机器学习---逻辑回归(二)(Machine Learning Logistic Regression II)
在《机器学习---逻辑回归(一)(Machine Learning Logistic Regression I)》一文中,我们讨论了如何用逻辑回归解决二分类问题以及逻辑回归算法的本质。现在来看一下多分类的情况。
现实中相对于二分类问题,我们更常遇到的是多分类问题。多分类问题如何求解呢?有两种方式。一种是方式是修改原有模型,另一种方式是将多分类问题拆分成一个个二分类问题解决。
先来看一下第一种方式:修改原有模型。即:把二分类逻辑回归模型变为多分类逻辑回归模型。
(二分类逻辑回归称为binary logistic regression,其目标y只有两种可能的类别,符合伯努利分布;而多分类逻辑回归称为multinomial logistic regression,其目标y有超过两种可能的类别,符合多项分布。)
在原有的二分类逻辑回归模型中,目标y只有两种类别。并且如果样本 P(y=1 | x) > P(y=0 | x),就表示样本属于 y=1这一类别的概率更高。现在我们要把目标y扩展为K种类别(K=0,1,2,...,k-1),我们想要知道给定特征x,其目标属于每一种类别的概率分别是多少,这样我们就能判断样本最有可能属于哪个类别。并且这些概率相加总和应该为1,即: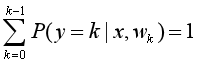 。那么我们就应该从这些目标类别中找一个类别作为baseline,然后计算其他类别相对于这个baseline的对数几率。
。那么我们就应该从这些目标类别中找一个类别作为baseline,然后计算其他类别相对于这个baseline的对数几率。
我们把类别0作为baseline,定为负类,其余K-1类中的一类分别定为正类。那么一共可以进行k-1次二分类逻辑回归,按照其公式,将对数几率写成线性组合的形式:
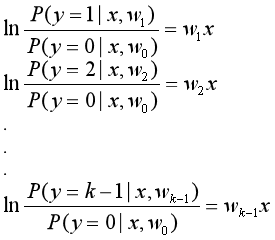 .................(1)
.................(1)
从式子(1)我们可以得知:
 .................(2)
.................(2)
因为给定特征x,其目标属于每一种类别的概率相加总和为1,因此:
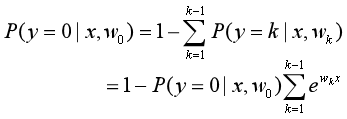
然后可以得到:
 .................(3)
.................(3)
将式子(3)代入式子(2):
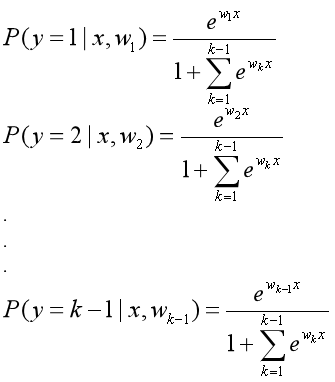 .................(4)
.................(4)
可以看出,当K=2时,上式变为逻辑函数的形式:
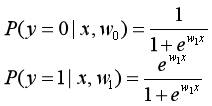
因此,二分类逻辑回归是多分类逻辑回归的特例,多分类逻辑回归是二分类逻辑回归的扩展。
又因为当K=2时, ,因此可以得出:
,因此可以得出: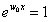 。
。
将这一结果代入式子(4),转换整合可以得到:
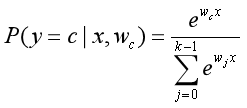 (其中c表示当前类别,k表示总类别数,即:类别一共K类,从0到k-1)
(其中c表示当前类别,k表示总类别数,即:类别一共K类,从0到k-1)
此条件概率公式对应的函数称为softmax函数(softmax function)。因此,其对应的模型也被称为softmax回归模型。
softmax函数:

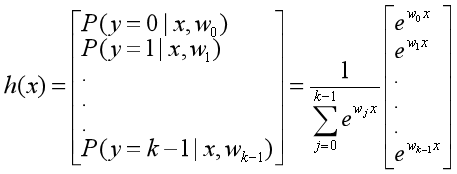
总结来说就是:多分类逻辑回归模型有多个输出,输出的个数与类别个数相同,输出的值为目标属于各个类别的概率,概率最高的那个类别就是目标最有可能的类别。
因为目标y是多个分类标签,因此我们假设y服从多项分布,那么目标y的概率质量函数就是: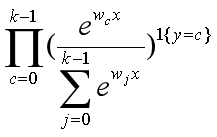 ,将其写成条件概率表达式就是:
,将其写成条件概率表达式就是: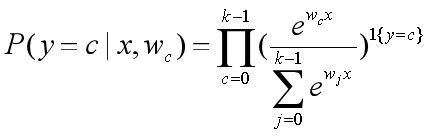 。
。
(注:1{y=c}表示当y属于类别c时,值为1,否则为0)
假设有m个独立样本,那么m个y之间也是相互独立的。因此,目标y的联合概率为: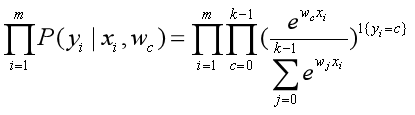 。
。
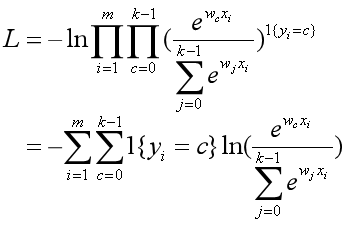
 。是不是很相似?只不过多分类逻辑回归是用的所有k项的累和,而二分类逻辑回归只有0和1类的累和。
。是不是很相似?只不过多分类逻辑回归是用的所有k项的累和,而二分类逻辑回归只有0和1类的累和。
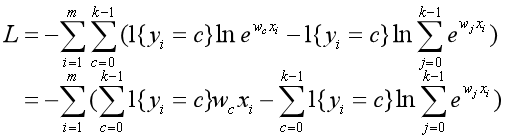
现在损失函数看起来还是很复杂,但是其实只有yi=c这一项有数值(也就是样本目标是正确类别的情况),其余项都为0。因此,我们可以继续简化损失函数。
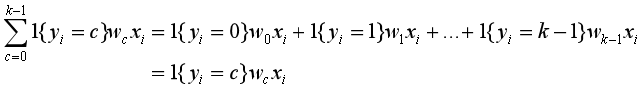
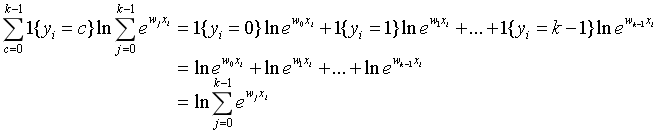
简化后的损失函数为:
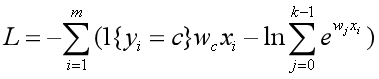
现在用wt对损失函数L求偏导(wt是w0~wk-1中的一个,是(n+1)*1的向量)。这里分为两种情况:
1. t=c:
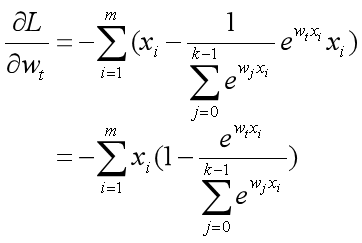
2. t≠c:
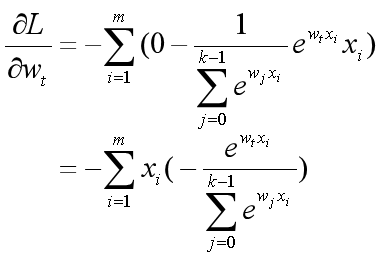
两种情况综合在一起,损失函数L的梯度就是:
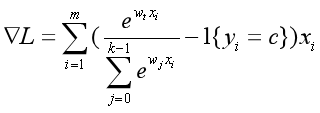 for t = 0, 1,…, k-1.
for t = 0, 1,…, k-1.
为简便起见,把参数w记成(n+1)*k的矩阵,把yi记成1*k的向量:
 (其中n表示特征数量,k表示类别数量)
(其中n表示特征数量,k表示类别数量)
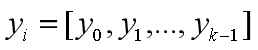
这样梯度可以写成:
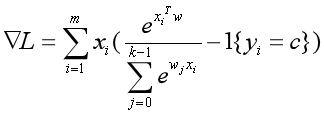
批量梯度下降法的参数更新公式为:
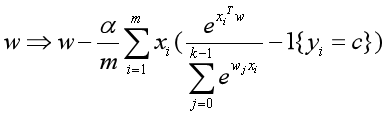
现在让我们来思考几个问题:
1. softmax函数是怎么得来的?(摘自:https://blog.csdn.net/acdreamers/article/details/44663305)
因为目标y是多个分类标签,因此我们假设y服从多项分布,那么目标y的概率质量函数就是:,将其写成条件概率表达式就是:。
k个类别的概率用k个变量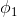 ,
,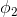 …,
…,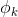 表示。这个k变量和为1,即满足:
表示。这个k变量和为1,即满足: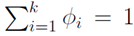 。
。
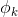 可以用前k-1个变量来表示,即:
可以用前k-1个变量来表示,即: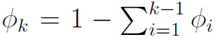 。
。
和sigmoid函数一样,softmax函数也是从证明目标的联合分布属于指数分布族而得来的。
先引入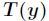 ,它是一个
,它是一个 维的向量,那么:
维的向量,那么:
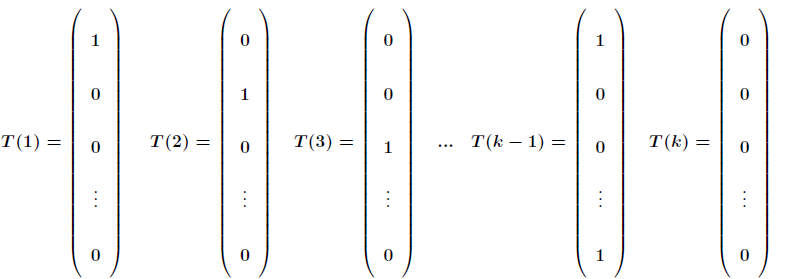
应用于一般线性模型, 必然是属于
必然是属于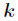 个类中的一种。用
个类中的一种。用 表示
表示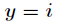 为真,同样当
为真,同样当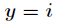 为假时,有
为假时,有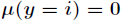 ,那么进一步得到y的联合概率为:
,那么进一步得到y的联合概率为:

对比指数分布族的一般表达式,可以得到:

既然: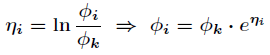
那么最终可以得到:

2. 为什么softmax函数上的点可以用来表示分类概率?
因为wx的值域从负无穷大到正无穷大,我们要想让softmax函数表示概率,那么就需要把wx的值域先变成正数,再归一化到(0,1)区间。指数函数正好能把wx的值域变成正数,且指数函数是严格递增的。把wx映射到指数函数上后,再把其除以它们的累和,就相当于将每个分类概率进行了归一化,使得所有分类概率之和为 1。
softmax函数的本质就是将一个K维的任意实数向量压缩(映射)成另一个K维的实数向量,使得向量中的每个元素取值都介于(0,1)之间,并且所有元素的和为1。
再来看一下第二种方式:将多分类问题拆分成二分类问题。即:将多分类问题拆分成一个个二分类问题,然后为每个拆出的二分类任务训练出一个二分类逻辑回归模型,然后对这些模型的预测结果进行集成以获得最终的多分类结果。这里面的关键是如何对问题进行拆分,即拆分的策略。
下面是三种拆分策略:
1. 一对其余(One vs. Rest,简称OvR)
每次将一个类别作为正类,其余所有类作为反类,训练出N个二分类逻辑回归模型。新样本提交给所有二分类逻辑回归模型,若仅有一个模型预测为正类,则该类的类别为最终结果。若有多个分类器标记为正类,则考虑预置置信度。
2. 一对一(One vs. One,简称OvO)
每次将N个类别两两配对,其中一个类别作为正类,另一个作为反类,训练出N(N-1)/2个二分类逻辑回归模型。新样本同时提交给所有二分类逻辑回归模型,得到N(N-1)/2个分类结果,预测最多的类别为最终结果。
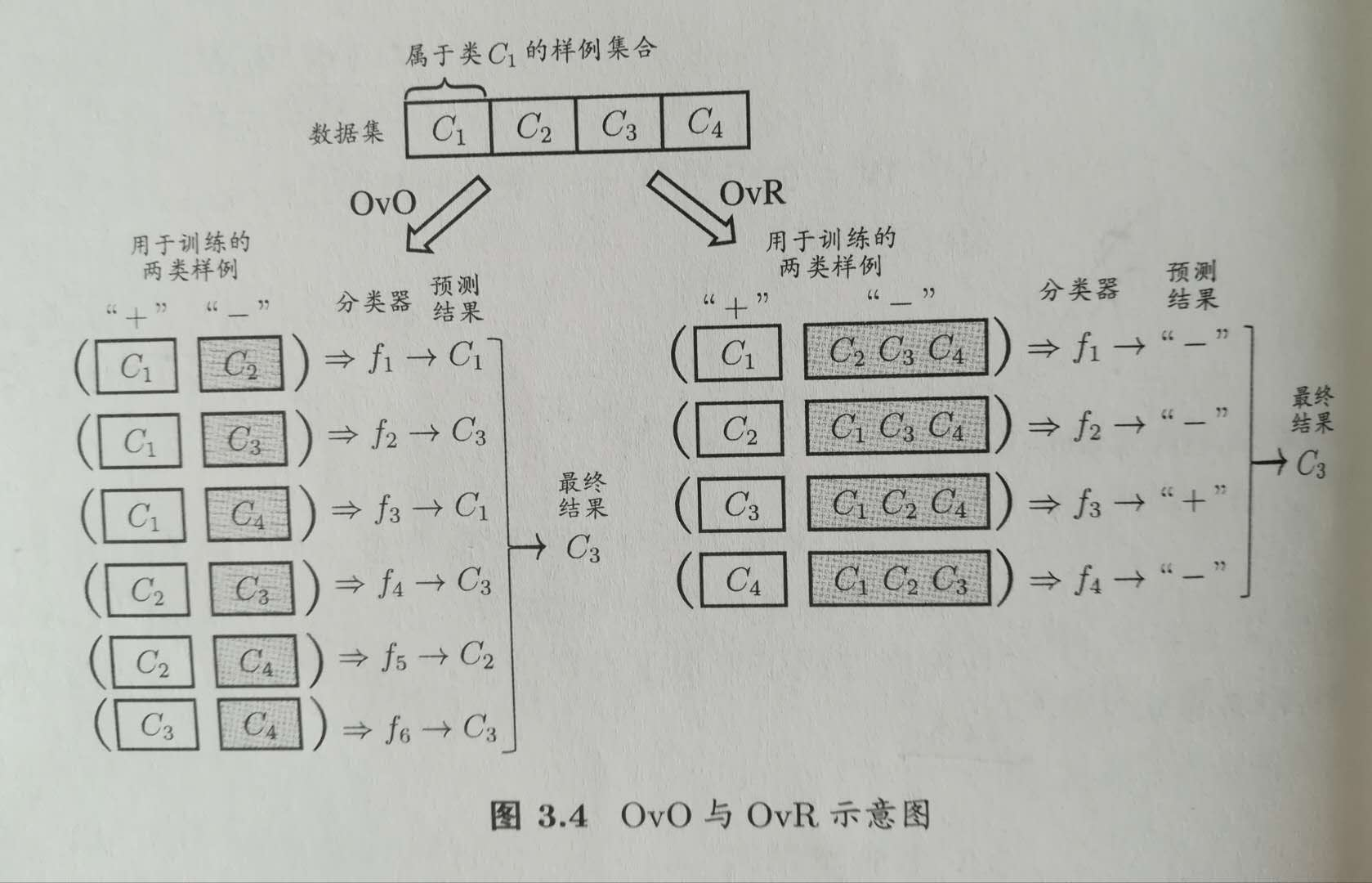
3. 多对多(Many vs. Many,简称MvM)
每次将若干个类别作为正类,其他作为反类。MvM的正、反类构造必须有特殊的设计,不能随意选取,最常用的技术是“纠错输出码“Error Correcting Output Codes(ECOC)。(ECOC编码对分类器错误有一定的容忍修正能力,即使某个分类器预测出错,也不一定会影响结果)
ECOC:
编码:将N个类别做M次划分,每次将一部分作为正例,其余作为反例,训练出M个二分类模型。
解码:新样本提交给M个二分类模型,得到M个结果,组成一个编码,将其和每个类别各自的编码进行比较,距离最小的类别为最终结果。
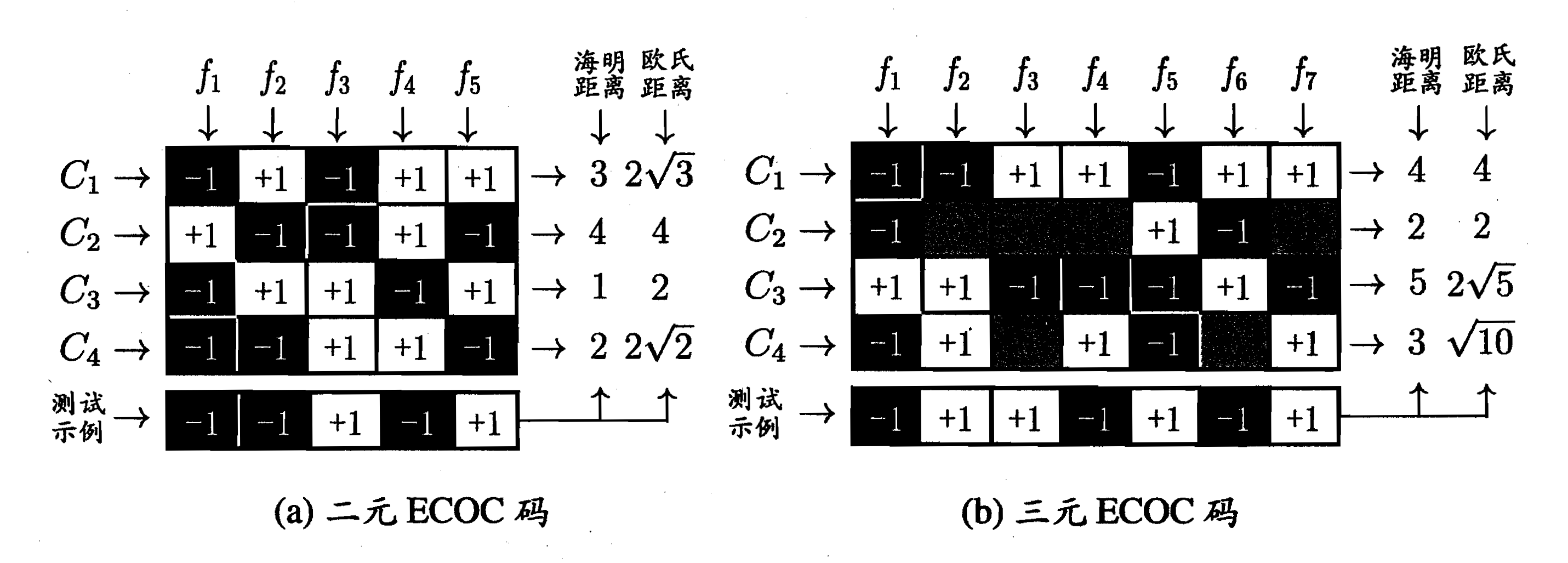
OvR和OvO这两种拆分策略比较简单且使用较多,因此下面详细介绍一下这两种拆分策略。
1. OvR:
如下图所示,假如目标一共有4个类别。每次将某一类分为正类,其余三类分为负类,进行二分类任务,新样本提交给模型,得到新样本分别属于正负两类的概率值。像这样一共进行4次二分类任务,最后得到新样本分别属于这四类的概率,最大概率对应哪一类,就将这点估计为哪一类。
OvR有个问题就是如果数据类别很多,那么每次二分类问题中,正类和负类的数量差别就很大,数据不平衡,这样会影响分类效果。
2. OvO:
如下图所示,假如目标一共有4个类别。每次将某一类分为正类,另一类分为负类,进行二分类任务,新样本提交给模型,估计出新样本属于正类还是负类。像这样一共进行 次二分类任务,最后投票决定新样本属于哪个类别(投票数最多的类别)。
次二分类任务,最后投票决定新样本属于哪个类别(投票数最多的类别)。
OvO的优点是虽然需要进行的分类任务增多了,但是每次只需要进行两个类别的比较,也就是说单次分类的数量减少了,因此一般不会出现数据不平衡的情况。缺点是分类任务增多,且每次需要记住分类结果,时间复杂度和空间复杂度都比较高。
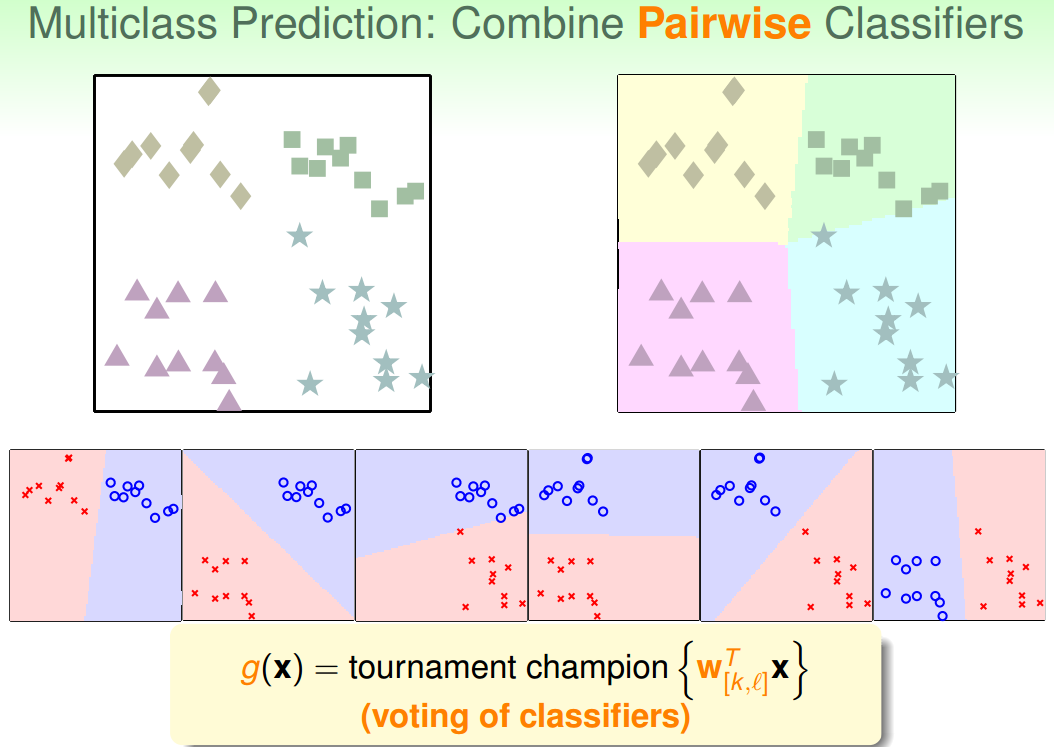
OvR和OvO对比总结:
OvR只需训练N个分类器,而OvO需训练N(N - 1)/2个分类器, 因此,OvO的存储开销和测试时间开销通常比OvR更大。但在训练时,OvR的每个分类器均使用全部训练样本,而OvO的每个分类器仅用到两个类别的样本,因此,在类别很多时,OvO的训练时间通常比OvR小。至于预测性能,则取决于具体的数据分布,在多数情形下两者差不多。
综上:
- OvR的优点是,分类器个数少,存储开销和测试时间比OvO少。缺点是,类别很多时,训练时间长,且有数据不平衡带来的影响。
- OvO的优点是,在类别很多时,训练时间要比OvR少。缺点是,分类器个数多。
方式一(softmax)和方式二(多个logistic回归)有什么区别呢?
- softmax回归进行的是单个多分类任务,类与类之间是互斥的,即一个输入只能被归为一类
- 多个logistic回归进行的是多个二分类任务,类与类之间并不是互斥的
总结:如果类别之间是互斥的,那么用softmax回归会比较合适;如果类别之间不是互斥的(可以同时属于不同类别,比如"苹果"可以既属于"水果"类也属于"3C"类),同时类别较少时,用OVR比较合适;如果类别较多,或者你需要看任意两类之间的区分,那么就用OVO。
机器学习---逻辑回归(二)(Machine Learning Logistic Regression II)的更多相关文章
- matlab-逻辑回归二分类(Logistic Regression)
逻辑回归二分类 今天尝试写了一下逻辑回归分类,把代码分享给大家,至于原理的的话请戳这里 https://blog.csdn.net/laobai1015/article/details/7811321 ...
- 机器学习---逻辑回归(一)(Machine Learning Logistic Regression I)
逻辑回归(Logistic Regression)是一种经典的线性分类算法.逻辑回归虽然叫回归,但是其模型是用来分类的. 让我们先从最简单的二分类问题开始.给定特征向量x=([x1,x2,...,xn ...
- [Machine learning] Logistic regression
1. Variable definitions m : training examples' count \(X\) : design matrix. each row of \(X\) is a t ...
- 逻辑回归的分布式实现 [Logistic Regression / Machine Learning / Spark ]
1- 问题提出 2- 逻辑回归 3- 理论推导 4- Python/Spark实现 # -*- coding: utf-8 -*- from pyspark import SparkContext f ...
- 机器学习系统设计(Building Machine Learning Systems with Python)- Willi Richert Luis Pedro Coelho
机器学习系统设计(Building Machine Learning Systems with Python)- Willi Richert Luis Pedro Coelho 总述 本书是 2014 ...
- 逻辑回归与神经网络还有Softmax regression的关系与区别
本文讨论的关键词:Logistic Regression(逻辑回归).Neural Networks(神经网络) 之前在学习LR和NN的时候,一直对它们独立学习思考,就简单当做是机器学习中的两个不同的 ...
- Machine Learning—Linear Regression
Evernote的同步分享:Machine Learning-Linear Regression 版权声明:本文博客原创文章.博客,未经同意,不得转载.
- 机器学习---三种线性算法的比较(线性回归,感知机,逻辑回归)(Machine Learning Linear Regression Perceptron Logistic Regression Comparison)
最小二乘线性回归,感知机,逻辑回归的比较: 最小二乘线性回归 Least Squares Linear Regression 感知机 Perceptron 二分类逻辑回归 Binary Logis ...
- 机器学习/逻辑回归(logistic regression)/--附python代码
个人分类: 机器学习 本文为吴恩达<机器学习>课程的读书笔记,并用python实现. 前一篇讲了线性回归,这一篇讲逻辑回归,有了上一篇的基础,这一篇的内容会显得比较简单. 逻辑回归(log ...
随机推荐
- 一文读懂内网、公网和NAT
我们做弱电监控系统的时候,都避免不了要跟IP地址打交道,比如摄像头.NVR.服务器等这些设备安装好之后,就需要给它们配上IP,那这个IP地址你了解嘛?今天我们就一起来聊聊什么是内网.公网和NAT地址转 ...
- springmvc 注解二
@SessionAttributes @sessionattributes注解应用到Controller上面,可以将Model中的属性同步到session作用域当中. SessionAttribute ...
- 【开发工具】- Myeclipse10.7破解方法
1.下载myeclipse 10,如果没有,可以使用链接:https://pan.baidu.com/s/1l9juqD4ALMuepVL6e5kgjA 密码:kpx6:当然时间久了可能链接失效,如有 ...
- jQuery实现图片上传
$('input[type="file"]').change(function(event) { var currentTarget = event.currentTarget; ...
- mysql的yearweek 和 weekofyear函数
1.MySQL 的 YEARWEEK 是获取年份和周数的一个函数,函数形式为 YEARWEEK(date[,mode]) 例如 2010-3-14 ,礼拜天 SELECT YEARWEEK('2010 ...
- Windows VNC远程连接用法
VNC (Virtual Network Console)是虚拟网络控制台 被控端 被控端需要打开服务,等待主控端连接 服务端已经启动成功,右下角有小图标 主控端 打开主控端,连接被控端 输入被控端i ...
- 三星手机使用应用沙盒一键修改路由mac数据
之前文章介绍了怎么在安卓手机上安装激活xposed框架,xposed框架的极强的功能大家都知道,能够不修改apk的前提下,修改系统底层的参数,打比方在某些应用情景,大家需要修改手机的某个系统参数,这情 ...
- iOS完整学习路线
来源:http://www.cnblogs.com/mjios/p/3226954.html
- Alpha_4
一. 站立式会议照片 二. 工作进展 (1) 昨天已完成的工作 a. 我的·主界面设计 b. 番茄钟的页面及音乐选择弹窗页面设计 c. 实现自定义习惯和设置新习惯的功能页面,并可预览 d.已实现番茄钟 ...
- springboot注解@NotNull,@NotBlank,@Valid自动判定空值
一.前言 搭建springboot项目,我们都是采用的Restful接口,那么问题来了,当前端调用接口或者是其他项目调用时,我们不能单一靠调用方来控制参数的准确性,自己也要对一些非空的值进行判定. 二 ...