2. RDD编程
2.1 编程模型
在Spark中,RDD被表示为对象,通过对象上的方法调用来对RDD进行转换。经过一系列的transformations定义RDD之后,就可以调用actions触发RDD的计算,action可以是向应用程序返回结果(count, collect等),或者是向存储系统保存数据(saveAsTextFile等)。在Spark中,只有遇到action,才会执行RDD的计算(即延迟计算),这样在运行时可以通过管道的方式传输多个转换
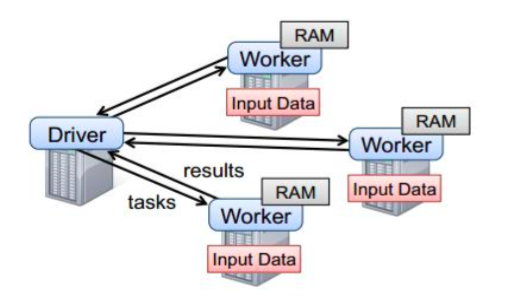
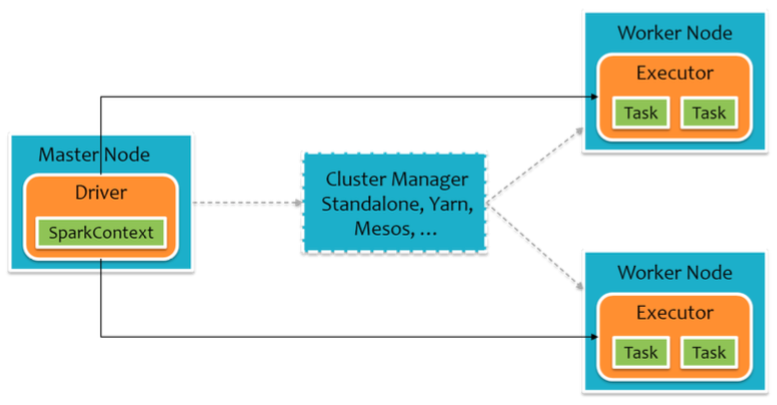
要使用Spark,开发者需要编写一个Driver程序,它被提交到集群以调度运行Worker,如下图所示。Driver中定义了一个或多个RDD,并调用RDD上的action,Worker则执行RDD分区计算任务
2.2 创建RDD
在Spark中创建RDD的创建方式大概可以分为三种:
1、从集合中创建RDD;
2、从外部存储创建RDD;
3、从其他RDD创建
1) 由一个已经存在的Scala集合创建,集合并行化
val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8))
而从集合中创建RDD,Spark主要提供了两种函数:parallelize和makeRDD。我们可以先看看这两个函数的声明:
def parallelize[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] def makeRDD[T: ClassTag](seq: Seq[(T, Seq[String])]): RDD[T]
从上面可以看出makeRDD有两种实现,而且第一个makeRDD函数接收的参数和parallelize完全一致。其实第一种makeRDD函数实现是依赖了parallelize函数的实现,来看看在Spark中是怎么实现这个makeRDD函数的:
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
parallelize(seq, numSlices)
}
我们可以看出,这个makeRDD函数完全和parallelize函数一致。但是我们得看看第二种makeRDD函数的函数实现,它接收的参数类型是Seq[(T,Seq[String])],Spark文档的说明是:
Distribute a local Scala collection to form an RDD, with one or more location preferences (hostnames of Spark nodes) for each object. Create a new partition for each collection item.
这个函数还为数据提供了位置信息,看看如何使用:
scala> val boke01= sc.parallelize(List(1,2,3))
boke01: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[10] at parallelize at <console>:21
scala> val boke02 = sc.makeRDD(List(1,2,3))
boke02: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[11] at makeRDD at <console>:21
scala> val seq = List((1, List("slave01")), | (2, List("slave02")))
seq: List[(Int, List[String])] = List((1,List(slave01)), (2,List(slave02)))
scala> val boke03 = sc.makeRDD(seq)
boke03: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[12] at makeRDD at <console>:23
scala> boke03.preferredLocations(boke03.partitions(1)) res26: Seq[String] = List(slave02)
scala> boke03.preferredLocations(boke03.partitions(0)) res27: Seq[String] = List(slave01)
scala> boke01.preferredLocations(boke01.partitions(0)) res28: Seq[String] = List()
可以看到,makeRDD函数有两种实现,第一种实现其实完全和parallelize一致;而第二种实现可以为数据提供位置信息,而除此之外的实现和parallelize函数也是一致的,如下:
def parallelize[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
assertNotStopped()
new ParallelCollectionRDD[T](this, seq, numSlices, Map[Int, Seq[String]]())
} def makeRDD[T: ClassTag](seq: Seq[(T, Seq[String])]): RDD[T] = withScope {
assertNotStopped()
val indexToPrefs = seq.zipWithIndex.map(t => (t._2, t._1._2)).toMap
new ParallelCollectionRDD[T](this, seq.map(_._1), seq.size, indexToPrefs)
}
都是ParallelCollectionRDD,而且这个makeRDD的实现不可以自己指定分区的数量,而是固定为seq参数的size大小
2) 由外部存储系统的数据集创建,包括本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、Cassandra、HBase等
scala> val demo01 = sc.textFile("hdfs://master01:9000/RELEASE")
demo01: org.apache.spark.rdd.RDD[String] = hdfs://master01:9000/RELEASE MapPartitionsRDD[4] at textFile at <console>:24
2.3 RDD编程
RDD一般分为数值RDD和键值对RDD,这里先不进行具体区分,先统一来看,下一章会对键值对RDD做专门说明
2.3.1 Transformation
RDD中的所有转换都是延迟加载的,也就是说,它们并不会直接计算结果。相反的,它们只是记住这些应用到基础数据集(例如一个文件)上的转换动作。只有当发生一个要求返回结果给Driver的动作时,这些转换才会真正运行。这种设计让Spark更加有效率地运行
常用的Transformation:
1) map(func),含义:返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成
2) filter(func),含义:返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成
3) flatMap(func),含义:类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素)
4) mapPartitions(func),含义:类似于map,但独立的在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U]。假设有N个元素,有M个分区,那么map的函数将被调用N次,而mapPartitions被调用M次,一个函数一次处理所有分区
5) mapPartitionsWithIndex(func),含义:类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此,在类型为T的RDD上运行时,func的函数类型必须是(Int,Iterator[T]) => Iterator[U]
6) sample(withReplacement, fraction, seed),含义:以指定的随机种子随机抽样出数量为fraction的数据,withReplacement表示是抽出的数据是否放回,true为有放回的抽样,false为无放回的抽样,seed用于指定随机数生成器种子。例如从RDD中随机且有放回的抽出50%的数据,随机种子值为3(即可能以1 2 3的其中一个起始值)
7) takeSample,含义:和Sample的区别是:takeSample返回的是最终的结果集合
8) union(otherDataset),含义:对源RDD和参数RDD求并集合返回一个新的RDD
9) intersection(otherDataset),含义:对源RDD和参数RDD求交集后返回一个新的RDD
10) distinct([numTasks]),含义:对源RDD进行去重后返回一个新的RDD。默认情况下,只有8个并行任务来操作,但是可以传入一个可选的numTasks参数改变它
11) partitionBy,含义:对RDD进行分区操作,如果原有的partionRDD和现有的partionRDD是一致的话就不进行分区,否则会生成ShuffleRDD
12) reduceByKey(func, [numTasks]),含义:在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,reduce任务的个数可以通过第二个可选的参数来设置
13) groupByKey,含义:groupByKey也是对每个key进行操作,但只生成一个sequence
14) combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
15) aggregateByKey(zeroValue: U, [partitioner: Partitioner])(seqOp: (U, V) => U, combOp: (U, U) => U),
含义:在kv对的RDD中,按key将value进行分组合并,合并时,将每个 value和初始值作为seq函数的参数,进行计算,返回的结果作为一个新的kv对,然后再将结果按照key进行合并,最后将每个分组的value 传递给combine函数进行计算(先将前两个value进行计算,将返回结 果和下一个value传给combine函数,以此类推),将key与计算结果作为一个新的kv对输出。seqOp函数用于在每一个分区中用初始值逐步迭代value,combOp函数用于合并每个分区中的结果
16) foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)],含义:aggregateByKey的简化操作,seqop和combop相同
17) sortByKey([ascending], [numTasks]),含义:在一个(K, V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K, V)的RDD
18) sortBy(func, [ascending], [numTasks]),含义:与sortByKey类似,但是更灵活,可以用func先对数据进行处理,按照处理后的数据比较结果排序
19) join(otherDataset, [numTasks]),含义:在类型为(K, V)和(K, W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K, (V, W))的RDD
20) cogroup(otherDataset, [numTasks]),含义:返回类型为(K, V)和(K, W)的RDD上调用,返回一个(K, (Iterable<V>, Iterable<W>))类型的RDD
21) cartesian(otherDataset),含义:笛卡尔积
22) pipe(command, [envVars]),含义:对于每个分区,都执行一个perl或者shell脚本,返回输出的RDD。注意:shell脚本需要集群中的所有节点都能访问到
23) coalesce(numPartitions),含义:缩减分区数,用于大数据集过滤后,提高小数据集的执行效率
24) repartition(numPartitions),含义:根据分区数,从新通过网络随机洗牌所有数据
25) repartitionAndSortWithinPartitions(partitioner),含义:repartitionAndSortWithinPartitions函数是repartition函数的变种,与repartition函数不同的是,repartitionAndSortWithinPartitions在给定的partitioner内部进行排序,性能比repartition要高
26) glom,含义:将每一个分区形成一个数组,形成新的RDD类型时RDD[Array[T]]
27) mapValues,含义:针对于(K, V)形式的类型只对V进行操作
28) subtract,含义:计算差的一种函数去除两个RDD中相同的元素,不同的RDD将保留下来
2.3.2 Action
常用的Action:
1) reduce(func),含义:通过func函数聚集RDD中的所有元素,这个功能必须是可交换且可并联的
2) collect(),含义:在驱动程序中,以数组的形式返回数据集的所有元素
3) count(),含义:返回RDD的元素个数
4) first(),含义:返回RDD的第一个元素(类似于take(1))
5) take(n),含义:返回一个由数据集的前n个元素组成的数组
6) takeSample(withReplacement, num, [seed]),含义:返回一个数组,该数组由从数据集中随机采样的num个元素组成,可以选择是否用随机数替换不足的部分,seed用于指定随机数生成器种子
7) takeOrdered(n),含义:返回前几个的排序
8) aggregate(zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U),含义:aggregate函数将每个分区里面的元素通过seqOp和初始值进行聚合,然后用combine函数将每个分区的结果和初始值(zeroValue)进行combine操作。这个函数最终返回的类型不需要和RDD中元素类型一致
9) fold(num)(func),含义:折叠操作,aggregate的简化操作,seqop和combop一样
10) saveAsTextFile(path),含义:将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它转换为文件中的文本
11) saveAsSequenceFile(path),含义:将数据集中的元素以Hadoop sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统
12) saveAsObjectFile(path),含义:用于将RDD中的元素序列化成对象,存储到文件中
13) countByKey(),含义:针对(K, V)类型的RDD,返回一个(K, Int)的map,表示每一个key对应的元素个数
14) foreach(func),含义:在数据集的每一个元素上,运行函数func进行更新
2.3.3 数值RDD的统计操作
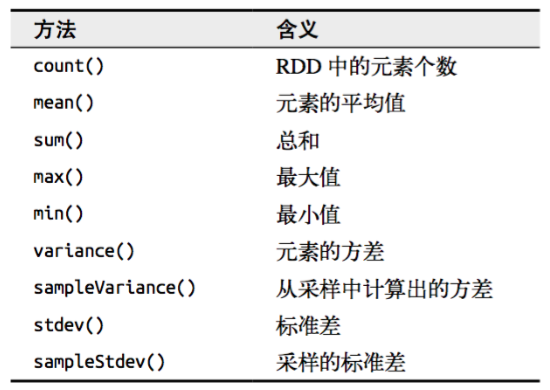
Spark对包含数值数据的RDD提供了一些描述性的统计操作。Spark的数值操作是通过流式算法实现的,允许以每次一个元素的方式构建出模型。这些统计数据都会在调用stats()时通过一次遍历数据计算出来,并以StatsCounter对象返回
2.3.4 向RDD操作传递函数注意
Spark的大部分转化操作和一部分行动操作,都需要依赖用户传递的函数来计算。在Scala中,我们可以把定义的内联函数、方法的引用或静态方法传递给Spark,就像Scala的其他函数式API一样。还要考虑其他一些细节,比如所传递的函数及其引用的数据需要是可序列化的(实现了Java的Serializable接口)。传递一个对象的方法或者字段时,会包含对整个对象的引用
class SearchFunctions(val query: String) extends java.io.Serializable {
def ismatch(s: String): Boolean = {
s.contains(query)
}
def getmatchesFunctionReference(rdd: org.apache.spark.rdd.RDD[String]):
org.apache.spark.rdd.RDD[String] = {
// 问题:"isMatch"表示"this.isMatch",因此我们要传递整个"this"
rdd.filter(ismatch)
}
def getMatchesFieldReference(rdd: org.apache.spark.rdd.RDD[String]):
org.apache.spark.rdd.RDD[String] = {
// 问题:"query"表示"this.query",因此我们要传递整个"this"
rdd.filter(x => x.contains(query))
}
def getMatchesNoReference(rdd: org.apache.spark.rdd.RDD[String]):
org.apache.spark.rdd.RDD[String] = {
// 安全:只把我们需要的字段拿出来放入局部变量中
val query_ = this.query
rdd.filter(x => x.contains(query_))
}
}
如果在Scala中出现了NotSerializableException,通常问题就在于我们传递了一个不可序列化的类中的函数或字段
2.3.5 在不同RDD类型间转换
有些函数只能用于特定类型的RDD,比如mean()和variance()只能用在数值RDD上,而join()只能用在键值对RDD上。在Scala和Java中,这些函数都没有定义在标准的RDD类中,所以要访问这些附加功能,必须要确保获得了正确的专用RDD类
在Scala中,将RDD转为有特定函数的RDD(比如在RDD[Double]上进行数值操作)是由隐式转换来自动处理的

2.4 RDD持久化
2.4.1 RDD的缓存
Spark速度非常快的原因之一,就是在不同操作中可以在内存中持久化或缓存个数据集。当持久化某个RDD后,每一个节点都将把计算的分片结果保存在内存中,并在对此RDD或衍生出的RDD进行的其他动作中重用。这使得后续的动作变得更加迅速。RDD相关的持久化和缓存,是Spark最重要的特征之一。可以说,缓存是Spark构建迭代式算法和快速交互式查询的关键。如果一个有持久化数据的节点发生故障,Spark会在需要用到缓存的数据时重算丢失的数据分区。如果希望节点故障的情况下不会拖累我们的执行速度,也可以把数据备份到多个节点上
2.4.2 RDD缓存方式
RDD通过persist方法或cache方法可以将前面的计算结果缓存,默认情况下persist()会把数据以序列化的形式缓存在JVM的堆空间中。但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面重用

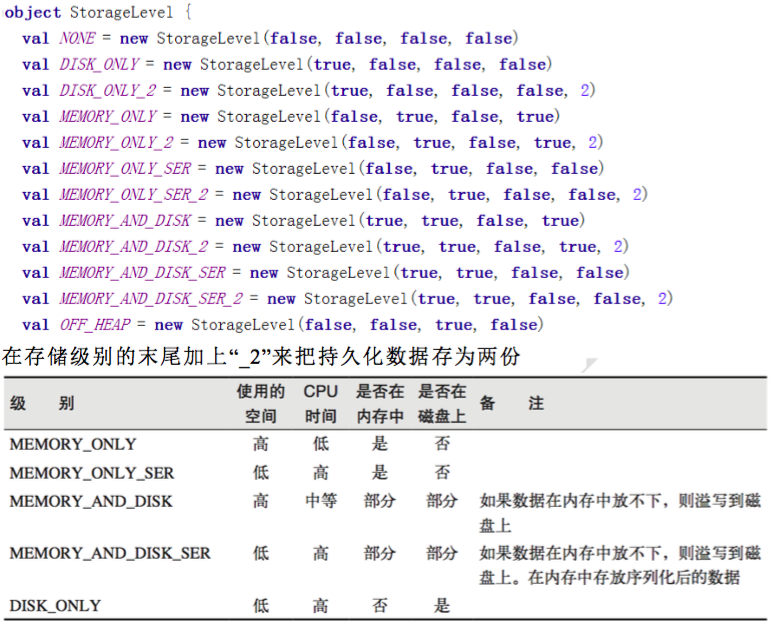
通过查看源码发现cache最终也是调用了persist方法,默认的存储级别都是仅在内存存储一份,Spark的存储级别还有好多种,存储级别在objectStorageLevel中定义的
缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除,RDD的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于RDD的一系列转换,丢失的数据会被重算,由于RDD的各个Partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部的Partition。
注意:使用Tachyon可以实现堆外缓存
2.5 RDD检查点机制
Spark中对于数据的保存除了持久化操作之外,还提供了一种检查点的机制,检查点(本质是通过将RDD写入Disk做检查点)是为了通过lineage做容错的辅助,lineage过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果之后有节点出现问题而丢失分区,从做检查点的RDD开始重做Lineage,就会减少开销。检查点通过将数据写入到HDFS文件系统实现了RDD的检查点功能
cache和checkpoint是有显著区别的,缓存把RDD计算出来然后放在内存中,但是RDD的依赖链(相当于数据库中的redo日志),也不能丢掉,当某个点某个executor宕了,上面cache的RDD就会丢掉,需要通过依赖链重放计算出来,不同的是,checkpoint是把RDD保存在HDFS中,是多副本可靠存储,所以依赖链就可以丢掉了,就斩断了依赖链,是通过复制实现的高容错
如果存在以下场景,则比较适合使用检查点机制:
1) DAG中的Lineage过长,如果重算,则开销太大(如在PageRank中)
2) 在宽依赖上做Checkpoint获得的收益更大
为当前RDD设置检查点。该函数将会创建一个二进制的文件,并存储到checkpoint目录中,该目录是用SparkContext.setCheckpointDir()设置的。在checkpoint的过程中,该RDD的所有依赖于父RDD中的信息将全部被移出。对RDD进行checkpoint操作并不会马上被执行,必须执行Action操作才能触发
2.5.1 checkpoint写流程
RDD checkpoint过程中会经过以下几个状态:
[Initialized -> marked for checkpoint -> checkpointing in progress -> checkpointed ]
转换流程如下:
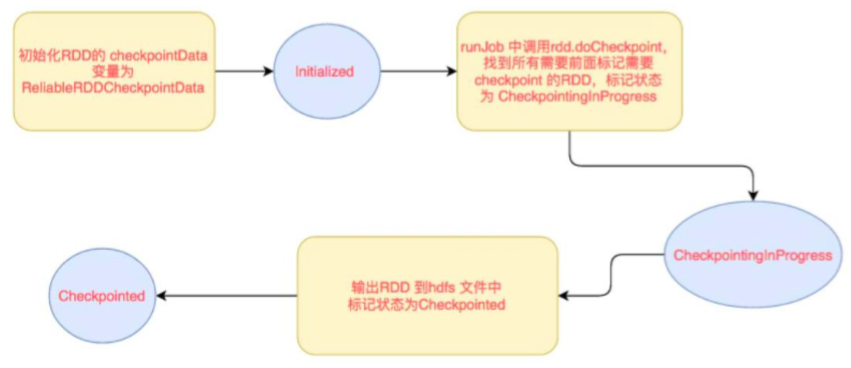
1) data.checkpoint 这个函数调用中,设置的目录中,所有依赖的RDD都会被删除,函数必须在job运行之前调用执行,强烈建议RDD缓存在内存中(又提到一次,千万要注意),否则保存到文件的时候需要从头计算,初始化RDD的checkpointData变量为ReliableRDDCheckpointData。这时候标记为Initialized状态
2) 在所有job action的时候,runJob方法中都会调用rdd.doCheckpoint,这个会向前递归调用所有的依赖的RDD,看看需不需要checkpoint。如果需要checkpoint,然后调用checkpointData.get.checkpoint(),里面标记状态为CheckpointingInProgress,里面调用具体实现类的ReliableRDDCheckpointData的doCheckpoint方法
3) doCheckpoint -> writeRDDToCheckpointDirectory,注意这里会把job再运行一次,如果已经cache了,就可以直接使用缓存中的RDD了,就不需要从头计算一遍了,这时候直接把RDD,输出到hdfs,每个分区一个文件,会先写到一个临时文件,如果全部输出完,进行rename,如果输出失败,就回滚delete
4) 标记状态为Checkpointed,markCheckpointed方法中清除所有的依赖,怎么清除依赖的呢,就是把RDD变量的强引用设置为null,垃圾回收了,会触发ContextCleaner里面监听清除实际BlockManager缓存中的数据
2.5.2 checkpoint读流程
如果一个RDD我们已经checkpoint了那么是什么时候用呢,checkpoint将RDD持久化到HDFS或本地文件夹,如果不被手动remove掉,是一直存在的,也就是说可以被下一个driver program使用。比如spark streaming挂掉了,重启后就可以使用之前checkpoint的数据进行recover,当然在同一个driver program也可以使用。讲下在同一个driver program中是怎么使用checkpoint数据的
如果一个RDD被checkpoint了,如果这个RDD上有action操作的时候,或者回溯的这个RDD的时候,这个RDD进行计算的时候,里面判断如果已经checkpoint过,对分区和依赖的处理都是使用的RDD内部的checkpointRDD变量
具体细节如下,
如果一个RDD被checkpoint了,那么这个RDD中对分区和依赖的处理都是使用的RDD内部的checkpointRDD变量,具体实现是ReliableCheckpointRDD类型。这个是在checkpoint写流程中创建的。依赖和获取分区方法中先判断是否已经checkpoint,如果已经checkpoint,就斩断依赖,使用ReliableCheckpointRDD,来处理依赖和获取分区
如果没有,才往前回溯依赖。依赖就是没有依赖,因为已经斩断了依赖,获取分区数据就是读取checkpoint到hdfs目录中不同分区保存下来的文件
2.6 RDD的依赖关系
RDD和它依赖的父RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)
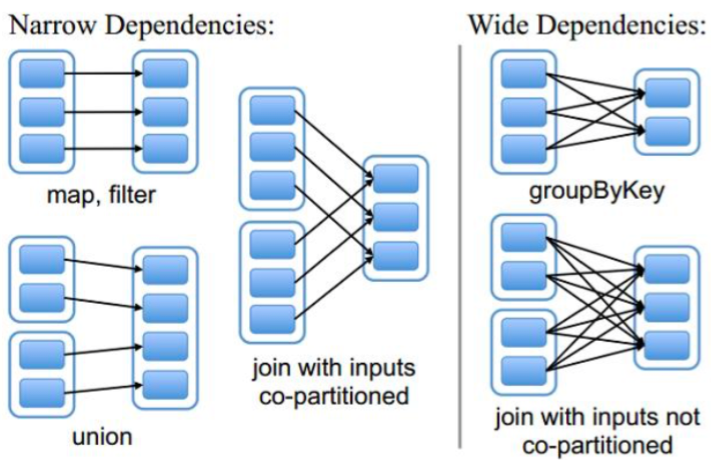
2.6.1 窄依赖
窄依赖指的是每一个父RDD的Partition最多被子RDD的一个Partition使用
总结:窄依赖我们形象的比喻为独生子女
2.6.2 宽依赖
宽依赖指的是多个子RDD的Partition会依赖同一个父RDD的Partition,会引起shuffe
总结:宽依赖我们形象的比喻为超生
2.6.3 Lineage
RDD只支持粗粒度转换,即在大量纪录上执行的单个操作,将创建RDD的一系列Lineage(即血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区
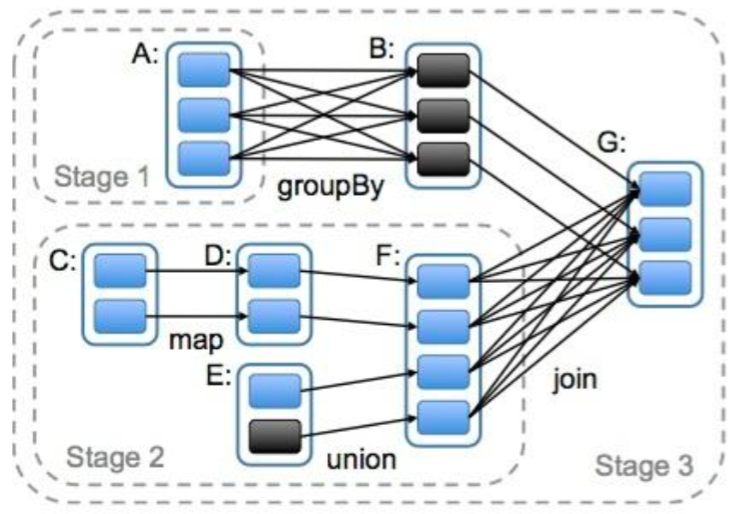
2.7 DAG的生成
DAG(Directed Acyclic Graph)叫做有向无环图,原始的RDD通过一系列的转换就形成了DAG,根据RDD之间的依赖关系的不同将DAG划分成不同的Stage,对于窄依赖,partition的转换处理在Stage中完成计算。对于宽依赖,由于有shuffe的存在,只能在parent RDD处理完成后,才能开始接下来的计算,因此宽依赖是划分Stage的依据
2.8 RDD相关概念关系
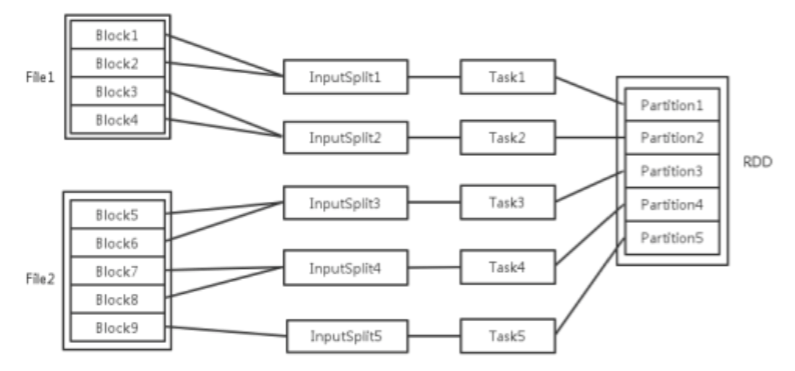
输入可能以多个文件的形式存储在HDFS上,每个File都包含了很多块,称为Block
当Spark读取这些文件作为输入时,会根据具体数据格式对应的InputFormat进行解析,一般是将若干个Block合并成一个输入分片,称为InputSplit,注意InputSplit不能跨文件。随后将为这些输入分片生成具体的Task。inputSplit与Task是一一对应关系
随后这些具体的Task每个都会被分配到集群上的某个节点的某个Executor去执行
1) 每个节点可以起一个或多个Executor
2) 每个Executor由若干core组成,每个Executor的每个core一次只能执行一个Task
3) 每个Task执行的结果就是生成了目标RDD的一个partition
注意:这里的core是虚拟的core而不是机器的物理CPU核,可以理解为就是Executor的一个工作线程
而Task被执行的并发度 = Executor数目 * 每个Executor核数
至于partition的数目:
1) 对于数据读入阶段,例如sc.textFile,输入文件被划分为多少InputSplit就会需要多少初始Task
2) 在Map阶段partition数目保持不变
3) 在Reduce阶段,RDD的聚合会触发shuffe操作,聚合后的RDD的partition数目跟具体操作有关,例如repartition操作会聚合成指定分区数,还有一些算子是可配置的
RDD在计算的时候,每个分区都会起一个task,所以rdd的分区数目决定了总的task数目
申请的计算节点(Executor)数目和每个计算节点核数,决定了你同一时刻并行执行的task
比如的RDD有100个分区,那么计算的时候就会生成100个task,你的资源配置为10个计算节点,每个2个核,同一时刻可以并行的task数目为20,计算这个RDD就需要5次轮次
如果计算资源不变,你有101个task的话,就需要6个轮次,在最后一轮中,只有一个task在执行,其余核都在空转
如果资源不变,你的RDD只有两个分区,那么同一时刻只有2个task运行,其余18个核空转,造成资源浪费。这就是在spark调优中,增大RDD分区数目,增大RDD分区数目,增大任务并行度的做法
2. RDD编程的更多相关文章
- Spark菜鸟学习营Day3 RDD编程进阶
Spark菜鸟学习营Day3 RDD编程进阶 RDD代码简化 对于昨天练习的代码,我们可以从几个方面来简化: 使用fluent风格写法,可以减少对于中间变量的定义. 使用lambda表示式来替换对象写 ...
- Spark菜鸟学习营Day1 从Java到RDD编程
Spark菜鸟学习营Day1 从Java到RDD编程 菜鸟训练营主要的目标是帮助大家从零开始,初步掌握Spark程序的开发. Spark的编程模型是一步一步发展过来的,今天主要带大家走一下这段路,让我 ...
- Spark学习笔记2:RDD编程
通过一个简单的单词计数的例子来开始介绍RDD编程. import org.apache.spark.{SparkConf, SparkContext} object word { def main(a ...
- Spark编程模型(RDD编程模型)
Spark编程模型(RDD编程模型) 下图给出了rdd 编程模型,并将下例中用 到的四个算子映射到四种算子类型.spark 程序工作在两个空间中:spark rdd空间和 scala原生数据空间.在原 ...
- 02、体验Spark shell下RDD编程
02.体验Spark shell下RDD编程 1.Spark RDD介绍 RDD是Resilient Distributed Dataset,中文翻译是弹性分布式数据集.该类是Spark是核心类成员之 ...
- Spark学习之RDD编程(2)
Spark学习之RDD编程(2) 1. Spark中的RDD是一个不可变的分布式对象集合. 2. 在Spark中数据的操作不外乎创建RDD.转化已有的RDD以及调用RDD操作进行求值. 3. 创建RD ...
- 5.1 RDD编程
一.RDD编程基础 1.创建 spark采用textFile()方法来从文件系统中加载数据创建RDD,该方法把文件的URL作为参数,这个URL可以是: 本地文件系统的地址 分布式文件系统HDFS的地址 ...
- spark实验(四)--RDD编程(1)
一.实验目的 (1)熟悉 Spark 的 RDD 基本操作及键值对操作: (2)熟悉使用 RDD 编程解决实际具体问题的方法. 二.实验平台 操作系统:centos6.4 Spark 版本:1.5.0 ...
- 第2章 RDD编程(2.3)
第2章 RDD编程(2.3) 2.3 TransFormation 基本RDD Pair类型RDD (伪集合操作 交.并.补.笛卡尔积都支持) 2.3.1 map(func) 返回一个新的RDD,该 ...
随机推荐
- mybatis-generator 插件
首先肯定要有mybatis的依赖 <!--mybatis spring--> <dependency> <groupId>org.mybatis.spring.bo ...
- 数组(定义、遍历、冒泡排序、合并和Join 方法)
一.数组的定义 1.理解:数组指一组数据,有序的数据,可以一次性存储多个数据,将多个元素(通常统一类型)按照一定的顺序排列放到一个集合里 2.通过构造函数创建数组: var 数组名=new Arrar ...
- python基础代码
from heapq import *; from collections import *; import random as rd; import operator as op; import r ...
- ls列出排除的文件
今天有个需求,将从日志文件夹中列出它排除旧备份日志的文件. ls -lhrt --ignore="*.gz" --ignore="*.zip"
- idea搭建简单ssm框架的最详细教程(新)
为开发一个测试程序,特搭建一个简单的ssm框架,因为网上看到很多都是比较老旧的教程,很多包都不能用了,eclipes搭建并且其中还附带了很多的其他东西,所以特此记录一下mac中idea搭建过程. 另: ...
- CEF 远程调试
转载:https://www.cnblogs.com/TianFang/p/9906786.html 转载:https://stackoverflow.com/questions/29117882/d ...
- 腾讯云短信 nodejs 接入, 通过验证码修改手机示例
腾讯云短信 nodejs 接入, 通过验证码修改手机示例 参考:腾讯云短信文档国内短信快速入门qcloudsms Node.js SDK文档中心>短信>错误码 nodejs sdk 使用示 ...
- Mysql关键字之Group By(一)
原文地址,优先更新https://hhe0.github.io group by 是一个我们在日常工作学习过程中经常遇到的一个Mysql关键字.现总结其用法如下,内容会不断补充,出现错误欢迎批评指正. ...
- [LeetCode] 251. Flatten 2D Vector 压平二维向量
Implement an iterator to flatten a 2d vector. For example,Given 2d vector = [ [1,2], [3], [4,5,6] ] ...
- [LeetCode] 380. Insert Delete GetRandom O(1) 插入删除获得随机数O(1)时间
Design a data structure that supports all following operations in average O(1) time. insert(val): In ...