Prometheus入门到放弃(6)之AlertManager进阶
前面几个篇幅,我们介绍了alertmanger报警配置,在实际运维过程中,我们都会遇到,报警的重复发送,以及报警信息关联性报警。接下来我们就介绍下通过alertmanger对告警信息的收敛。
一、告警分组(Grouping)
1.1 定义三个报警规则:
文中为了实验验证,告警值设置比较小,实际生产中,应该跟据业务的实际使用场景,来确定合理的告警值
[root@prometheus-server ~]# vim /etc/prometheus/rules/node_alerts.yml groups:
- name: node_alerts
rules:
- alert: InstanceDown
expr: up{job='node'} ==
for: 2m
labels:
severity: "critical"
env: dev
annotations:
summary: Host {{ $labels.instance }} of {{ $labels.job }} is Down!
- alert: OSLoad
expr: node_load1 >
for: 2m
labels:
severity: "warning"
env: dev
annotations:
summary: "主机 {{ $labels.instance }} 负载大于 1"
description: "当前值: {{ $value }}"
- alert: HightCPU
expr: -avg(irate(node_cpu_seconds_total{mode="idle"}[1m])) by(instance)* >
for: 2m
labels:
severity: "warning"
annotations:
summary: "主机 {{ $labels.instance }} of CPU 使用率大于10%!"
description: "当前值: {{ $value }}%"
以上3个报警规则,node_alerts是监控node_exporter服务状态,OSLoad是监控系统负载,HightCPU是监控系统cpu使用率,前两个有标签env: dev,后面2个有标签 severity: "warning",重启Prometheus服务,可以看到监控规则已经加载
1.2 定义alertmanager报警组:
[root@prometheus-server ~]# vim /etc/alertmanager/alertmanager.yml
global:
smtp_smarthost: 'smtp.163.com:25'
smtp_from: '****@163.com'
smtp_auth_username: '****@163.com'
smtp_auth_password: '****' ## 授权码
smtp_require_tls: false route:
group_by: ['env'] ### 以标签env分组,拥有labels为env的规则,如果在指定时间同时报警,报警信息会合并为一条进行发送
group_wait: 10s ### 组报警等待,等待该组中有没有其它报警
group_interval: 30s ### 组报警时间间隔
repeat_interval: 2m ### 重复报警时间,这个生产中跟据服务选择合适的时间
receiver: dev-mail ## 接收者 receivers:
- name: 'dev-mail' ## 对应上面的接收者
email_configs:
- to: '****@vanje.com.cn'
1.3 验证
我们停掉一台主机node_exporter(10.10.0.12)服务,用压测工具使某一台机器(10.10.0.11)负载大于1,cpu使用率(10.10.0.11)大于10,看下报警邮件是否会按我们定义组进行报警:
虽然我们同时触发了三个报警,但是跟据我们的定义,应该只会发两条报警信息,因为拥有env标签的报警规则,同时报警,会被合并为一条发送。
触发报警查看Prometheus ui界面上的alerts:

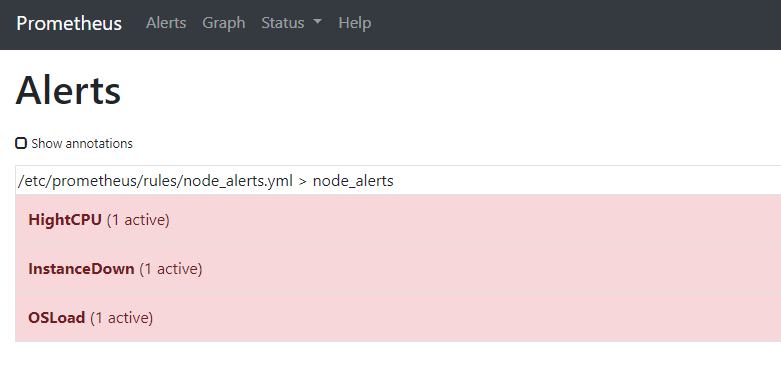
等2分钟后,如果检测到机器还是处于触发告警状态,Prometheus把会告警信息发送至alertmanager,然后跟据报警定义进行邮件报警:
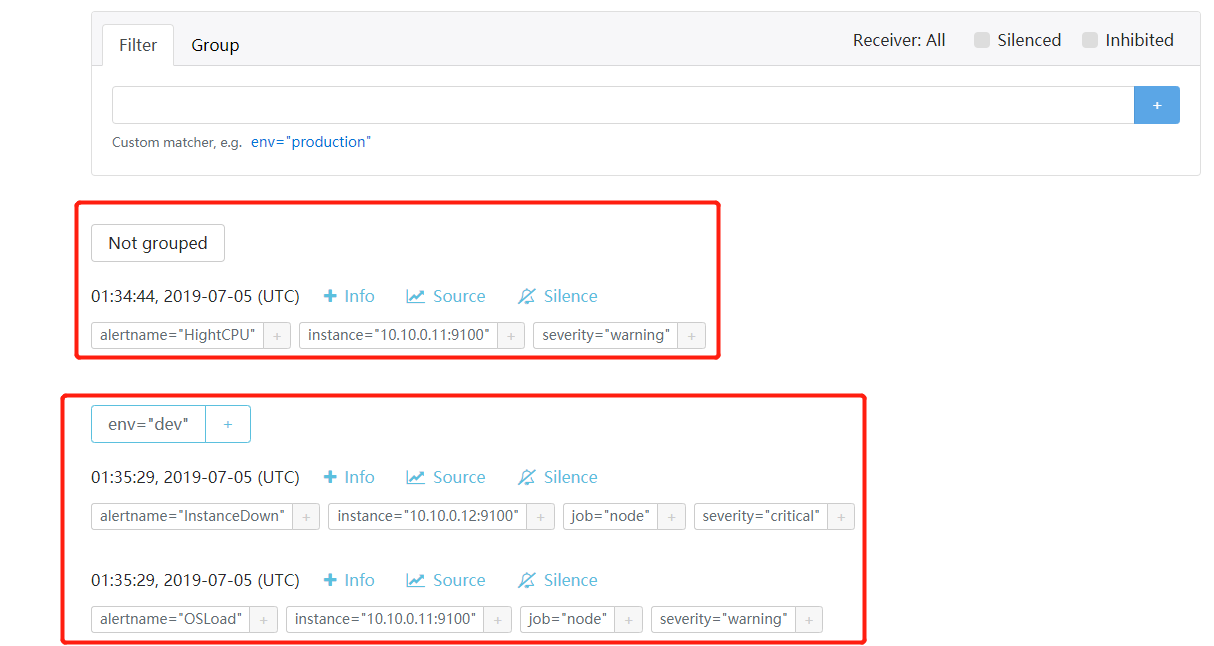
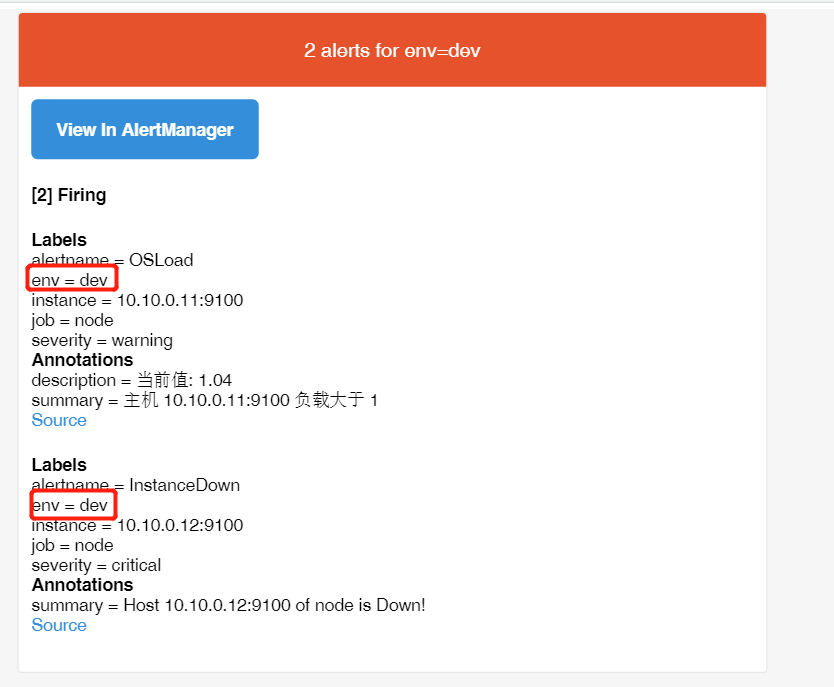
上图从alertmanager报警界面可以看到,报警信息已经按照分组合并,接下来我们看下邮箱中报警信息:
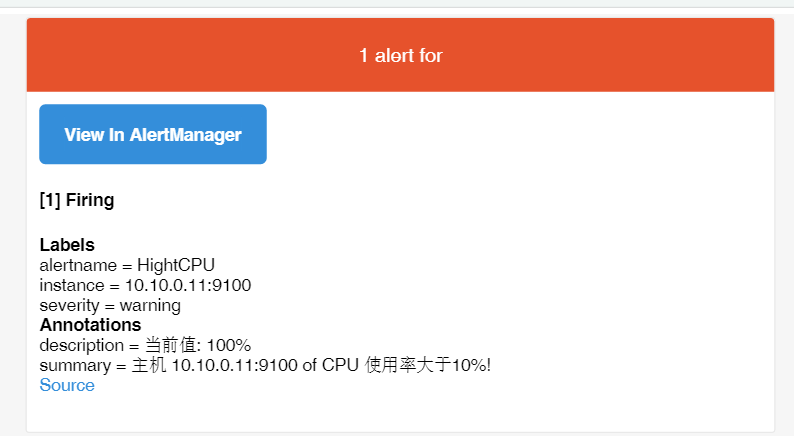
分组总结:
1、alertmanager跟据标签进行分组时,应该选择合适的标签,标签可以自定义,也可以使用默认的标签。
2、alertmanager报警分组,可以有效减少告警邮件数,但是仅是在同一个时间段报警,同一个组的告警信息才会合并发送。
二、告警抑制(Inhibition)
2.1 修改Prometheus 报警规则文件,为报警信息添加新标签area: A
[root@prometheus-server ~]# vim /etc/prometheus/rules/node_alerts.yml
groups:
- name: node_alerts
rules:
- alert: InstanceDown
expr: up{job='node'} ==
for: 2m
labels:
severity: "critical"
env: dev
area: A
annotations:
summary: Host {{ $labels.instance }} of {{ $labels.job }} is Down!
- alert: OSLoad
expr: node_load1 > 0.6
for: 2m
labels:
severity: "warning"
env: dev
area: A
annotations:
summary: "主机 {{ $labels.instance }} 负载大于 1"
description: "当前值: {{ $value }}"
- alert: HightCPU
expr: -avg(irate(node_cpu_seconds_total{mode="idle"}[1m])) by(instance)* >
for: 2m
labels:
severity: "warning"
area: A
annotations:
summary: "主机 {{ $labels.instance }} of CPU 使用率大于10%!"
description: "当前值: {{ $value }}%"
2.2 修改alertmanager配置文件
[root@prometheus-server ~]# vim /etc/alertmanager/alertmanager.yml
## 新增以下配置
inhibit_rules:
- source_match: ## 源报警规则
severity: 'critical'
target_match: ## 抑制的报警规则
severity: 'warning'
equal: ['area'] ## 需要都有相同的标签及值,否则抑制不起作用
2.3 验证
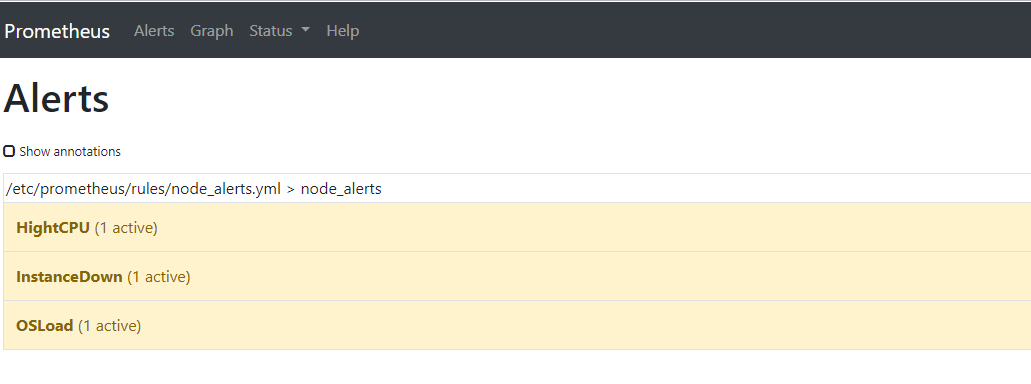
跟上面一样手动触发三个规则告警,跟据定义规则,应该只会收到一条报警信息:
查看Prometheus告警都已经触发,状态变为PENDING状态
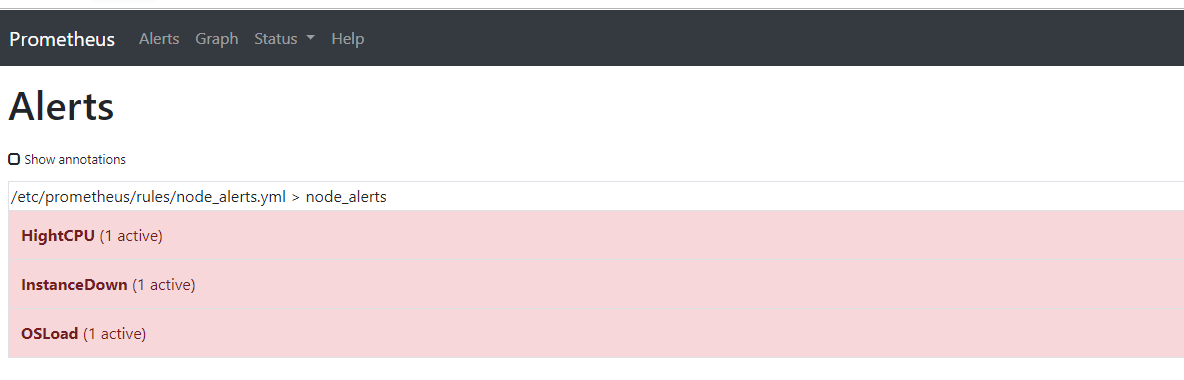
等待2分钟后, 三个告警状态由PENDING 变为 FIRING,同时prometheus会把告警信息发给alertmanager。
Alertmanager中我们只看到一条InstanceDown报警信息。

查看邮件中,也只收到InstanceDown的报警,另外2条报警已经被配置的抑制规则,把报警信息忽略掉。
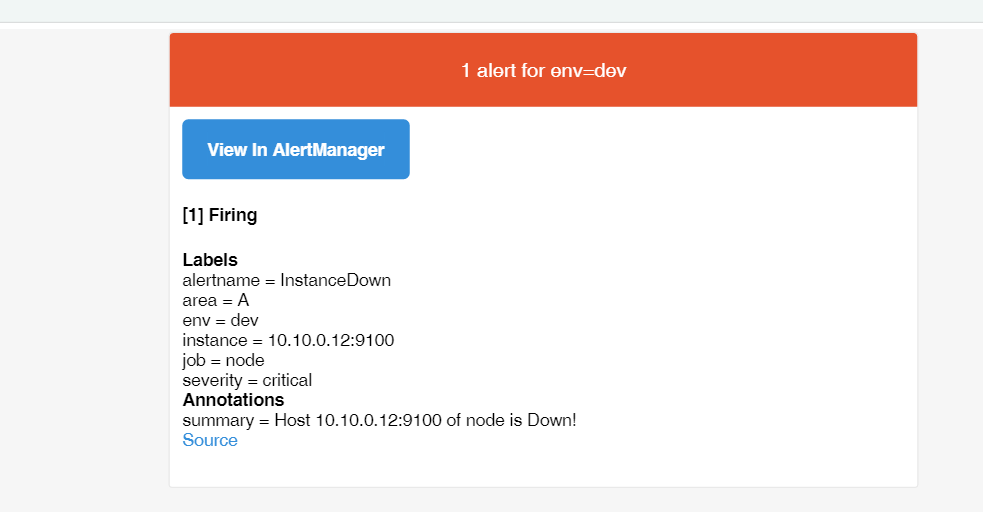
抑制总结:
1、抑制是指当警报发出后,停止重复发送由此警报引发其他错误的警报的机制。(比如网络不可达,服务器宕机等灾难性事件导致其他服务连接相关警报);
2、配置抑制规则,需要合理源规则及需要抑制的规则;
3、源规则与抑制规则需要具有相同的标签及标签值;
Prometheus入门到放弃(6)之AlertManager进阶的更多相关文章
- Prometheus入门到放弃(5)之AlertManager部署
alertmanager与exporters.cadvisor一样,都是独立于prometheus项目,这里我们也使用docker方式部署alertmanager. 1.下载镜像 镜像地址:https ...
- Prometheus入门到放弃(1)之Prometheus安装部署
规划: IP 角色 版本 10.10.0.13 prometheus-server 2.10 10.10.0.11 node_exporter 0.18.1 10.10.0.12 node_expor ...
- Prometheus入门到放弃(7)之redis_exporter部署
redis监控,prometheus需要使用redis_exporter客户端. 这里我们采用docker方式部署,既可以部署在redis所在服务器,也可以部署在其他机器: docker镜像地址:ht ...
- Prometheus入门到放弃(4)之cadvisor监控docker容器
Prometheus监控docker容器运行状态,我们用到cadvisor服务,cadvisor我们这里也采用docker方式直接运行. 1.下载镜像 [root@prometheus-server ...
- Prometheus入门到放弃(3)之Grafana展示监控数据
grafana我们这里采用docker方式部署 1.下载镜像 镜像官网地址:https://hub.docker.com/r/grafana/grafana/tags [root@prometheus ...
- Prometheus入门到放弃(2)之Node_export安装部署
1.下载安装 node_exporter服务需要在三台机器都安装,这里我们以一台机器为例: 地址:https://prometheus.io/download/ ### 另外两个节点部署时,需要先创建 ...
- K8S从入门到放弃系列-(16)Kubernetes集群Prometheus-operator监控部署
Prometheus Operator不同于Prometheus,Prometheus Operator是 CoreOS 开源的一套用于管理在 Kubernetes 集群上的 Prometheus 控 ...
- [精品书单] C#/.NET 学习之路——从入门到放弃
C#/.NET 学习之路--从入门到放弃 此系列只包含 C#/CLR 学习,不包含应用框架(ASP.NET , WPF , WCF 等)及架构设计学习书籍和资料. C# 入门 <C# 本质论&g ...
- FQ:从入门到放弃(二)
上次的FQ:从入门到放弃(一)介绍了XXNet的部署和基本使用.本文整理一些部署过程中出现的问题,都是这几天朋友们安装过程中出现的问题.如果覆盖不全,欢迎在博客下方评论,互相交流,互相学习. 不过首先 ...
随机推荐
- python 字符串方法整理
Python字符串方法 1.大小写转换 1.1 lower.upper lower():小写 upper():大写 1.2 title.capitalize S.title():字符串中所有单词首字母 ...
- 抓取Dump文件的方法和工具介绍
一.Windows系统的任务管理器里抓dump 启动任务管理器,选中某个进程,右键,弹出菜单"创建转储文件" 注意事项: 当你在64位Windows系统上抓32位进程的dmup文件 ...
- Linux 系统管理——账号管理
一.用户账号管理 1.用户账户概述 用户账户的常见分类: 超级用户:root uid=0 gid=0 权限最大 普通用户:uid>=500 做一般权限的系统管理,权限有限. 程序用户:1 ...
- Linux启动与停止Tomcat
停止Tomcat: cd 切换到Tomcat的bin目录下,关闭命令:[root@localhost bin]# ./shutdown.sh 检查tomcat是否已关闭,检查命令:[root@loca ...
- 洛谷P4380 [USACO18OPEN]Multiplayer Moo
题目 第一问: 用广搜类似用\(floodfill\)的方法. 第二问: 暴力枚举加剪枝,对于每个连通块,枚举跟这个连通块相连的其他与他颜色不同的连通块,然后向外扩展合并颜色与他们俩相同的连通块.扩展 ...
- 洛谷P3147 262144
题目 此题数据范围小的话可以用区间\(DP\),但是该题目的数据范围并不能用区间DP来求解,因此我们考虑优化\(DP\). 每个数的生成一定是由这两个区间 考虑区间DP的弊端是并不知道每个数生成的区间 ...
- 一篇文章了解Github和Git教程
有趣有内涵的文章第一时间送达! 喝酒I创作I分享 关注我,每天都有优质技术文章推送,工作,学习累了的时候放松一下自己. 本篇文章同步微信公众号 欢迎大家关注我的微信公众号:「醉翁猫咪」 生活中总有些东 ...
- 【POJ1573】Robot Motion
题目传送门 本题知识点:模拟 本题的题意也很简单. 给出一个矩阵,矩阵里面有着东南西北(上下左右)的指示,当机器人走到上面时则会按照指示前进.机器人每次都从最上面一行的某一列进入. 需要判断的是机器人 ...
- nRF51822 的两路 PWM 极性
忙了一阵这个PWM,玩着玩着终于发现了些规律.Nordic 也挺会坑爹的. nRF51822 是没有硬件 PWM 的,只能靠一系列难以理解的 PPI /GPIOTE/TIMER来实现,其实我想说,我醉 ...
- D3.js的v5版本入门教程(第九章)——完整的柱状图
D3.js的v5版本入门教程(第九章) 一个完整的柱状图应该包括的元素有——矩形.文字.坐标轴,现在,我们就来一一绘制它们,这章是前面几章的综合,这一章只有少量新的知识点,它们是 d3.scaleBa ...