python_进程池以及线程池
可以重复利用的线程
直接上代码
from threading import Thread, current_thread
from queue import Queue
# 重写线程类
class MyThread(Thread):
def __init__(self):
super().__init__()
self.daemon = True # 守护线程
self.queue = Queue(10)
self.start() # 实例化的时候开启线程 def run(self): # 子线程只有这一个线程, 从队列里面拿任务
while True:
task, args, kwargs = self.queue.get() # 拿任务 也是元组
task(*args, **kwargs) # 可能有,可能没有,所有传入不定长参数
self.queue.task_done() # 结束任务 def apply_async(self, func, args=(), kwargs={}): # 自写任务,不是重写任务, 充当生产者, 给线程提供任务(把任务扔到队列)
self.queue.put((func, args, kwargs)) def join_R(self): # 主线程等待子线程结束
self.queue.join() # task_done 为0 的时候就阻塞 def func():
print(1, current_thread()) def func2(*args, **kwargs):
print(2, current_thread())
print('func: ', args, kwargs) t = MyThread()
t.apply_async(func)
t.apply_async(func2, args=(1,2), kwargs={'a':1, 'b':2})
print("任务提交完成")
t.join_R()
print("任务完成")
结果:
任务提交完成
1 <MyThread(Thread-1, started daemon -1223214272)>
2 <MyThread(Thread-1, started daemon -1223214272)>
func: (1, 2) {'a': 1, 'b': 2}
任务完成 任务完成后,主线程就开始退出, 因此守护线程被杀死
线程池的简单实现
池的概念
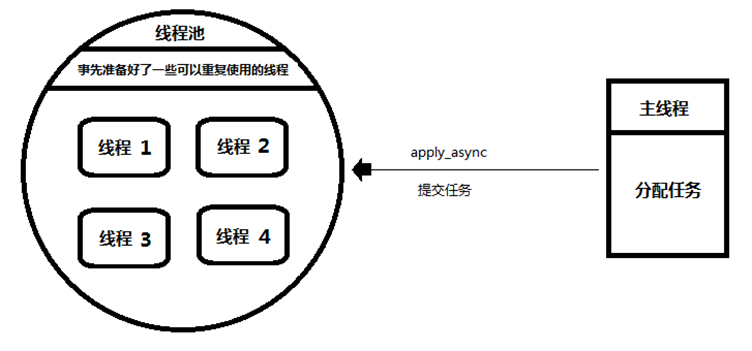
主线程: 相当于生产者,只管向线程池提交任务。
并不关心线程池是如何执行任务的。
因此,并不关心是哪一个线程执行的这个任务。
线程池: 相当于消费者,负责接收任务,
并将任务分配到一个空闲的线程中去执行。
代码实现如下:
from threading import Thread, current_thread
from queue import Queue class T_pool:
def __init__(self, n): # 准备多少个池
super().__init__()
self.queue = Queue()
for i in range(n): # 在池里开多少个线程
Thread(target=self.fun, daemon=Thread).start() # 守护进程 并启动 def fun(self): # 生产者
while True:
task = self.queue.get()
task()
self.queue.task_done() def apply_async(self, task): # 消费者
self.queue.put(task) def join(self):
self.queue.join() def func():
print(current_thread()) def func2():
print(current_thread()) p = T_pool(2)
p.apply_async(func)
p.apply_async(func2)
p.join()
结果:
<Thread(Thread-1, started daemon -1223324864)>
<Thread(Thread-1, started daemon -1223324864)>
Python自带的池
内置线程池
from multiprocessing.pool import ThreadPool # 线程池
from multiprocessing import pool # 进程池
# 内置线程池
def fun(*args, **kwargs):
print(args, kwargs) p = ThreadPool(2) # 直接使用内置的
p.apply_async(fun, args=(1,2), kwds={'a':1})
p.close() # 要求:在join前必须要close,这样就不允许再提交任务了
p.join()
结果:
(1, 2) {'a': 1}
内置进程池
from multiprocessing import Pool # 进程池
# 内置进程池
def fun(*args, **kwargs):
print(args, kwargs) if __name__ == '__main__': # 必须要有一个main测试
p = Pool(2) # pool的实例化必须在main测试之下
p.apply_async(fun, args=(1,2), kwds={'a':1})
p.close() # 要求:在join前必须要close,这样就不允许再提交任务了
p.join()
结果:
(1, 2) {'a': 1}
池的其他操作 操作一: close - 关闭提交通道,不允许再提交任务
操作一: close - 关闭提交通道,不允许再提交任务 操作二: terminate - 中止进程池,中止所有任务
操作二: terminate - 中止进程池,中止所有任务  操作三: 结果操作
操作三: 结果操作
结果操作
from multiprocessing.pool import ThreadPool
import time
def func(n):
if n == 1:
return 1
elif n == 2:
return 2
return func(n-1) + func(n-2) pool = ThreadPool() a_result = pool.apply_async(func, args=(35,))
print("note1:",time.asctime(time.localtime(time.time())))
result = a_result.get() # 会阻塞,知道结果产生了
print("note2:",time.asctime(time.localtime(time.time())))
结果:
note1: Mon Sep 17 00:07:31 2018
note2: Mon Sep 17 00:07:34 2018
使用池来实现并发服务器
使用线程池来实现并发服务器
import socket
from multiprocessing.pool import ThreadPool # 线程池
from multiprocessing import Pool, cpu_count
'''
使用线程池来实现
并发服务器
'''
print(cpu_count()) server = socket.socket()
server.bind(('0.0.0.0', 8080))
server.listen(1000) def work_thread(conn):
while True:
data = conn.recv(1000)
if data:
print(data)
conn.send(data) else:
conn.close()
break if __name__ == '__main__': t_pool = ThreadPool(5) # 使用线程池, 通常分配2倍的cpu个数
while True:
conn,addr = server.accept()
t_pool.apply_async(work_thread, args=(conn,)) # 接收的是个任务, conn做为参数
使用进程池来实现并发服务器
import socket
from multiprocessing.pool import ThreadPool # 线程池
from multiprocessing import Pool, cpu_count
'''
使用进程池来实现
并发服务器
'''
print(cpu_count()) server = socket.socket()
server.bind(('0.0.0.0', 9000))
server.listen(1000) def work_process(server):
t_pool = ThreadPool(cpu_count()*2) # 使用线程池, 通常分配2倍的cpu个数
while True:
conn,addr = server.accept()
t_pool.apply_async(work_thread, args=(conn,)) # 接收的是个任务, conn做为参数 def work_thread(conn):
while True:
data = conn.recv(1000)
if data:
print(data)
conn.send(data) else:
conn.close()
break n = cpu_count() # 获取当前计算机的CPU核心数量
p = Pool(n)
for i in range(n): # 充分利用CPU, 为每个CPU分配一个进程
p.apply_async(work_process, args=(server,)) p.close()
p.join()
客户端:
import socket click = socket.socket()
click.connect(('127.0.0.1', 8888)) while True:
data = input("请输入你要发送的数据:")
click.send(data.encode())
print("接收到的消息: {}".format(click.recv(1024).decode()))
总结完毕。
作者:含笑半步颠√
博客链接:https://www.cnblogs.com/lixy-88428977
声明:本文为博主学习感悟总结,水平有限,如果不当,欢迎指正。如果您认为还不错,欢迎转载。转载与引用请注明作者及出处。
python_进程池以及线程池的更多相关文章
- python系列之 - 并发编程(进程池,线程池,协程)
需要注意一下不能无限的开进程,不能无限的开线程最常用的就是开进程池,开线程池.其中回调函数非常重要回调函数其实可以作为一种编程思想,谁好了谁就去掉 只要你用并发,就会有锁的问题,但是你不能一直去自己加 ...
- 第三十八天 GIL 进程池与线程池
今日内容: 1.GIL 全局解释器锁 2.Cpython解释器并发效率验证 3.线程互斥锁和GIL对比 4.进程池与线程池 一.全局解释器锁 1.GIL:全局解释器锁 GIL本质就是一把互斥锁,是夹在 ...
- python并发编程之进程池,线程池,协程
需要注意一下不能无限的开进程,不能无限的开线程最常用的就是开进程池,开线程池.其中回调函数非常重要回调函数其实可以作为一种编程思想,谁好了谁就去掉 只要你用并发,就会有锁的问题,但是你不能一直去自己加 ...
- 基于concurrent.futures的进程池 和线程池
concurrent.futures:是关于进程池 和 线程池 的 官方文档 https://docs.python.org/dev/library/concurrent.futures.html 现 ...
- GIL锁、进程池与线程池
1.什么是GIL? 官方解释: ''' In CPython, the global interpreter lock, or GIL, is a mutex that prevents multip ...
- python自带的进程池及线程池
进程池 """ python自带的进程池 """ from multiprocessing import Pool from time im ...
- 内存池、进程池、线程池介绍及线程池C++实现
本文转载于:https://blog.csdn.net/ywcpig/article/details/52557080 内存池 平常我们使用new.malloc在堆区申请一块内存,但由于每次申请的内存 ...
- python并发编程之进程池,线程池concurrent.futures
进程池与线程池 在刚开始学多进程或多线程时,我们迫不及待地基于多进程或多线程实现并发的套接字通信,然而这种实现方式的致命缺陷是:服务的开启的进程数或线程数都会随着并发的客户端数目地增多而增多, 这会对 ...
- python之进程池与线程池
一.进程池与线程池介绍 池子使用来限制并发的任务数目,限制我们的计算机在一个自己可承受的范围内去并发地执行任务 当并发的任务数远远超过了计算机的承受能力时,即无法一次性开启过多的进程数或线程数时就应该 ...
- 12 并发编程-(线程)-线程queue&进程池与线程池
queue 英 /kjuː/ 美 /kju/ 队列 1.class queue.Queue(maxsize=0) #队列:先进先出 import queue q=queue.Queue() q.put ...
随机推荐
- 使用 gitstats 来统计代码
使用 gitstats 来统计代码 github地址如下 gitstats clone地址 git clone https://github.com/hoxu/gitstats && ...
- GoCN每日新闻(2019-10-27)
GoCN每日新闻(2019-10-27) 1. Golab(意大利GopherCon)2019见闻 http://fedepaol.github.io/blog/2019/10/23/golab-20 ...
- centos7安装hadoop2.7.7
下载hadoop-2.7.7 网址如下 https://www-eu.apache.org/dist/hadoop/core/ 移动到/opt 路径下 在/opt下新建一个文件夹,名为app mkdi ...
- python 获取天气信息,并绘制曲线
import urllib.request import gzip import json print('------天气查询------') def get_weather_data() : cit ...
- 认真分析mmap:是什么 为什么 怎么用(转)
阅读目录 mmap基础概念 mmap内存映射原理 mmap和常规文件操作的区别 mmap优点总结 mmap相关函数 mmap使用细节 回到顶部 mmap基础概念 mmap是一种内存映射文件的方法,即将 ...
- MLflow系列4:MLflow模型
英文链接:https://mlflow.org/docs/latest/models.html 本文链接:https://www.cnblogs.com/CheeseZH/p/11946260.htm ...
- android -------- VideoCache 视频播放(缓存视频到本地)
先前做了一个小视频的功能,里面有播放多个视频的功能,为了效率,我加了视频缓存功能: 一方面耗费用户的流量,另一方面直接从本地播放要更流畅 网上看资料,一个视频缓存库,使用起来很方便,还不错,就分享给大 ...
- MYSQL定时任务-定时清除备份数据
背景 由于项目需要,每个月的历史存量数据需要进行一个归档和备份操作,以及一些日志表需要进行一个明细字段清除,让mysql数据库磁盘节省空间.则需要一些定时任务来定时清理这些数据. 技术选型 Java ...
- JFinal 数据库“手动”事务(提交、回滚)
一.用注解 @Before(Tx.class) 实现 事务回滚 @Before(Tx.class) public void pay() throws Exception { //throws exce ...
- JSON字符串转实体对象
JSON转实体两种方式 代码片段 ; i < dt.Rows.Count; i++) { //Json字符串 string designJson = dt.Rows[i]["Desig ...