Python之(scikit-learn)机器学习
一、机器学习(Machine Learning, ML)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
简而言之,机器学习就是通过一系列变种的数据公式,通过大量的数据推导,得出的接近于满足数据点的一个公式(f(x) = w1x1 + w2x2^2 + w3x3^3 + ...),然后需要推测的新数据,通过该公式来得出预测的结果。
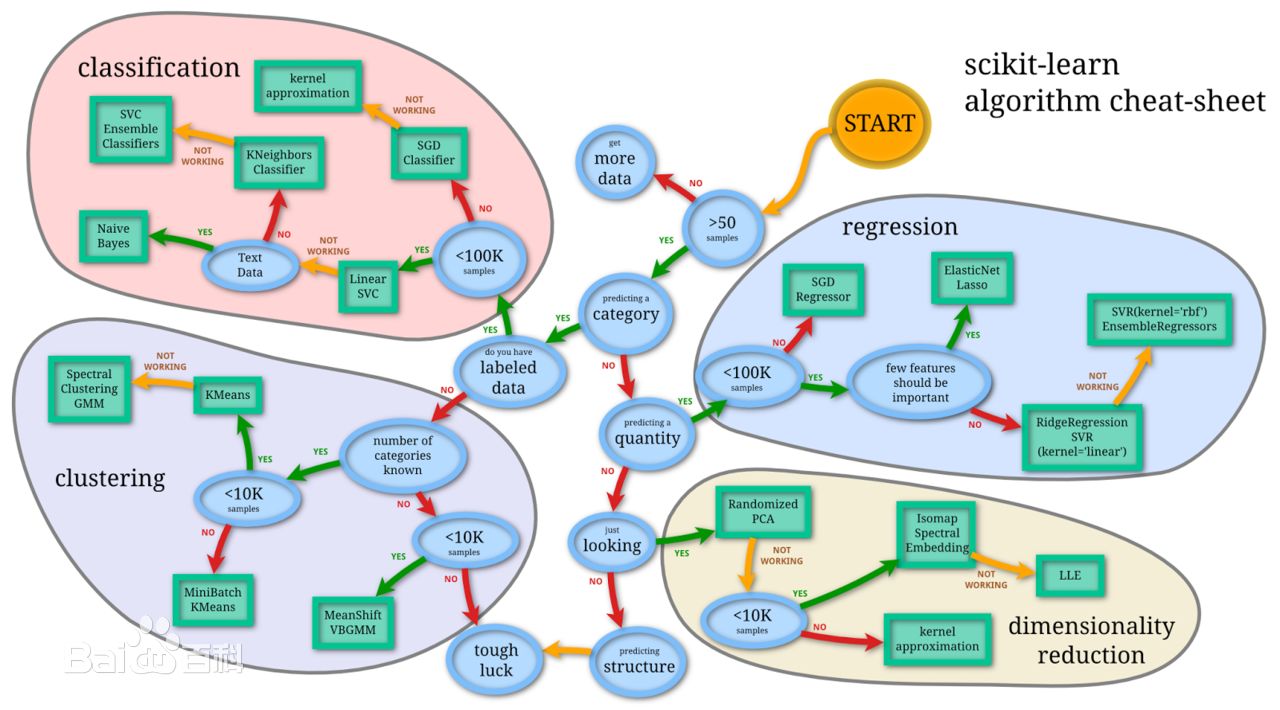
记住上面这个图,他是后续选择算法的规则,也是核心。
二、scikit-learn(简记sklearn),是用python实现的机器学习算法库。sklearn可以实现数据预处理、分类、回归、降维、模型选择等常用的机器学习算法。sklearn是基于NumPy,matplotlib,而形成的。SciPy
scikit-learn的强大主要是它提供了很多算法库,以及数据处理的方式,学习scikit-learn很大程度上可以了解机器学习的实现、训练、预测过程。
三、在开始scikit-learn之前,我们先了解机器学习的流程:
1、原始数据:原始数据可以是很多种形式(比如:图片,json,文本,table等),这些数据可以通过pandas来加载成一个二维数组的数据。也可以通过numpy的方式生成数据。
数据来源一般通过kaggle官方获取,地址:https://www.kaggle.com/
2、数据处理:得到原始数据过后,我们需要对数据进行处理(比如:数据分割(训练集、测试集),构造特征(比如:时间(年份一样,月份、天构造新的特征)),删除特征(没有用的,但是存在影响的特征)等)
3、特征工程:在数据进行处理过后,我们不能盲目的使用该数据(比如:文本数据,数值差异过大的数据),这个时候就要转换数据(转换器)。转换器:字典特征、文本特征、tf_idf(数据出现频次)、归一化、标准化、降维等,然后得出提取特征后的矩阵数据。
4、算法模型:(核心)主要分为监督学习和无监督学习。机器学习的核心就是算法模型。
监督学习:有特征值,目标值(有标准答案)。常有算法为分类算法(离散型(具体的分类标准))、回归算法(连续型(预测值))
无监督学习:只有特征值。常有算法为聚类。
模型:数据在训练集和测试集上面,反复的训练过后,会得出最接近满足所有数据点的公式也称为模型,这个也是后续用于其他业务数据用于分类或者预测的基础。
5、算法评估:分类模型:一般是通过准确率、精准率、召回率、混淆矩阵、AUC来确认模型的准确度,回归模型:一般是通过均方误差的方式来确认准确度。
四、通过第三点的大致介绍,基本可以了解机器学习需要掌握的知识量还是不小的。特别是很多概念,需要自己去理解。下面主要是讲具体的过程和部分原理。(注意:算法是核心会放到最后讲)
五、源码:https://github.com/lilin409546297/scikit_learn_demo
六、数据下载地址:
k_near/train.csv:https://www.kaggle.com/c/facebook-v-predicting-check-ins/data
decision_tree/titanic.csv:http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt
market/orders.csv、order_products__prior.csv、products.csv、market/aisles.csv:https://www.kaggle.com/psparks/instacart-market-basket-analysis
classify_regression/breast-cancer-wisconsin.data:https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/
Python之(scikit-learn)机器学习的更多相关文章
- Scikit Learn: 在python中机器学习
转自:http://my.oschina.net/u/175377/blog/84420#OSC_h2_23 Scikit Learn: 在python中机器学习 Warning 警告:有些没能理解的 ...
- scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类 (python代码)
scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类数据集 fetch_20newsgroups #-*- coding: UTF-8 -*- import ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
- Scikit Learn
Scikit Learn Scikit-Learn简称sklearn,基于 Python 语言的,简单高效的数据挖掘和数据分析工具,建立在 NumPy,SciPy 和 matplotlib 上.
- 小姐姐带你一起学:如何用Python实现7种机器学习算法(附代码)
小姐姐带你一起学:如何用Python实现7种机器学习算法(附代码) Python 被称为是最接近 AI 的语言.最近一位名叫Anna-Lena Popkes的小姐姐在GitHub上分享了自己如何使用P ...
- 搭建基于python +opencv+Beautifulsoup+Neurolab机器学习平台
搭建基于python +opencv+Beautifulsoup+Neurolab机器学习平台 By 子敬叔叔 最近在学习麦好的<机器学习实践指南案例应用解析第二版>,在安装学习环境的时候 ...
- Python数据预处理:机器学习、人工智能通用技术(1)
Python数据预处理:机器学习.人工智能通用技术 白宁超 2018年12月24日17:28:26 摘要:大数据技术与我们日常生活越来越紧密,要做大数据,首要解决数据问题.原始数据存在大量不完整.不 ...
- 探索 Python、机器学习和 NLTK 库 开发一个应用程序,使用 Python、NLTK 和机器学习对 RSS 提要进行分类
挑战:使用机器学习对 RSS 提要进行分类 最近,我接到一项任务,要求为客户创建一个 RSS 提要分类子系统.目标是读取几十个甚至几百个 RSS 提要,将它们的许多文章自动分类到几十个预定义的主题领域 ...
- 使用 Python 开始你的机器学习之旅【转】
转自:https://linux.cn/article-8582-1.html 编译自:https://opensource.com/article/17/5/python-machine-learn ...
随机推荐
- phpstorm yii2框架的redis和mongodb提示
随便找个目录创建一个 yii_helper.php 文件,内容如下: /** * Class Yii */ class Yii { /** * @var MyApplication */ public ...
- layuiadmin(iframe)常用问题集锦
1. 弹出窗口中传值给父层表单 table.on('tool(tableList)', function(obj){ var selected = obj.data; var layEvent = o ...
- netty5自定义私有协议实例
一般业务需求都会自行定义私有协议来满足自己的业务场景,私有协议也可以解决粘包和拆包问题,比如客户端发送数据时携带数据包长度,服务端接收数据后解析消息体,获取数据包长度值,据此继续获取数据包内容.我们来 ...
- declaration of 'int ret' shadows a parameter
定义的变量名称重复, 例如: int look_up_max(int m, int n) { int m; //... return m; }
- Python记录-python执行shell命令
# coding=UTF-8 import os def distcp(): nncheck = os.system('lsof -i:8020') dncheck = os.system('lsof ...
- Spring Cloud 如何使用Eureka注册服务 4.2.2
要使用Eureka实现服务发现,需要项目中包含Eureka的服务端发现组件以及客户端发现组件. 搭建Maven父工程 创建一个Maven父工程xcservice-springcloud,并在工程的po ...
- pca数学原理(转)
PCA的数学原理 前言 数据的向量表示及降维问题 向量的表示及基变换 内积与投影 基 基变换的矩阵表示 协方差矩阵及优化目标 方差 协方差 协方差矩阵 协方差矩阵对角化 算法及实例 PCA算法 实例 ...
- log4net使用简明教程,快看看哟
在项目当中经常会遇到各种各样的问题,如何可以尽快找到问题,那么就只能靠日志了,所以一个系统的日志是否完备合理就尤为重要. 在日志管理插件中log4net相当流行,下面就简单说明一下使用方法. log4 ...
- P/Invoke 技术
.NET 互操作 首先推荐一本书<精通.NET 互操作> ,这本书是目前中文资料里讲 互操作最详尽的书了. 做系统集成项目的同学应该都和设备打过交道(如视频设备:海康.大华等),在大多数情 ...
- rsync同步本地和服务器之间的文件
同步本地文件到服务器 rsync -zvrtopg --progress --delete test -e 'ssh -p 6665' yueyao@172.16.0.99:/media/sdb/us ...