xpath+多进程爬取网易云音乐热歌榜。
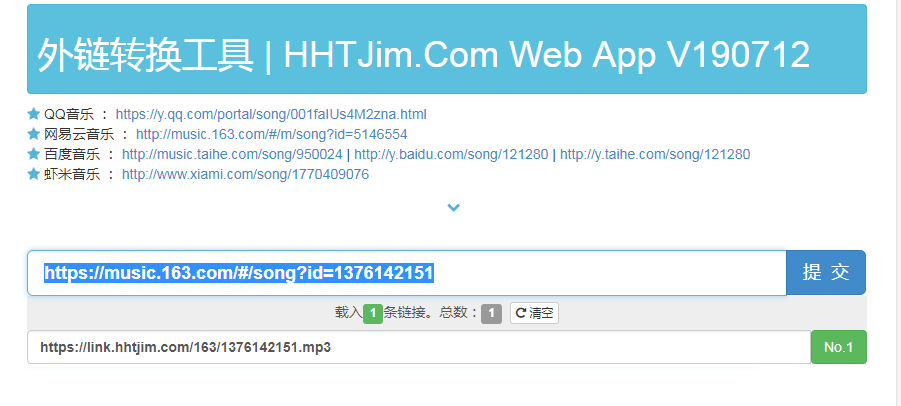
用到的工具,外链转换工具
网易云网站直接打开源代码里面并没有对应的歌曲信息,需要对url做处理,

查看网站源代码路径;发现把里面的#号去掉会显示所有内容,
右键打开的源代码路径:view-source:https://music.163.com/#/discover/toplist?id=3778678 去掉#号后:view-source:https://music.163.com/discover/toplist?id=3778678
资源拿到了,开始写代码;
import requests
from lxml import etree
import os
from multiprocessing import Pool
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
}
# 创建存储路径
pathname = './music/'
if not os.path.exists(pathname):
os.mkdir(pathname)
# 获取歌曲链接的函数
def get_urls(url):
try:
response = requests.get(url=url,headers=headers)
music = etree.HTML(response.text)
music_urls = music.xpath('//ul[@class="f-hide"]/li')
musiclist=[]
for music_url in music_urls:
url = music_url.xpath('./a/@href')[0]
name = music_url.xpath('./a/text()')[0]
musiclist.append({'key':name,'url':'https://link.hhtjim.com/163/'+url.split('=')[-1]+'.mp3'})
# 多进程启动爬取
pool.map(get_music,musiclist)
except Exception:
print('get_urls failed')
# 下载歌曲的函数
def get_music(url):
try:
# 判断歌曲是否已下载,避免网络问题导致重新爬取
if os.path.exists(pathname+url['key']+'.mp3'):
print('歌曲已存在')
else:
response = requests.get(url=url['url'],headers=headers)
with open(pathname+url['key']+'.mp3','wb') as f:
f.write(response.content)
print('正在下载:'+url['key'],url['url'])
except Exception:
print('get_music failed') if __name__ == '__main__':
# 爬取的url的源代码路径
url = 'https://music.163.com/discover/toplist?id=3778678'
# 开启进程池
pool = Pool()
get_urls(url)
代码中获取歌曲链接是拼接的路由要用到音乐外链工具,
控制台输出;
正在下载:那个女孩 https://link.hhtjim.com/163/1300994613.mp3
正在下载:Lemon https://link.hhtjim.com/163/536622304.mp3
正在下载:给未来 https://link.hhtjim.com/163/1377131180.mp3
正在下载:四块五 https://link.hhtjim.com/163/1365221826.mp3
正在下载:再也没有 https://link.hhtjim.com/163/480580003.mp3
正在下载:云烟成雨 https://link.hhtjim.com/163/513360721.mp3
正在下载:你是人间四月天 https://link.hhtjim.com/163/1344897943.mp3
正在下载:静悄悄 https://link.hhtjim.com/163/553815178.mp3
正在下载:我的名字 https://link.hhtjim.com/163/554241732.mp3
正在下载:我的一个道姑朋友 https://link.hhtjim.com/163/1367452194.mp3
正在下载:感谢你曾来过 https://link.hhtjim.com/163/460578140.mp3
正在下载:心安理得 https://link.hhtjim.com/163/474739467.mp3
正在下载:烟火里的尘埃 https://link.hhtjim.com/163/29004400.mp3
打开文件夹查看是否下载成功;

done。
xpath+多进程爬取网易云音乐热歌榜。的更多相关文章
- 用Python爬取网易云音乐热评
用Python爬取网易云音乐热评 本文旨在记录Python爬虫实例:网易云热评下载 由于是从零开始,本文内容借鉴于各种网络资源,如有侵权请告知作者. 要看懂本文,需要具备一点点网络相关知识.不过没有关 ...
- python网络爬虫&&爬取网易云音乐
#爬取网易云音乐 url="https://music.163.com/discover/toplist" #歌单连接地址 url2 = 'http://music.163.com ...
- 爬取网易云音乐评论!python 爬虫入门实战(六)selenium 入门!
说到爬虫,第一时间可能就会想到网易云音乐的评论.网易云音乐评论里藏了许多宝藏,那么让我们一起学习如何用 python 挖宝藏吧! 既然是宝藏,肯定是用要用钥匙加密的.打开 Chrome 分析 Head ...
- Python爬取网易云音乐歌手歌曲和歌单
仅供学习参考 Python爬取网易云音乐网易云音乐歌手歌曲和歌单,并下载到本地 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做 ...
- 如何用Python网络爬虫爬取网易云音乐歌曲
今天小编带大家一起来利用Python爬取网易云音乐,分分钟将网站上的音乐down到本地. 跟着小编运行过代码的筒子们将网易云歌词抓取下来已经不再话下了,在抓取歌词的时候在函数中传入了歌手ID和歌曲名两 ...
- python爬虫+词云图,爬取网易云音乐评论
又到了清明时节,用python爬取了网易云音乐<清明雨上>的评论,统计词频和绘制词云图,记录过程中遇到一些问题 爬取网易云音乐的评论 一开始是按照常规思路,分析网页ajax的传参情况.看到 ...
- python爬虫:了解JS加密爬取网易云音乐
python爬虫:了解JS加密爬取网易云音乐 前言 大家好,我是"持之以恒_liu",之所以起这个名字,就是希望我自己无论做什么事,只要一开始选择了,那么就要坚持到底,不管结果如何 ...
- Python爬虫——request实例:爬取网易云音乐华语男歌手top10歌曲
requests是python的一个HTTP客户端库,跟urllib,urllib2类似,但比那两个要简洁的多,至于request库的用法, 推荐一篇不错的博文:https://cuiqingcai. ...
- python爬取网易云音乐歌曲评论信息
网易云音乐是广大网友喜闻乐见的音乐平台,区别于别的音乐平台的最大特点,除了“它比我还懂我的音乐喜好”.“小清新的界面设计”就是它独有的评论区了——————各种故事汇,各种金句频出.我们可以透过歌曲的评 ...
随机推荐
- CentOS 7上重新编译安装nginx
CentOS 7的源所提供的nginx几乎不包含任何扩展模块:为了能够使用一些扩展模块,我们需要从源代码重新编译安装nginx. 目前最新版的源代码是1.6.1.下载解压后先不要急着configure ...
- FastJson 对json中的KEY值的大小写转换方法
/** * json大写转小写 * * @return JSONObject */ public static JSONObject transToLowerObject(String json) { ...
- Python键盘按键模拟
有时候我们需要使用python执行一些脚本,可能需要让程序自动按键或自动点击鼠标,下面的代码实现了对键盘的模拟按键, 需要安装pypiwin32,当然也可以直接用ctypes来实现. 输入:pip i ...
- Oracle Spatial分区应用研究之六:全局空间索引下按县分区与按省分区效率差异原因分析
1.实验结论 全局空间索引下,不同分区粒度之所有效率会有不同,差异并不在于SDO_FILTER操作本身,而在于对于数据字典表的访问次数上: 分区越多.表上的lob column越多,对数据字典表的访问 ...
- 【jquery】【jqGrid】设置不能多选
onSelectAll:function(rowids,statue){ layui.layer.msg("请选择单条记录"); $("#jqGrid").jq ...
- kafka 如何保证数据不丢失
一般我们在用到这种消息中件的时候,肯定会考虑要怎样才能保证数据不丢失,在面试中也会问到相关的问题.但凡遇到这种问题,是指3个方面的数据不丢失,即:producer consumer 端数据不丢失 b ...
- 数论 - 同余 + BFS (Find The Multiple)
Find The Multiple Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 16995 Accepted: 692 ...
- EasyExcel读取文件-同步处理数据
读取代码 // 前端传过来的文件 MultipartFile file; InputStream inputStream = file.getInputStream(); // 读取excel数据,边 ...
- Linux下使用strip如何对库和可执行文件进行裁减
如果生成的可执行文件或库比较大,这时候就可以使用strip命令进行裁减,在嵌入式开发中,如果使用的交叉编译工具是arm-linux,则命令 是arm-linux-strip,如果是arm-uclibc ...
- js拼接url以及为html某标签属性赋值
记录 js拼接url 比如有些时候我们需要为某按钮实现跳转,可以利用下面的方式做到: function ReturnIndex() { var rex = RegExp("tools&quo ...