python-django框架中使用docker和elasticsearch配合实现搜索功能
注意:系统环境为Ubuntu18
一、docker安装
0:如果之前有安装过docker使用以下命令卸载:
sudo apt-get remove docker docker-engine docker.io containerd runc
docker安装官网参考:
https://docs.docker.com/install/linux/docker-ce/ubuntu/
1:首先更新apt
sudo apt-get update
2:添加证书安装包以允许apt通过HTTPS:
sudo apt-get install \
apt-transport-https \
ca-certificates \
curl \
gnupg-agent \
software-properties-common
3:添加docker官方密钥
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
4:添加仓库
sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
5:安装docker ce
sudo apt-get install docker-ce docker-ce-cli containerd.io
6:测试
sudo docker run hello-world
7:添加当前系统用户到docker用户组
sudo usermod -aG docker 用户名
docker 拓展命令:
docker images :查看所有启动成功的镜像
docker ps -a :查看所有
docker logs 容器id :查看容器日志
docker 如果启动容器失败,就先删除容器,删除目录,再次执行安装。
二、使用docker安装Elasticsearch
1:获取镜像
docker image pull delron/elasticsearch-ik:2.4.6-1.0
如果pull拉取很慢可以从我的百度云中下载,然后传到Linux系统中然后使用docker命令导入
链接:https://pan.baidu.com/s/1zXBR_uHSFxK5xNxklGV1pQ
提取码:96iw
docker load -i elasticsearch-ik-2.4.6_docker.tar
查看本地仓库是否有这个镜像
docker images
或
docker image ls
将下载的elasticsearch.zip上传到Linux系统中的家目录,然后解压。在目录中的elasticsearch/config/elasticsearch.yml第54行更改IP地址为0.0.0.0,端口改为8002,默认为9002
解压命令:
unzip elasticsearch.zip
2:创建docker容器并运行
根据拉取到本地的镜像创建容器,需要将elasticsearch/config配置文件所在目录修改为你自己的路径
docker run -dti --network=host --name=elasticsearch -v /home/上面上传后解压出来的文件路径地址/elasticsearch/config:/usr/share/eleaticsearh/config delron/elasticsearch-ik:2.4.6-1.0
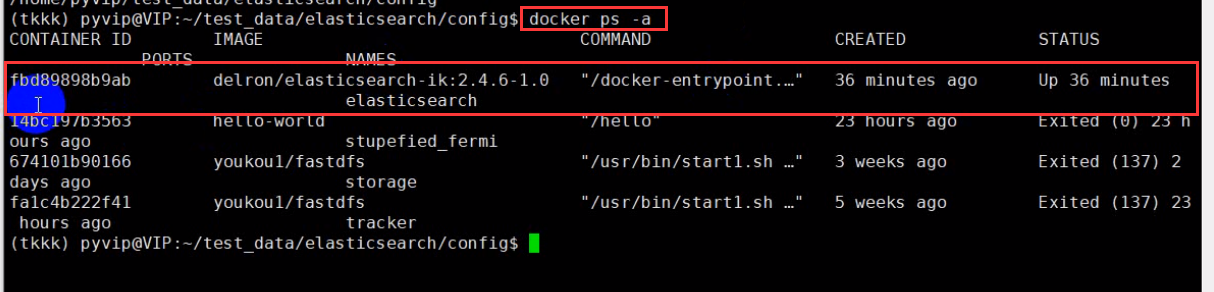
查看是否创建成功,如果STATUS为Up则创建成功
docker container ls -a 或 docker ps -a
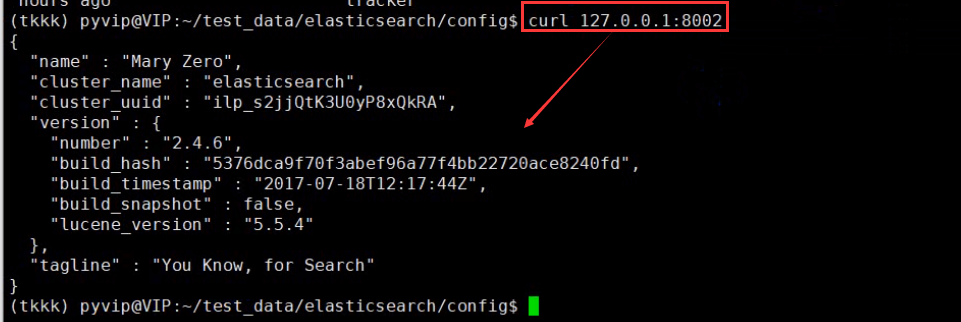
测试 curl 127.0.0.1:8002
3:进入项目的虚拟环境中,安装以下包
pip install django-haystack
pip install elasticsearch==2.4.1
4:在django项目配置,在settings.py文件中加入下面配置。
4-1:在INSTALLED_APPS节点中注册haystack
INSTALLED_APPS = [
...
'haystack',
...
]
4-2:加入配置
# 建立连接
ELASTICSEARCH_DSL = {
'default':{
'host':'127.0.0.1:8002'
},
}
# 配置Haystack
HAYSTACK_CONNECTIONS = {
'default': {
'ENGINE': 'haystack.backends.elasticsearch_backend.ElasticsearchSearchEngine',
'URL': 'http://127.0.0.1:8002/', # 此处为elasticsearch运行的服务器ip地址,端口号固定为9200
'INDEX_NAME': 'mysite', # 指定elasticsearch建立的索引库的名称
},
} # 当添加、修改、删除数据时,自动生成索引,当数据库改变时候,会自动更新索引
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
# 每页显示多少条数据
HAYSTACK_SEARCH_RESULTS_PER_PAGE = 20
5:建立索引
在需要创建索引的实体中创建search_indexes.py(文件名固定写法)

5-1:search_indexes.py文件内容如下:
from haystack import indexes
from .models import News # 导入模型类 # 建索引类
# 模型名称+Index(固定的)
class NewsIndex(indexes.SearchIndex, indexes.Indexable):
'''
News索引数据库模型
'''
# 这个主要是使用5-2来建立索引
text = indexes.CharField(document=True, use_template=True)
# 以下是为了在使用时 news.id 如果没有写就需要news.object.id
id = indexes.IntegerField(model_attr='id')
title = indexes.CharField(model_attr='title')
digest = indexes.CharField(model_attr='digest')
content = indexes.CharField(model_attr='content')
image_url = indexes.CharField(model_attr='image_url') def get_model(self):
'''
返回建立索引模型
'''
return News def index_queryset(self, using=None):
'''
返回要建立索引的数据查询集
:param using:
:return:
''' return set.get_model().objects.filter(is_delete=False, tag_id=1)
# return set.get_model().objects.filter(is_delete=False,tag_id=[1,2,3,4,5])
5-2:创建模板
# 需要在templates文件夹中创建一个search/indexes/app名称/模型名称小写_text.txt文件(固定结构)

news_text.txt内容为:需要建立的索引

6:生成索引
通过xshell进入项目进入虚拟环境执行
python manage.py rebuild_index

7: 分页搜索接口/方法
7-1
from haystack.views import SearchView as _SearchView
from .models import News # 导入模型类
from .models import HotNews
from mysite import setttings
from django.core.paginator import Paginator, EmptyPage, PageNotAnInteger
from django.shortcuts import render
from django.views import View class SearchView(_SearchView):
# 模板文件
template = 'news/search.html' # 重写响应方式,如果请求参数为空,返回模型News的热门新闻数据,否则根据参数q搜索相关数据
def create_response(self):
kw = self.request.GET.get('q', '')
if not kw:
show_all = True
hot_news = HotNews.objects.select_related(
'News'
).only(
'news__title',
'news__image_url',
'news__id'
).filter(
is_delete=False
).order_by(
'priority',
'-news__clicks'
)
paginator = Paginator(hot_news, setttings.HAYSTACK_SEARCH_RESULTS_PER_PAGE)
try:
page = paginator.page(int(self.request.GET.get('page', 1)))
except PageNotAnInteger:
# 如果参数page的数据类型不是整数,则返回第一页数据
page = paginator.page(1)
except EmptyPage:
# 用户访问的页数大于实际的页数,则返回最后一页的数据
page = paginator.page(paginator.num_pages)
return render(self.request, self.template, locals())
else:
show_all = False
qs = super(SearchView, self).create_response()
return qs
7-2:在app中的urls中设置url
path('search/',view.SearchView(),name='search')
7-3:前端部分代码
<div class="content">
<!-- search-list start -->
{% if not show_all %}
<div class="search-result-list">
<h2 class="search-result-title">
搜索结果 <span style="font-weight: 700;color: #ff6620;">{{ paginator.num_pages }}</span>页
</h2>
<ul class="news-list">
{% for one_news in page.object_list %}
<li class="news-item clearfix">
<a href="{% url 'news:detail' one_news.id %}" class="news-thumbnail"
target="_blank">
<img src="{{ one_news.object.image_url }}">
</a>
<div class="news-content">
<h4 class="news-title">
<a href="{% url 'news:detail' one_news.id %}">
{% highlight one_news.title with query %}
</a>
</h4>
<p class="news-details">{% highlight one_news.digest with query %}</p>
<div class="news-other">
<span class="news-type">{{ one_news.object.tag.name }}</span>
<span class="news-time">{{ one_news.object.update_time }}</span>
<span
class="news-author">{% highlight one_news.object.author.username with query %} </span>
</div>
</div>
</li>
{% endfor %} </ul>
</div> {% else %} <div class="news-contain">
<div class="hot-recommend-list">
<h2 class="hot-recommend-title">热门推荐</h2>
<ul class="news-list"> {% for one_hotnews in page.object_list %} <li class="news-item clearfix">
<a href="#" class="news-thumbnail">
<img src="{{ one_hotnews.news.image_url }}">
</a>
<div class="news-content">
<h4 class="news-title">
<a href="{% url 'news:detail' one_hotnews.news.id %}">{{ one_hotnews.news.title }}</a>
</h4>
<p class="news-details">{{ one_hotnews.news.digest }}</p>
<div class="news-other">
<span class="news-type">{{ one_hotnews.news.tag.name }}</span>
<span class="news-time">{{ one_hotnews.update_time }}</span>
<span class="news-author">{{ one_hotnews.news.author.username }}</span>
</div>
</div>
</li> {% endfor %} </ul>
</div>
</div> {% endif %} <!-- search-list end -->
<!-- news-contain start --> {# 分页导航 #}
<div class="page-box" id="pages">
<div class="pagebar" id="pageBar">
<a class="a1">{{ page.paginator.count }}条</a>
{# 上一页的URL地址 #}
{% if page.has_previous %}
{% if query %}
<a href="{% url 'news:search' %}?q={{ query }}&page={{ page.previous_page_number }}"
class="prev">上一页</a>
{% else %}
<a href="{% url 'news:search' %}?page={{ page.previous_page_number }}" class="prev">上一页</a>
{% endif %}
{% endif %}
{# 列出所有的URL地址 #}
{% for num in page.paginator.page_range|slice:":10" %}
{% if num == page.number %}
<span class="sel">{{ page.number }}</span>
{% else %}
{% if query %}
<a href="{% url 'news:search' %}?q={{ query }}&page={{ num }}"
target="_self">{{ num }}</a>
{% else %}
<a href="{% url 'news:search' %}?page={{ num }}" target="_self">{{ num }}</a>
{% endif %}
{% endif %}
{% endfor %} {# 如果页数大于10,则打两点 #}
{% if page.paginator.num_pages > 10 %}
.. {% if query %}
<a href="{% url 'news:search' %}?q={{ query }}&page={{ page.paginator.num_pages }}"
target="_self">{{ page.paginator.num_pages }}</a>
{% else %}
<a href="{% url 'news:search' %}?page={{ page.paginator.num_pages }}"
target="_self">{{ page.paginator.num_pages }}</a>
{% endif %} {% endif %} {# 下一页的URL地址 #}
{% if page.has_next %}
{% if query %}
<a href="{% url 'news:search' %}?q={{ query }}&page={{ page.next_page_number }}"
class="next">下一页</a>
{% else %}
<a href="{% url 'news:search' %}?page={{ page.next_page_number }}"
class="next">下一页</a>
{% endif %}
{% endif %}
</div>
</div> <!-- news-contain end -->
</div>
7-4:高亮及分页样式
/* === current index start === */
#pages {
padding: 32px 0 10px;
} .page-box {
text-align: center;
/*font-size: 14px;*/
} #pages a.prev, a.next {
width: 56px;
padding: 0
} #pages a {
display: inline-block;
height: 26px;
line-height: 26px;
background: #fff;
border: 1px solid #e3e3e3;
text-align: center;
color: #333;
padding: 0 10px
} #pages .sel {
display: inline-block;
height: 26px;
line-height: 26px;
background: #0093E9;
border: 1px solid #0093E9;
color: #fff;
text-align: center;
padding: 0 10px
} .highlighted{
color:coral;
mso-ansi-font-weight: bold;
}
/* === current index end === */
8:效果图
python-django框架中使用docker和elasticsearch配合实现搜索功能的更多相关文章
- Python的Django框架中forms表单类的使用方法详解
用户表单是Web端的一项基本功能,大而全的Django框架中自然带有现成的基础form对象,本文就Python的Django框架中forms表单类的使用方法详解. Form表单的功能 自动生成HTML ...
- Python的Django框架中的Cookie相关处理
Python的Django框架中的Cookie相关处理 浏览器的开发人员在非常早的时候就已经意识到. HTTP's 的无状态会对Web开发人员带来非常大的问题,于是(cookies)应运而生. coo ...
- Python的Django框架中的Context使用
Python的Django框架中的Context使用 近期整理些Python方面的知识,一旦你创建一个 Template 对象,你能够用 context 来传递数据给它. 一个context是一系列变 ...
- Python中的Django框架中prefetch_related()函数对数据库查询的优化
实例的背景说明 假定一个个人信息系统,需要记录系统中各个人的故乡.居住地.以及到过的城市.数据库设计如下: Models.py 内容如下: ? 1 2 3 4 5 6 7 8 9 10 11 12 1 ...
- Python的Django框架中的URL配置与松耦合
Python的Django框架中的URL配置与松耦合 用 python 处理一个文本时,想要删除其中中某一行,常规的思路是先把文件读入内存,在内存中修改后再写入源文件. 但如果要处理一个很大的文本,比 ...
- Django框架中的Context使用
Django框架中的Context使用 2017年11月09日 20:01:09 aweilark 阅读数:1113 转载自:http://www.aichengxu.com/python/606 ...
- 分布式队列celery 异步----Django框架中的使用
仅仅是个人学习的过程,发现有问题欢迎留言 一.celery 介绍 celery是一种功能完备的即插即用的任务对列 celery适用异步处理问题,比如上传邮件.上传文件.图像处理等比较耗时的事情 异步执 ...
- [Python] Django框架入门
说明:Django框架入门 当前项目环境:python3.5.django-1.11 项目名:test1 应用名:booktest 命令可简写为:python manager.py xxx => ...
- Django框架中logging的使用
Django框架中logging的使用 日志是我们在项目开发中必不可少的一个环节,Python中内置的logging已经足够优秀到可以直接在项目中使用. 本文介绍了如何在DJango项目中配置日志. ...
随机推荐
- 高斯混合模型(GMM)及MATLAB代码
之前在学习中遇到高斯混合模型,卡了很长一段时间,在这里记下学习中的一些问题以及解决的方法.希望看到这篇文章的同学们对高斯混合模型能有一些基本的概念.全文不废话,直接上重点. 本文将从以下三个问题详解高 ...
- fluent将出口温度赋值给入口
Fluent版本:Fluent18.2 首先我们启动Fluent 然后按照正常的流程进行模型缩放,材料的设置,边界条件的设置等等,然后初始化. 在完成了算例的初始化以后 (define (OutToI ...
- js DOM之基础详解
DOM(文档对象模型)是针对HTML和XML文档的一个API,描绘了一个层次化的节点树,允许开发人员添加.删除和修改页面的某一部分. HTML DOM 树形结构如下: 1.Node方面 1.1 节点类 ...
- 第07组 Alpha冲刺(4/6)
队名:摇光 队长:杨明哲 组长博客:求戳 作业博客:求再戳 队长:杨明哲 过去两天完成了哪些任务 文字/口头描述:摇光测评的相关功能. 展示GitHub当日代码/文档签入记录:(组内共用,已询问过助教 ...
- redis之 主从复制和哨兵
一.Redis主从复制 主从复制:主节点负责写数据,从节点负责读数据,主节点定期把数据同步到从节点保证数据的一致性 1. 主从复制的相关操作 a,配置主从复制方式一.新增redis6380.conf, ...
- linux学习(1):linux命令大全
Linux命令 目录 1 文件管理... 5 1.1 basename. 5 1.2 cat 5 1.3 cd. 5 1.4 ...
- 【mybatis源码学习】mybatis的结果映射
一.mybatis结果映射的流程 二.mybatis结果映射重要的类 1.org.apache.ibatis.executor.resultset.ResultSetWrapper(对sql执行返回的 ...
- python基于redis实现分布式锁
阅读目录 什么事分布式锁 基于redis实现分布式锁 一.什么是分布式锁 我们在开发应用的时候,如果需要对某一个共享变量进行多线程同步访问的时候,可以使用我们学到的锁进行处理,并且可以完美的运行,毫无 ...
- elementui---for循环需要添加KEY
在用VUE和elementui开发项目的时候,在开启 es-lient 的时候,如果for循环没有添加 key ,会报语法上的错误. genderSelect:[ {value:0,label:'女' ...
- C# winform判断窗体是否已打开
Form1 form; /// <summary> /// 开始检测 /// </summary> /// <param name="sender"& ...