降维和PCA
- 数据在低维下更容易处理、更容易使用;
- 相关特征,特别是重要特征更能在数据中明确的显示出来;如果只有两维或者三维的话,更便于可视化展示;
- 去除数据噪声
- 降低算法开销
去除平均值计算协方差矩阵计算协方差矩阵的特征值和特征向量将特征值从大到小排序保留最上面的N个特征向量将数据转换到上述N个特征向量构建的新空间中
# 加载数据的函数def loadData(filename, delim = '\t'):fr = open(filename)stringArr = [line.strip().split(delim) for line in fr.readlines()]datArr = [map(float,line) for line in stringArr]return mat(datArr)# =================================# 输入:dataMat:数据集# topNfeat:可选参数,需要应用的N个特征,可以指定,不指定的话就会返回全部特征# 输出:降维之后的数据和重构之后的数据# =================================def pca(dataMat, topNfeat=9999999):meanVals = mean(dataMat, axis=0)# axis = 0表示计算纵轴meanRemoved = dataMat - meanVals #remove meancovMat = cov(meanRemoved, rowvar=0)# 计算协方差矩阵eigVals,eigVects = linalg.eig(mat(covMat))# 计算特征值(eigenvalue)和特征向量eigValInd = argsort(eigVals) #sort, sort goes smallest to largesteigValInd = eigValInd[:-(topNfeat+1):-1] #cut off unwanted dimensionsredEigVects = eigVects[:,eigValInd] #reorganize eig vects largest to smallestlowDDataMat = meanRemoved * redEigVects#transform data into new dimensionsreconMat = (lowDDataMat * redEigVects.T) + meanValsreturn lowDDataMat, reconMat
filename = r'E:\ml\machinelearninginaction\Ch13\testSet.txt'dataMat = loadData(filename)lowD, reconM = pca(dataMat, 1)
def plotData(dataMat,reconMat):fig = plt.figure()ax = fig.add_subplot(111)# 绘制原始数据ax.scatter(dataMat[:, 0].flatten().A[0], dataMat[:,1].flatten().A[0], marker='^', s = 90)# 绘制重构后的数据ax.scatter(reconMat[:,0].flatten().A[0], reconMat[:,1].flatten().A[0], marker='o', s = 10, c='red')plt.show()
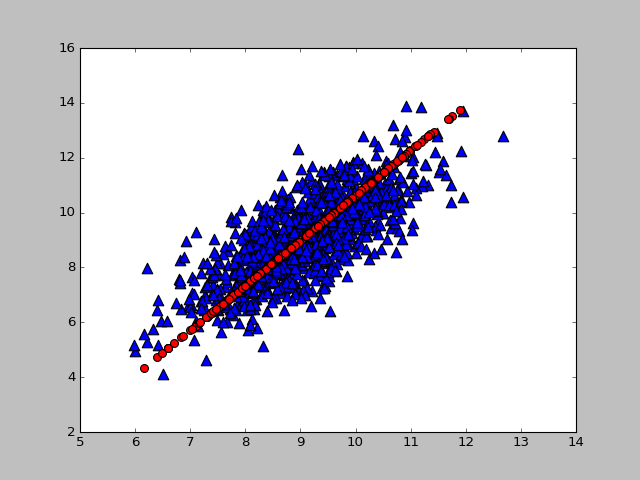
lowD, reconM = pca(dataMat, 2)
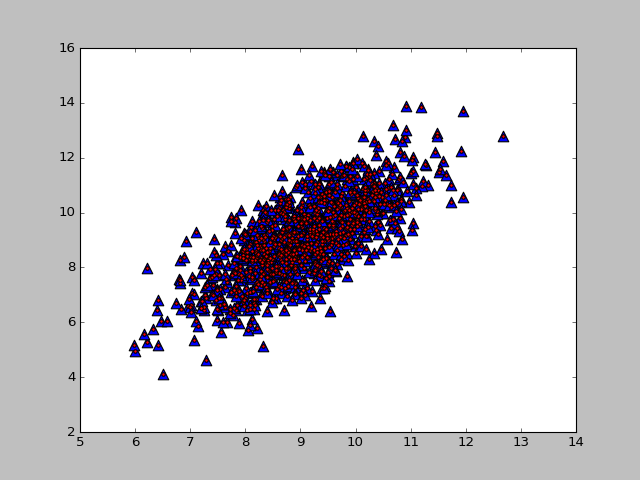
本文中只用了一个比较小的数据集来展示和验证PCA算法。
降维和PCA的更多相关文章
- 机器学习--PCA降维和Lasso算法
1.PCA降维 降维有什么作用呢?数据在低维下更容易处理.更容易使用:相关特征,特别是重要特征更能在数据中明确的显示出来:如果只有两维或者三维的话,更便于可视化展示:去除数据噪声降低算法开销 常见的降 ...
- PCA 降维算法详解 以及代码示例
转载地址:http://blog.csdn.net/watkinsong/article/details/38536463 1. 前言 PCA : principal component analys ...
- 从矩阵(matrix)角度讨论PCA(Principal Component Analysis 主成分分析)、SVD(Singular Value Decomposition 奇异值分解)相关原理
0. 引言 本文主要的目的在于讨论PAC降维和SVD特征提取原理,围绕这一主题,在文章的开头从涉及的相关矩阵原理切入,逐步深入讨论,希望能够学习这一领域问题的读者朋友有帮助. 这里推荐Mit的Gilb ...
- kaggle 实战 (1): PCA + KNN 手写数字识别
文章目录 加载package read data PCA 降维探索 选择50维度, 拆分数据为训练集,测试机 KNN PCA降维和K值筛选 分析k & 维度 vs 精度 预测 生成提交文件 本 ...
- [OpenCV] Face Detection
即将进入涉及大量数学知识的阶段,先读下“别人家”的博文放松一下. 读罢该文,基本能了解面部识别领域的整体状况. 后生可畏. 结尾的Google Facenet中的2亿数据集,仿佛隐约听到:“你们都玩儿 ...
- paper 50 :人脸识别简史与近期进展
自动人脸识别的经典流程分为三个步骤:人脸检测.面部特征点定位(又称Face Alignment人脸对齐).特征提取与分类器设计.一般而言,狭义的人脸识别指的是"特征提取+分类器"两 ...
- 【学习笔记】非监督学习-k-means
目录 k-means k-means API k-means对Instacart Market用户聚类 Kmeans性能评估指标 Kmeans性能评估指标API Kmeans总结 无监督学习,顾名思义 ...
- GoogLeNet 改进之 Inception-v2/v3 解读
博主在前一篇博客中介绍了GoogLeNet 之 Inception-v1 解读中的结构和思想.Inception的计算成本也远低于VGGNet.然而,Inception架构的复杂性使得更难以对网络进行 ...
- [CNN] Face Detection
即将进入涉及大量数学知识的阶段,先读下“别人家”的博文放松一下. 读罢该文,基本能了解面部识别领域的整体状况. 后生可畏. 结尾的Google Facenet中的2亿数据集,仿佛隐约听到:“你们都玩儿 ...
随机推荐
- 9-1、大型项目的接口自动化实践记录----数据库结果、JSON对比
上一篇写了如何从DB获取预期.实际结果,这一篇分别对不同情况说下怎么进行对比. PS:这部分在JSON对比中也适用. 1.结果只有一张表,只有一条数据 数据格式:因为返回的是dicts_list的格式 ...
- MyBatis之foreach
foreach foreach 元素是非常强大的,它允许你指定一个集合,声明集合项和索引变量,它们可以用在元素体内.它也允许你指定开放和关闭的字符串,在迭代之间放置分隔符.这个元素是很智能的,它不会偶 ...
- Golang高效实践之array、slice、map
前言 Golang的slice类型为连续同类型数据提供了一个方便并且高效的实现方式.slice的实现是基于array,slice和map一样是类似于指针语义,传递slice和map并不涉及底层数据结构 ...
- 算法与数据结构基础 - 合并查找(Union Find)
Union Find算法基础 Union Find算法用于处理集合的合并和查询问题,其定义了两个用于并查集的操作: Find: 确定元素属于哪一个子集,或判断两个元素是否属于同一子集 Union: 将 ...
- 三角函数与JavaScript
1. 三角函数 sin&(求对边与斜边的比值) cos&(邻边与斜边的比值) tan&(对边与邻边的比值) 2.JavaScript的函数的使用 Math.sin() Mat ...
- Yii2 登录报错
当用数据库登录系统报如下错误时 PHP Recoverable Error – yii\base\ErrorException Argument 1 passed to yii\web\User::l ...
- 在centos6系列vps装Tomcat8.0
In the following tutorial you will learn how to install and set-up Apache Tomcat 8 on your CentOS 6 ...
- React单页面应用使用antd的锚点跳转失效
首先在react项目中引用antd的锚点 import {Anchor} from 'antd';const { Link } = Anchor; <Anchor> <Link hr ...
- Unity进阶之ET网络游戏开发框架 04-资源打包
版权申明: 本文原创首发于以下网站: 博客园『优梦创客』的空间:https://www.cnblogs.com/raymondking123 优梦创客的官方博客:https://91make.top ...
- nginx之gzip压缩提升网站速度
目录: 为啥使用gzip压缩 nginx使用gzip gzip的常用配置参数 nginx配置gzip 注意 为啥使用gzip压缩 开启nginx的gzip压缩,网页中的js,css等静态资源的大小会大 ...