SQL Server 2019 中标量用户定义函数性能的改进
在SQL Server中,我们通常使用用户定义的函数来编写SQL查询。UDF接受参数并将结果作为输出返回。我们可以在编程代码中使用这些UDF,并且可以快速编写查询。我们可以独立于任何其他编程代码来修改UDF。
在SQL Server中,我们具有以下类型的用户定义函数。
- 标量函数:标量用户定义的函数返回单个值。您将始终具有RETURNS子句。返回值不能是文本,图像或时间戳。以下是标量函数的示例。
Create FUNCTION dbo.ufnGetCustomerData (@CustomerID int)
RETURNS varchar (50)
AS
BEGIN
DECLARE @CustomerName varchar(50);
SELECT @CustomerName = customername
FROM [WideWorldImporters].[Sales].[Customers] C
WHERE C.CustomerID=@CustomerID
RETURN @CustomerName;
END;传统上,标量用户定义函数不被认为是高性能的好选择,但是SQL Server 2019提供了一种提高这些标量用户定义函数的性能的方法。我们将在本文的后一部分中了解更多有关它的信息。
多语句表值函数(TVF):其语法类似于标量用户定义函数,并提供多值作为输出。由于基数估计问题,这些性能也不优化。
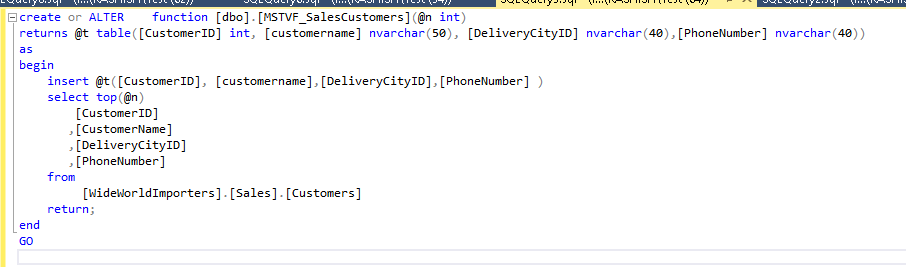
SQL Server 2012提供固定的基数估计,而SQL Server 2012提供的基数估计为100。SQLServer 2017使用称为交错执行的功能改进了这些MSTVF的基数估计。
- 内联表值函数:内联表值函数是性能优化的函数。它们不包含表定义。此函数内部的查询批处理是一条语句,因此,当我们以批处理或循环方式使用它时,它不会提供任何性能问题。
下面是内联表值函数的示例。
USE [WideWorldImporters]
GO SET ANSI_NULLS ON
GO SET QUOTED_IDENTIFIER ON
GO CREATE FUNCTION [Application].[DetermineCustomerAccess](@CityID int)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN (SELECT 1 AS AccessResult
WHERE IS_ROLEMEMBER(N'db_owner') <> 0
OR IS_ROLEMEMBER((SELECT sp.SalesTerritory
FROM [Application].Cities AS c
INNER JOIN [Application].StateProvinces AS sp
ON c.StateProvinceID = sp.StateProvinceID
WHERE c.CityID = @CityID) + N' Sales') <> 0
OR (ORIGINAL_LOGIN() = N'Website'
AND EXISTS (SELECT 1
FROM [Application].Cities AS c
INNER JOIN [Application].StateProvinces AS sp
ON c.StateProvinceID = sp.StateProvinceID
WHERE c.CityID = @CityID
AND sp.SalesTerritory = SESSION_CONTEXT(N'SalesTerritory'))));
GO
标量用户定义函数
如上所述,标量用户定义的函数不会在SQL Server中提供性能优势。因此,在本节中,我们将首先查看标量用户定义函数的性能问题,然后使用SQL Server 2019比较性能。
对于此示例,我正在运行SQL Server 2019 2.1和WideWorldImporters数据库。
将数据库兼容性级别设置为140。
USE [master]
GO
ALTER DATABASE [WideWorldImporters] SET COMPATIBILITY_LEVEL = 140
GO
使用数据库范围的配置选项清除过程缓存。这将从所有存储的执行计划或缓存中清除我们的数据库。
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE ;
Go
现在,在WideWorldImporters数据库中创建标量用户定义函数。此函数将根据说明返回数量。执行以下脚本。
CREATE OR ALTER FUNCTION Sales.SalesQuantity
(@Description NVARCHAR(100))
RETURNS SMALLINT
AS
BEGIN
DECLARE @Count SMALLINT SELECT @Count= Quantity
FROM Sales.OrderLines
WHERE Description=@Description; RETURN(@Count)
END;
GO
我们可以使用类似于表列对象的功能。运行以下命令,该命令将UDF函数用作普通表列。
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT
Sol.orderid,
sol.Description,
Sales.SalesQuantity(sol.Description) as quantity,
PickedQuantity
FROM Sales.Orders as so
JOIN Sales.OrderLines as sol
on so.OrderId=sol.OrderID
WHERE
sol.PickingCompletedWhen >'2013-01-01 11:00:00.0000000'
ORDER BY UnitPrice DESC
GO
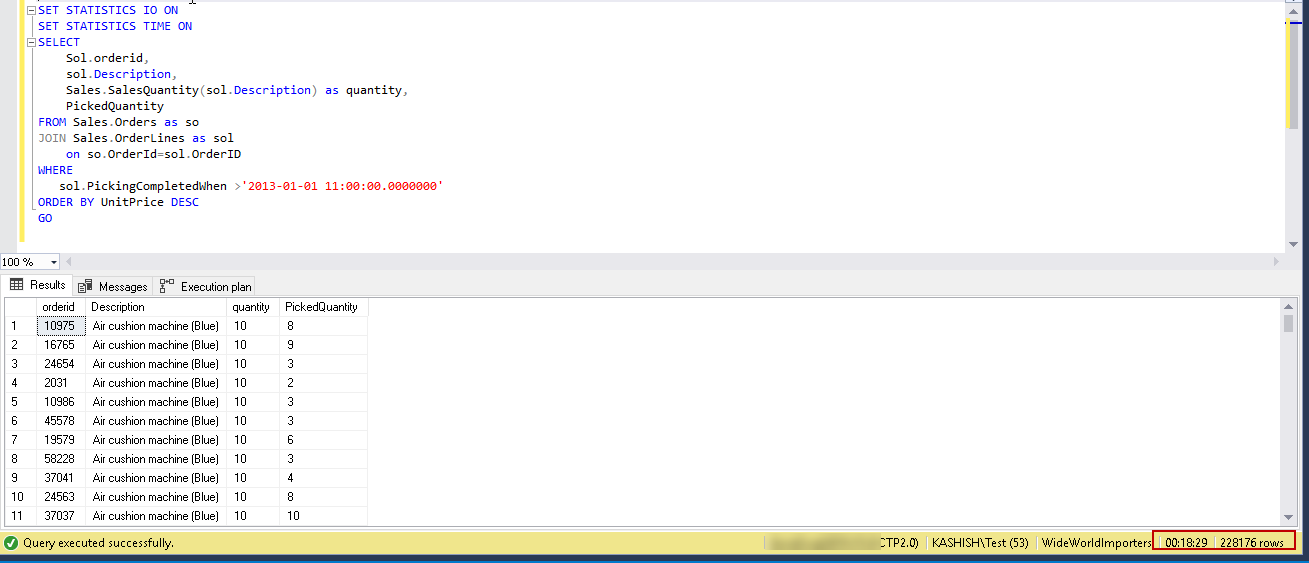
在上面的屏幕截图中,您可以看到大约花了18分钟来处理228,176条记录。
现在让我们以兼容级别150(SQL Server 2019)运行相同的查询。
USE [master]
GO
ALTER DATABASE [WideWorldImporters] SET COMPATIBILITY_LEVEL = 150
GO
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE ;
Go
使用此已修改的兼容性级别再次运行查询。
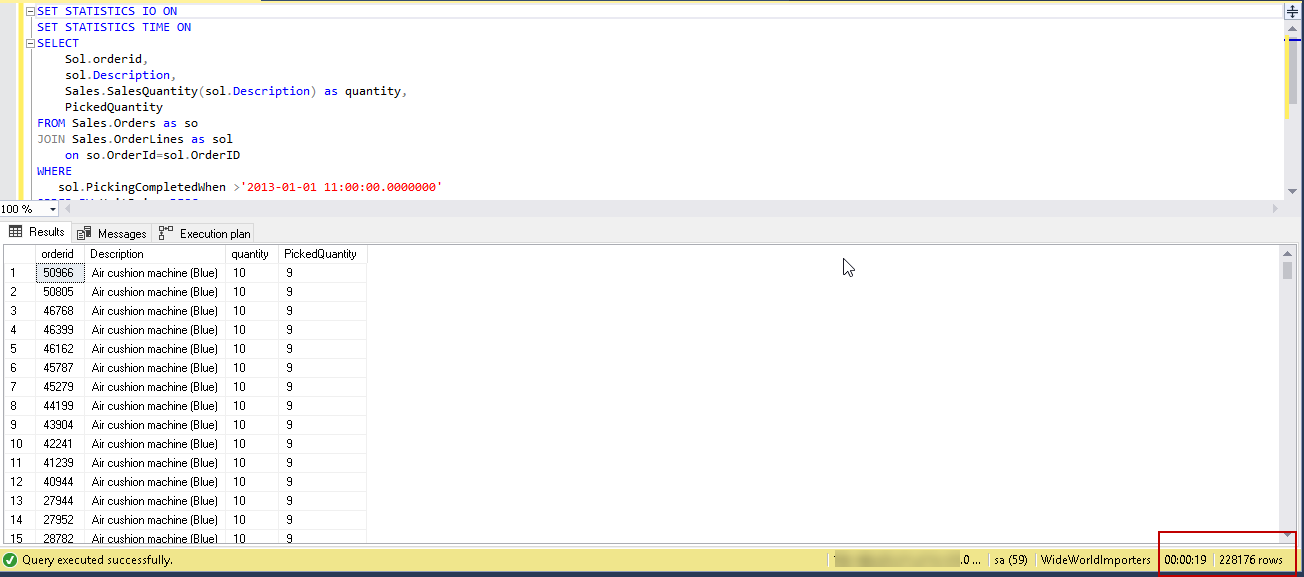
在SQL Server 2019中,您可以注意到查询仅用19秒就完成了处理228,176行,而SQL Server 2016中则是12分钟。相对而言,处理这些结果非常快。
现在让我们在SQL Server 2016和SQL Server 2019数据库兼容性级别中再次运行查询,并捕获统计数据IO和统计时间以及要与之进行比较的实际执行计划。
SQL Server 2019统计信息输出
(受影响的228176行)
表'OrderLines'。扫描计数5,逻辑读857,物理读0,预读0,lob逻辑读180,lob物理读0,lob预读0。
表'OrderLines'。段读取为2,段跳过0。
表为“工作表”。扫描计数227,逻辑读730037,物理读0,预读0,lob逻辑读0,lob物理读0,lob预读0。
表'Workfile'。扫描计数0,逻辑读0,物理读0,预读0,lob逻辑读0,lob物理读0,lob预读0。
(受影响的1行)
SQL Server执行时间:
CPU时间= 15287毫秒,经过的时间= 18782毫秒。
SQL Server解析和编译时间:
CPU时间= 0毫秒,经过的时间= 0毫秒。
SQL Server执行时间:
CPU时间= 0毫秒,经过的时间= 0毫秒。

SQL Server 2016统计信息输出
SQL Server解析和编译时间:
CPU时间= 0毫秒,经过的时间= 0毫秒。
SQL Server执行时间:
CPU时间= 0毫秒,经过的时间= 0毫秒。
SQL Server解析和编译时间:
CPU时间= 0毫秒,经过的时间= 0毫秒。
SQL Server执行时间:
CPU时间= 0毫秒,经过的时间= 0毫秒。
SQL Server执行时间:
CPU时间= 0毫秒,经过的时间= 0毫秒。
(受影响的228176行)
表“工作表”。扫描计数0,逻辑读0,物理读0,预读0,lob逻辑读0,lob物理读0,lob预读0。
表'OrderLines'。扫描计数1,逻辑读3504,物理读0,预读0,lob逻辑读0,lob物理读0,lob预读0。
(受影响的1行)
SQL Server执行时间:
CPU时间= 1071719 ms,经过的时间= 1109655 ms。
SQL Server解析和编译时间:
CPU时间= 0毫秒,经过的时间= 0毫秒。
SQL Server执行时间:
CPU时间= 0毫秒,经过的时间= 0毫秒。

如果将执行级别与兼容性级别140(SQL Server 2017)和兼容性级别150(SQL Server 2019)进行比较,则可以看到CPU时间和运行时间有了显着改善。

在下表中,您可以看到Scalar用户定义函数与SQL Server 2019的性能优化比较
|
SQL Server兼容性级别140 |
SQL Server兼容性级别150 |
性能改进 |
|
CPU – 1,071,719毫秒 |
CPU 15,287毫秒 |
1,056,432毫秒 |
|
经过时间1,109,655毫秒 |
经过时间18,782毫秒 |
1,090,873毫秒 |
执行计划比较
在本节中,我们将比较在使用SQL Server 2019及更高版本运行标量UDF时的执行计划。
以下是我们以兼容级别140(SQL Server 2017或更低版本)运行标量UDF时的实际执行计划
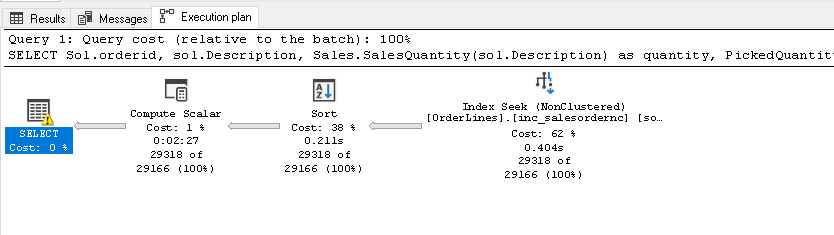
在估算的执行计划中,我们将对此有一个更清晰的认识。在下面的计划中,它显示了查询和UDF函数的单独执行计划。因此,SQL Server在SQL Server 2017之前将标量UDF函数视为一个单独的标识。每次调用此UDF函数时,SQL Server都需要做额外的工作。
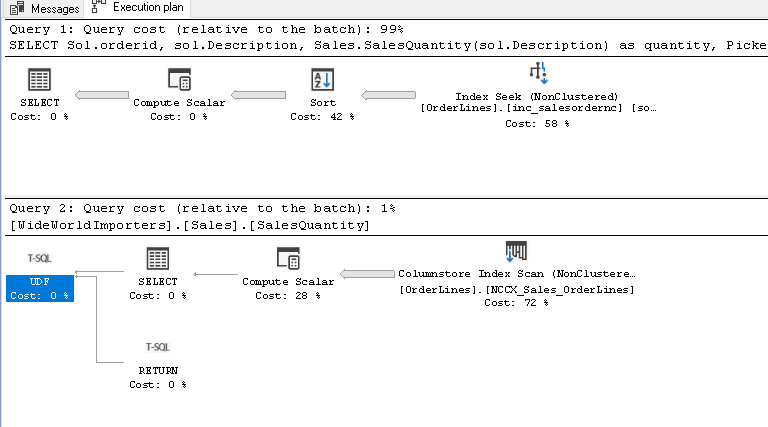
现在,如果我们查看SQL Server 2019中的实际估计计划,我们将获得一个较早执行计划的复杂计划,如下图所示。在SQL Server 2019中,由于内联功能,它能够将UDF操作合并到单个查询计划中。
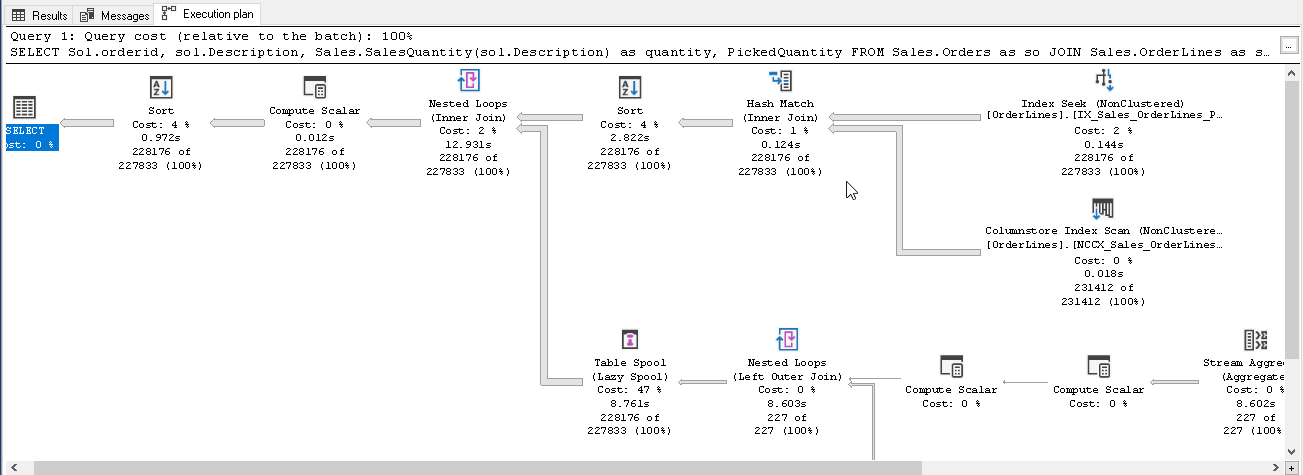
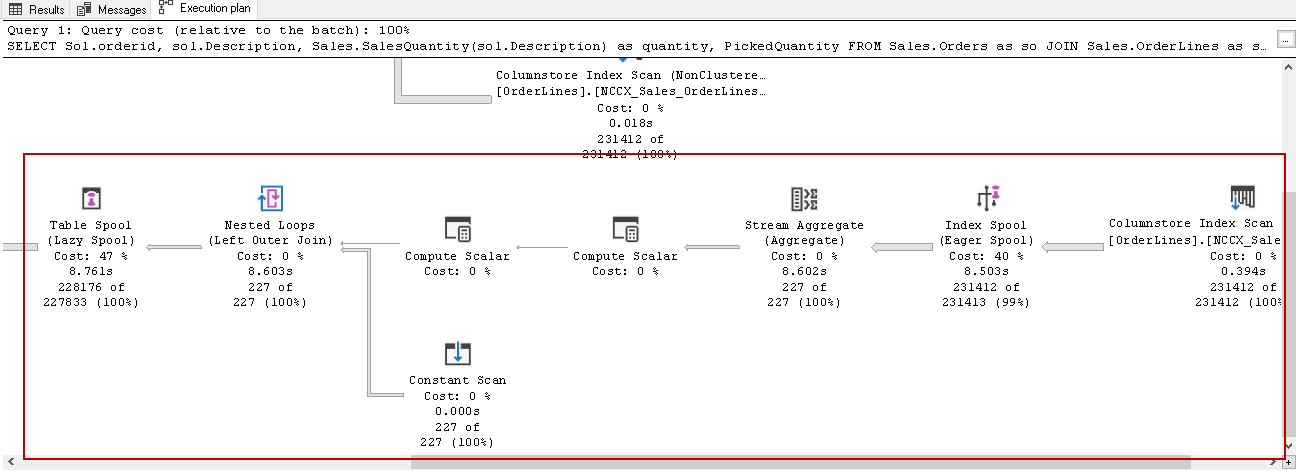
在此执行计划中,它在下部区域显示了UDF。您可以看到多个运算符来执行查询。SQL Server 2019内联标量UDF以优化查询的执行。它不会将此UDF视为单独的标识,但是会像正常的select语句一样运行它。因此,我们获得了CPU,内存,执行时间等方面的性能优势。
我们可以检查SQL Server是否能够内联特定标量UDF。SQL Server 2019在sys.sql_modules中引入了新列is_inlineable。运行以下查询,并在其中传递标量函数名称。在下面的查询中,我们的UDF显示值1,这意味着SQL Server 2019可以倾斜此函数。
select o.name, sm.is_inlineable
from sys.sql_modules sm
join sys.objects o on sm.object_id = o.object_id
where o.name = 'SalesQuantity';
在SQL Server 2019中内嵌标量UDF的条件
如果满足以下条件,则SQL Server 2019可以内联标量函数。
- UDF不是分区函数
- 没有引用任何表变量
- 没有使用任何计算列。
- 不能在Group By子句中调用UDF
- 可以在标量UDF中使用以下构造
- Declare
- Select
- If/ else
- Return
- Exits or IsNull
- UDF没有包含任何与时间有关的函数。
使用SQL Server 2019 UDF倾斜功能的不同方法。
我们可以通过以下方式在SQL Server 2019中使用此UDF内联功能。
- 将数据库兼容性级别设置为150(SQL Server 2019)
我们可以使用新的数据库处理配置来控制此行为。您可以在下面的数据库作用域配置列表中看到,我们有了新的选项TSQL_SCALAR_UDF_INLINING
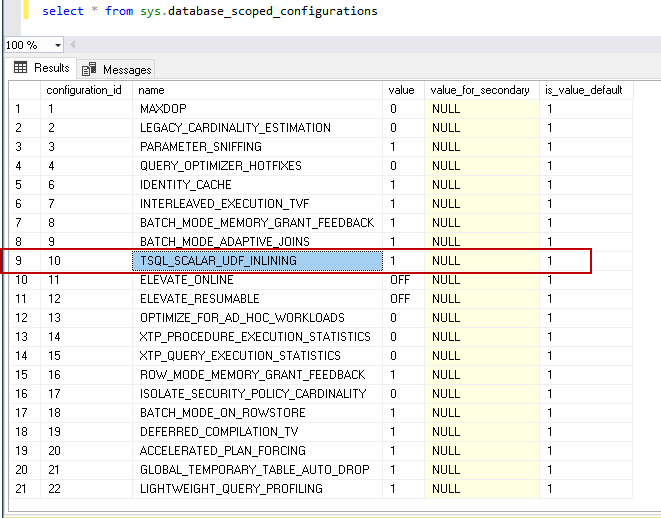
--Run the below query to turn on Scalar UDF Inlining in a particular database
ALTER DATABASE SCOPED CONFIGURATION SET TSQL_SCALAR_UDF_INLINING = ON; -- Run the below query to turn off Scalar UDF Inlining in a particular database
ALTER DATABASE SCOPED CONFIGURATION SET TSQL_SCALAR_UDF_INLINING = OFF;- 我们还可以通过指定查询提示来禁用特定查询的标量UDF内联:
DISABLE_TSQL_SCALAR_UDF_INLINING
在此示例中,我们使用以下参数禁用了UDF内联
'OPTION(USE HINT ('DISABLE_TSQL_SCALAR_UDF_INLINING'))'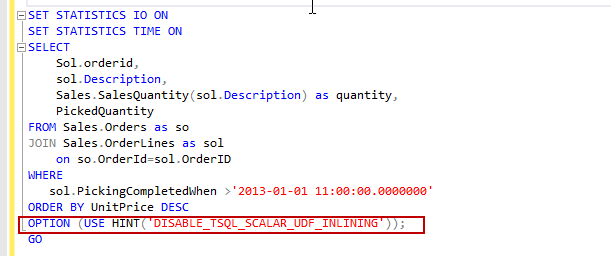
注意:如果我们已为标量UDF内联启用数据库作用域配置,并使用查询提示在查询级别禁用此功能,则SQL Server将优先提示数据库作用域配置或兼容性级别设置。
创建标量UDF时,我们可以指定也关闭此功能。我们需要在以下示例中指定WITH INLINE = OFF
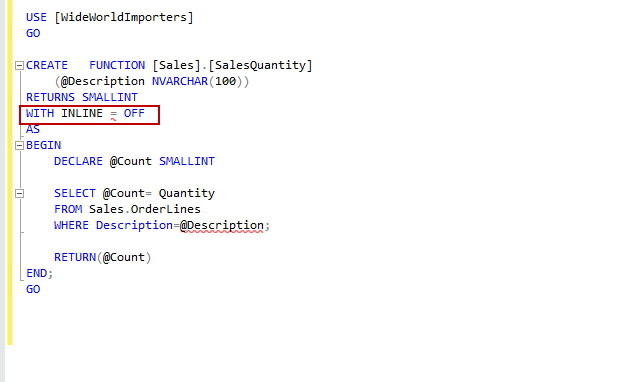
默认情况下,在SQL Server 2019中启用了标量UDF内联,因此,我们不需要指定参数WITH INLINE = ON。如果需要,可以指定它。
结论:
在本文中,我们探讨了由于内联导致标量UDF的显着性能改进。这些增强功能会给开发人员和管理员带来微笑。
SQL Server 2019 中标量用户定义函数性能的改进的更多相关文章
- Sql server 浅谈用户定义表类型
1.1 简介 SQL Server 中,用户定义表类型是指用户所定义的表示表结构定义的类型.您可以使用用户定义表类型为存储过程或函数声明表值参数,或者声明您要在批处理中或在存储过程或函数的主体中使用的 ...
- SQL Server 2019 新版本
2019 年 11 月 4 日,微软在美国奥兰多举办的 Ignite 大会上发布了关系型数据库 SQL Server 的新版本.与之前版本相比,新版本的 SQL Server 2019 具备以下重要功 ...
- SQL Server 2019 新函数Approx_Count_Distinct
2019年11月4日微软发布了2019正式版,该版本有着比以往更多强大的新功能和性能上的优势,可参阅SQL Server 2019 新版本. SQL Server 2019具有一组丰富的增强功能和新功 ...
- 微软SQL Server 2019 全新发布,更新内容亮点都在这里了
IT之家11月7日消息 在Microsoft Ignite 2019 大会上,微软正式发布了新一代数据库产品SQL Server 2019.使用统一的数据平台实现业务转型SQL Server 20 ...
- SQL Server 2019企业版和标准版的区别?
来源公众号:SQL数据库运维 原文链接:https://mp.weixin.qq.com/s?__biz=MzI1NTQyNzg3MQ==&mid=2247485400&idx=1&a ...
- 应用C#和SQLCLR编写SQL Server用户定义函数
摘要: 文档阐述使用C#和SQLCLR为SQL Server编写用户定义函数,并演示用户定义函数在T-SQL中的应用.文档中实现的 Base64 编码解码函数和正则表达式函数属于标量值函数,字符串分割 ...
- 调试SQL Server的存储过程及用户定义函数
分类: 数据库管理 2005-06-03 13:57 9837人阅读 评论(5) 收藏 举报 sql server存储vb.net服务器sql语言 1.在查询分析器中调试 查询分析器中调试的步骤如下: ...
- SQL Server中授予用户查看对象定义的权限
SQL Server中授予用户查看对象定义的权限 在SQL Server中,有时候需要给一些登录名(用户)授予查看所有或部分对象(存储过程.函数.视图.表)的定义权限存.如果是部分存储过程.函数. ...
- 【翻译】Flink Table Api & SQL — 用户定义函数
本文翻译自官网:User-defined Functions https://ci.apache.org/projects/flink/flink-docs-release-1.9/dev/tabl ...
随机推荐
- 指针*和取地址&函数输入使用
函数输入问题: 1 带&和不带& (参数本身还是拷贝一份参数) 2 函数输入指针 #include <iostream> using namespace std; int ...
- Longest Common Substring II SPOJ - LCS2 (后缀自动机)
Longest Common Substring II \[ Time Limit: 236ms\quad Memory Limit: 1572864 kB \] 题意 给出\(n\)个子串,要求这\ ...
- pytcharm无法debug:pydev debugger: process 15188 is connecting
今天问老师,老师说需要设置断点,果然设置断点后就可以正常调试了.
- <每日 1 OJ> -LeetCode 7. 整数反转
题目描述 给定一个 32 位有符号整数,将整数中的数字进行反转. 示例 1: 输入: 123 输出: 321 示例 2: 输入: -123 输出: -321 示例 3: 输入: 120 输出: 21 ...
- [Beta阶段]第八次Scrum Meeting
Scrum Meeting博客目录 [Beta阶段]第八次Scrum Meeting 基本信息 名称 时间 地点 时长 第八次Scrum Meeting 19/05/14 大运村寝室6楼 25min ...
- 1045-Access denied for user 'root'@'localhost'解决方法
1.出现这个问题的原因之一是权限的问题,也就是说你的电脑可能没有权限访问mysql数据库. 讲道理这种情况其实基本上不该遇到,因为我们在安装mysql之后,root其实是有最高权限的,而且很少会有人去 ...
- Linux下如何测试网速
本文链接:https://blog.csdn.net/Beyond_F4/article/details/80497118在Linux下如何测量下载和上传的速度? 这里用到一个Python工具spee ...
- eclispe: 修改所有文件默认编码为UTF-8
1.修改 workspace text file encoding 依次点击windows -> Preferences -> general -> Workspace,修改如图的编 ...
- Sequelize模糊查询
const Sequelize = require('sequelize'); const Op = Sequelize.Op; User.findAll({ raw: true, order: [ ...
- bootcss 之 .table-hover 类 鼠标悬停
通过添加 .table-hover 类可以让 <tbody> 中的每一行对鼠标悬停状态作出响应. <table class="table table-hover" ...