Python数据分析 之时间序列基础
1. 时间序列基础
import numpy as np
import pandas as pd
np.random.seed(12345)
import matplotlib.pyplot as plt
plt.rc('figure', figsize=(10, 6))
PREVIOUS_MAX_ROWS = pd.options.display.max_rows
pd.options.display.max_rows = 20
np.set_printoptions(precision=4, suppress=True)
pandas最基本的时间序列类型就是以时间戳(通常以Python字符串或datatime对象表示)为索引的Series:
from datetime import datetime
dates = [datetime(2011, 1, 2), datetime(2011, 1, 5),
datetime(2011, 1, 7), datetime(2011, 1, 8),
datetime(2011, 1, 10), datetime(2011, 1, 12)]
ts = pd.Series(np.random.randn(6), index=dates)
ts
这些datetime对象实际上是被放在一个DatetimeIndex中的:
ts.index

跟其他Series一样,不同索引的时间序列之间的算术运算会自动按日期对 齐:
print(ts[::2]) #每隔一个取一个
ts + ts[::2]
pandas用NumPy的datetime64数据类型以纳秒形式存储时间戳:
ts.index.dtype
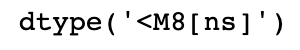
DatetimeIndex中的各个标量值是pandas的Timestamp对象:
stamp = ts.index[0]
stamp
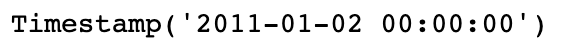
只要有需要,TimeStamp可以随时自动转换为datetime对象。此外,它还可以存储频率信息(如果有的话),且知道如何执行时区转换以及其他操作。 之后将对此进行详细讲解。
2. 索引、选取、子集构造
当你根据标签索引选取数据时,时间序列和其它的pandas.Series很像:
print(ts)
stamp = ts.index[2]
print(ts[stamp]) #标签索引
print(ts[2]) #整数索引
还有一种更为方便的用法:传入一个可以被解释为日期的字符串:
print(ts['1/10/2011'])
print(ts['20110110'])
ts['2011-01-10']

对于较长的时间序列,只需传入“年”或“年月”即可轻松选取数据的切片:
longer_ts = pd.Series(np.random.randn(1000),
index=pd.date_range('1/1/2000', periods=1000))#天为单位
longer_ts
longer_ts['2001']
这里,字符串“2001”被解释成年,并根据它选取时间区间。指定月也同样奏效:
longer_ts['2001-05']
datetime对象也可以进行切片:
print(ts)
ts[datetime(2011, 1, 7):]
由于大部分时间序列数据都是按照时间先后排序的,因此你也可以用不存在于该时间序列中的时间戳对其进行切片(即范围查询):
ts['1/6/2011':'1/11/2011']

跟之前一样,你可以传入字符串日期、datetime或Timestamp进行索引。注意,这样 切片所产生的是原时间序列的视图(共享内存),跟NumPy数组的切片运算是一样的。
这意味着,没有数据被复制,对切片进行修改会反映到原始数据上。
此外,还有一个等价的实例方法也可以截取两个日期之间TimeSeries:
ts.truncate(after='1/9/2011')无锡妇科医院哪家好 http://www.xasgyy.net/

这些操作对DataFrame也有效。例如,对DataFrame的行进行索引:
dates = pd.date_range('1/1/2000', periods=100, freq='W-WED') #间隔单位为周
long_df = pd.DataFrame(np.random.randn(100, 4),
index=dates,
columns=['Colorado', 'Texas',
'New York', 'Ohio'])
long_df.loc['5-2001']
3. 带有重复索引值的时间序列
在某些应用场景中,可能会存在多个观测数据落在同一个时间点上的情况。下面就是一个例子:
dates = pd.DatetimeIndex(['1/1/2000', '1/2/2000', '1/2/2000',
'1/2/2000', '1/3/2000'])
dup_ts = pd.Series(np.arange(5), index=dates)
dup_ts

通过检查索引的is_unique属性,我们就可以知道它是不是唯一的:
dup_ts.index.is_unique
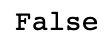
对这个时间序列进行索引,要么产生标量值,要么产生切片,具体要看所选的时间点是否重复:
print(dup_ts['1/3/2000'])# not duplicated
dup_ts['1/2/2000'] # duplicated
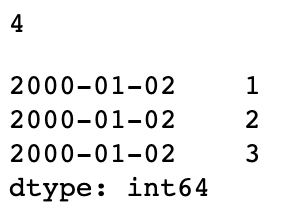
假设你想要对具有非唯一时间戳的数据进行聚合。一个办法是使用 groupby,并传入level=0:
grouped = dup_ts.groupby(level=0)
print(grouped.mean())
grouped.count()
Python数据分析 之时间序列基础的更多相关文章
- 第一章:Python数据分析前的基础铺垫
本节概要 - 数据类型 - 数据结构 - 数据的常用操作方法 数据类型 基础铺垫 定义 我们搞数据时,首先要告诉Python我们的数据类型是什么 数值型:直接写一个数字即可 逻辑型:True,Fals ...
- python数据分析02语法基础
在我来看,没有必要为了数据分析而去精通Python.我鼓励你使用IPython shell和Jupyter试验示例代码,并学习不同类型.函数和方法的文档.虽然我已尽力让本书内容循序渐进,但读者偶尔仍会 ...
- 零基础学习Python web开发、Python爬虫、Python数据分析,从基础到项目实战!
随着大数据和人工智能的发展,目前Python语言的上升趋势比较明显,而且由于Python语言简单易学,所以不少初学者往往也会选择Python作为入门语言. Python语言目前是IT行业内应用最为广泛 ...
- Python数据分析 Pandas模块 基础数据结构与简介(一)
pandas 入门 简介 pandas 组成 = 数据面板 + 数据分析工具 poandas 把数组分为3类 一维矩阵:Series 把ndarray强大在可以存储任意数据类型可以专门处理时间数据 二 ...
- 【Python数据分析】IPython基础
一.配置启动IPython 打开cmd窗口,在dos界面下输入ipython,结果报错了!!! 出现这个问题是由于环境变量未配置(前提:已经安装了ipython),那么接下来配置环境变量 我的电脑→右 ...
- Python数据分析 Pandas模块 基础数据结构与简介(二)
重点方法 分组:groupby('列名') groupby(['列1'],['列2'........]) 分组步骤: (spiltting)拆分 按照一些规则将数据分为不同的组 (Applying)申 ...
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 利用Python进行数据分析(5) NumPy基础: ndarray索引和切片
概念理解 索引即通过一个无符号整数值获取数组里的值. 切片即对数组里某个片段的描述. 一维数组 一维数组的索引 一维数组的索引和Python列表的功能类似: 一维数组的切片 一维数组的切片语法格式为a ...
- 利用Python进行数据分析(9) pandas基础: 汇总统计和计算
pandas 对象拥有一些常用的数学和统计方法. 例如,sum() 方法,进行列小计: sum() 方法传入 axis=1 指定为横向汇总,即行小计: idxmax() 获取最大值对应的索 ...
随机推荐
- JDOJ 2982: 最大连续子段和问题
洛谷 P1115 最大子段和 洛谷传送门 JDOJ 2982: 最大连续子段和问题 JDOJ传送门 题目描述 给出一段序列,选出其中连续且非空的一段使得这段和最大. 输入格式 第一行是一个正整数NN, ...
- 7.Go退出向Consuk反注册服务,优雅关闭服务
注册和反注册代码 package utils import ( consulapi "github.com/hashicorp/consul/api" "log" ...
- es6 Class类的使用
es6新增了一种定义对象实例的方法,使用class关键字定义类,与class相关的知识点也逐步火热起来,但是部分理解起来相对抽象,简单对class相关的知识点进行总结,更好的使用class. 关于类有 ...
- Generating YouTube-like IDs in Postgres using PL/V8 and Hashids
转自:https://blog.abevoelker.com/2017-01-03/generating-youtube-like-ids-in-postgres-using-plv8-and-has ...
- IDEA中各种图标
前言 在用这个开发工具之前对大量的图标先有所了解,会提高不少效率 首先讲下基本的图标 Java类 Java抽象类 Groovy类 注解类 枚举类 异常类 最终的类 接口 包含有main方法的可 ...
- 基于zookeeper-3.5.5安装hadoop-3.1.2
目录 目录 1 1. 前言 3 2. 缩略语 3 3. 安装步骤 4 4. 下载安装包 4 5. 机器规划 4 6. 设置批量操作参数 5 7. 环境准备 5 7.1. 修改最大可打开文件数 5 7. ...
- 洛谷p3916图的遍历题解
题面 思路: 反向建边,dfs艹咋想出来的啊 倒着遍历,如果你现在遍历到的这个点已经被标记了祖先是谁了 那么就continue掉 因为如果被标记了就说明前面已经遍历过了 而我们的顺序倒着来的 前边的一 ...
- 专题-主存储器与Cache的地址映射方式
2019/05/02 10:23 首先,我们注意到地址映射有三种:分别是直接地址映射.全相联映射.组相联映射. 首先我们搞清楚主存地址还有Cache地址的关系,还有组内地址的关系,常见我们的块内地址, ...
- 安装-apache skywalking (java 应用性能监控)
官网:http://skywalking.apache.org/ 服务器:10.30.31.28 centos 7 jdk 1.8.x ES 5.x 5.0.0-bet a2版本 . http://s ...
- DI 依赖注入之unity的MVC版本使用Microsoft.Practices.Unity1.2与2.0版本对比
DI 依赖注入之unity的MVC版本使用Microsoft.Practices.Unity1.2与2.0版本对比 参考:https://www.cnblogs.com/xishuai/p/36702 ...