基于spark logicplan的表血缘关系解析实现
随着公司平台用户数量与表数量的不断增多,各种表之间的数据流向也变得更加复杂,特别是某个任务中会对源表读取并进行一系列复杂的变换后又生成新的数据表,因此需要一套表血缘关系解析机制能清晰地解析出每个任务所形成的表血缘关系链。
实现思路:
spark对sql的操作会形成一个dataframe,dataframe中的logicplan包含了sql的语法树,通过对logicplan的语法树解析可以获取当前stage所操作的输入表和输出表,将整套表关系链连接起来,再去除中间表即可获取当前作业的输入表和输出表信息。
核心代码:
def resolveLogicPlan(plan: LogicalPlan, currentDB:String): (util.Set[DcTable], util.Set[DcTable]) ={
val inputTables = new util.HashSet[DcTable]()
val outputTables = new util.HashSet[DcTable]()
resolveLogic(plan, currentDB, inputTables, outputTables)
Tuple2(inputTables, outputTables)
}
def resolveLogic(plan: LogicalPlan, currentDB:String, inputTables:util.Set[DcTable], outputTables:util.Set[DcTable]): Unit ={
plan match {
case plan: Project =>
val project = plan.asInstanceOf[Project]
resolveLogic(project.child, currentDB, inputTables, outputTables)
case plan: Union =>
val project = plan.asInstanceOf[Union]
for(child <- project.children){
resolveLogic(child, currentDB, inputTables, outputTables)
}
case plan: Join =>
val project = plan.asInstanceOf[Join]
resolveLogic(project.left, currentDB, inputTables, outputTables)
resolveLogic(project.right, currentDB, inputTables, outputTables)
case plan: Aggregate =>
val project = plan.asInstanceOf[Aggregate]
resolveLogic(project.child, currentDB, inputTables, outputTables)
case plan: Filter =>
val project = plan.asInstanceOf[Filter]
resolveLogic(project.child, currentDB, inputTables, outputTables)
case plan: Generate =>
val project = plan.asInstanceOf[Generate]
resolveLogic(project.child, currentDB, inputTables, outputTables)
case plan: RepartitionByExpression =>
val project = plan.asInstanceOf[RepartitionByExpression]
resolveLogic(project.child, currentDB, inputTables, outputTables)
case plan: SerializeFromObject =>
val project = plan.asInstanceOf[SerializeFromObject]
resolveLogic(project.child, currentDB, inputTables, outputTables)
case plan: MapPartitions =>
val project = plan.asInstanceOf[MapPartitions]
resolveLogic(project.child, currentDB, inputTables, outputTables)
case plan: DeserializeToObject =>
val project = plan.asInstanceOf[DeserializeToObject]
resolveLogic(project.child, currentDB, inputTables, outputTables)
case plan: Repartition =>
val project = plan.asInstanceOf[Repartition]
resolveLogic(project.child, currentDB, inputTables, outputTables)
case plan: Deduplicate =>
val project = plan.asInstanceOf[Deduplicate]
resolveLogic(project.child, currentDB, inputTables, outputTables)
case plan: Window =>
val project = plan.asInstanceOf[Window]
resolveLogic(project.child, currentDB, inputTables, outputTables)
case plan: MapElements =>
val project = plan.asInstanceOf[MapElements]
resolveLogic(project.child, currentDB, inputTables, outputTables)
case plan: TypedFilter =>
val project = plan.asInstanceOf[TypedFilter]
resolveLogic(project.child, currentDB, inputTables, outputTables)
case plan: Distinct =>
val project = plan.asInstanceOf[Distinct]
resolveLogic(project.child, currentDB, inputTables, outputTables)
case plan: SubqueryAlias =>
val project = plan.asInstanceOf[SubqueryAlias]
val childInputTables = new util.HashSet[DcTable]()
val childOutputTables = new util.HashSet[DcTable]()
resolveLogic(project.child, currentDB, childInputTables, childOutputTables)
if(childInputTables.size()>){
for(table <- childInputTables) inputTables.add(table)
}else{
inputTables.add(DcTable(currentDB, project.alias))
}
case plan: CatalogRelation =>
val project = plan.asInstanceOf[CatalogRelation]
val identifier = project.tableMeta.identifier
val dcTable = DcTable(identifier.database.getOrElse(currentDB), identifier.table)
inputTables.add(dcTable)
case plan: UnresolvedRelation =>
val project = plan.asInstanceOf[UnresolvedRelation]
val dcTable = DcTable(project.tableIdentifier.database.getOrElse(currentDB), project.tableIdentifier.table)
inputTables.add(dcTable)
case plan: InsertIntoTable =>
val project = plan.asInstanceOf[InsertIntoTable]
resolveLogic(project.table, currentDB, outputTables, inputTables)
resolveLogic(project.query, currentDB, inputTables, outputTables)
case plan: CreateTable =>
val project = plan.asInstanceOf[CreateTable]
if(project.query.isDefined){
resolveLogic(project.query.get, currentDB, inputTables, outputTables)
}
val tableIdentifier = project.tableDesc.identifier
val dcTable = DcTable(tableIdentifier.database.getOrElse(currentDB), tableIdentifier.table)
outputTables.add(dcTable)
case plan: GlobalLimit =>
val project = plan.asInstanceOf[GlobalLimit]
resolveLogic(project.child, currentDB, inputTables, outputTables)
case plan: LocalLimit =>
val project = plan.asInstanceOf[LocalLimit]
resolveLogic(project.child, currentDB, inputTables, outputTables)
case `plan` => logger.info("******child plan******:\n"+plan)
}
}
上述代码是对logicplan做递归解析的,当logicplan为LocalLimit、GlobalLimit、Window等类型时,继续解析其子类型;当logicplan为CataLogRelation、UnresolvedRelation时,解析出的表名作为输入表;当logicplan为CreateTable、InsertIntoTable时,解析出的表名为输出表。
这里需要考虑一种特殊情况,某些源表是通过spark.read加载得到的,这样logicplan解析出来的类型为LogicRDD,不能直接获取到表名,以下面的python代码为例:
schema = StructType([StructField('id', IntegerType(), True), StructField('name', StringType(), True), StructField('age', IntegerType(), True)])
rdd = sparkSession.sparkContext.textFile('/user/hive/warehouse/bigdata.db/tdl_spark_test/testdata.txt').map(lambda r:r.split(',')).map(lambda p: Row(int(p[]), p[], int(p[])))
df = sparkSession.createDataFrame(rdd, schema)
df.createOrReplaceTempView('tdl_spark_test')
sparkSession.sql('create table tdl_file_test as select * from tdl_spark_test')
上述代码首先通过textFile读取文件得到rdd,再对rdd进行变换,最后将rdd注册成dataframe,这里对df的logicplan进行解析会得到LogicRDD,对于这种情况的解决思路是在调用textFile时记录产生的rdd,解析df的logicplan时获取其rdd,判断之前产生的rdd是否为当前rdd的祖先,如果是,则将之前rdd对应的表名计入。
判断rdd依赖关系的逻辑为:
def checkRddRelationShip(rdd1:RDD[_], rdd2:RDD[_]): Boolean ={
if (rdd1.id == rdd2.id) return true
dfsSearch(rdd1, rdd2.dependencies)
}
def dfsSearch(rdd1:RDD[_], dependencies:Seq[Dependency[_]]): Boolean ={
for(dependency <- dependencies){
if(dependency.rdd.id==rdd1.id) return true
if(dfsSearch(rdd1, dependency.rdd.dependencies)) return true
}
false
}
对LogicRDD的解析为:
case plan: LogicalRDD =>
val project = plan.asInstanceOf[LogicalRDD]
try{
for(rdd <- rddTableMap.keySet()){
if(checkRddRelationShip(rdd, project.rdd)){
val tableName = rddTableMap.get(rdd)
val db = StringUtils.substringBefore(tableName, ".")
val table = StringUtils.substringAfter(tableName, ".")
inputTables.add(DcTable(db, table))
}
}
}catch {
case e:Throwable => logger.error("resolve LogicalRDD error:", e)
}
在spark中会生成dataframe的代码段中通过aspect进行拦截,并且解析dataframe得到表的关系链,此时的关系链是一张有向无环图,图中可能包含中间表,去除掉中间表节点,则得到最终的数据流向图。
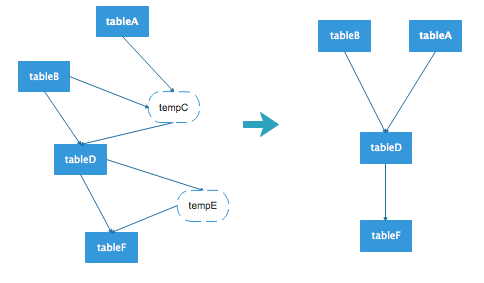
例如上图的左边是一张原始的表数据流向,其中tempC和tempE为临时表,去除这个图中的临时表节点,得到右图的数据流向图。对于前面给出的python代码,执行过后获取的数据流向为:
[bigdata.tdl_spark_test]--->bigdata.tdl_file_test
当然这种解析方式也存在一些缺点,比如首先通过spark.read读取数据注册一张临时表,再将临时表中的某些字段值拉到本地缓存,然后创建一个空的datadrame,将缓存的字段值直接插入到该df中,由于当前创建的df与之前创建的df已经没有依赖关系,因此这种情况将无法解析出准确的数据流向。
基于spark logicplan的表血缘关系解析实现的更多相关文章
- 基于Spark GraphX计算二度关系
关系计算问题描述 二度关系是指用户与用户通过关注者为桥梁发现到的关注者之间的关系.目前微博通过二度关系实现了潜在用户的推荐.用户的一度关系包含了关注.好友两种类型,二度关系则得到关注的关注.关注的好友 ...
- 苏宁基于Spark Streaming的实时日志分析系统实践 Spark Streaming 在数据平台日志解析功能的应用
https://mp.weixin.qq.com/s/KPTM02-ICt72_7ZdRZIHBA 苏宁基于Spark Streaming的实时日志分析系统实践 原创: AI+落地实践 AI前线 20 ...
- 基于MaxCompute InformationSchema进行血缘关系分析
一.需求场景分析 在实际的数据平台运营管理过程中,数据表的规模往往随着更多业务数据的接入以及数据应用的建设而逐渐增长到非常大的规模,数据管理人员往往希望能够利用元数据的分析来更好地掌握不同数据表的血缘 ...
- 基于Extjs的web表单设计器 第七节——取数公式设计之取数公式的使用
基于Extjs的web表单设计器 基于Extjs的web表单设计器 第一节 基于Extjs的web表单设计器 第二节——表单控件设计 基于Extjs的web表单设计器 第三节——控件拖放 基于Extj ...
- 基于 Spark 的文本情感分析
转载自:https://www.ibm.com/developerworks/cn/cognitive/library/cc-1606-spark-seniment-analysis/index.ht ...
- 京东基于Spark的风控系统架构实践和技术细节
京东基于Spark的风控系统架构实践和技术细节 时间 2016-06-02 09:36:32 炼数成金 原文 http://www.dataguru.cn/article-9419-1.html ...
- 血缘关系分析工具SQLFLOW--实践指南
SQLFlow 是用于追溯数据血缘关系的工具,它自诞生以来以帮助成千上万的工程师即用户解决了困扰许久的数据血缘梳理工作. 数据库中视图(View)的数据来自表(Table)或其他视图,视图中字段(Co ...
- Django 一对多,多对多关系解析
[转]Django 一对多,多对多关系解析 Django 的 ORM 有多种关系:一对一,多对一,多对多. 各自定义的方式为 : 一对一: OneToOneField ...
- mybatis整合spring 之 基于接口映射的多对一关系
转载自:http://my.oschina.net/huangcongmin12/blog/83731 mybatis整合spring 之 基于接口映射的多对一关系. 项目用到俩个表,即studen ...
随机推荐
- 钉钉、阿里云和PaaS平台的整合开发
钉钉在企业移动办公领域有着很高的占有率,但是可能大家都会觉得,他在企业定制化,数据分析等领域有着很大的短板. 而我们的kintone作为PaaS平台,可以补足这个短板.很多开发者想知道如何利用钉钉还有 ...
- React中的State与Props
一.State 1.什么是 state 一个组件的显示形态可以由数据状态和外部参数决定,其中,数据状态为 state,外部参数为 props 2.state 的使用 组件初始化时,通过 this.st ...
- 51nod 2517 最少01翻转次数
小b有一个01序列,她每次可以翻转一个元素,即将该元素异或上1. 现在她希望序列不降,求最少翻转次数. 收起 输入 第一行输入一个数n,其中1≤n≤20000: 第二行输入一个由‘0’和‘1’组成 ...
- 小白怎么用最短时间高效的学习Python?
之所以写这篇文章,在标题里已经表达得很清楚了.做技术的人都知道,时间就是金钱不是一句空话,同一个技术,你比别人早学会半年,那你就能比别人多拿半年的钱.所以有时候别人去培训我也不怎么拦着,为什么?因为培 ...
- vue 博客知识点汇总
1. vue修改url,页面不刷新 项目中经常会用到同一个页面,结构是相同的,我只是在vue-router中通过添加参数的方式来区分状态,参数可以在页面跳转时带上params,或者query,但是有一 ...
- mac pro下安装brew软件包管理工具
Homebrew简称brew,OSX上的软件包管理工具,在Mac终端可以通过brew安装.更新.卸载软件. 1.打开终端直接输入下面指令回车: ruby -e "$(curl -fsSL h ...
- Nginx页面图片错误 ERR_CONTENT_LENGTH_MISMATCH
现场:nginx代理的网站有的虚拟目录的图片无法正常显示,提示 ERR_CONTENT_LENGTH_MISMATCH,不断刷新页面图片一条一条的显示出来. 解决方法:找到nginx的缓存文件目录,c ...
- 语法速学,返回数组 repeated修饰符
重新编写proto文件 syntax = "proto3"; package services; import "google/api/annotations.proto ...
- Tomcat 部署多个web项目
1.若Tomcat的端口设置为10000,则http://localhost:10000访问的目录是 webapps 2.Service.xml中host内配置Context标签,path+docba ...
- Java 中List集合中自定义排序
/* 集合框架的工具类. Collections:集合框架的工具类.里面定义的都是静态方法. Collections和Collection有什么区别? Collection是集合框架中的一个顶层接口, ...