表示取整除
#返回商的整数部分,例如9//2 输出结果是4
monthsI=daysI//30
print('月份数:',monthsI)
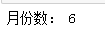
#业务指标1:月均消费次数=总消费次数 / 月份数
kpi1_I=totalI // monthsI
print('业务指标1:月均消费次数=',kpi1_I)
业务指标1:月均消费次数= 890
(2)指标2:月均消费金额 = 总消费金额 / 月份数
#总消费金额
totalMoneyF=salesDf.loc[:,'实收金额'].sum()
#月均消费金额
monthMoneyF=totalMoneyF / monthsI
print('业务指标2:月均消费金额=',monthMoneyF)
业务指标2:月均消费金额= 50668.35166666666
(3)指标3:客单价=总消费金额 / 总消费次数
'''
totalMoneyF:总消费金额
totalI:总消费次数
'''
pct=totalMoneyF / totalI
print('客单价:',pct)
客单价: 56.909417821040805
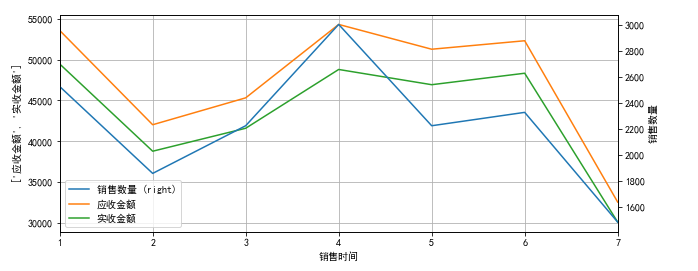
(4)指标4:消费趋势,画图:折线图
#在进行操作之前,先把数据复制到另一个数据框中,防止对之前清洗后的数据框造成影响
groupDf=salesDf
#第1步:重命名行名(index)为销售时间所在列的值
groupDf.index=groupDf['销售时间']
groupDf.head()
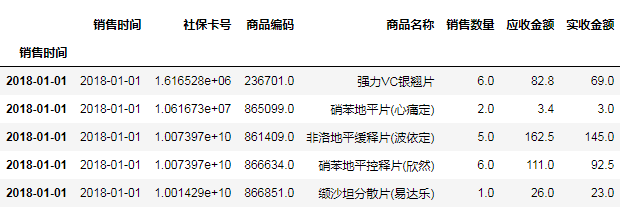
#第2步:分组 print(groupDf.index.month)
gb=groupDf.groupby(groupDf.index.month)

# Pandas 无法显示中文问题 解决方案##
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
import matplotlib.pyplot as plt
ax = data_mounth.plot(
secondary_y=['销售数量'],
x_compat=True,
grid=True,figsize=(10,4))
ax.right_ax.set_ylabel('销售数量')
ax.set_ylabel(['应收金额','实收金额'])
#ax.set_ylabel()
plt.show()
(5)热销商品、滞销商品
product = salesDf.groupby('商品名称').count()
#print(product)
# print(type(product))
sum_product = product.loc[:,'销售数量']
# print(sum_product)
# 可以看出商品整体的销量情况
print(sum_product.sort_values(ascending=True))


六、总结和建议
药店商品销量分析(python)的更多相关文章
- 用Python爬取分析【某东618】畅销商品销量数据,带你看看大家都喜欢买什么!
618购物节,辰哥准备分析一波购物节大家都喜欢买什么?本文以某东为例,Python爬取618活动的畅销商品数据,并进行数据清洗,最后以可视化的方式从不同角度去了解畅销商品中,名列前茅的商品是哪些?销售 ...
- Python 爬取淘宝商品数据挖掘分析实战
Python 爬取淘宝商品数据挖掘分析实战 项目内容 本案例选择>> 商品类目:沙发: 数量:共100页 4400个商品: 筛选条件:天猫.销量从高到低.价格500元以上. 爬取淘宝商品 ...
- Kaggle 商品销量预测季军方案出炉,应对时间序列问题有何妙招
https://www.leiphone.com/news/201803/fPnpTdrkvUHf7uAj.html 雷锋网 AI 研习社消息,Kaggle 上 Corporación Favorit ...
- 电商打折套路分析 —— Python数据分析练习
电商打折套路分析 ——2016天猫双十一美妆数据分析 数据简介 此次分析的数据来自于城市数据团对2016年双11天猫数据的采集和整理,原始数据为.xlsx格式 包括update_time/id/tit ...
- B2C电子商务系统研发——商品SKU分析和设计(二)
转:http://www.cnblogs.com/winstonyan/archive/2012/01/07/2315886.html 上文谈到5种商品SKU设计模式,本文将做些细化说明. 笔者研究过 ...
- 让ecshop显示商品销量或者月销量
首先,ecshop的信息显示模块在. ./includes/lib_goods.php文件 在其末尾添加下面这个函数 月销量:(和总销量二选一) function ec_buysum($goods_i ...
- ecshop获取商品销量函数
以下函数会获取订单状态为已完成的订单中该商品的销量,此函数放在lib_goods.php文件中即可调用 /** * 获取商品销量 * * @access public * @param ...
- arp协议分析&python编程实现arp欺骗抓图片
arp协议分析&python编程实现arp欺骗抓图片 序 学校tcp/ip协议分析课程老师布置的任务,要求分析一种网络协议并且研究安全问题并编程实现,于是我选择了研究arp协议,并且利用pyt ...
- [深度分析] Python Web 开发框架 Bottle
[深度分析] Python Web 开发框架 Bottle(这个真的他妈的经典!!!) 作者:lhf2009913 Bottle 是一个非常精致的WSGI框架,它提供了 Python Web开发中需要 ...
随机推荐
- 算法问题实战策略 PICNIC
下面是另一道搜索题目的解答过程题目是<算法问题实战策略>中的一题oj地址是韩国网站 连接比较慢 https://algospot.com/judge/problem/read/PICNIC ...
- What is Market Intelligence and how is it Used?
https://blog.globalwebindex.com/marketing/market-intelligence/ Market intelligence is the gathering ...
- vue项目中引入iconfont
背景 对于前端而言,图标的发展可谓日新月异.从img标签,到雪碧图,再到字体图标,svg,甚至svg也有了类似于雪碧图的方案svg-sprite-loader.雪碧图没有什么好讲的了,只是简单地利用了 ...
- java基础(19):List、Set
1. List接口 我们掌握了Collection接口的使用后,再来看看Collection接口中的子类,他们都具备那些特性呢? 接下来,我们一起学习Collection中的常用几个子类(List集合 ...
- Python爬取Boss直聘,帮你获取全国各类职业薪酬榜
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 王翔 清风Python PS:如有需要Python学习资料的小伙伴 ...
- PHP+Mysql查询上一篇和下一篇文章实例
简单的PHP+Mysql查询上一篇和下一篇文章实例,并输出上一篇和下一篇文章的标题和链接,适合新手学习 获取当前浏览文章id: $id = isset($_GET['id']) > 0 ? in ...
- 1042. Flower Planting With No Adjacent
题意: 本题题意为: 寻找一个花园的涂色方案,要求 1.花园和花园之间,不能有路径连接的,不能涂成相同颜色的 一共有4中颜色,花园和花园之间,至多有三条路径 我菜了 - - ,又没做出来.. 看答案 ...
- 【转载】每个 Android 开发者必须知道的消息机制问题总结
Android的消息机制几乎是面试必问的话题,当然也并不是因为面试,而去学习,更重要的是它在Android的开发中是必不可少的,占着举足轻重的地位,所以弄懂它是很有必要的.下面就来说说最基本的东西. ...
- (转载)林轩田机器学习基石课程学习笔记1 — The Learning Problem
(转载)林轩田机器学习基石课程学习笔记1 - The Learning Problem When Can Machine Learn? Why Can Machine Learn? How Can M ...
- Vue实战狗尾草博客管理平台第四章
本章主要内容如下: 填补上期的坑. iconfont仓库的关联,引入. 开发登录页面 填坑 上期中我们功能都已正常使用.但不知道有没有小伙伴测试过error页面,当访问地址不存在时,路由是否能正常挑战 ...