Python之selenium+pytesseract 实现识别验证码自动化登录脚本
今天写自己的爆破靶场WP时候,遇到有验证码的网站除了使用pkav的工具我们同样可以通过py强大的第三方库来实现识别验证码+后台登录爆破,这里做个笔记~~~
0x01关于selenium
selenium 是一套完整的web应用程序测试系统,包含了测试的录制(selenium IDE),编写及运行(Selenium Remote Control)和测试的并行处理(Selenium Grid)。Selenium的核心Selenium Core基于JsUnit,完全由JavaScript编写,因此可以用于任何支持JavaScript的浏览器上。
selenium可以模拟真实浏览器,自动化测试工具,支持多种浏览器,爬虫中主要用来解决JavaScript渲染问题。
selenium安装和使用
安装selenium之前需安装些必要工具
1. 安装setuptools
下载地址:https://pypi.python.org/pypi/setuptools
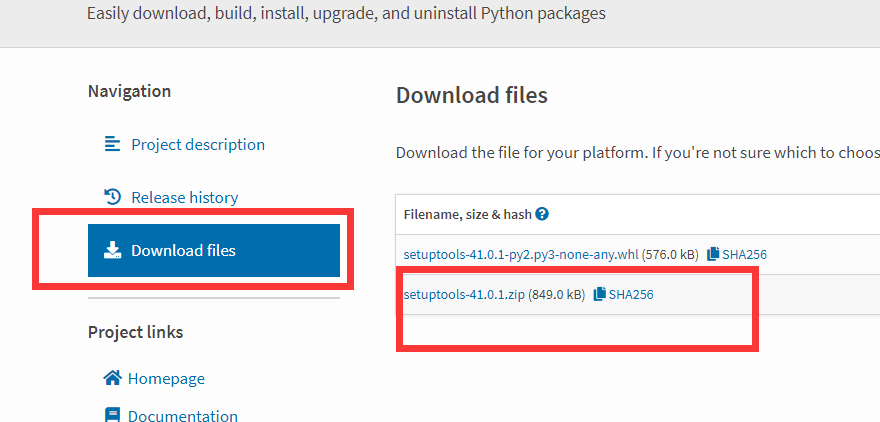
在页面找到zip安装包,下载后解压。在命令行(运行->cmd)进入解压目录
执行 python setup.py install 即可安装,注意解压路径不要包含中文,否则安装会报错。
2.安装pip
下载地址:https://pypi.python.org/pypi/pip
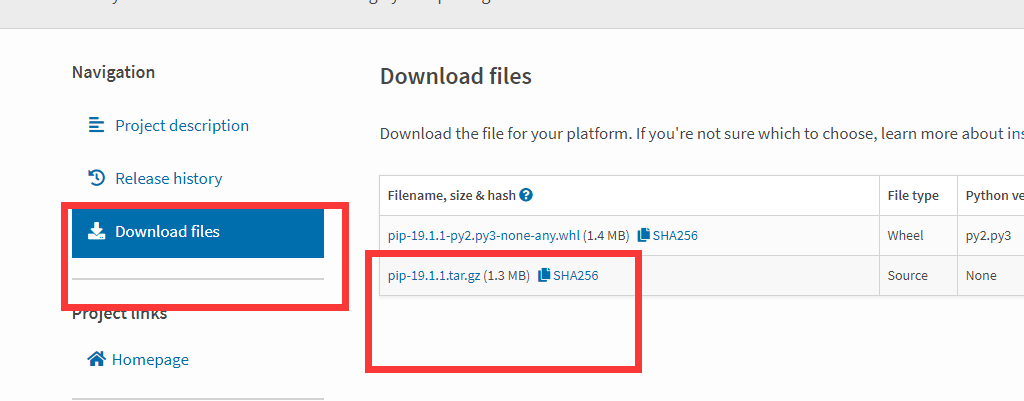
在页面找到pip-9.x.tar.gz,下载后解压。同样在命令行进入解压目录,执行 python setup.py install 即可自动安装。
3.安装selenium
上面2个工具安装好后,安装selenium只需在命令行进入python安装路径Script目录下,执行 pip install -U selenium 即可自动安装。
完成安装后在IDLE输入 from selenium import webdriver ,如果没报错即代表安装成功。


1. selenium3.0需要独立安装Firefox驱动,不再自带驱动,下载地址: https://github.com/mozilla/geckodriver/releases 下载对应版本,解压放在python安装路径下即可;
2. geckodriver驱动要求Friefox浏览器必须48版本以上,如果不是,更新Firefox;
3. 如果用Java开发,需注意3.0必须用JDK1.8版本才行;
4. Chromedriver下载:https://sites.google.com/a/chromium.org/chromedriver/downloads 同样也是下载后放在python安装路径下即可。
执行结果如下,从结果中我们也可以看出基本山支持了常见的所有浏览器:
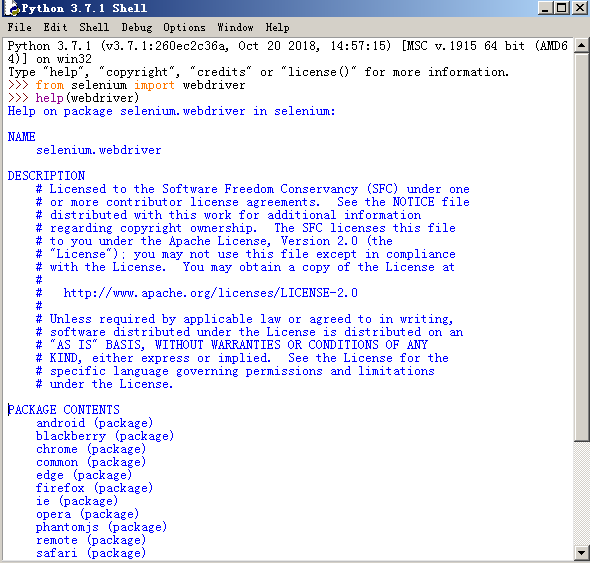
这里要说一下比较重要的PhantomJS,PhantomJS是一个而基于WebKit的服务端JavaScript API,支持Web而不需要浏览器支持,其快速、原生支持各种Web标准:Dom处理,CSS选择器,JSON等等。PhantomJS可以用用于页面自动化、网络监测、网页截屏,以及无界面测试
声明浏览器对象
上面我们知道了selenium支持很多的浏览器,但是如果想要声明并调用浏览器则需要:
from selenium import webdriver browser = webdriver.Chrome()
browser = webdriver.Firefox()
访问页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get("http://www.baidu.com")
print(browser.page_source)
browser.close()
0x02 关于pytesseract
pytesseract最新版本0.1.6,网址:https://pypi.python.org/pypi/pytesseract
a、Python-tesseract是一个基于google's Tesseract-OCR的独立封装包;
b、Python-tesseract功能是识别图片文件中文字,并作为返回参数返回识别结果;
c、Python-tesseract默认支持tiff、bmp格式图片,只有在安装PIL之后,才能支持jpeg、gif、png等其他图片格式;
注意:tesserocr与pytesseract是Python的一个OCR识别库,但其实是对tesseract做的一层Python API封装,pytesseract是Google的Tesseract-OCR引擎包装器;所以它们的核心是tesseract,因此在安装tesserocr之前,我们需要先安装tesseract
pytesseract安装 && tesseract安装
下载tesseract:https://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-w64-setup-v4.0.0-beta.1.20180414.exe
然后双击程序安装即可,可以勾选Additional language data(download)选项来安装OCR识别支持的语言包,但下载语言包实在是慢,我们可以直接从https://github.com/tesseract-ocr/tessdata下载zip的语言包压缩文件,解压后将tessdata-master中的文件复制到Tesseract的安装目录C:\Program Files (x86)\Tesseract-OCR\tessdata目录下,最后我们配置下环境变量,我们将C:\Program Files (x86)\Tesseract-OCR添加到环境变量中
在测试之前先了解下tesseract的命令程序格式:
tesseract imagename outputbase [-l lang]
imagename指定图片名称,outputbase指定输出文件名,-l指定识别的语言
#显示安装的语言包
tesseract --list-langs #显示帮助
tesseract --help
tesseract --help-extra
tesseract --version
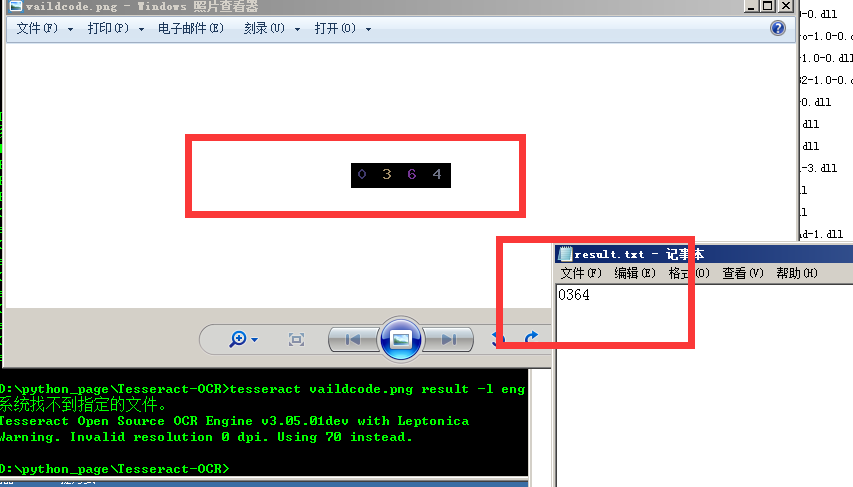
#使用一张图片测试,成功识别字符串
tesseract image.png result -l eng |type result.txt
由于tesserocr在windows环境下会出现各种不兼容问题,并且与pycharm虚拟环境不兼容等问题,所以在windows系统环境下,选择pytesseract模块进行安装,如果实在要安装请使用whl文件安装或者使用conda安装
pip install pytesseract
如果在pytesseract运行是找不到tesseract解释器,这种情况一般是在虚拟环境下会发生,我们需要将tesseract-OCR的执行文件tesseract.ext配置到windows系统中的PATH环境中,或者修改pytesseract.py文件,将其中的“tesseract_cmd”字段指定为tesseract.exe的完整路径即可
测试识别功能:
import pytesseract
from PIL import Image im=Image.open('image.png')
print(pytesseract.image_to_string(im))

tesserocr与pytesseract模块的使用
(1)tesserocr的使用
#从文件识别图像字符
In [7]: tesserocr.file_to_text('image.png')
Out[7]: 'Python3WebSpider\n\n' #查看tesseract已安装的语言包
In [8]: tesserocr.get_languages()
Out[8]: ('/usr/share/tesseract/tessdata/', ['eng']) #从图片数据识别图像字符
In [9]: tesserocr.image_to_text(im)
Out[9]: 'Python3WebSpider\n\n' #查看版本信息
In [10]: tesserocr.tesseract_version()
Out[10]: 'tesseract 3.04.00\n leptonica-1.72\n libgif 4.1.6(?) : libjpeg 6b (libjpeg-turbo 1.2.90) : libpng 1.5.13 : libtiff 4.0.3 : zlib 1.2.7 : libwebp 0.3.0\n'
(2)pytesseract使用
功能:
- get_tesseract_version 返回系统中安装的Tesseract版本。
- image_to_string 将图像上的Tesseract OCR运行结果返回到字符串
- image_to_boxes 返回包含已识别字符及其框边界的结果
- image_to_data 返回包含框边界,置信度和其他信息的结果。需要Tesseract 3.05+。有关更多信息,请查看Tesseract TSV文档
- image_to_osd 返回包含有关方向和脚本检测的信息的结果。
参数:
image_to_data(image, lang=None, config='', nice=0, output_type=Output.STRING)
- image object 图像对象
- lang String,Tesseract 语言代码字符串
- config String 任何其他配置为字符串,例如:
config='--psm 6' - nice Integer 修改Tesseract运行的处理器优先级。Windows不支持。尼斯调整了类似unix的流程的优点。
- output_type 类属性,指定输出的类型,默认为
string。有关所有支持类型的完整列表,请检查pytesseract.Output类的定义。
from PIL import Image
import pytesseract #如果PATH中没有tesseract可执行文件,请指定tesseract路径
pytesseract.pytesseract.tesseract_cmd='C:\Program Files (x86)\Tesseract-OCR\\tesseract.exe' #打印识别的图像的字符串
print(pytesseract.image_to_string(Image.open('test.png'))) #指定语言识别图像字符串,eng为英语
print(pytesseract.image_to_string(Image.open('test-european.jpg'), lang='eng')) #获取图像边界框
print(pytesseract.image_to_boxes(Image.open('test.png'))) #获取包含边界框,置信度,行和页码的详细数据
print(pytesseract.image_to_data(Image.open('test.png'))) #获取方向和脚本检测
print(pytesseract.image_to_osd(Image.open('test.png'))
图像识别简单应用
一般图像处理验证,需要通过对图像进行灰度处理、二值化后增加图像文字的辨识度,下面是一个简单的对图像验证码识别处理,如遇到复杂点的图像验证码如中间带多条同等大小划线的验证码需要对文字进行乔正切割等操作,但它的识别度也只有百分之30左右,所以得另外想别的办法来绕过验证
from PIL import Image
import pytesseract im = Image.open('66.png')
#二值化图像传入图像和阈值
def erzhihua(image,threshold):
''':type image:Image.Image'''
image=image.convert('L')
table=[]
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
return image.point(table,'1') image=erzhihua(im,127)
image.show() result=pytesseract.image_to_string(image,lang='eng')
print(result)
模拟自动识别验证码登陆:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/7/13 8:58
# @Author : Py.qi
# @File : login.py
# @Software: PyCharm
from selenium import webdriver
from selenium.common.exceptions import TimeoutException,WebDriverException
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.remote.webelement import WebElement
from io import BytesIO
from PIL import Image
import pytesseract
import time user='zhang'
password='123'
url='http://10.0.0.200'
driver=webdriver.Chrome()
wait=WebDriverWait(driver,10) #识别验证码
def acker(content):
im_erzhihua=erzhihua(content,127)
result=pytesseract.image_to_string(im_erzhihua,lang='eng')
return result #验证码二值化
def erzhihua(image,threshold):
''':type image:Image.Image'''
image=image.convert('L')
table=[]
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
return image.point(table,'1') #自动登陆
def login():
try:
driver.get(url)
#获取用户输入框
input=wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#loginname'))) #type:WebElement
input.clear()
#发送用户名
input.send_keys(user)
#获取密码框
inpass=wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#password'))) #type:WebElement
inpass.clear()
#发送密码
inpass.send_keys(password)
#获取验证输入框
yanzheng=wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#code'))) #type:WebElement
#获取验证码在画布中的位置
codeimg=wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#codeImg'))) #type:WebElement
image_location = codeimg.location
#截取页面图像并截取掩码码区域图像
image=driver.get_screenshot_as_png()
im=Image.open(BytesIO(image))
imag_code=im.crop((image_location['x'],image_location['y'],488,473))
#输入验证码并登陆
yanzheng.clear()
yanzheng.send_keys(acker(imag_code))
time.sleep(2)
yanzheng.send_keys(Keys.ENTER)
except TimeoutException as e:
print('timeout:',e)
except WebDriverException as e:
print('webdriver error:',e) if __name__ == '__main__':
login()
Python之selenium+pytesseract 实现识别验证码自动化登录脚本的更多相关文章
- Selenium&Pytesseract模拟登录+验证码识别
验证码是爬虫需要解决的问题,因为很多网站的数据是需要登录成功后才可以获取的. 验证码识别,即图片识别,很多人都有误区,觉得这是爬虫方面的知识,其实是不对的. 验证码识别涉及到的知识:人工智能,模式识别 ...
- Selenium&Pytesseract模拟登录+验证码识别
验证码是爬虫需要解决的问题,因为很多网站的数据是需要登录成功后才可以获取的. 验证码识别,即图片识别,很多人都有误区,觉得这是爬虫方面的知识,其实是不对的. 验证码识别涉及到的知识:人工智能,模式识别 ...
- python网络爬虫之如何识别验证码
有些网站的登录方式是验证码登录的方式,比如今天我们要测试的网站专利检索及分析. http://www.pss-system.gov.cn/sipopublicsearch/portal/uilogin ...
- Selenium+Tesseract-OCR智能识别验证码爬取网页数据
1.项目需求描述 通过订单号获取某系统内订单的详细数据,不需要账号密码的登录验证,但有图片验证码的动态识别,将获取到的数据存到数据库. 2.整体思路 1.通过Selenium技术,无窗口模式打开浏览器 ...
- Python——使用代码平台进行识别验证码
打码平台介绍 一般使用超级鹰或打码兔的打码平台. 超级鹰介绍 打开http://www.chaojiying.com/contact.html注册用户,生成软件ID 下载python的demo文件 查 ...
- 吴裕雄--天生自然python学习笔记:python用 Selenium 组件实现浏览器操作自动化
一般情况下,我们都是用手工操作的方式来对浏览器进行各种操作 . 实际上, 只要我们安装一个自动化操作组件, Python 就可以让我们的很多操作实现自动化 . Selenium 组件 在开发网页时,用 ...
- python+pymssql+selenium 获取短信验证码登录(实战练习)
登录页面输入手机号, 获取短信验证码(验证码有10分钟有效期) 1 连接sql server数据库,获取10分钟之内的有效短信验证码 2 页面输入手机号,并获取验证码.若存在有效验证码则输入验证码,若 ...
- python识别验证码——PIL,pytesser,pytesseract的安装
1.使用Python识别验证码需要安装Python的图像处理模块(PIL.pytesser.pytesseract) (安装过程需要pip,在我的Python中已经安装pip了,pip的安装就不在赘述 ...
- python利用selenium库识别点触验证码
利用selenium库和超级鹰识别点触验证码(学习于静谧大大的书,想自己整理一下思路) 一.超级鹰注册:超级鹰入口 1.首先注册一个超级鹰账号,然后在超级鹰免费测试地方可以关注公众号,领取1000积分 ...
随机推荐
- 一个Android 架构师的成长之路
前言 总所周知,当下流行的编程语言有Java.PHP.C.C++.Python.Go等.其中,稳坐榜首的仍然是Java编程语言,且在以面向对象思想占主导的应用开发中,Java往往成为其代名词.Java ...
- CSS——字体
1.字体样式font-family.颜色color <!DOCTYPE html> <html> <head> <meta charset="UTF ...
- 三、SpringBoot 整合mybatis 多数据源以及分库分表
前言 说实话,这章本来不打算讲的,因为配置多数据源的网上有很多类似的教程.但是最近因为项目要用到分库分表,所以让我研究一下看怎么实现.我想着上一篇博客讲了多环境的配置,不同的环境调用不同的数据库,那接 ...
- NIO入门-----01
package com.sico.pck01_nio; import java.nio.ByteBuffer; import org.junit.Test; /** * @author Sico ...
- python excel to mysql
import sys import xlrd import pymysql import math import json from collections import OrderedDict # ...
- linux虚拟化简介
为跨平台而生 在计算机发展的早期,各类计算平台.计算设备所提供的接口.调用方式纷繁复杂,没有像今天这样相对统一的标准.由于需要适配不同的平台,需要写很多繁琐的兼容代码,这无形中给开发者带来了很大的不便 ...
- java selenium 自动化笔记-不是0基础,至少有java基础
本来今天要学GitHub的,但是在群里问了下小伙伴时被暴击.说我学的东西太多太杂,不是很深入,都是皮毛.哎~自己早深有意识到,因个人能力吧,找的资料都不是很全,加上实际工作没有应用到.所以写一篇sel ...
- Fresco添加HTTP请求头
项目中用Fresco来管理图片由于服务器图片有不同的版本需要根据客户端的屏幕密度来选择不同的图片共享一份用OkHttp下载图片并添加HTTP头代码. public class OkHttpNetwor ...
- Linux端口占用情况查看
1,查看8010端口是否被占用[root@cloud ~]# netstat -an|grep 8010tcp 0 0 0.0.0.0:8010 0.0.0.0:* LISTEN 2,查看8010是被 ...
- EF Core 实现读写分离的最佳方案
前言 公司之前使用Ado.net和Dapper进行数据访问层的操作, 进行读写分离也比较简单, 只要使用对应的数据库连接字符串即可. 而最近要迁移到新系统中,新系统使用.net core和EF Cor ...