OCR5:预处理
Tesseract4.X已经有了初步成效(见下面的对比), 但目前结果对于训练之外的数据, 仍会有很大的偏差。想要更好的 OCR 结果, README 中重点强调的一点是: 在交给 Tesseract 之前, 改进图像的质量.
图像质量
Tesseract 处理 300 dpi 以上的图片会更加出色, 所以要对图片的大小有起码的要求. 分辨率和 point size 必须要考虑, 低于 10pt * 300dpi 的会被筛掉, 低于 8pt * 300dpi 的筛除地更快. 快速对图片进行检查, 是为了计算字符 x 的高度(像素). 在 10pt * 300dpi 的情况下, x的高度通常为 20 像素(字体差异上下浮动). 低于 10 像素的 x 字符高度的识别, 很难做到准确了, 如果低于 8 像素, 那么这些文本将在 ‘去噪’ 环节被过滤掉。
DPI(Dots Per Inch,每英寸点数):表示分辨率,是一个量度单位,用于点阵数码影像,指每一英寸长度中,取样、可显示或输出点的数目。
预处理流程:
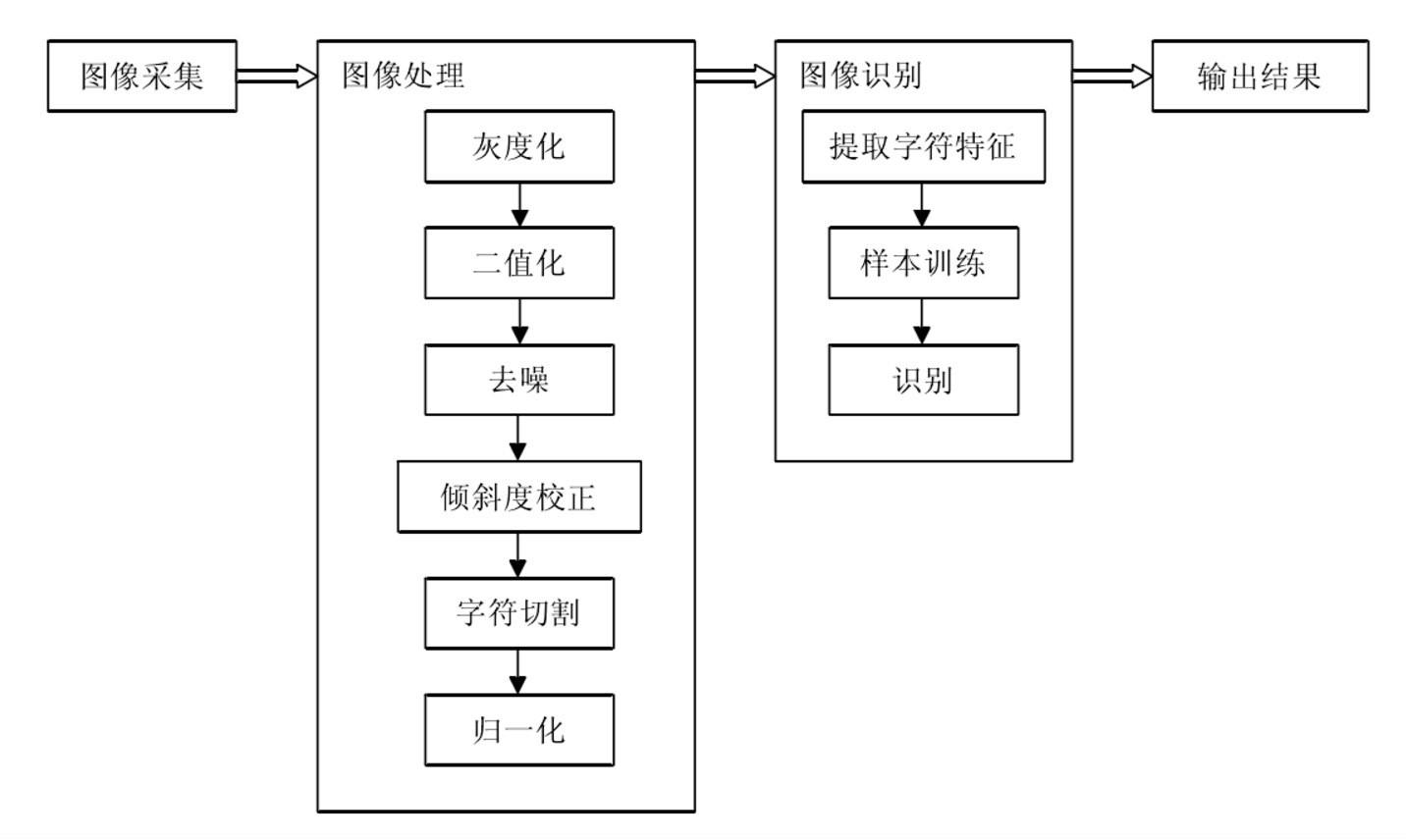
二值化
二值化的过程, 实际上 Tesseract 内置了, 但处理的应该比较粗暴, 我的经验是, 这个二值化的过程, 尽量由自己进行, 选取一个尽量去除光照影响的算法,
去噪
噪点, 往往是二值化过程中, 处理亮度与颜色时遗留下来的. Tesseract 对这些噪点不会去除, 从而影响了结果的准确率.
旋转/去偏移
如果目标文字出现倾斜, Tesseract 的 line segmentation 效果会大打折扣. 如果可能的话,应该提前将文字扶正, 保证水平.
去边缘
无论是扫描件, 还是照片, 往往在二值化之后, 残留大量的黑线/黑框. 这些会被 Tesseract 错误地拾取, 造成干扰. 最好能够截取目标文字区域, 然后交给 Tesseract.
图像来源百度
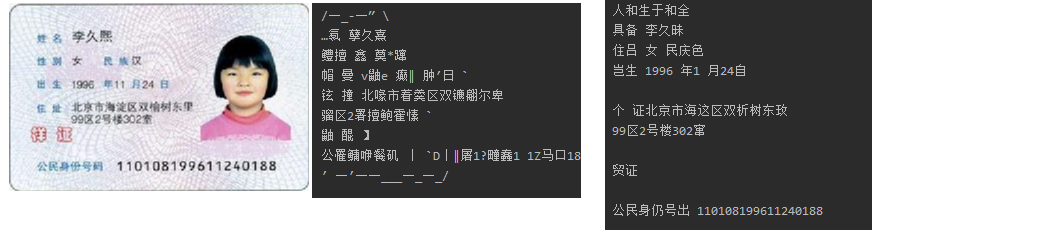
V4.X 脚本:
text = pytesseract.image_to_string(img.open('src1\A0.jpg'), lang='chi_sim', config='--psm 3 --oem 1')
print(text)
A0.jpg

A1.jpg

A2.jpg

A3.jpg
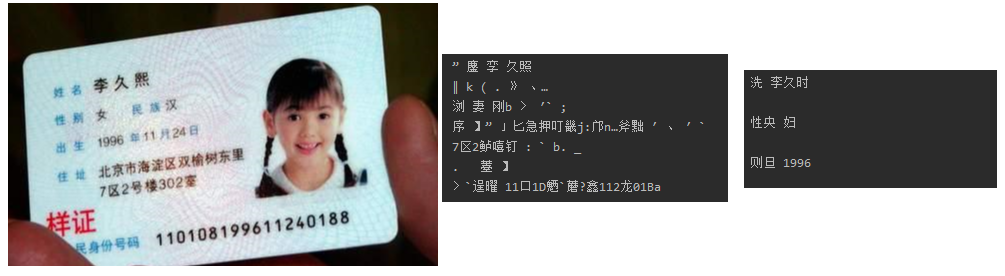
A4.jpg
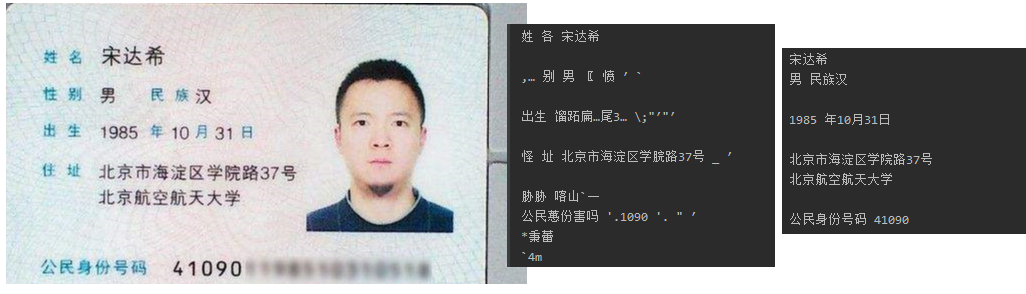
A5.jpg
参考资料:
- https://pushmind.org/2017/07/26/tesseract-notes/
- https://www.jianshu.com/p/41127bf90ca9
- https://my.oschina.net/gaoyoubo/blog/2231438/print
- https://blog.csdn.net/viewcode/article/details/7849448
OCR5:预处理的更多相关文章
- 借助 SIMD 数据布局模板和数据预处理提高 SIMD 在动画中的使用效率
原文链接 简介 为发挥 SIMD1 的最大作用,除了对其进行矢量化处理2外,我们还需作出其他努力.可以尝试为循环添加 #pragma omp simd3,查看编译器是否成功进行矢量化,如果性能有所提升 ...
- 前端学PHP之PDO预处理语句
× 目录 [1]定义 [2]准备语句 [3]绑定参数[4]执行查询[5]获取数据[6]大数据对象 前面的话 本来要把预处理语句和前面的基础操作写成一篇的.但是,由于博客园的限制,可能是因为长度超出,保 ...
- C语言之预处理
这是2016年的最后一篇博客,年初定的计划是写12篇博客,每月一篇,1/3转载,2/3原创,看来是实现不了了! -- 题外话.今天要写的东西是C语言中的预处理器,我们常说的宏定义的用法.为什么要写这个 ...
- CSS3与页面布局学习总结(七)——前端预处理技术(Less、Sass、CoffeeScript、TypeScript)
CSS不像其它高级语言一样支持算术运算.变量.流程控制与面向对象特性,所以CSS样式较多时会引起一些问题,如修改复杂,冗余,某些别的语言很简单的功能实现不了等.而javascript则是一种半面向对象 ...
- 【NLP】Tika 文本预处理:抽取各种格式文件内容
Tika常见格式文件抽取内容并做预处理 作者 白宁超 2016年3月30日18:57:08 摘要:本文主要针对自然语言处理(NLP)过程中,重要基础部分抽取文本内容的预处理.首先我们要意识到预处理的重 ...
- GCC 预处理、编译、汇编、链接..
1简介 GCC 的意思也只是 GNU C Compiler 而已.经过了这么多年的发展,GCC 已经不仅仅能支持 C 语言:它现在还支持 Ada 语言.C++ 语言.Java 语言.Objective ...
- 预处理指令#pragma
#pragma介绍 #pragma是一个预处理指令,pragma的中文意思是『编译指示』.它不是Objective-C中独有的东西(貌似在C/C++中使用比较多),最开始的设计初衷是为了保证代码在不同 ...
- 预处理命令[#define]说明
宏定义 宏定义是对一些常见的变量.字符串等进行定义,被定义的数据在编译会进行自动替换.有时一些变量或字符串被多次使用,当需要修改时,就需要对源文件中它们出现的地方一一修改,效率比较低,而通过宏定义,只 ...
- iOS开发系列--C语言之预处理
概述 大家都知道一个C程序的运行包括编译和链接两个阶段,其实在编译之前预处理器首先要进行预处理操作,将处理完产生的一个新的源文件进行编译.由于预处理指令是在编译之前就进行了,因此很多时候它要比在程序运 ...
随机推荐
- Generating YouTube-like IDs in Postgres using PL/V8 and Hashids
转自:https://blog.abevoelker.com/2017-01-03/generating-youtube-like-ids-in-postgres-using-plv8-and-has ...
- GLIBC中的库函数fflush究竟做了什么?
目录 目录 1 1. 库函数fflush原型 1 2. FILE结构体 1 3. fflush函数实现 2 4. fclose函数实现 4 附1:强弱函数名 5 附2:属性__visibility__ ...
- Shiro框架详解 tagline
之间工作中曾经用到过shiro这个权限控制的框架,之前一直都是停留在用的方面,没有过多的 去理解这方面的知识,现在有时间,专门研究了一下这个Shiro权限的框架使用. Shiro是什么? ...
- 第9课 C++异常处理机制
一. 回顾C++异常机制 (一)概述 1. 异常处理是C++的一项语言机制,用于在程序中处理异常事件(也被称为导常对象). 2. 异常事件发生时,使用throw关键字抛出异常表达,抛出点称为异常出现点 ...
- docker-compose可持续集成之nexus
什么是 Nexus 概述 Nexus 是一个强大的仓库管理器,极大地简化了内部仓库的维护和外部仓库的访问. 2016 年 4 月 6 日 Nexus 3.0 版本发布,相较 2.x 版本有了很大的改变 ...
- solr配置同义词,停止词,和扩展词库(IK分词器为例)
定义 同义词:搜索结果里出现的同义词.如我们输入”还行”,得到的结果包括同义词”还可以”. 停止词:在搜索时不用出现在结果里的词.比如is .a .are .”的”,“得”,“我” 等,这些词会在句子 ...
- 规范化使用MySQL
如何更规范化使用MySQL 如何更规范化使用MySQL 背景:一个平台或系统随着时间的推移和用户量的增多,数据库操作往往会变慢:而在Java应用开发中数据库更是尤为重要,绝大多数情况下数据库的性能决定 ...
- Spring+Spring+Hibernate环境搭建
源码地址:https://gitee.com/kszsa/ssht.git 一.引入lib包 pom.xml,引入需要的jar包 <?xml version="1.0" en ...
- javascript中的each遍历
each的用法 1.数组中的each 复制代码 var arr = [ "one", "two", "three", "four ...
- JavaScript核心知识点
一.JavaScript 简介 一.JavaScript语言的介绍:JavaScript是基于对象和原型的一种动态.弱类型的脚本语言 二.JavaScript语言的组成:JavaScript是由核心语 ...