Cloudera Certified Associate Administrator案例之Test篇
Cloudera Certified Associate Administrator案例之Test篇
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.准备工作(将CM升级到"60天使用的企业版")
1>.在CM界面中点击"试用Cloudera Enterprise 60天"
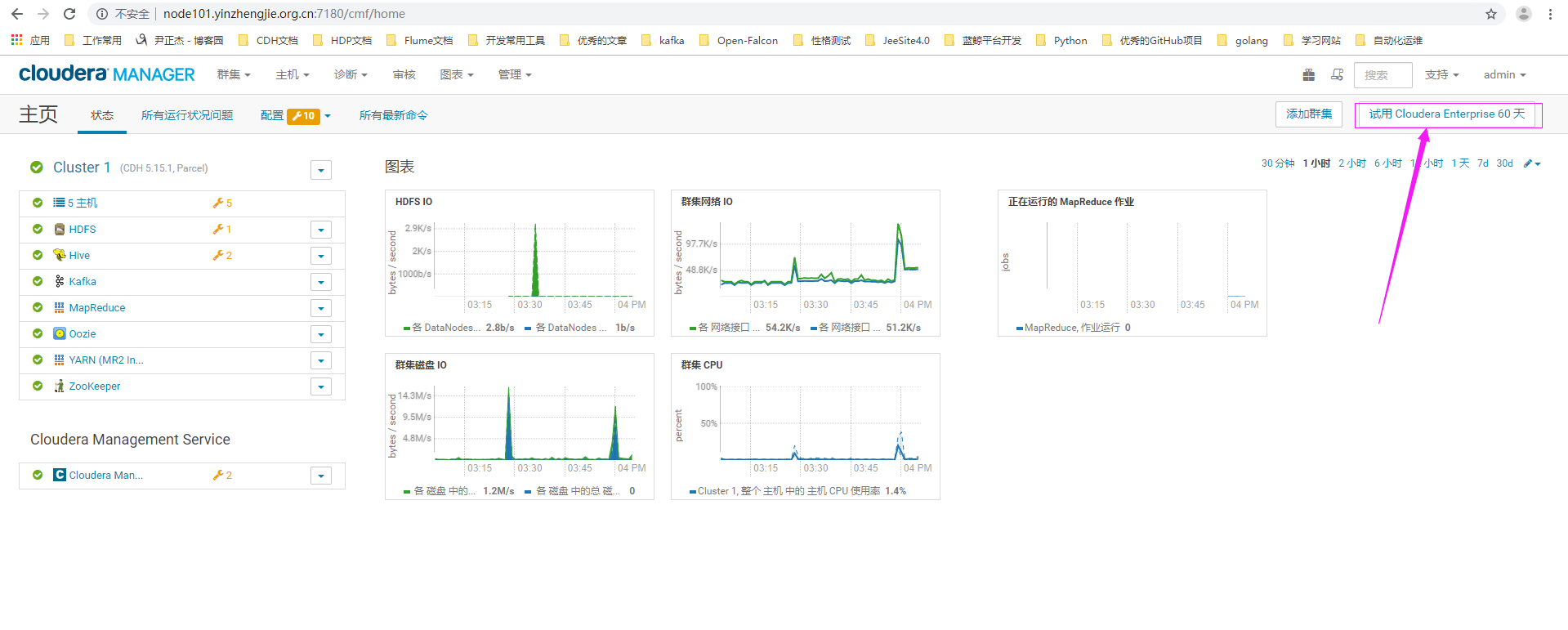
2>.进入许可证界面可以看到当前使用的是"Cloudera Express",点击"试用Cloudera Enterprise 60天""
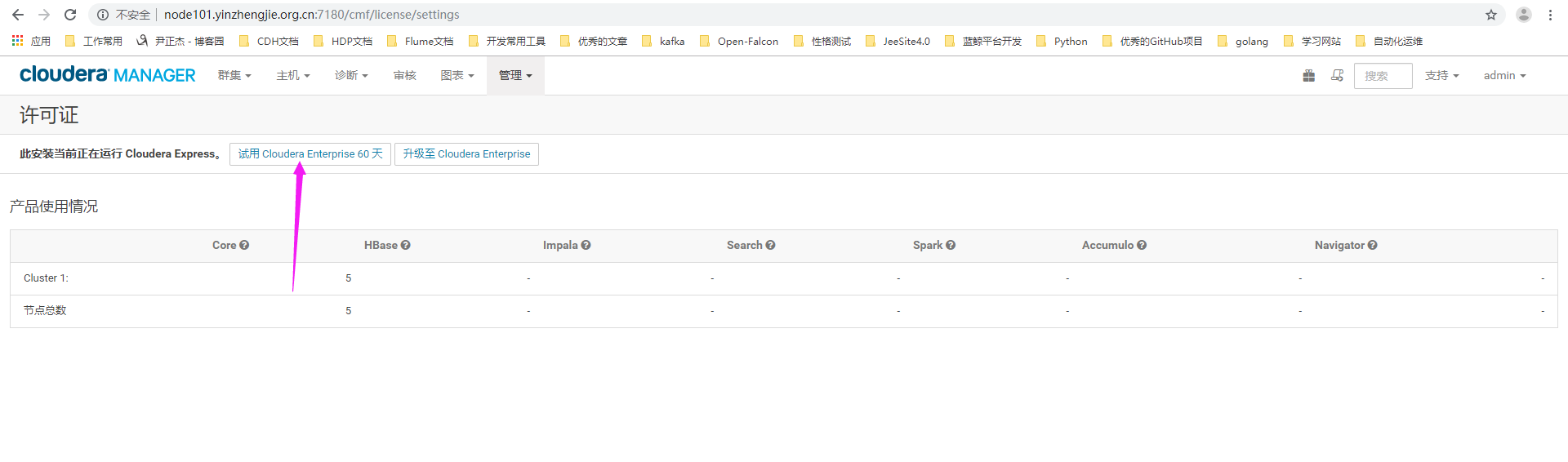
3>.点击确认
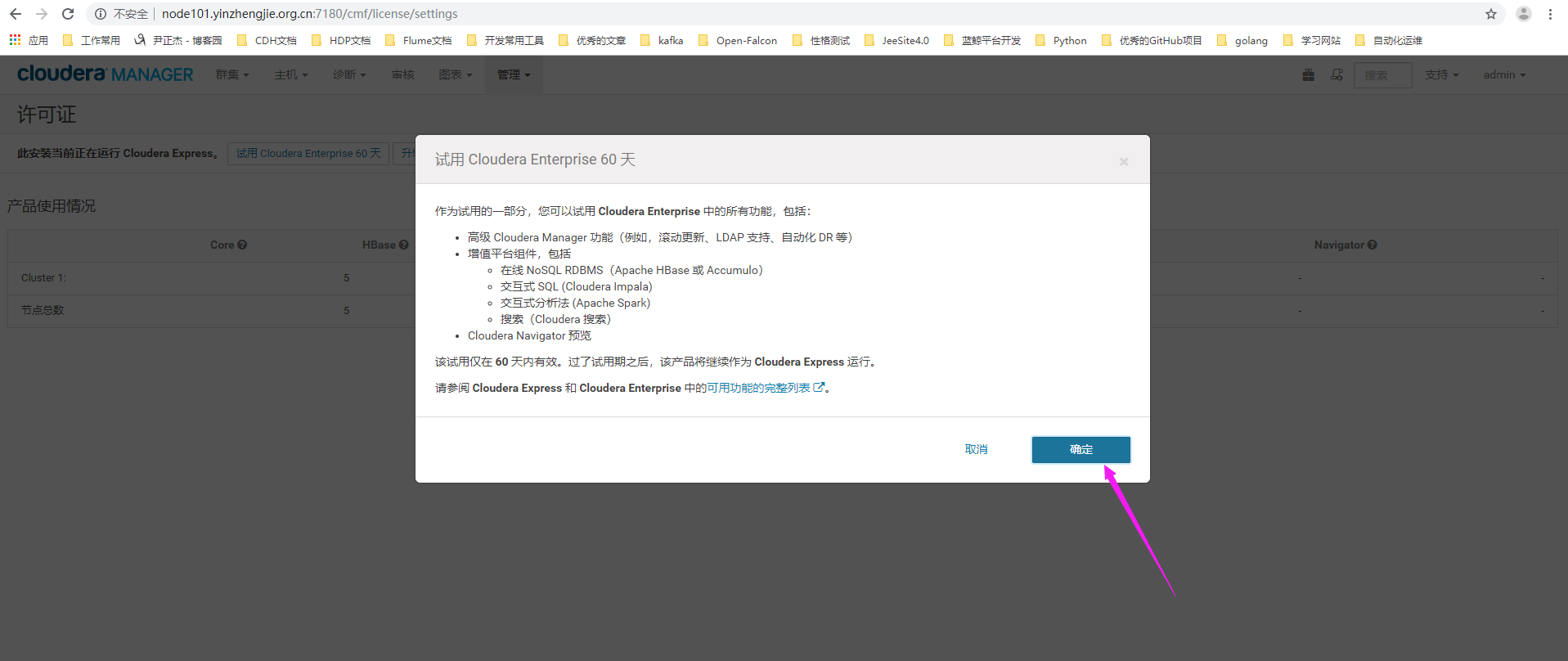
4>.进入升级向导,点击"继续"

5>.升级完成
6>.查看CM主界面
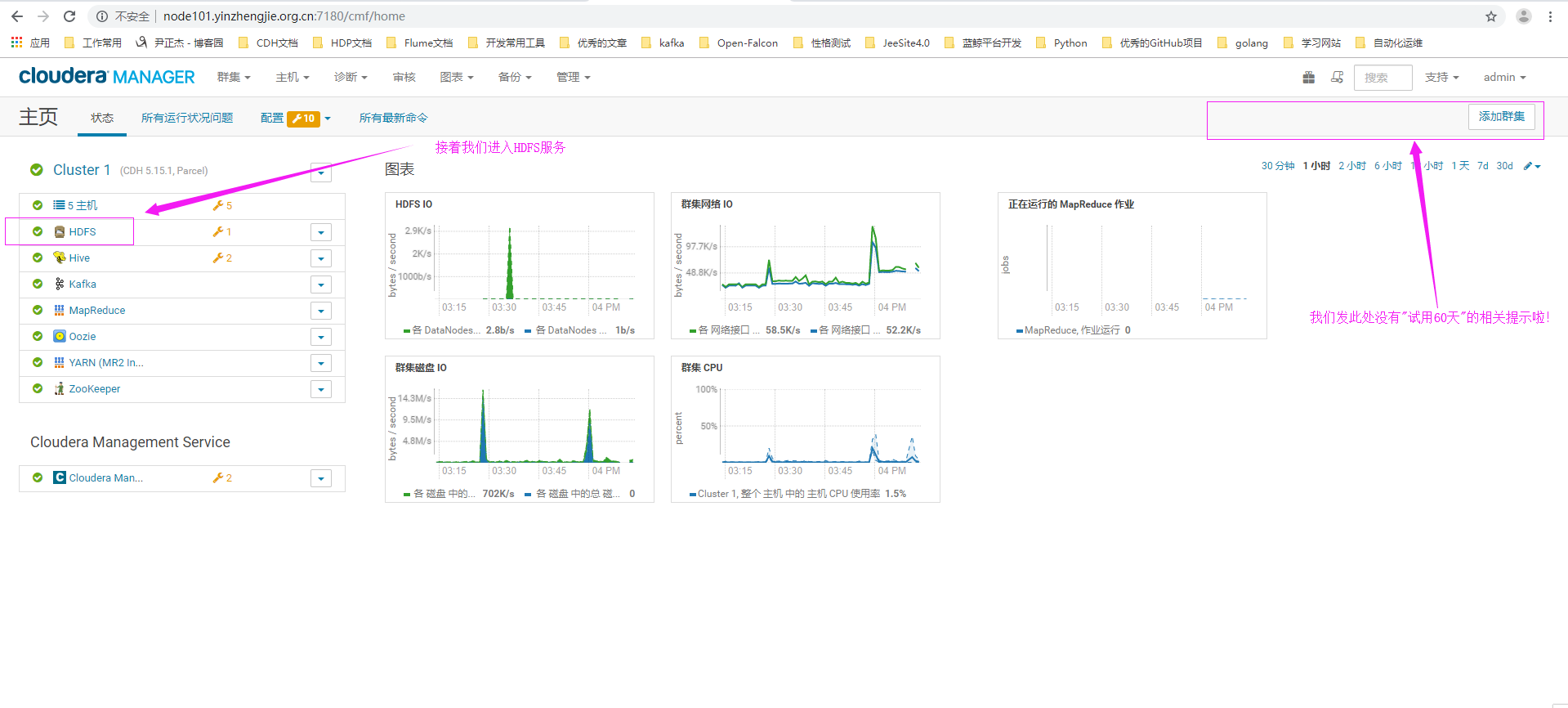
二.使用企业级的CM的快照功能
1>.点击HDFS中的"文件浏览器"
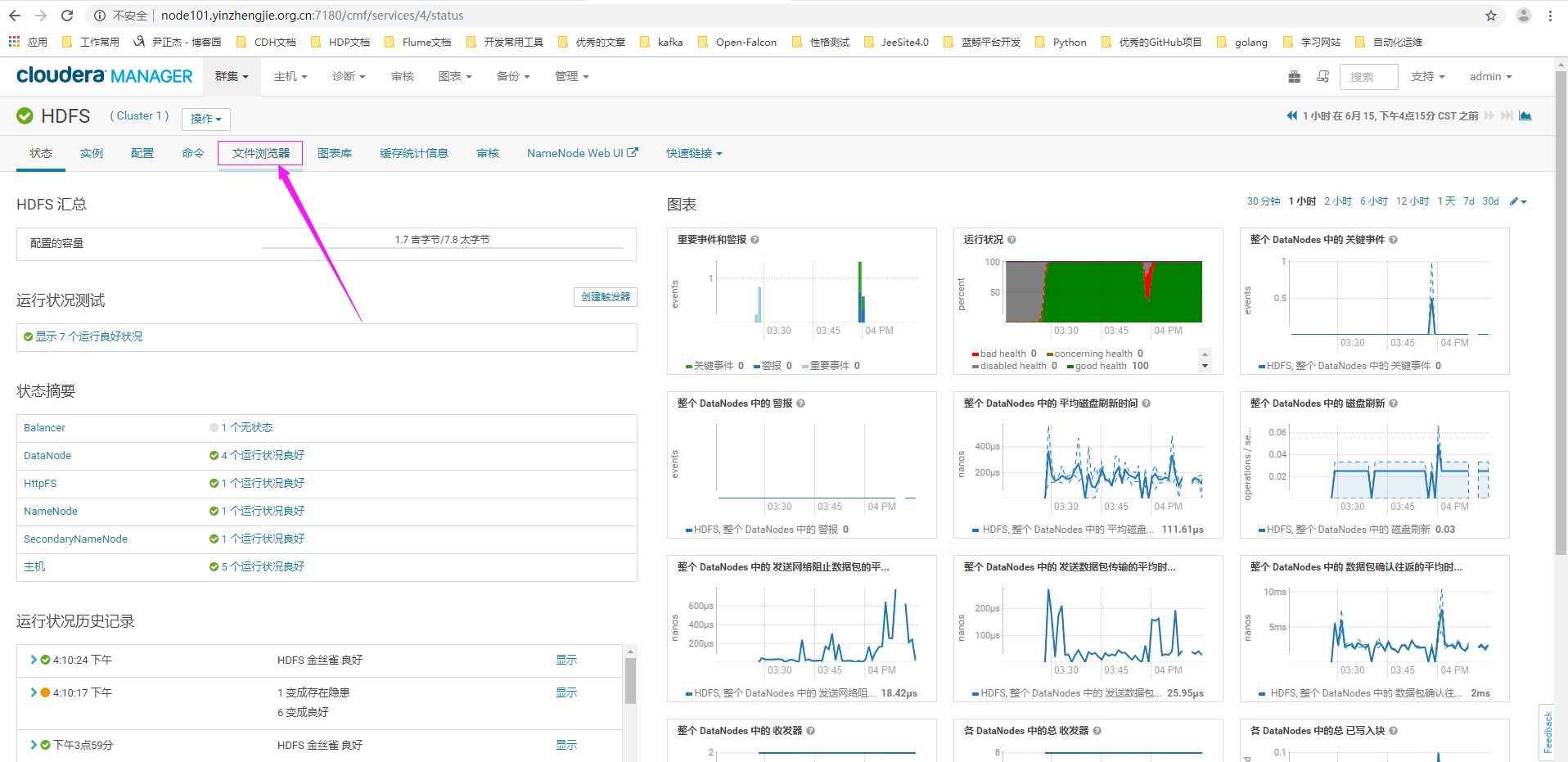
2>.进入我们的测试目录
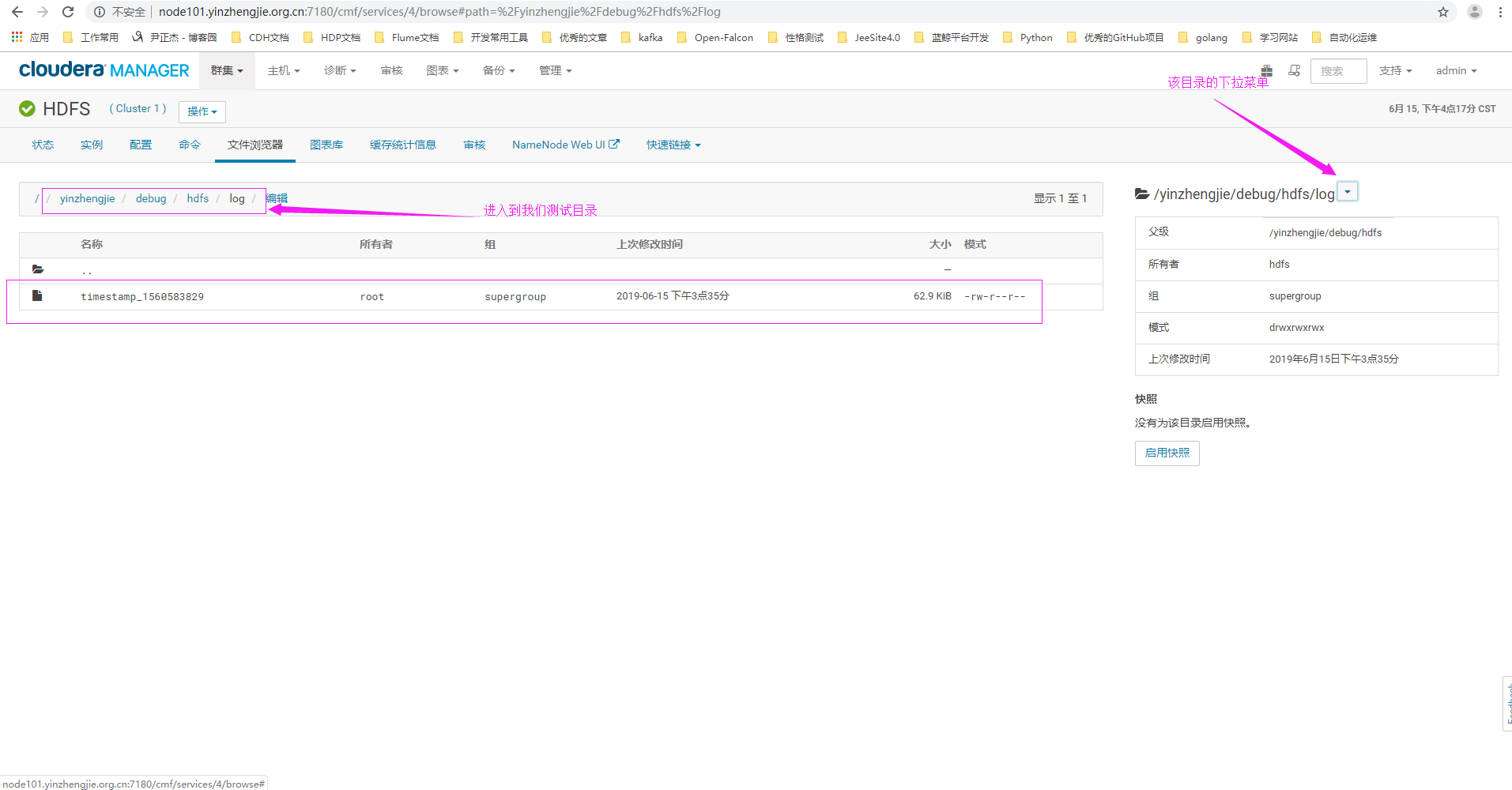
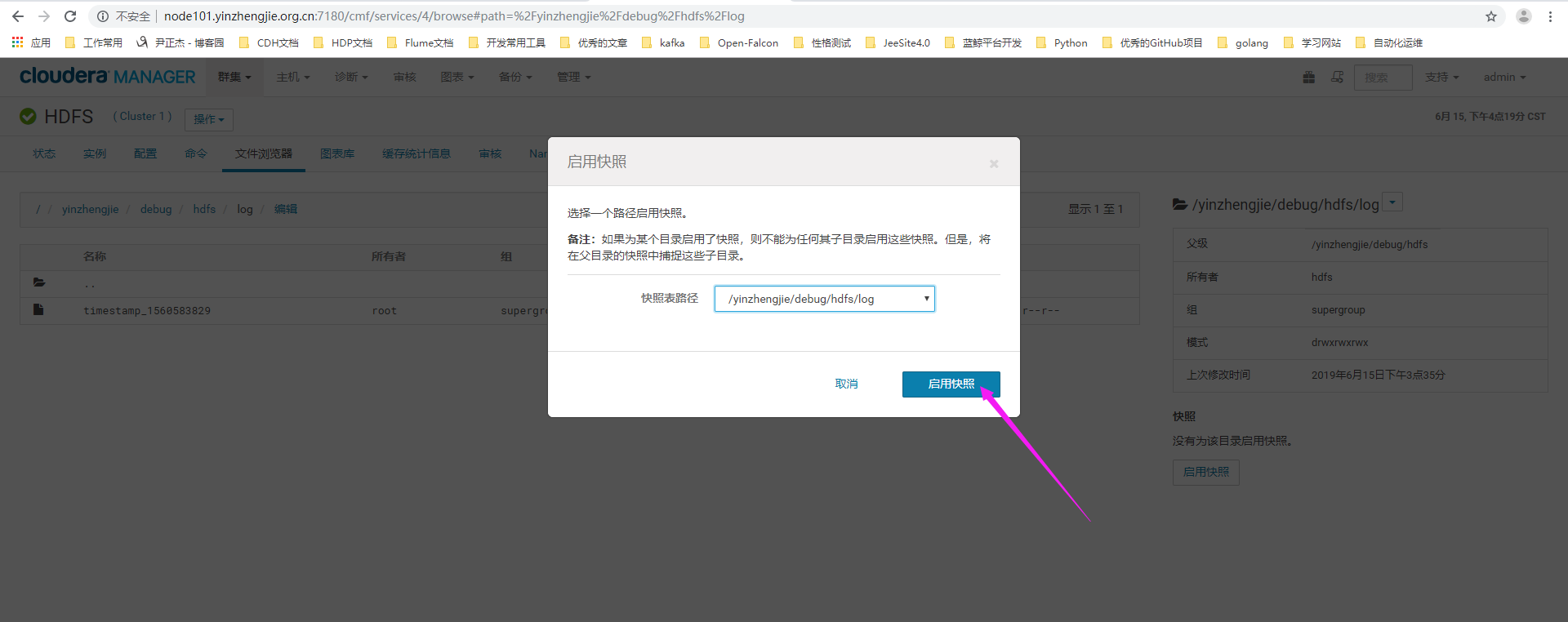
3>.点击启用快照

4>.弹出一个确认对话框,点击"启用快照"
5>.快照启用成功
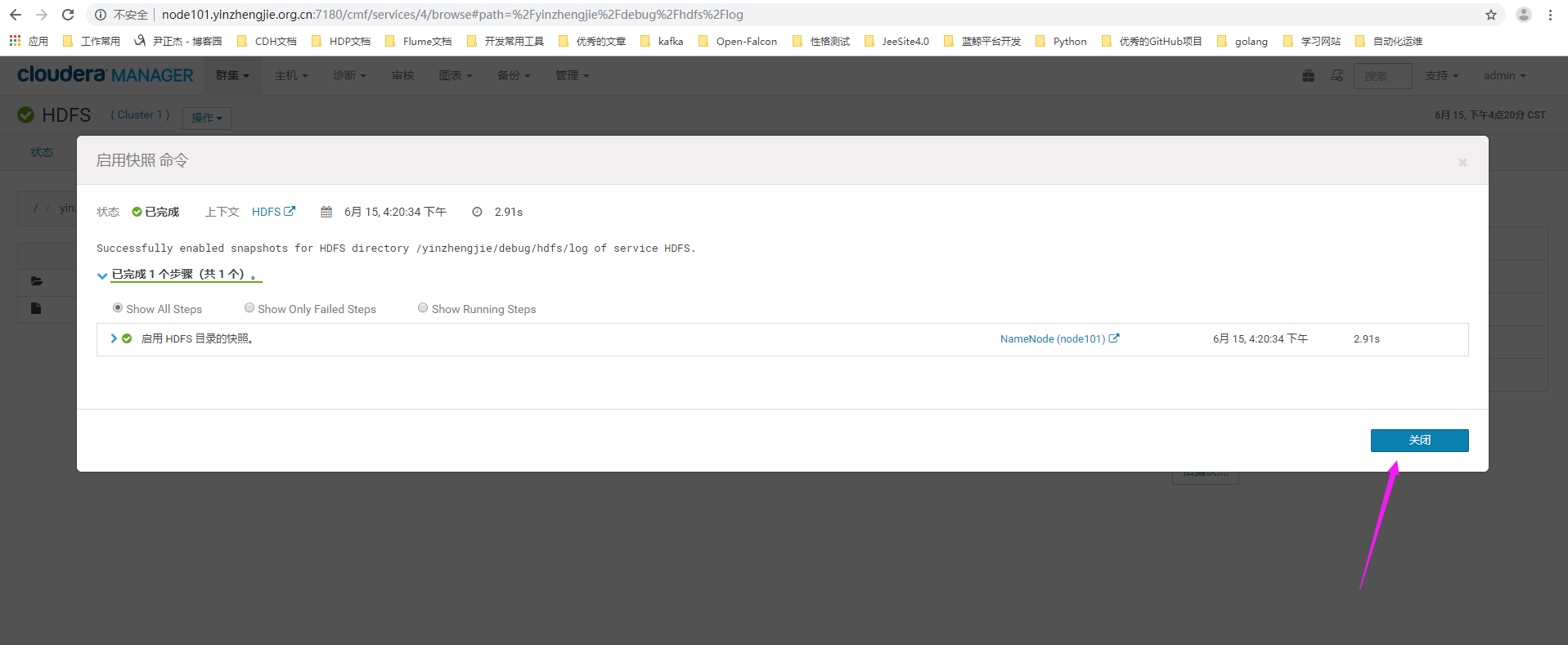
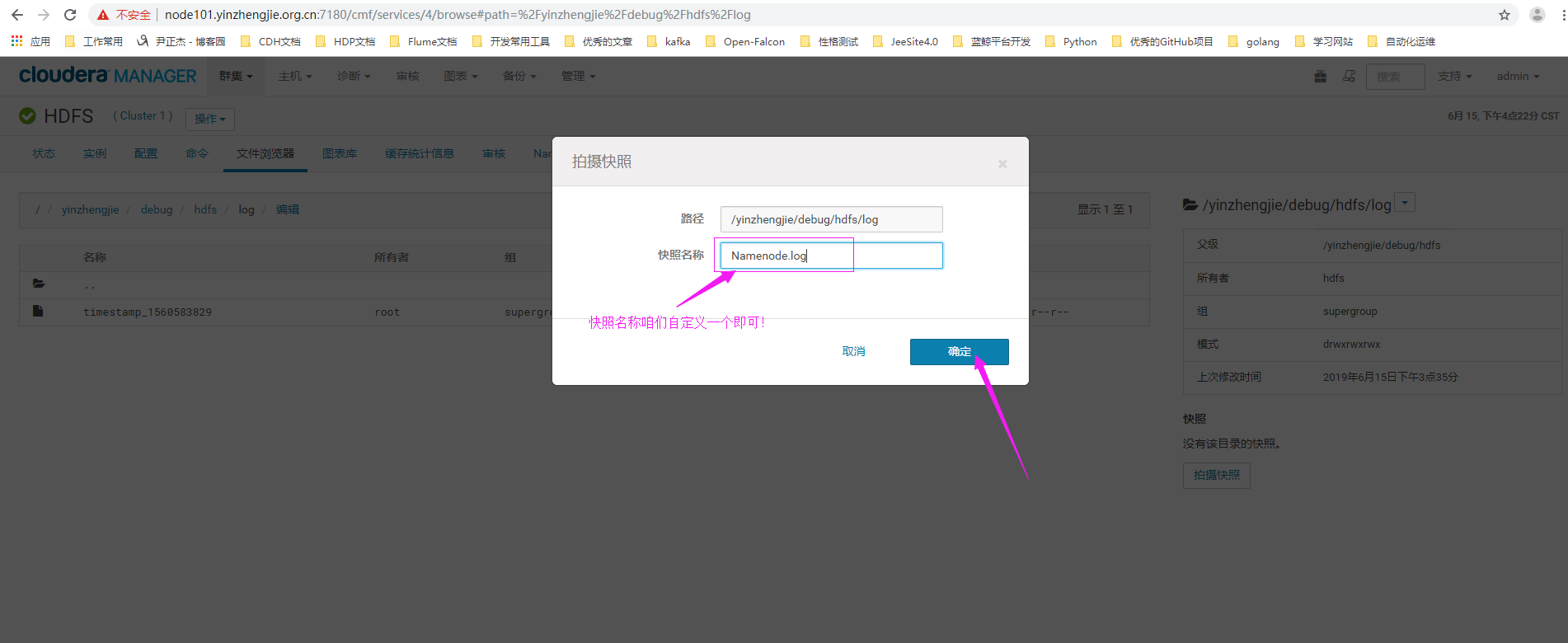
6>.点击拍摄快照

7>.给快照起一个名字
8>.等待快照创建完毕
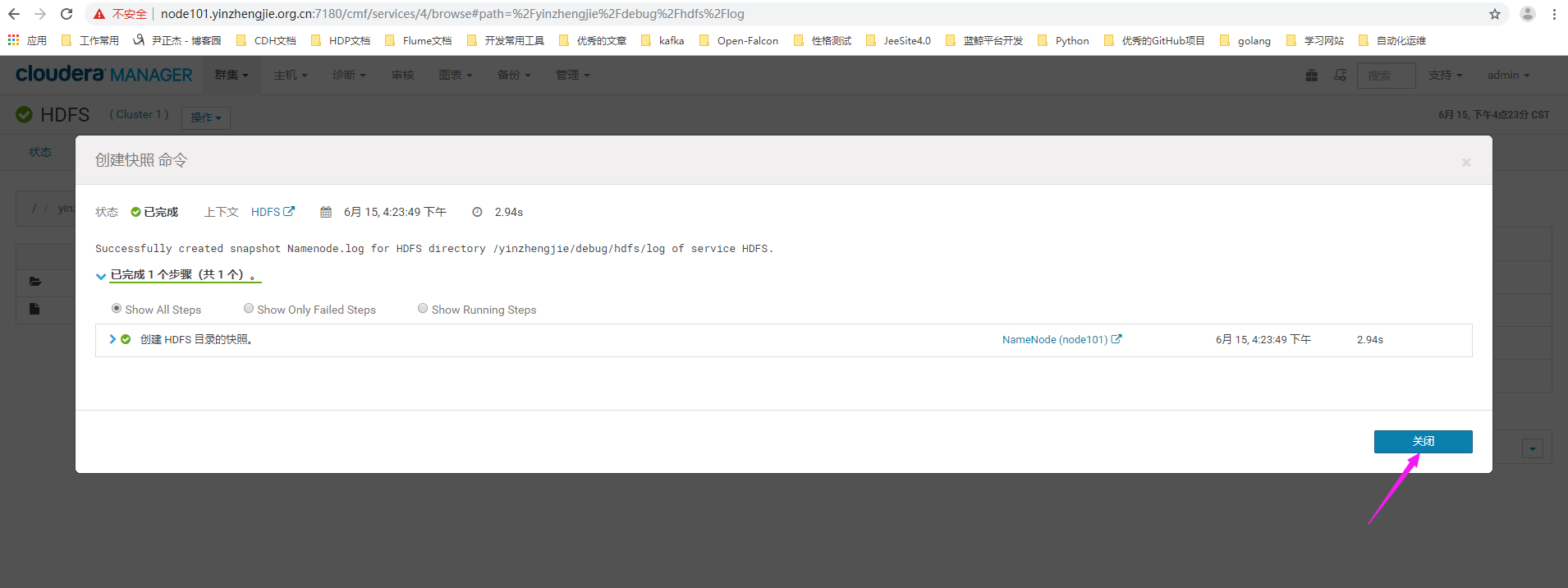
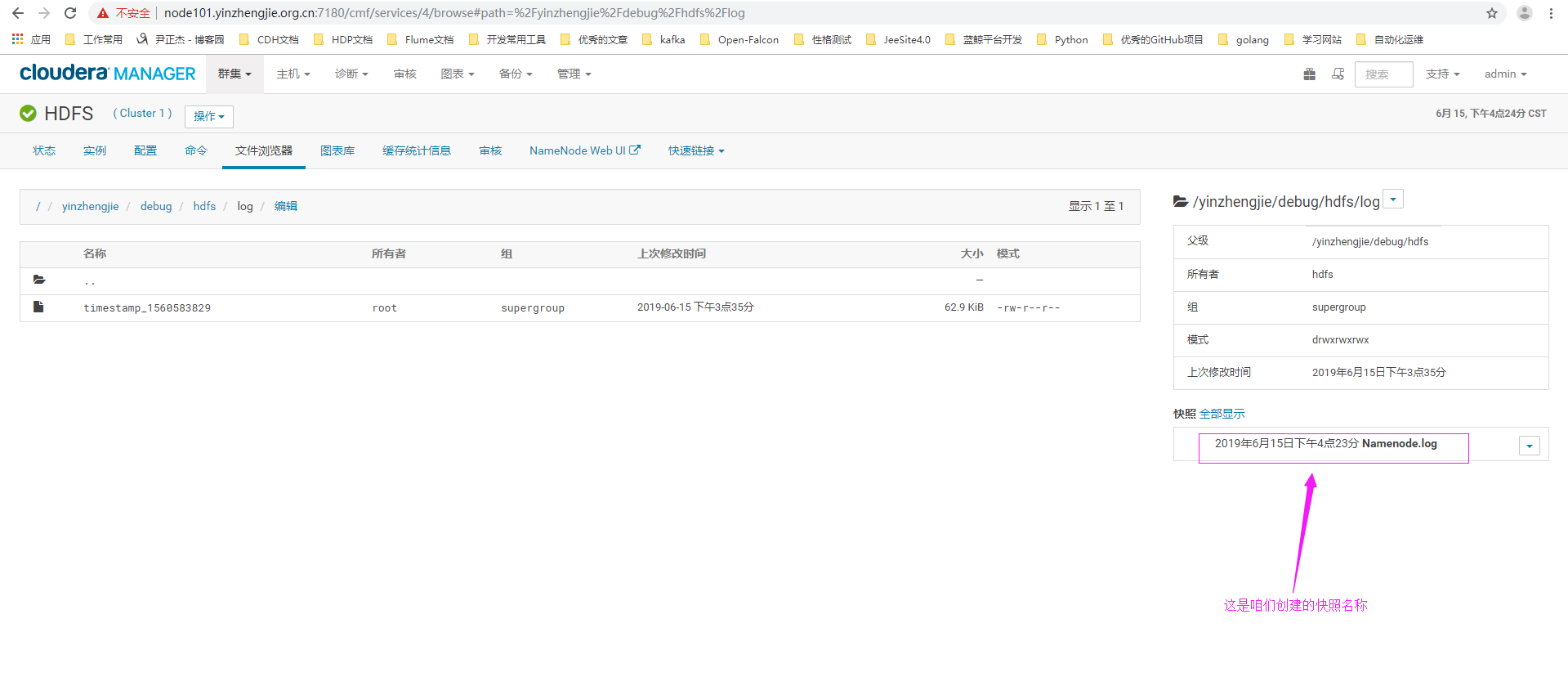
9>.快照创建成功
19>.彻底删除做了快照的文件
- [root@node101.yinzhengjie.org.cn ~]# hdfs dfs -ls /yinzhengjie/debug/hdfs/log
- Found items
- -rw-r--r-- root supergroup -- : /yinzhengjie/debug/hdfs/log/timestamp_1560583829
- [root@node101.yinzhengjie.org.cn ~]#
- [root@node101.yinzhengjie.org.cn ~]#
- [root@node101.yinzhengjie.org.cn ~]# hdfs dfs -rm -skipTrash /yinzhengjie/debug/hdfs/log/timestamp_1560583829
- Deleted /yinzhengjie/debug/hdfs/log/timestamp_1560583829
- [root@node101.yinzhengjie.org.cn ~]#
- [root@node101.yinzhengjie.org.cn ~]# hdfs dfs -ls /yinzhengjie/debug/hdfs/log
- [root@node101.yinzhengjie.org.cn ~]#
[root@node101.yinzhengjie.org.cn ~]# hdfs dfs -rm -skipTrash /yinzhengjie/debug/hdfs/log/timestamp_1560583829 #会跳过回收站

三.使用最近一个快照恢复数据
- 问题描述:
- 公司某用户在HDFS上存放了重要的文件,但是不小心将其删除了。幸运的是,该目录被设置为可快照的,并曾经创建过一次快照。请使用最近的一个快照回复数据。
要求恢复"/yinzhengjie/debug/hdfs/log"目录下的所有文件,并恢复文件原有的权限,所有者,ACL等。- 解决方案:
快照在操作中日常运维中也是很有用的,不单是用于测试。我之前在博客中有介绍过Hadoop2.9.2版本是如何使用命令行的管理快照的方法,本次我们使用CM来操作。
1>.点击HDFS服务
2>.点击文件浏览器
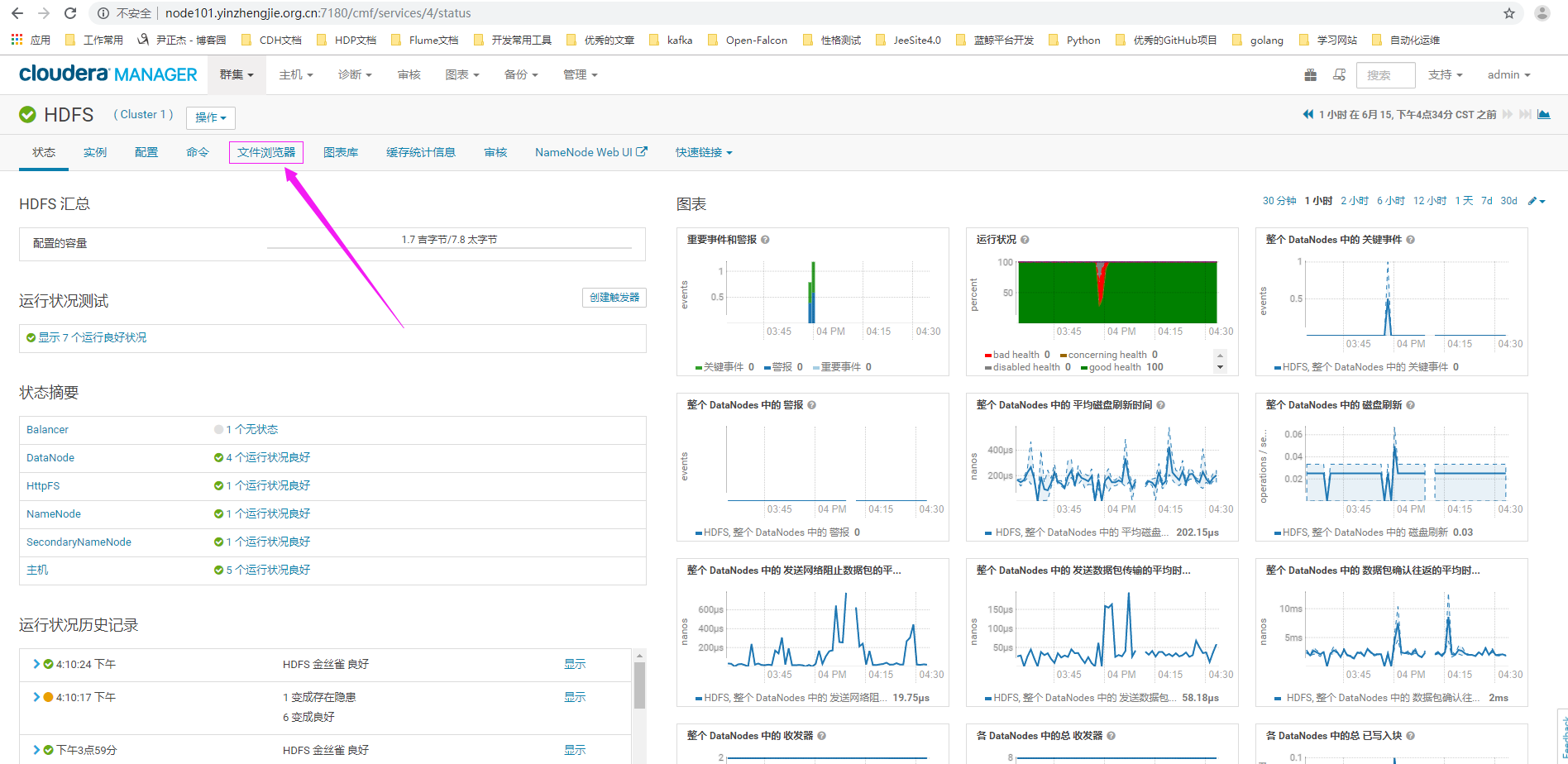
3>.进入我们要还原数据的目录,并点击"从快照还原目录"
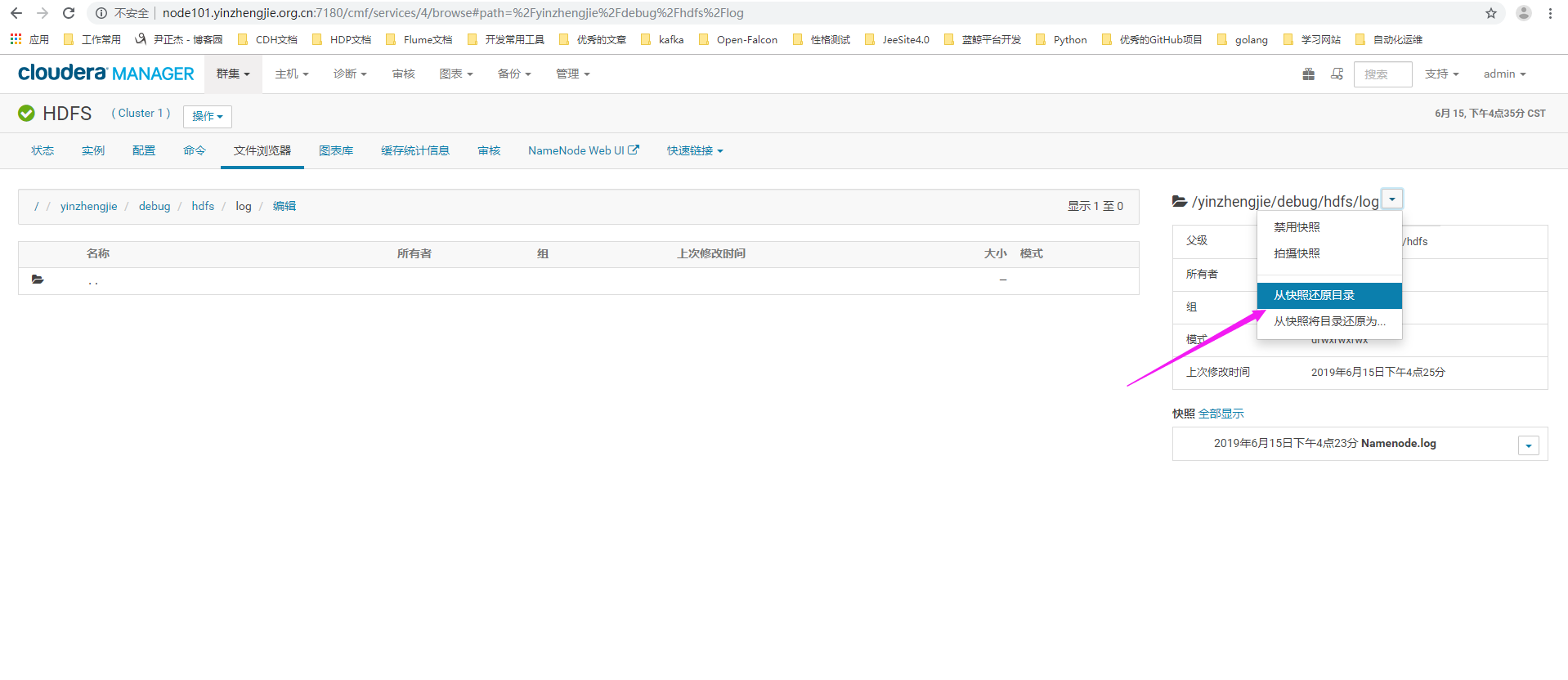
4>.选择快照及恢复的方法
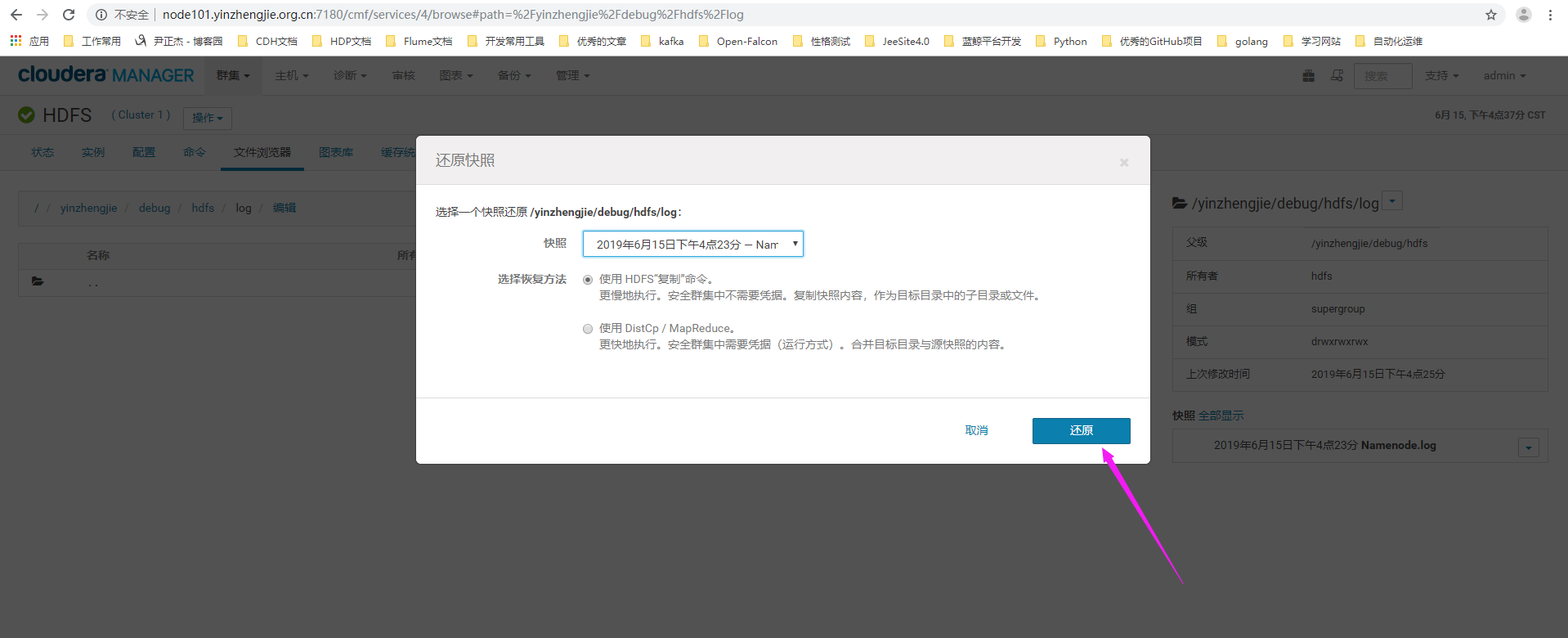
5>.恢复完成,点击"关闭"

6>.刷新当前页面,发现数据恢复成功啦
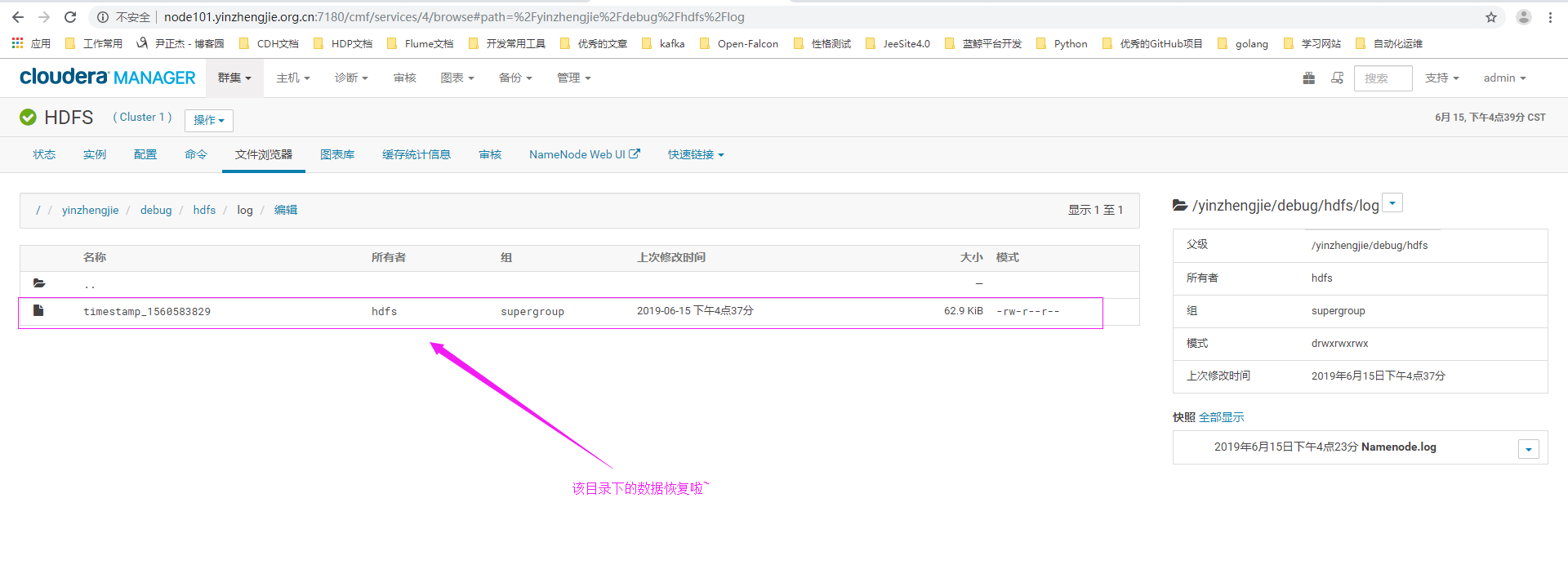
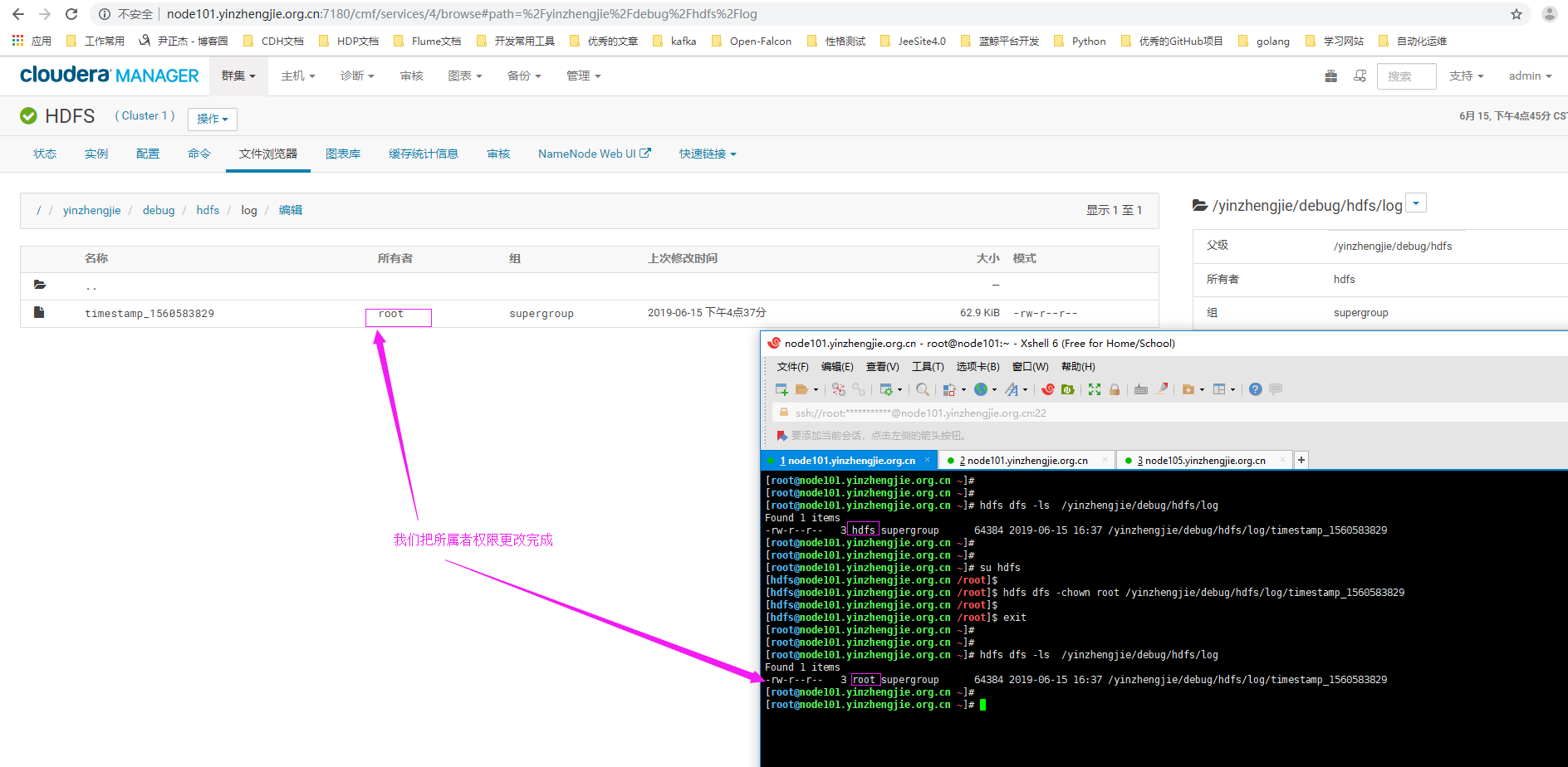
7>.恢复文件权限
四.运行一个mapreduce进程
- 问题描述:
- 公司一个运维人员尝试优化集群,但反而使得一些以前可以运行的MapReduce作业不能运行了。请你识别问题并予以纠正,并成功运行性能测试,要求为在Linux文件系统上找到hadoop-mapreduce-examples.jar包,并使用它完成三步测试:
- >.使用teragen /user/yinzhengjie/data/day001/test_input 生成10000000行测试记录并输出到指定目录
- >.使用terasort /user/yinzhengjie/data/day001/test_input /user/yinzhengjie/data/day001/test_output 进行排序并输出到指定目录
- >.使用teravalidate /user/yinzhengjie/data/day001/test_output /user/yinzhengjie/data/day001/ts_validate检查输出结果
- 解决方案:
- 需要对MapReduce作业的常见错误会排查。按照上述操作执行即可,遇到问题自行处理。
1>.生成输入数据
- [root@node101.yinzhengjie.org.cn ~]# find / -name hadoop-mapreduce-examples.jar
- /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar
- [root@node101.yinzhengjie.org.cn ~]#
- [root@node101.yinzhengjie.org.cn ~]# cd /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce
- [root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce]#
- [root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce]# hadoop jar hadoop-mapreduce-examples.jar teragen /user/yinzhengjie/data/day001/test_input
- [root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce]# hadoop jar hadoop-mapreduce-examples.jar teragen /user/yinzhengjie/data/day001/test_input
- // :: INFO terasort.TeraGen: Generating using
- // :: INFO mapreduce.JobSubmitter: number of splits:
- // :: INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1558520562958_0001
- // :: INFO impl.YarnClientImpl: Submitted application application_1558520562958_0001
- // :: INFO mapreduce.Job: The url to track the job: http://node101.yinzhengjie.org.cn:8088/proxy/application_1558520562958_0001/
- // :: INFO mapreduce.Job: Running job: job_1558520562958_0001
- // :: INFO mapreduce.Job: Job job_1558520562958_0001 running in uber mode : false
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: Job job_1558520562958_0001 completed successfully
- // :: INFO mapreduce.Job: Counters:
- File System Counters
- FILE: Number of bytes read=
- FILE: Number of bytes written=
- FILE: Number of read operations=
- FILE: Number of large read operations=
- FILE: Number of write operations=
- HDFS: Number of bytes read=
- HDFS: Number of bytes written=
- HDFS: Number of read operations=
- HDFS: Number of large read operations=
- HDFS: Number of write operations=
- Job Counters
- Launched map tasks=
- Other local map tasks=
- Total time spent by all maps in occupied slots (ms)=
- Total time spent by all reduces in occupied slots (ms)=
- Total time spent by all map tasks (ms)=
- Total vcore-milliseconds taken by all map tasks=
- Total megabyte-milliseconds taken by all map tasks=
- Map-Reduce Framework
- Map input records=
- Map output records=
- Input split bytes=
- Spilled Records=
- Failed Shuffles=
- Merged Map outputs=
- GC time elapsed (ms)=
- CPU time spent (ms)=
- Physical memory (bytes) snapshot=
- Virtual memory (bytes) snapshot=
- Total committed heap usage (bytes)=
- org.apache.hadoop.examples.terasort.TeraGen$Counters
- CHECKSUM=
- File Input Format Counters
- Bytes Read=
- File Output Format Counters
- Bytes Written=
- [root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce]#
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.1-1.cdh5.15.1.p0.4/lib/hadoop-mapreduce]# hadoop jar hadoop-mapreduce-examples.jar teragen 10000000 /user/yinzhengjie/data/day001/test_input
2>.排序和输出
- [root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce]# pwd
- /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce
- [root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce]#
- [root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce]# hadoop jar hadoop-mapreduce-examples.jar terasort /user/yinzhengjie/data/day001/test_input /user/yinzhengjie/data/day001/test_output
- // :: INFO terasort.TeraSort: starting
- // :: INFO input.FileInputFormat: Total input paths to process :
- Spent 151ms computing base-splits.
- Spent 3ms computing TeraScheduler splits.
- Computing input splits took 155ms
- Sampling splits of
- Making from sampled records
- Computing parititions took 1019ms
- Spent 1178ms computing partitions.
- // :: INFO mapreduce.JobSubmitter: number of splits:
- // :: INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1558520562958_0002
- // :: INFO impl.YarnClientImpl: Submitted application application_1558520562958_0002
- // :: INFO mapreduce.Job: The url to track the job: http://node101.yinzhengjie.org.cn:8088/proxy/application_1558520562958_0002/
- // :: INFO mapreduce.Job: Running job: job_1558520562958_0002
- // :: INFO mapreduce.Job: Job job_1558520562958_0002 running in uber mode : false
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: Job job_1558520562958_0002 completed successfully
- // :: INFO mapreduce.Job: Counters:
- File System Counters
- FILE: Number of bytes read=
- FILE: Number of bytes written=
- FILE: Number of read operations=
- FILE: Number of large read operations=
- FILE: Number of write operations=
- HDFS: Number of bytes read=
- HDFS: Number of bytes written=
- HDFS: Number of read operations=
- HDFS: Number of large read operations=
- HDFS: Number of write operations=
- Job Counters
- Launched map tasks=
- Launched reduce tasks=
- Data-local map tasks=
- Rack-local map tasks=
- Total time spent by all maps in occupied slots (ms)=
- Total time spent by all reduces in occupied slots (ms)=
- Total time spent by all map tasks (ms)=
- Total time spent by all reduce tasks (ms)=
- Total vcore-milliseconds taken by all map tasks=
- Total vcore-milliseconds taken by all reduce tasks=
- Total megabyte-milliseconds taken by all map tasks=
- Total megabyte-milliseconds taken by all reduce tasks=
- Map-Reduce Framework
- Map input records=
- Map output records=
- Map output bytes=
- Map output materialized bytes=
- Input split bytes=
- Combine input records=
- Combine output records=
- Reduce input groups=
- Reduce shuffle bytes=
- Reduce input records=
- Reduce output records=
- Spilled Records=
- Shuffled Maps =
- Failed Shuffles=
- Merged Map outputs=
- GC time elapsed (ms)=
- CPU time spent (ms)=
- Physical memory (bytes) snapshot=
- Virtual memory (bytes) snapshot=
- Total committed heap usage (bytes)=
- Shuffle Errors
- BAD_ID=
- CONNECTION=
- IO_ERROR=
- WRONG_LENGTH=
- WRONG_MAP=
- WRONG_REDUCE=
- File Input Format Counters
- Bytes Read=
- File Output Format Counters
- Bytes Written=
- // :: INFO terasort.TeraSort: done
- [root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce]#
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.1-1.cdh5.15.1.p0.4/lib/hadoop-mapreduce]# hadoop jar hadoop-mapreduce-examples.jar terasort /user/yinzhengjie/data/day001/test_input /user/yinzhengjie/data/day001/test_output
- [root@node102.yinzhengjie.org.cn ~]# hdfs dfs -ls /user/yinzhengjie/data/day001
- Found items
- drwxr-xr-x - root supergroup -- : /user/yinzhengjie/data/day001/test_input
- drwxr-xr-x - root supergroup -- : /user/yinzhengjie/data/day001/test_output
- [root@node102.yinzhengjie.org.cn ~]#
- [root@node102.yinzhengjie.org.cn ~]# hdfs dfs -ls /user/yinzhengjie/data/day001/test_input
- Found items
- -rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_input/_SUCCESS
- -rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_input/part-m-
- -rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_input/part-m-
- [root@node102.yinzhengjie.org.cn ~]#
- [root@node102.yinzhengjie.org.cn ~]# hdfs dfs -ls /user/yinzhengjie/data/day001/test_output
- Found items
- -rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/_SUCCESS
- -rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/_partition.lst
- -rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
- -rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
- -rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
- -rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
- -rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
- -rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
- -rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
- -rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
- -rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
- -rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
- -rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
- -rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
- -rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
- -rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
- -rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
- -rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
- [root@node102.yinzhengjie.org.cn ~]#
3>.验证输出
- [root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce]# pwd
- /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce
- [root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce]#
- [root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce]# hadoop jar hadoop-mapreduce-examples.jar teravalidate /user/yinzhengjie/data/day001/test_output /user/yinzhengjie/data/day001/ts_validate
- // :: INFO input.FileInputFormat: Total input paths to process :
- Spent 29ms computing base-splits.
- Spent 3ms computing TeraScheduler splits.
- // :: INFO mapreduce.JobSubmitter: number of splits:
- // :: INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1558520562958_0003
- // :: INFO impl.YarnClientImpl: Submitted application application_1558520562958_0003
- // :: INFO mapreduce.Job: The url to track the job: http://node101.yinzhengjie.org.cn:8088/proxy/application_1558520562958_0003/
- // :: INFO mapreduce.Job: Running job: job_1558520562958_0003
- // :: INFO mapreduce.Job: Job job_1558520562958_0003 running in uber mode : false
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: map % reduce %
- // :: INFO mapreduce.Job: Job job_1558520562958_0003 completed successfully
- // :: INFO mapreduce.Job: Counters:
- File System Counters
- FILE: Number of bytes read=
- FILE: Number of bytes written=
- FILE: Number of read operations=
- FILE: Number of large read operations=
- FILE: Number of write operations=
- HDFS: Number of bytes read=
- HDFS: Number of bytes written=
- HDFS: Number of read operations=
- HDFS: Number of large read operations=
- HDFS: Number of write operations=
- Job Counters
- Launched map tasks=
- Launched reduce tasks=
- Data-local map tasks=
- Rack-local map tasks=
- Total time spent by all maps in occupied slots (ms)=
- Total time spent by all reduces in occupied slots (ms)=
- Total time spent by all map tasks (ms)=
- Total time spent by all reduce tasks (ms)=
- Total vcore-milliseconds taken by all map tasks=
- Total vcore-milliseconds taken by all reduce tasks=
- Total megabyte-milliseconds taken by all map tasks=
- Total megabyte-milliseconds taken by all reduce tasks=
- Map-Reduce Framework
- Map input records=
- Map output records=
- Map output bytes=
- Map output materialized bytes=
- Input split bytes=
- Combine input records=
- Combine output records=
- Reduce input groups=
- Reduce shuffle bytes=
- Reduce input records=
- Reduce output records=
- Spilled Records=
- Shuffled Maps =
- Failed Shuffles=
- Merged Map outputs=
- GC time elapsed (ms)=
- CPU time spent (ms)=
- Physical memory (bytes) snapshot=
- Virtual memory (bytes) snapshot=
- Total committed heap usage (bytes)=
- Shuffle Errors
- BAD_ID=
- CONNECTION=
- IO_ERROR=
- WRONG_LENGTH=
- WRONG_MAP=
- WRONG_REDUCE=
- File Input Format Counters
- Bytes Read=
- File Output Format Counters
- Bytes Written=
- [root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce]#
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.1-1.cdh5.15.1.p0.4/lib/hadoop-mapreduce]# hadoop jar hadoop-mapreduce-examples.jar teravalidate /user/yinzhengjie/data/day001/test_output /user/yinzhengjie/data/day001/ts_validate
- [root@node102.yinzhengjie.org.cn ~]# hdfs dfs -ls /user/yinzhengjie/data/day001
- Found items
- drwxr-xr-x - root supergroup -- : /user/yinzhengjie/data/day001/test_input
- drwxr-xr-x - root supergroup -- : /user/yinzhengjie/data/day001/test_output
- drwxr-xr-x - root supergroup -- : /user/yinzhengjie/data/day001/ts_validate
- [root@node102.yinzhengjie.org.cn ~]#
- [root@node102.yinzhengjie.org.cn ~]# hdfs dfs -ls /user/yinzhengjie/data/day001/ts_validate
- Found items
- -rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/ts_validate/_SUCCESS
- -rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/ts_validate/part-r-
- [root@node102.yinzhengjie.org.cn ~]#
- [root@node102.yinzhengjie.org.cn ~]# hdfs dfs -cat /user/yinzhengjie/data/day001/ts_validate/part-r-00000 #我们可以看到checksum是有内容,说明验证的数据是有序的。
- checksum 4c49607ac53602
- [root@node102.yinzhengjie.org.cn ~]#
- [root@node102.yinzhengjie.org.cn ~]#
Cloudera Certified Associate Administrator案例之Test篇的更多相关文章
- Cloudera Certified Associate Administrator案例之Troubleshoot篇
Cloudera Certified Associate Administrator案例之Troubleshoot篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.调整日志的进 ...
- Cloudera Certified Associate Administrator案例之Manage篇
Cloudera Certified Associate Administrator案例之Manage篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.下载Namenode镜像 ...
- Cloudera Certified Associate Administrator案例之Install篇
Cloudera Certified Associate Administrator案例之Install篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.创建主机模板(为了给主 ...
- Cloudera Certified Associate Administrator案例之Configure篇
Cloudera Certified Associate Administrator案例之Configure篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.下载CDH集群中最 ...
- Flume实战案例运维篇
Flume实战案例运维篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Flume概述 1>.什么是Flume Flume是一个分布式.可靠.高可用的海量日志聚合系统,支 ...
- CNCF基金会的Certified Kubernetes Administrator认证考试计划
关于CKA考试 CKA(Certified Kubernetes Administrator)是CNCF基金会(Cloud Native Computing Foundation)官方推出的Kuber ...
- 分享数百个 HT 工业互联网 2D 3D 可视化应用案例之 2019 篇
继<分享数百个 HT 工业互联网 2D 3D 可视化应用案例>2018 篇,图扑软件定义 2018 为国内工业互联网可视化的元年后,2019 年里我们与各行业客户进行了更深度合作,拓展了H ...
- 数百个 HT 工业互联网 2D 3D 可视化应用案例分享 - 2019 篇
继<分享数百个 HT 工业互联网 2D 3D 可视化应用案例>2018 篇,图扑软件定义 2018 为国内工业互联网可视化的元年后,2019 年里我们与各行业客户进行了更深度合作,拓展了H ...
- robotframework+selenium搭配chrome浏览器,web测试案例(搭建篇)
这两天发布版本 做的事情有点多,都没有时间努力学习了,先给自己个差评,今天折腾了一天, 把robotframework 和 selenium 还有appnium 都研究了一下 ,大概有个谱,先说说we ...
随机推荐
- 人脸识别(基于ArcFace)
我们先来看看效果 上面是根据图片检测出其中的人脸.每个人脸的年龄还有性别,非常强大 第一步: 登录https://ai.arcsoft.com.cn/,注册开发者账号,身份认证,注册应用,得到APPI ...
- 123456123456----updateV#%#1%#%---pinLv###20%%%----com.zzj.ChildEnglis698---前show后广--儿童英语-111111111
com.zzj.ChildEnglis698---前show后广--儿童英语-111111111
- JAVA中生成指定位数随机数的方法总结
JAVA中生成指定位数随机数的方法很多,下面列举几种比较常用的方法. 方法一.通过Math类 public static String getRandom1(int len) { int rs = ( ...
- kafka生产部署
kafka真实环境部署规划 1. 操作系统选型 因为kafka服务端代码是Scala语言开发的,因此属于JVM系的大数据框架,目前部署最多的3类操作系统主要由Linux ,OS X 和Windows, ...
- openshift 使用curl命令访问apiserver
openshift版本:openshift v3.6.173.0.5 使用oc(同kubectl)命令访问apiserver资源的时候,会使用到/root/.kube/config文件中使用的配置. ...
- 说说Java Web中的Web应用程序|乐字节
大家好,我是乐字节的小乐,今天接着上期文章<Javaweb的概念与C/S.B/S体系结构>继续往下介绍Java Web ,这次要说的是web应用程序. 1. Web 应用程序的工作原理 W ...
- python快速开始一-------常见的数据类型
前置条件:已经安装好python程序 常用的数据类型 Python常见的数据类型: 整数:就是我们数学里面的整数,比如3455,python目前支持最大的32bit或者64bit 长整数(long): ...
- git 删除本地分支,删除远程分支
本地分支 git branch -d 分支名 远程分支 git push origin --delete 分支名 查看所有分支 git branch -a
- Html设置问题(设置浏览器上面的图标,移动设备上面页面保存为图标)
最近开发了一个新的项目,项目完成之后:要求把页面在移动设备上面保存为图标,通过图标直接进入系统入口(这样看着就想APP一样):刚开始通过百度直接设置了,发现有两个问题,第一.图标直接是页面的截图:第二 ...
- Django使用distinct报错:DISTINCT ON fields is not supported by this database backend
具体错误提示是:django.db.utils.NotSupportedError: DISTINCT ON fields is not supported by this database back ...