StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation - 1 - 多个域间的图像翻译论文学习
Abstract
最近在两个领域上的图像翻译研究取得了显著的成果。但是在处理多于两个领域的问题上,现存的方法在尺度和鲁棒性上还是有所欠缺,因为需要为每个图像域对单独训练不同的模型。为了解决该问题,我们提出了StarGAN方法,这是一个新型的可扩展的方法,能够仅使用一个单一模型就实现多领域的图像翻译。StarGAN这样的统一模型的结构允许在单个网络上同时训练带有不同领域的多个数据集。这使得StarGAN的翻译图像质量优于现有的模型,并具有将输入图像灵活地翻译到任意目标域的新能力。通过实验,验证了该方法在人脸属性转移和表情合成任务上的有效性。
1. Introduction
图像翻译的任务是改变给定图像的某一方面,例如,改变一个人的面部表情从微笑到皱眉(见图1)。这个任务在生成对抗网络(GANs)的介绍后得到了重大改善,从改变头发颜色[9],重建照片的边缘[7]到改变风景图片的季节[33]。
给定来自两个不同领域的训练数据,这些模型学习将图像从一个领域转换到另一个领域。我们将属性
attribute一词表示为图像中固有的有意义的特性,如头发颜色、性别或年龄,属性值attribute value表示属性的特定值,如头发颜色为黑色/金色/棕色,性别为男性/女性。我们进一步将域domain表示为一组共享相同属性值的图像。例如,女性的图像可以代表一个领域,而男性的图像则代表另一个领域。
一些图像数据集带有许多标记的属性。例如,CelebA[19]数据集包含40个与面部属性相关的标签,如头发颜色、性别和年龄;RaFD[13]数据集包含8个用于面部表情的标签,如“高兴”、“生气”和“悲伤”。这些集合使我们能够执行更有趣的任务,即多域图像到图像的转换,即根据来自多个域的属性更改图像。图1的前五列显示了如何根据“金发”、“性别”、“年龄”和“苍白皮肤”这四个域中的任意一个来翻译名人图片。我们可以进一步从不同的数据集中训练多个域,例如联合训练CelebA和RaFD图像,利用RaFD上训练得到的特征来改变一个CelebA图像的面部表情,如图1最右栏所示:

然而,现有的模型在多域图像翻译任务中效率低下,效果不好。它们效率低下的原因是,为了学习k个域之间的所有映射,必须训练k(k−1)个生成器。图2 (a)说明了如何训练12个不同的生成网络来在4个不同的域中转换图像:
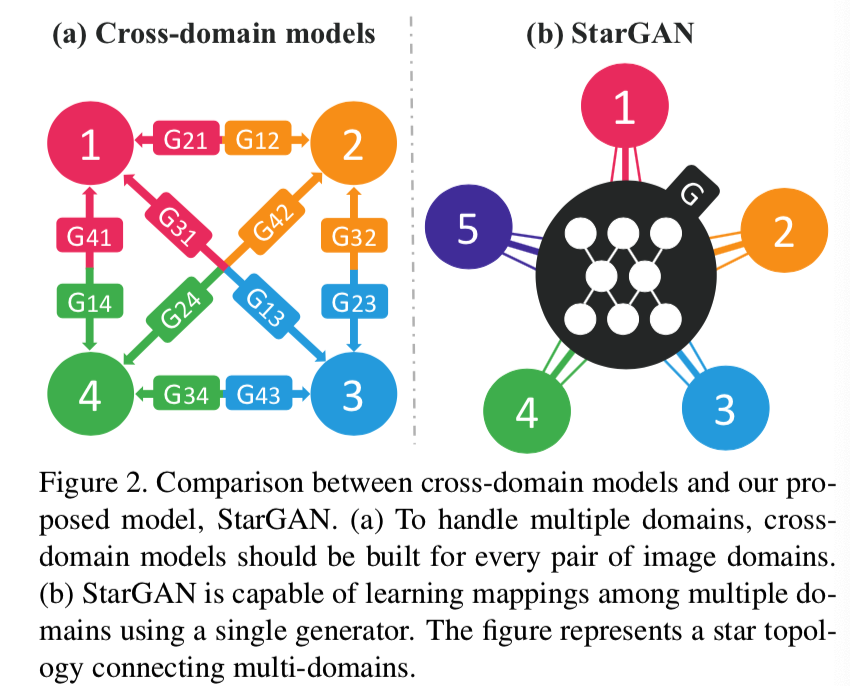
同时,他们效果也是不好的,尽管存在可以从所有领域的图像中学习得到的全局特征,如脸型,但是每个生成器不能充分利用整个训练数据,只能使用对应的两个域的图像。不能完全利用训练数据可能会限制生成图像的质量。此外,它们无法从不同的数据集中联合训练域,因为每个数据集都是部分标记,该内容我们将在第3.2节中进一步讨论。
为了解决这些问题,我们提出了StarGAN,这是一种新颖的、可扩展的方法,能够学习多个域之间的映射。如图2 (b)所示,我们的模型接受多个域的训练数据,仅使用一个生成器学习所有可用域之间的映射。想法很简单。我们的生成器不是学习固定的翻译(例如,从黑色到金色的头发),而是将图像和域信息作为输入,并灵活地学着将图像转换为相应的域。我们使用一个标签(例如,二进制或一个one-hot向量)来表示域信息。在训练过程中,我们随机生成目标域标签,并训练模型将输入图像灵活地转换到目标域。通过这样做,我们可以控制域标签并在测试阶段将图像翻译到任何想要的域。
我们还介绍了一种简单但有效的方法,通过向域标签添加掩码向量来实现不同数据集域之间的联合训练。我们提出的方法确保模型可以忽略未知的标签,而专注于特定数据集提供的标签。通过这种方式,我们的模型可以很好地完成一些任务,例如使用RaFD中学习到的特征来合成CelebA图像的面部表情,如图1最右边的列所示。据我们所知,我们的工作是第一个成功地执行跨不同数据集的多域图像转换。
总之,我们的贡献如下:
- 我们提出了StarGAN,一个新的生成式对抗网络,它能从所有域的图像中有效地训练,只使用一个生成器和一个识别器就能学习多个域之间的映射。
- 我们演示了如何利用掩模向量方法成功地学习多个数据集之间的多域图像转换,该方法使StarGAN能够控制所有可用的域标签。
- 我们使用StarGAN提供了面部属性转移和面部表情合成识别任务的定性和定量结果,表明其优于基线模型。
2. Related Work
Generative Adversarial Networks.生成式对抗网络(GANs)[3]在图像生成[6,24,32,8]、图像翻译[7,9,33]、超分辨率成像[14]、人脸图像合成[10,16,26,31]等各种计算机视觉任务中都取得了显著的效果。典型的GAN模型由两个模块组成:判别器和生成器。判别器学习区分真实样本和虚假样本,而生成器学习生成与真实样本难以区分的虚假样本。我们的方法还利用了对抗性损失,使生成的图像尽可能真实。
Conditional GANs.基于gan的条件图像生成也得到了积极的研究。之前的研究已经为判别器和生成器提供了类信息,以便生成以类为条件的样本[20,21,22]。最近的其他方法侧重于生成与给定文本描述高度相关的特定图像[25,30]。条件图像生成的思想也成功地应用于领域转移[9,28]、超分辨率成像[14]和照片编辑[2,27]中。在本文中,我们提出了一个可伸缩的GAN框架,通过提供条件域信息,可以灵活地将图像转换到不同的目标域。
Image-to-Image Translation.近年来在图像翻译方面取得了令人瞩目的成果[7,9,17,33]。例如,pix2pix[7]使用cGANs[20]以有监督的方式来学习这个任务。它结合了一个对抗损失和一个L1损失,因此需要成对的数据样本。为了解决获取数据对的问题,提出了不配对的图像翻译框架[9,17,33]。UNIT[17]将变分自编码器(VAEs)[12]和CoGAN[18]结合起来,CoGAN[18]是一个GAN框架,两个生成器共享权值来学习图像在交叉域中的联合分布。CycleGAN[33]和DiscoGAN[9]利用循环一致性损失来保存输入和转换后图像之间的关键属性。然而,所有这些框架一次只能学习两个不同领域之间的关系。它们的方法在处理多个域时具有有限的可伸缩性,因为应该为每一对域训练不同的模型。与上述方法不同,我们的框架仅使用一个模型就可以学习多个域之间的关系。
3. Star Generative Adversarial Networks
我们首先介绍我们提出的StarGAN,这是一个在单个数据集中处理多域图像到图像转换的框架。然后,我们讨论StarGAN如何合并包含不同标签集的多个数据集来灵活地使用这些标签执行图像转换。
3.1. Multi-Domain Image-to-Image Translation
我们的目标是训练单个生成器G来学习多个域之间的映射。为此,我们训练G在目标域标签c的条件下,将输入图像x转换为输出图像y, 即G(x, c)→y。我们随机生成目标域标签c,使G学会灵活地转换输入图像。我们还介绍了一个辅助分类器[22],它允许一个判别器控制多个域。也就是说,我们的判别器生成源和域标签上的概率分布,D: x→{Dsrc(x), Dcls(x)}。图3展示了我们提出的方法的训练过程。

Adversarial Loss. 为了使生成的图像不受真实图像的影响,我们采用了一种对抗性损失的方法:
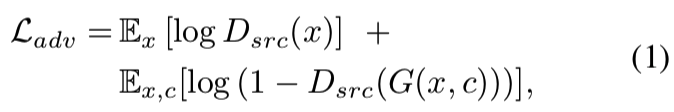
其中,G根据输入图像x和目标域标签c生成一个假图像G(x, c),而D试图区分真实图像x和虚假图像G(x, c)。在本文中,我们称Dsrc(x)为D给出的源上的概率分布。生成器G试图最小化这个目标,而判别器D试图最大化它。
Domain Classification Loss. 对于一个给定的输入图像x和一个目标域标签c,我们的目标是将x转化为输出图像y,正确分类到目标域c。为了达到这个条件,我们在D上添加一个辅助分类器并利用域分类损失来优化D和g。我们将目标分解为两个方面:将用于优化D的真实图像的域分类损失和用于优化G生成的虚假图像的域分类损失分别定义为:

其中术语Dcls(c ' |x)表示由D计算出的在域标签上的概率分布。通过最小化这个目标,D学会将一个真实图像x分类为它相应的原始域c '。我们假设输入图像和域标签对(x, c ')是由训练数据给出的。另一方面,定义生成的虚假图像的域分类的损失函数为:

换句话说,G试图最小化这个目标来生成可以被分类为目标域c的虚假图像。
Reconstruction Loss. 通过最小化对抗和分类损失,G训练生成真实的图像,并将其分类到正确的目标域。然而,最小化损失(公式(1)和(3))并不保证翻译后的图像保留其输入图像的内容,而只改变与域相关的输入部分。为了解决这个问题,我们对生成器应用一个循环一致性损失[9,33],定义为:

其中,G以翻译后的图像G(x, c)和原始域标记c’作为生成器输入,尝试重建原始图像x。我们采用L1范数作为重建损失。注意,我们使用单个生成器两次,第一次将原始图像转换为目标域中的图像,然后从转换后的图像重构原始图像。
Full Objective. 最后,优化G和D的目标函数分别为:
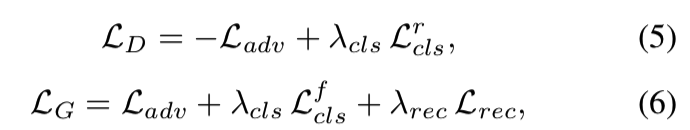
λcls和λrec是超参数,分别用于控制域分类和重建损失与对抗损失的相对重要性,。在我们所有的实验,我们使用λcls = 1和λrec = 10。
3.2. Training with Multiple Datasets
StarGAN的一个重要优点是它同时合并了包含不同类型标签的多个数据集,因此StarGAN可以在测试阶段控制所有的标签。然而,当从多个数据集学习时,一个问题是每个数据集只部分知道标签信息。在CelebA[19]和RaFD[13]中,前者包含诸如头发颜色和性别等属性的标签,而没有任何诸如后者的“高兴”和“生气”等面部表情的标签,反之亦然。这是有问题的,因为当从翻译后的图像G(x, c)重建输入图像x时,需要标签向量c '上的完整信息(参见公式(4))。
Mask Vector. 为了缓解这个问题,我们引入了一个掩码向量m,它允许StarGAN忽略未指定的标签,而专注于特定数据集提供的显式已知标签。在StarGAN中,我们使用一个n维的one-hot向量来表示m, n是数据集的数量。此外,我们将标签的统一版本定义为向量:
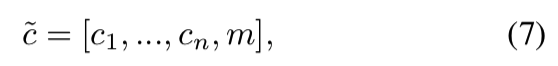
其中[·]表示连接,ci表示第i个数据集标签的向量。已知标签ci的向量可以表示为二进制属性的二进制向量,也可以表示为分类属性的one-hot向量。对于剩下的n - 1个未知标签,我们简单地赋值为0。在我们的实验中,我们使用CelebA和RaFD数据集,其中n为2。
即如果使用的是两个数据集,即CelebA和RaFD数据集,则通过设置 m = [0,1],即说明使用不使用Celeba数据集的属性,使用RaFD数据集的属性,即不使用c2这个标签向量,使用c2这个标签向量
Training Strategy. 当训练StarGAN与多个数据集,我们使用在公式(7)中定义的域标签c̃ 作为生成器的输入。通过这样做,生成器学会忽略未指定的标签(它们是零向量),而专注于显式给定的标签。在训练中,该生成器的结构与仅有单一数据集的情况是一模一样的,除了输入的c̃ 标签不同。另一方面,我们扩展了判别器的辅助分类器来生成所有数据集标签上的概率分布。然后,我们在一个多任务学习环境中训练模型,在这个环境中,判别器试图最小化与已知标签相关的分类错误。例如,当使用CelebA中的图像进行训练时,判别器只最小化与CelebA属性相关的标签的分类错误,而不最小化与RaFD相关的面部表情。在这些设置下,通过在CelebA和RaFD之间交替,判别器学习两个数据集的所有判别特征,而生成器学习控制两个数据集中的所有标签。
4. Implementation
Improved GAN Training. 为了稳定训练过程,生成更高质量的图像,我们将Eq.(1)替换为带有梯度惩罚[1,4]的Wasserstein GAN目标,定义为:
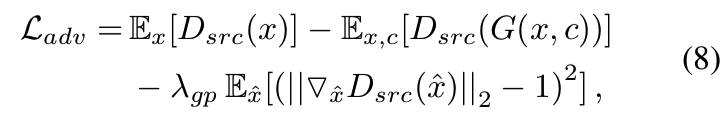
xˆ是在一对真正的和生成的图像之间沿着直线均匀采样得到的。在所有实验中,λgp = 10。
Network Architecture. StarGAN采用CycleGAN[33]为基础,它的生成器网络由两个下采样的步幅为2卷积层,6个残差块[5],以及两个上采样的步幅为2的转置卷积层组成。我们对生成器使用
instance normalization[29],而对判别器不使用规范化normalization。我们利用PatchGANs[7,15,33]作为判别器网络,它可以对局部图像补丁进行真假分类。有关网络架构的详细信息,请参阅附录(7.2节)。
5. Experiments
在这一节中,我们首先通过用户研究将StarGAN与最近的面部属性转移方法进行比较。接下来,我们对面部表情合成进行分类实验。最后,我们证明了StarGAN可以从多个数据集学习图像到图像的转换。我们所有的实验都是利用训练阶段不可见图像的模型输出进行的。
5.1. Baseline Models
我们采用DIAT[16]和Cycle-GAN[33]作为基线模型,这两种模型都在两个不同的域之间进行图像到图像的转换。为了进行比较,我们针对每一对不同的域对这些模型进行了多次训练。我们也采用IcGAN[23]作为基线,可以使用cGAN[22]执行属性转移。
DIAT 使用一种对抗损失来学习从x∈x到y∈y的映射,其中x和y分别是x和y两个不同域中的人脸图像。该方法在映射上的正则化项为||x−F (G(x))||1,以保持源图像的身份特征,其中F是针对人脸识别任务预先训练的特征提取器。
CycleGAN还使用了一个具有对抗性的损失来学习两个不同域X和Y之间的映射。该方法通过循环一致性损失||x−(GYX(GXY(x)))||1和||y−(GXY(GYX(y)))||1来规范映射。该方法需要对两个不同的域的每个对使用两个生成器和判别器。
IcGAN将编码器encoder与cGAN[22]模型相结合。cGAN学习映射G: {z, c}→x,以潜在向量z和条件向量c作为条件来生成一个图像x。此外,IcGAN介绍用于学习cGAN的逆映射编码器,Ez: x→z和Ec: x→c。这允许IcGAN合成图像只改变条件向量和保护潜在的向量。
5.2. Datasets
CelebA. CelebFaces Attributes (CelebA)数据集[19]包含202,599张名人的面部图像,每个图像都带有40个二进制属性。我们将最初的178×218大小的图像裁剪为178×178,然后将其大小调整为128×128。我们随机选择2000张图像作为测试集,并使用所有剩余的图像作为训练数据。我们使用以下属性构建了七个域:头发颜色(黑色、金色、棕色)、性别(男性/女性)和年龄(年轻/年老)。
RaFD。Radboud Faces Database (RaFD)[13]由来自67名参与者的4824张图像组成。每个参与者在三个不同的注视方向做出八个面部表情,这些表情是从三个不同的角度捕捉到的。我们裁剪图像为256×256,面居中,然后将其大小调整为128×128。
5.3. Training
所有模型训练使用亚当[11]β1 = 0.5和β2 = 0.999。为了增加数据,我们以0.5的概率水平翻转图像。在[4]中,我们在五个判别器更新之后执行一个生成器更新。所有实验的批大小设置为16。在CelebA上的实验中,我们在前10个epoch中以0.0001的学习率训练所有模型,并在接下来的10个epoch中将学习率线性衰减为0。为了弥补数据的不足,当使用RaFD训练时,我们以0.0001的学习率训练100个epoch的所有模型,并在接下来的100个epoch中应用相同的衰减策略。在一台NVIDIA Tesla M40 GPU上训练大约需要一天的时间。
5.4. Experimental Results on CelebA
我们首先将提出的方法与基线模型在单个和多个属性转移任务上进行比较。考虑到所有可能的属性值对,我们对DIAT和CycleGAN等跨域模型进行了多次训练。在DIAT和CycleGAN的例子中,我们执行多步转换来合成多个属性(例如,在改变头发颜色后转换性别属性)。
Qualitative evaluation. 图4显示了CelebA上的面部属性转移结果:

我们注意到,与跨域模型相比,我们的方法在测试数据上提供了更高视觉质量的翻译结果。一个可能的原因是StarGAN通过多任务学习框架的正则化效果。换句话说,我们训练模型根据目标域的标签灵活地翻译图像,而不是训练模型执行固定的翻译(例如,从棕色到金色的头发),这很容易导致过度拟合。这使得我们的模型能够学习到可靠的特征,这些特征普遍适用于具有不同面部属性值的多个图像域。
此外,与IcGAN相比,我们的模型在保持输入的面部特征方面具有优势。我们推测这是因为我们的方法通过使用卷积层的激活映射作为潜在表征来维护空间信息,而不是像IcGAN中那样仅仅使用一个低维的潜在向量。
Quantitative evaluation protocol. 为了进行定量评估,我们使用Amazon Mechanical Turk (AMT)以调查的形式进行了两项用户研究,以评估单个和多个属性转移任务。在给定一个输入图像的情况下,Turkers被要求根据感知真实感、属性转移的质量以及图形原始身份的保留来选择最佳生成的图像。这些选项是由四种不同方法生成的四张随机打乱的图像。在一项研究中生成的图像在头发颜色(黑色、金色、棕色)、性别或年龄方面有单一属性转移。在另一项研究中,生成的图像涉及属性转移的组合。每个Turker都被问了30到40个问题,其中包括一些简单但合乎逻辑的问题,以验证人类的作用。在每个用户研究中,验证过的Turkers的数量分别是146个和100个。
Quantitative results. 表1和表2分别显示了我们在单属性和多属性转移任务上的AMT实验结果:

StarGAN在所有情况下都获得了最佳转移属性的多数票。在表1性别变化的情况下,我们的模型与其他模型之间的投票差异很小,例如,StarGAN为39.1%,DIAT为31.4%。然而,在多属性变化中,如表2中的“G+A”情况,性能差异变得显著,如StarGAN为49.8%,IcGAN为20.3%,这清楚地显示了StarGAN在更复杂的多属性转移任务中的优势。这是因为与其他方法不同,StarGAN可以通过在训练阶段随机生成一个目标域标签来处理涉及多个属性变化的图像转换。
5.5. Experimental Results on RaFD
接下来,我们在RaFD数据集上训练我们的模型来学习合成面部表情的任务。为了比较StarGAN和基线模型,我们将输入域固定为“中立”表情,但是目标域在其余七个表情中有所不同。
Qualitative evaluation定性评估。如图5所示,StarGAN可以清晰地生成最自然的表情,同时适当地保持输入的个人身份和面部特征:

虽然DIAT和CycleGAN基本上保留了输入的标识,但是它们的许多结果显示得很模糊,并且不能保持在输入中看到的锐度。IcGAN甚至通过生成男性图像没能保持图像中的个人身份。
我们认为StarGAN在图像质量上的优势是由于它在多任务学习环境下的隐式数据增强效果。RaFD图像包含相对较小的样本,例如,每个域包含500个图像。当在两个域上训练时,DIAT和CycleGAN一次只能使用1000个训练图像,但是StarGAN可以从所有可用域总共使用4000个图像来进行训练。这使StarGAN能够正确地学习如何保持生成输出的质量和清晰度。
Quantitative evaluation定量评价。为了定量评估,我们计算了一个面部表情在合成图像上的分类误差。我们使用ResNet-18架构的[5]在RaFD数据集上训练了一个面部表情分类器(按90%/10%的比例分别用于训练和测试集),获得了近乎完美的准确率99.55%。然后,我们使用相同的训练集对每个图像翻译模型进行训练,并在相同的、不可见的测试集上进行图像翻译。最后,我们使用上述分类器对这些翻译后的图像进行分类。从表3可以看出,我们的模型分类误差最小,说明我们的模型在所有比较的方法中,面部表情最真实:
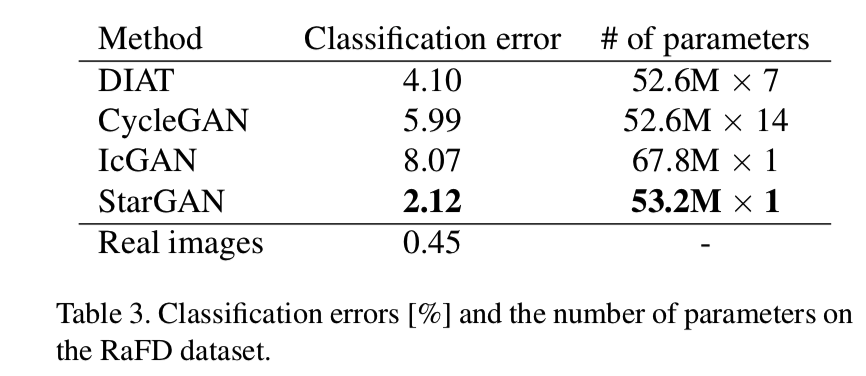
我们的模型的另一个重要优点是在所需参数数量方面的可伸缩性。表3的最后一列显示,StarGAN学习所有翻译所需的参数数量比DIAT少7倍,比CycleGAN少14倍。这是因为StarGAN只需要一个生成器和判别器对,而不管域的数量,而在跨域模型(如CycleGAN)的情况下,应该为每个源-目标域对训练一个完全不同的模型。
5.6. Experimental Results on CelebA+RaFD
最后,我们的经验证明我们的模型不仅可以从单个数据集中的多个域学习,而且可以从多个数据集中学习。我们使用掩模向量在CelebA和RaFD数据集上联合训练我们的模型(见3.2节)。为了区分仅训练于RaFD的模型和同时训练于CelebA和RaFD的模型,我们将前者称为StarGAN-SNG (single),后者称为StarGAN-JNT (joint)。
联合训练的效果. 图6是StarGAN-SNG和StarGAN-JNT的定性比较,其中的任务是合成CelebA中图像的面部表情。StarGAN-JNT展示了高视觉质量的情感表达,而StarGAN-SNG生成合理但模糊的灰色背景图像。这种差异是由于StarGAN-JNT在训练中学习翻译CelebA图像,而StarGAN-SNG没有。换句话说,StarGAN-JNT可以利用这两个数据集来改进共享的低级任务,比如面部关键点检测和分割。StarGAN-JNT通过同时使用CelebA和RaFD,可以改善这些低级任务,有利于学习面部表情合成。

学习掩模向量的作用。在这个实验中,我们通过将特定面部表情的维数(可从第二个数据集RaFD获得)设置为1来给出一个one-hot向量c。在这种情况下,由于与第二个数据集关联的标签被显式地给定,所以适当的掩码向量应该是[0,1]。图7给出了正确的掩模向量,而相反的情况给出了错误的掩模向量[1,0]。当使用错误的掩模矢量时,StarGAN-JNT无法合成面部表情,并控制输入图像的年龄。这是因为该模型忽略未知的面部表情标签,通过掩模向量将面部属性标签视为有效的。请注意,由于面部特征之一是“年轻”,当它接受一个零向量作为输入时,该模型将图像从年轻转换为年老。从这个行为中,我们可以确定StarGAN在涉及来自多个数据集的所有标签时,正确地理解了掩码向量在图像到图像转换中的预期角色。

意思是如果有两个数据集,则这个掩码就是两维的,即 m = [x,x],设置为0则说明不使用该数据集的属性,设置为1则说明使用该数据集的属性。因此上面正确的设置是[0,1],即说明使用不使用Celeba数据集的属性,使用RaFD数据集的属性,而这个时候RaFD数据集使用的属性有Disgusted、Fearful和Happy;而如果使用的设置是[1,0],即说明使用不使用RaFD数据集的属性,使用Celeba数据集的属性,Celeba数据集的属性此时是变老
6. Conclusion
在本文中,我们提出了StarGAN,一个可扩展的图像到图像的翻译模型在多个领域之间使用一个单一的生成器和一个判别器。除了在可扩展性方面的优势外,由于多任务学习设置背后的泛化能力,StarGAN生成的图像比现有方法具有更高的视觉质量[16,23,33]。此外,使用建议的简单掩码向量使StarGAN能够利用具有不同域标签集的多个数据集,从而处理其中的所有可用标签。我们希望我们的工作能够使用户开发有趣的跨多个领域的图像翻译应用程序。
StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation - 1 - 多个域间的图像翻译论文学习的更多相关文章
- 《StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation》论文笔记
---恢复内容开始--- Motivation 使用单组的生成器G和判别训练图片在多个不同的图片域中进行转换 效果确实很逆天,难怪连Good Fellow都亲手给本文点赞 Introduction 论 ...
- (转)Introductory guide to Generative Adversarial Networks (GANs) and their promise!
Introductory guide to Generative Adversarial Networks (GANs) and their promise! Introduction Neural ...
- 生成对抗网络(Generative Adversarial Networks,GAN)初探
1. 从纳什均衡(Nash equilibrium)说起 我们先来看看纳什均衡的经济学定义: 所谓纳什均衡,指的是参与人的这样一种策略组合,在该策略组合上,任何参与人单独改变策略都不会得到好处.换句话 ...
- Generative Adversarial Networks overview(2)
Libo1575899134@outlook.com Libo (原创文章,转发请注明作者) 本文章会先从Gan的简单应用示例讲起,从三个方面问题以及解决思路覆盖25篇GAN论文,第二个大部分会进一步 ...
- Generative Adversarial Networks overview(1)
Libo1575899134@outlook.com Libo (原创文章,转发请注明作者) 本文章会先从Gan的简单应用示例讲起,从三个方面问题以及解决思路覆盖25篇GAN论文,第二个大部分会进一步 ...
- StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks 论文笔记
StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks 本文将利 ...
- 论文笔记之:Semi-Supervised Learning with Generative Adversarial Networks
Semi-Supervised Learning with Generative Adversarial Networks 引言:本文将产生式对抗网络(GAN)拓展到半监督学习,通过强制判别器来输出类 ...
- 《Self-Attention Generative Adversarial Networks》里的注意力计算
前天看了 criss-cross 里的注意力模型 仔细理解了 在: https://www.cnblogs.com/yjphhw/p/10750797.html 今天又看了一个注意力模型 < ...
- Paper Reading: Perceptual Generative Adversarial Networks for Small Object Detection
Perceptual Generative Adversarial Networks for Small Object Detection 2017-07-11 19:47:46 CVPR 20 ...
随机推荐
- 进程间通信之数据传输--Socket
The client server model Most interprocess communication uses the client server model. These terms re ...
- OAuth 第三方登录授权码(authorization code)方式的小例子
假如上面的网站A,可以通过GitHub账号登录: 下面以OAuth其中一种方式,授权码(authorization code)方式为例. 一.第三方登录的原理 所谓第三方登录,实质就是 OAuth 授 ...
- initState 必须调用 super.initState(); 否则报错
@override void initState() { // initState 必须调用 super.initState(); 否则报错:info: This method overrides a ...
- vector Construct
#include<vector> #include<iostream> using namespace std; void Test(); void main() { ,,,, ...
- Python列表生成式练习
''' 如果list中既包含字符串,又包含整数,由于非字符串类型没有lower()方法,所以列表生成式会报错 使用内建的isinstance函数可以判断一个变量是不是字符串: 返回True 或 Fal ...
- vim文本编辑器——文件导入、命令查找、导入命令执行结果、自定义快捷键、ab命令、快捷键的保存
1.文件的导入(r): 导入前: 导入后: 在光标处,将tmp目录下的zhbb文件的内容导入到了当前文件. 2.命令的查找: 3.导入命令的执行结果: 光标所在行为导入的位置. 4.自定义快捷键: ( ...
- ent 基本使用十四 edge
edge 在ent 中属于比较核心,同时也是功能最强大的,ent 提供了比较强大的关系模型 快速使用 参考图 以上包含了两个通过边定义的关系 pets/owner: user package sc ...
- 修改 oracle xe 默认中文字符集成为:SIMPLIFIED CHINESE_CHINA.ZHS16GBK
修改 oracle xe 默认中文字符集成为:SIMPLIFIED CHINESE_CHINA.ZHS16GBK Oracle XE 执行安装程序后,很简单的默认为 SIMPLIFIED CHINE ...
- P1501 [国家集训队]Tree II LCT
链接 luogu 思路 简单题 代码 #include <bits/stdc++.h> #define ls c[x][0] #define rs c[x][1] using namesp ...
- 洛谷p2330繁忙的都市题解
题面 根据题意来分析, 要求出你选了几条路, 最小生成树是能解的, 那么就直接输出n - 1条路即可, 至于最大值则走一遍最小生成树求出即可 这里提供最小生成树的两种方法 1. 克鲁斯卡尔 克鲁斯卡尔 ...