Storm 学习之路(八)—— Storm集成HDFS和HBase
一、Storm集成HDFS
1.1 项目结构
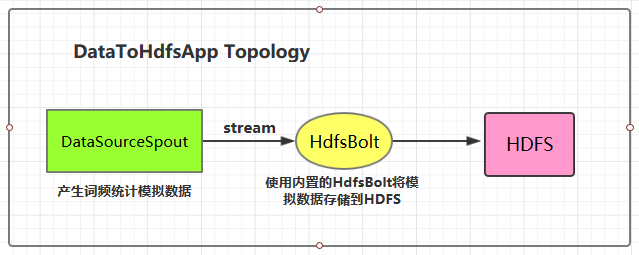
本用例源码下载地址:storm-hdfs-integration
1.2 项目主要依赖
项目主要依赖如下,有两个地方需要注意:
- 这里由于我服务器上安装的是CDH版本的Hadoop,在导入依赖时引入的也是CDH版本的依赖,需要使用
<repository>标签指定CDH的仓库地址; hadoop-common、hadoop-client、hadoop-hdfs均需要排除slf4j-log4j12依赖,原因是storm-core中已经有该依赖,不排除的话有JAR包冲突的风险;
<properties>
<storm.version>1.2.2</storm.version>
</properties>
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>${storm.version}</version>
</dependency>
<!--Storm整合HDFS依赖-->
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-hdfs</artifactId>
<version>${storm.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0-cdh5.15.2</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0-cdh5.15.2</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.0-cdh5.15.2</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
1.3 DataSourceSpout
/**
* 产生词频样本的数据源
*/
public class DataSourceSpout extends BaseRichSpout {
private List<String> list = Arrays.asList("Spark", "Hadoop", "HBase", "Storm", "Flink", "Hive");
private SpoutOutputCollector spoutOutputCollector;
@Override
public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) {
this.spoutOutputCollector = spoutOutputCollector;
}
@Override
public void nextTuple() {
// 模拟产生数据
String lineData = productData();
spoutOutputCollector.emit(new Values(lineData));
Utils.sleep(1000);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("line"));
}
/**
* 模拟数据
*/
private String productData() {
Collections.shuffle(list);
Random random = new Random();
int endIndex = random.nextInt(list.size()) % (list.size()) + 1;
return StringUtils.join(list.toArray(), "\t", 0, endIndex);
}
}
产生的模拟数据格式如下:
Spark HBase
Hive Flink Storm Hadoop HBase Spark
Flink
HBase Storm
HBase Hadoop Hive Flink
HBase Flink Hive Storm
Hive Flink Hadoop
HBase Hive
Hadoop Spark HBase Storm
1.4 将数据存储到HDFS
这里HDFS的地址和数据存储路径均使用了硬编码,在实际开发中可以通过外部传参指定,这样程序更为灵活。
public class DataToHdfsApp {
private static final String DATA_SOURCE_SPOUT = "dataSourceSpout";
private static final String HDFS_BOLT = "hdfsBolt";
public static void main(String[] args) {
// 指定Hadoop的用户名 如果不指定,则在HDFS创建目录时候有可能抛出无权限的异常(RemoteException: Permission denied)
System.setProperty("HADOOP_USER_NAME", "root");
// 定义输出字段(Field)之间的分隔符
RecordFormat format = new DelimitedRecordFormat()
.withFieldDelimiter("|");
// 同步策略: 每100个tuples之后就会把数据从缓存刷新到HDFS中
SyncPolicy syncPolicy = new CountSyncPolicy(100);
// 文件策略: 每个文件大小上限1M,超过限定时,创建新文件并继续写入
FileRotationPolicy rotationPolicy = new FileSizeRotationPolicy(1.0f, Units.MB);
// 定义存储路径
FileNameFormat fileNameFormat = new DefaultFileNameFormat()
.withPath("/storm-hdfs/");
// 定义HdfsBolt
HdfsBolt hdfsBolt = new HdfsBolt()
.withFsUrl("hdfs://hadoop001:8020")
.withFileNameFormat(fileNameFormat)
.withRecordFormat(format)
.withRotationPolicy(rotationPolicy)
.withSyncPolicy(syncPolicy);
// 构建Topology
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(DATA_SOURCE_SPOUT, new DataSourceSpout());
// save to HDFS
builder.setBolt(HDFS_BOLT, hdfsBolt, 1).shuffleGrouping(DATA_SOURCE_SPOUT);
// 如果外部传参cluster则代表线上环境启动,否则代表本地启动
if (args.length > 0 && args[0].equals("cluster")) {
try {
StormSubmitter.submitTopology("ClusterDataToHdfsApp", new Config(), builder.createTopology());
} catch (AlreadyAliveException | InvalidTopologyException | AuthorizationException e) {
e.printStackTrace();
}
} else {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("LocalDataToHdfsApp",
new Config(), builder.createTopology());
}
}
}
1.5 启动测试
可以用直接使用本地模式运行,也可以打包后提交到服务器集群运行。本仓库提供的源码默认采用maven-shade-plugin进行打包,打包命令如下:
# mvn clean package -D maven.test.skip=true
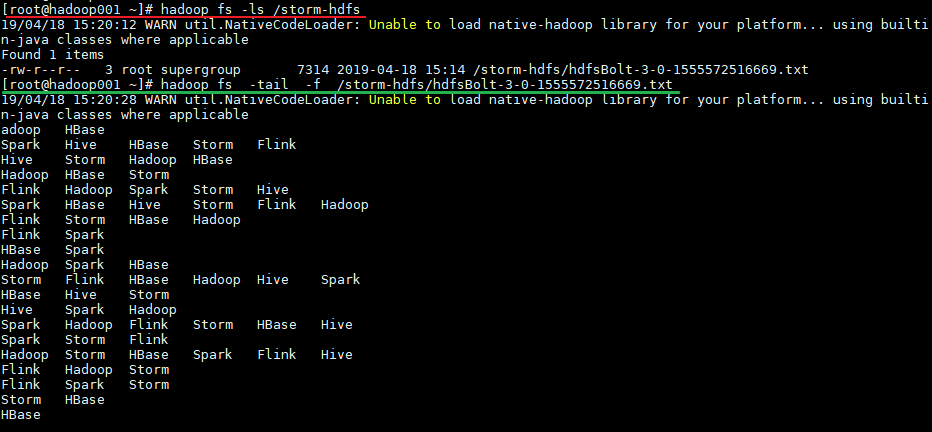
运行后,数据会存储到HDFS的/storm-hdfs目录下。使用以下命令可以查看目录内容:
# 查看目录内容
hadoop fs -ls /storm-hdfs
# 监听文内容变化
hadoop fs -tail -f /strom-hdfs/文件名
二、Storm集成HBase
2.1 项目结构
集成用例: 进行词频统计并将最后的结果存储到HBase,项目主要结构如下:
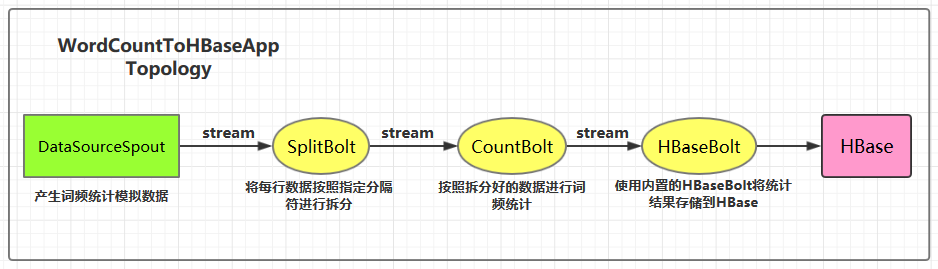
本用例源码下载地址:storm-hbase-integration
2.2 项目主要依赖
<properties>
<storm.version>1.2.2</storm.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>${storm.version}</version>
</dependency>
<!--Storm整合HBase依赖-->
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-hbase</artifactId>
<version>${storm.version}</version>
</dependency>
</dependencies>
2.3 DataSourceSpout
/**
* 产生词频样本的数据源
*/
public class DataSourceSpout extends BaseRichSpout {
private List<String> list = Arrays.asList("Spark", "Hadoop", "HBase", "Storm", "Flink", "Hive");
private SpoutOutputCollector spoutOutputCollector;
@Override
public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) {
this.spoutOutputCollector = spoutOutputCollector;
}
@Override
public void nextTuple() {
// 模拟产生数据
String lineData = productData();
spoutOutputCollector.emit(new Values(lineData));
Utils.sleep(1000);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("line"));
}
/**
* 模拟数据
*/
private String productData() {
Collections.shuffle(list);
Random random = new Random();
int endIndex = random.nextInt(list.size()) % (list.size()) + 1;
return StringUtils.join(list.toArray(), "\t", 0, endIndex);
}
}
产生的模拟数据格式如下:
Spark HBase
Hive Flink Storm Hadoop HBase Spark
Flink
HBase Storm
HBase Hadoop Hive Flink
HBase Flink Hive Storm
Hive Flink Hadoop
HBase Hive
Hadoop Spark HBase Storm
2.4 SplitBolt
/**
* 将每行数据按照指定分隔符进行拆分
*/
public class SplitBolt extends BaseRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String line = input.getStringByField("line");
String[] words = line.split("\t");
for (String word : words) {
collector.emit(tuple(word, 1));
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}
2.5 CountBolt
/**
* 进行词频统计
*/
public class CountBolt extends BaseRichBolt {
private Map<String, Integer> counts = new HashMap<>();
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector=collector;
}
@Override
public void execute(Tuple input) {
String word = input.getStringByField("word");
Integer count = counts.get(word);
if (count == null) {
count = 0;
}
count++;
counts.put(word, count);
// 输出
collector.emit(new Values(word, String.valueOf(count)));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}
2.6 WordCountToHBaseApp
/**
* 进行词频统计 并将统计结果存储到HBase中
*/
public class WordCountToHBaseApp {
private static final String DATA_SOURCE_SPOUT = "dataSourceSpout";
private static final String SPLIT_BOLT = "splitBolt";
private static final String COUNT_BOLT = "countBolt";
private static final String HBASE_BOLT = "hbaseBolt";
public static void main(String[] args) {
// storm的配置
Config config = new Config();
// HBase的配置
Map<String, Object> hbConf = new HashMap<>();
hbConf.put("hbase.rootdir", "hdfs://hadoop001:8020/hbase");
hbConf.put("hbase.zookeeper.quorum", "hadoop001:2181");
// 将HBase的配置传入Storm的配置中
config.put("hbase.conf", hbConf);
// 定义流数据与HBase中数据的映射
SimpleHBaseMapper mapper = new SimpleHBaseMapper()
.withRowKeyField("word")
.withColumnFields(new Fields("word","count"))
.withColumnFamily("info");
/*
* 给HBaseBolt传入表名、数据映射关系、和HBase的配置信息
* 表需要预先创建: create 'WordCount','info'
*/
HBaseBolt hbase = new HBaseBolt("WordCount", mapper)
.withConfigKey("hbase.conf");
// 构建Topology
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(DATA_SOURCE_SPOUT, new DataSourceSpout(),1);
// split
builder.setBolt(SPLIT_BOLT, new SplitBolt(), 1).shuffleGrouping(DATA_SOURCE_SPOUT);
// count
builder.setBolt(COUNT_BOLT, new CountBolt(),1).shuffleGrouping(SPLIT_BOLT);
// save to HBase
builder.setBolt(HBASE_BOLT, hbase, 1).shuffleGrouping(COUNT_BOLT);
// 如果外部传参cluster则代表线上环境启动,否则代表本地启动
if (args.length > 0 && args[0].equals("cluster")) {
try {
StormSubmitter.submitTopology("ClusterWordCountToRedisApp", config, builder.createTopology());
} catch (AlreadyAliveException | InvalidTopologyException | AuthorizationException e) {
e.printStackTrace();
}
} else {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("LocalWordCountToRedisApp",
config, builder.createTopology());
}
}
}
2.7 启动测试
可以用直接使用本地模式运行,也可以打包后提交到服务器集群运行。本仓库提供的源码默认采用maven-shade-plugin进行打包,打包命令如下:
# mvn clean package -D maven.test.skip=true
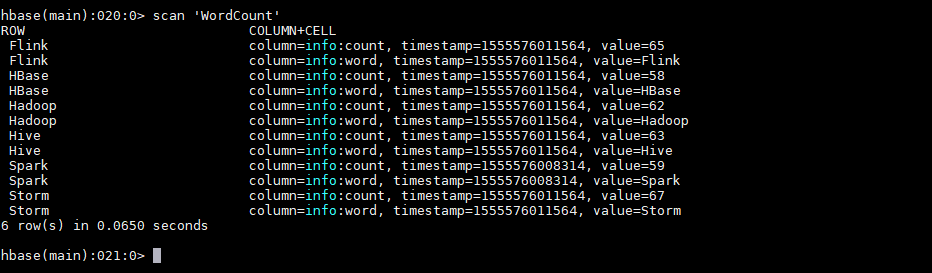
运行后,数据会存储到HBase的WordCount表中。使用以下命令查看表的内容:
hbase > scan 'WordCount'
2.8 withCounterFields
在上面的用例中我们是手动编码来实现词频统计,并将最后的结果存储到HBase中。其实也可以在构建SimpleHBaseMapper的时候通过withCounterFields指定count字段,被指定的字段会自动进行累加操作,这样也可以实现词频统计。需要注意的是withCounterFields指定的字段必须是Long类型,不能是String类型。
SimpleHBaseMapper mapper = new SimpleHBaseMapper()
.withRowKeyField("word")
.withColumnFields(new Fields("word"))
.withCounterFields(new Fields("count"))
.withColumnFamily("cf");
参考资料
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
Storm 学习之路(八)—— Storm集成HDFS和HBase的更多相关文章
- springboot 学习之路 3( 集成mybatis )
目录:[持续更新.....] spring 部分常用注解 spring boot 学习之路1(简单入门) spring boot 学习之路2(注解介绍) spring boot 学习之路3( 集成my ...
- springboot 学习之路 6(集成durid连接池)
目录:[持续更新.....] spring 部分常用注解 spring boot 学习之路1(简单入门) spring boot 学习之路2(注解介绍) spring boot 学习之路3( 集成my ...
- Storm 系列(八)—— Storm 集成 HDFS 和 HBase
一.Storm集成HDFS 1.1 项目结构 本用例源码下载地址:storm-hdfs-integration 1.2 项目主要依赖 项目主要依赖如下,有两个地方需要注意: 这里由于我服务器上安装的是 ...
- Storm 学习之路(七)—— Storm集成 Redis 详解
一.简介 Storm-Redis提供了Storm与Redis的集成支持,你只需要引入对应的依赖即可使用: <dependency> <groupId>org.apache.st ...
- Storm 学习之路(九)—— Storm集成Kafka
一.整合说明 Storm官方对Kafka的整合分为两个版本,官方说明文档分别如下: Storm Kafka Integration : 主要是针对0.8.x版本的Kafka提供整合支持: Storm ...
- Storm 学习之路(六)—— Storm项目三种打包方式对比分析
一.简介 在将Storm Topology提交到服务器集群运行时,需要先将项目进行打包.本文主要对比分析各种打包方式,并将打包过程中需要注意的事项进行说明.主要打包方式有以下三种: 第一种:不加任何插 ...
- Storm 学习之路(五)—— Storm编程模型详解
一.简介 下图为Strom的运行流程图,在开发Storm流处理程序时,我们需要采用内置或自定义实现spout(数据源)和bolt(处理单元),并通过TopologyBuilder将它们之间进行关联,形 ...
- Storm 学习之路(二)—— Storm核心概念详解
一.Storm核心概念 1.1 Topologies(拓扑) 一个完整的Storm流处理程序被称为Storm topology(拓扑).它是一个是由Spouts 和Bolts通过Stream连接起来的 ...
- Storm 学习之路(一)—— Storm和流处理简介
一.Storm 1.1 简介 Storm 是一个开源的分布式实时计算框架,可以以简单.可靠的方式进行大数据流的处理.通常用于实时分析,在线机器学习.持续计算.分布式RPC.ETL等场景.Storm具有 ...
随机推荐
- c语言学习笔记(11)——枚举
# include <stdio.h> enum WeekDay //定义了一个数据类型(值只能写一下值) { MonDay, TuesDay, WednesDay, ThursDay, ...
- REST = HTTP动词(GET POST PUT DELETE)操作 + 服务器暴露资源URI,最后返回状态码(充分利用HTTP自身的特征,而不仅仅是把HTTP当作传输协议。Rest协议是面向资源的,SOAP是面向服务的),表现形式可以是JSON XML BIN,举例很清楚
好处是,操作系统或者浏览器,可以重复利用它们内置的缓存机制等等. 增删改查都是一个地址,具体靠http头部信息判断. 利用HTTP协议语义构建的语义化.可缓存的接口. URL定位资源,用HTTP动词( ...
- windown下linux子系统的安装和卸载
原文:windown下linux子系统的安装和卸载 安装 第一步 打开开发人员模式 第二步 勾选适用linux的window子系统 第三步 打开powershell 第四步 在PowerShe ...
- BZOJ 1483 HNOI2009 梦幻布丁 名单+启示录式的合并
标题效果:特定n布丁.每个人都有一个颜色布丁,所有的布丁反复有一定的颜色变化的颜色,颜色反复询问的段数 数据范围:n<=10W 色彩数<=100W 启发式合并名单0.0 从来不写清楚 实际 ...
- Bootstrap Edit 使用方法
Getting Started <!-- rounded edit text --> <com.beardedhen.androidbootstrap.BootstrapEditTe ...
- OpenStack Summit Paris 会议记录 - 11-05-2014
Ops/Design Summit - 2014-11-05 Record 1. Keystone Operators, Deployers, and DevOps 1. Icehouse中,SAML ...
- DOS符号转义(转 http://www.robvanderwoude.com/escapechars.php)
Escape Characters Character to be escaped Escape Sequence Remark % %% May not always be required in ...
- 基于IdentityServer4的单点登录——Api
1.新建项目并添加引用 新建一个asp .net core 2.0的项目引用IdentityServer4.AccessTokenValidation 2.配置 将Api与IdentityServer ...
- 详解 Java 8 HashMap 实现原理
HashMap 是 Java 开发过程中常用的工具类之一,也是面试过程中常问的内容,此篇文件通过作者自己的理解和网上众多资料对其进行一个解析.作者本地的 JDK 版本为 64 位的 1.8.0_171 ...
- Central Subscriber Model Explained
原文 http://www.sqlrepl.com/sql-server/central-subscriber-model-explained/ The majority of SQL Server ...