Learning Conditioned Graph Structures for Interpretable Visual Question Answering
Learning Conditioned Graph Structures for Interpretable Visual Question Answering
2019-05-29 00:29:43
Code:https://github.com/aimbrain/vqa-project
1. Background and Motivation:
最近的计算机视觉工作开始探索图像的高层表达(higher level representation of images),特别是利用 object detector 以及 graph-based structures 以进行更好的语义和空间图像理解。将图像表达为 graphs,可以显示的进行模型交互,通过 graph iterms(objects in the image) 无缝进行信息的迁移。这种基于 graph 的技术已经在最近的 VQA 任务上应用上。这种方法的一个缺点是:the input graph structures are heavily engineered, image specific rather than question specific, and not easily transferable from abstract scenes to real images. 此外,very few approaches provide means to interpret the model's behavior, an essential aspect that is often lacking in deep learning models.

本文贡献:现有的 VQA 方法并没有尝试建模不同物体之间的 semantic connections, 所以,本文尝试通过引入一个先验,来解决该问题。
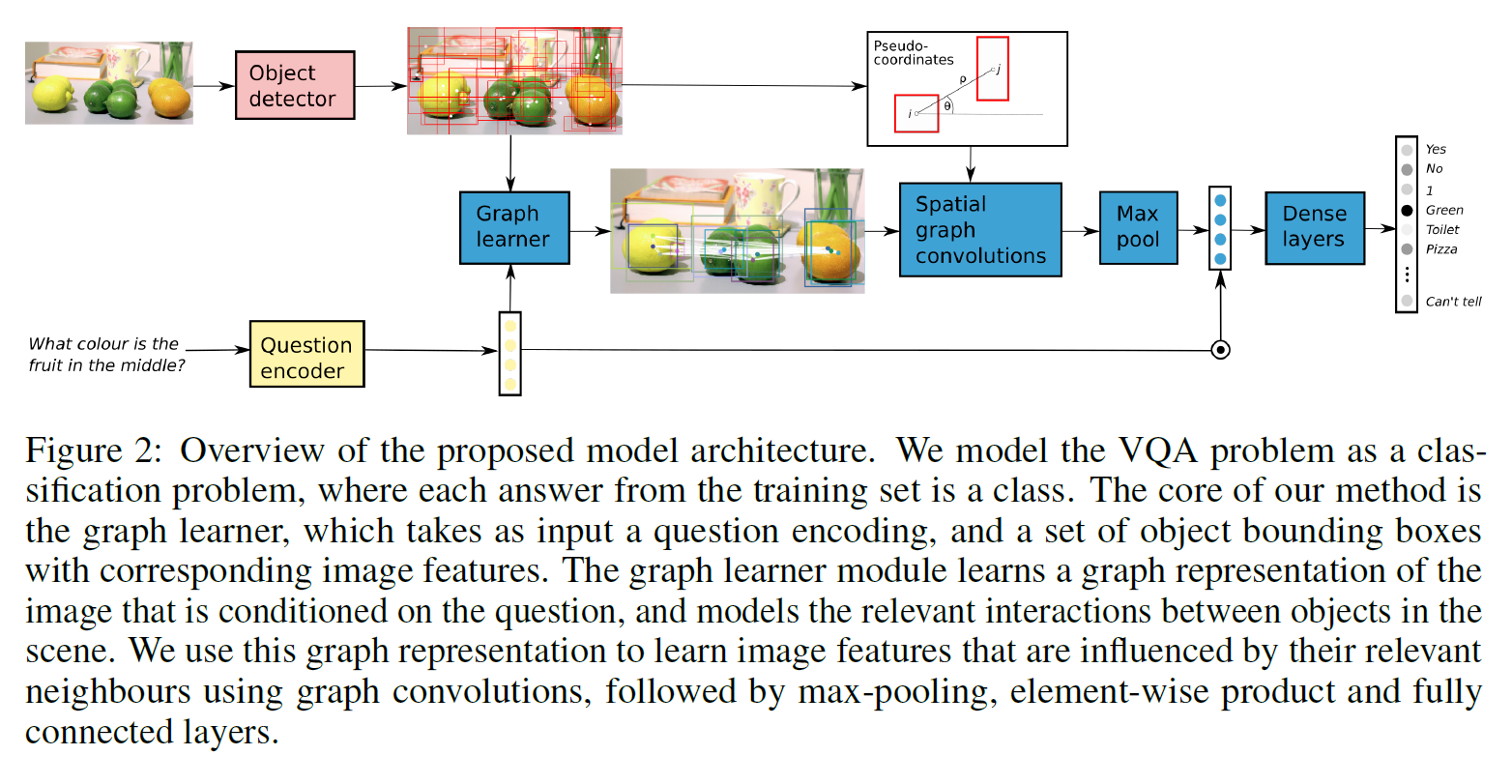
2. The Proposed Method :
本文所提出的方法如图 2 所示。我们开发了一种 DNN 可以将 spatial,image and textual features 以一种新颖的方式进行组合,进行问题的回答。我们的模型首先利用 Word embedding 和 RNN 模型来计算得到问题的表达,以及一系列的物体描述(object descriptor),包括:bounding box corrdinates, image features vectors。我们的 graph learning module 然后基于给定的问题,去学习一个 adjacency matrix。这个邻接矩阵确保下一层 -the spatial graph convolutions- 可以使其不但聚焦于 the objects,而且可以聚焦在于问题相关的物体关系上。我们卷积图特征,随后经过 max-pooling,与 question embedding 组合在一起,利用一个简单的元素级相乘,从而可以预测一个答案。
2.1 Computing model inputs :
第一个阶段是:计算输入图像和问题的 embedding。我们将给定的图像,用物体检测算法转换为 K 个 visual features。物体检测模型是我们方法的必要步骤,因为每一个 bounding box 都将在 question specific graph representations 上作为一个节点。对于每一个提出的 bounding box 都将会有一个 embedding,即:对应区域的卷积特征。利用这种 object features 在其他工作中已经被证明可以提升 VQA 的效果,因为这使得模型可以聚焦于 object-level feature,而不仅仅是 CNN feature。对于每一个 question,我们利用一个 pre-trained Word embeddings 将问题转换为向量。然后用动态 GRU 模型,来进一步将句子编码为向量 q。
2.2 Graph Learner :
本小结是全文最重要的贡献部分了:图学习模块(the graph learner module)。该模块产生了一个基于 question 的图像的 graphical representation。该模块是比较 general 的,并且容易实现,学习到的复杂 feature 之间的关系,是可解释的且问题相关的。学习到的 graph structure 通过定义的 node neighborhoods 来驱动空间图卷积,允许 unary 和 pairwise attention 可以被很自然的的学习到,因为 adjacency matrix 包含 self loops。
我们想构建一个无向图 g = {V, E, A},E 是边的集合,A 是对应的邻接矩阵。每一个顶点 v 对应的是检测到的物体(包围盒的坐标 以及 特征向量)。我们想学习一个邻接矩阵 A,使得每一个 edge $(i, j, A_{ij})$ 是基于问题特征 q 。直观的来讲,我们需要建模 feature vectors 之间的相似性,及其他们与 given question 之间的相关性。所以,我们将 question embedding q 与每一个 visual features $v_n$ 进行组合,得到 $[v_n][q]$。我们然后计算该联合映射:
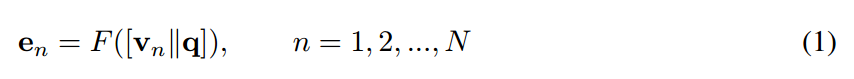
其中,F 是非线性函数。通过将该 joint embedding $e_n$ 进行组合,得到矩阵 E,这样就可以定义一个邻接矩阵,带有 self loops,$A = EE^T$,其中,$A_{i,j} = e^T_i e_j$。
这种定义不会在图的稀疏性上有额外的约束,所以,可以产生一个全连接的邻接矩阵。这种学习到的 graph structure 将会被当做是接下来 图卷积层的 backbone,目标是:learn a representation of object features that is conditioned on the most relevant, question-specific neighbours。这需要该 sparse graph structure 聚焦于图像中最相关的部分。为了学习一个每一个节点的稀疏邻接系统,我们采用 ranking 的方法:

其中,topm 返回的是:输入向量中前 m 个最大值的索引,$a_i$ 表示的是邻接矩阵的第 i 行。换句话说,给定节点的邻接系统将会对应与该节点有最强链接的 nodes。
2.3 Spatial Graph Convolutions:
给定一个特定问题的 graph structure,我们探索一种图卷积的方法去学习一种新的目标表达(that are informed by a neighborhood system tailored to answer the given question)。图的顶点 V (BBox 的位置及其 feature)可以通过他们的在图像中的位置进行刻画,可以在空间上对他们的联系进行建模。此外,许多 VQA 问题需要该模型有关于:the model has an awareness of the orientation and relative position of features in an image, 但是许多之前的方法都忽略了这一点。
我们使用一种 graph CNN 方法,直接在 graph domain 上依赖于空间关系直接进行操作。关键的是,他们的方法通过 pairwise pseudo-coordinate function u(i, j) 来捕获 spatial information,对于每一个 vertex i,以 i 为坐标系统,u(i, j) 是那个系统中的 vertex j 的坐标。我们的 pseudo-coordinate function u(i, j) 返回了一个极坐标向量 $\ro, \theta$,表述了顶点 i 和 j 的 BBox 的空间相对位置。我们将 Cartesian 和 Polar 坐标作为 Gaussian kernels 的输入,并且观察看:polar coordinates 效果更好。我们认为这是因为极坐标分为:方向和距离,提供了两个角度来表示空间关系。
一个特别的步骤和挑战是:the definition of a patch operator describing the influence of each neighbouring node that is robust to irregular neighbourhood structures. Monti et al. 提出使用 K个 可学习均值和协方差的 Gaussian kernels,均值可以理解为 pseudo coordinate 的方向和距离。对每一个 k,我们得到一个 kernel weight $w_k(u)$,the patch operator is defined at kernel k for node i as:
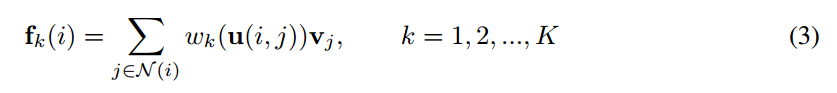
其中,$f_n(i)$ 和 $N(i)$ 代表如公式 2 所示的顶点 i 的近邻,我们将每一个 patch operator 的输出看做是:近邻特征的加权求和(a weighted sum of the neighbouring features), 高斯核的集合描述了每一个近邻在卷积操作输出时的影响。
我们调整 patch operator 使其包含一个额外的基于产生的 graph edges 的加权因子:
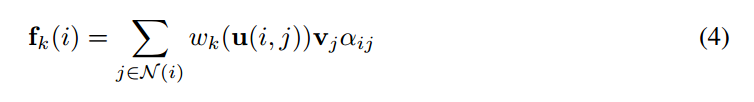
$\alpha_{ij} = s(a_i)_j$,$s(.)_j$ 是一个 scaling function 的第 j 个元素 (此处定义为 a softmax of the selected adjacency matrix elements)。这种更加 general 的形式意味着不同顶点之间的信息传递的强度可以通过除了空间位置之外的信息进行加权。在本文的模型中,可以理解为:根据回答问题的情况,我们应该对两个 nodes 之间的关系关注多少。所以,该网络学习基于问题以 pairwise 的方式去关注 visual features。
最终,我们定义在顶点 i 的卷积操作的输出为,K 个 kernels 的组合:

其中,每一个 $G_k$ 是一个可学习权重矩阵(即:卷积核)。这可以输出一个卷积后的图表示 H。
2.4 Prediction Layers :
通过上述步骤,我们可以得到考虑结构化建模的特征输出,然后就可以进行答案的预测了。本文的做法是通过 max-pooling layer 得到 graph $h_{max}$ 的 global vector representation。作者将问题特征 q 和 image $h_{max}$ 通过一个元素级相乘进行融合。然后用两层 MLP 来计算分类得分。
2.5 Loss Function:
损失函数一般是采用交叉熵损失函数进行。作者采用和 [Tips and tricks for visual question answering: Learnings from the 2017 challenge] 类似的方法来处理。
3. Experiments:
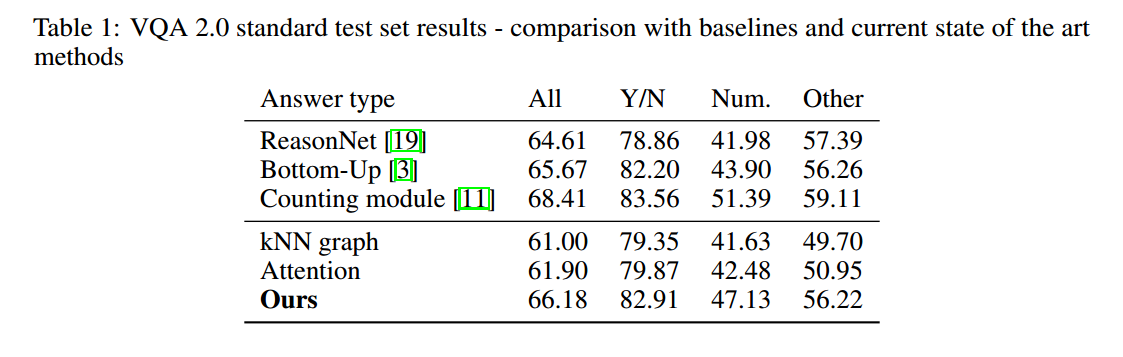

==
Learning Conditioned Graph Structures for Interpretable Visual Question Answering的更多相关文章
- 论文笔记:Visual Question Answering as a Meta Learning Task
Visual Question Answering as a Meta Learning Task ECCV 2018 2018-09-13 19:58:08 Paper: http://openac ...
- 论文阅读:Learning Visual Question Answering by Bootstrapping Hard Attention
Learning Visual Question Answering by Bootstrapping Hard Attention Google DeepMind ECCV-2018 2018 ...
- Visual Question Answering with Memory-Augmented Networks
Visual Question Answering with Memory-Augmented Networks 2018-05-15 20:15:03 Motivation: 虽然 VQA 已经取得 ...
- 【自然语言处理】--视觉问答(Visual Question Answering,VQA)从初始到应用
一.前述 视觉问答(Visual Question Answering,VQA),是一种涉及计算机视觉和自然语言处理的学习任务.这一任务的定义如下: A VQA system takes as inp ...
- Hierarchical Question-Image Co-Attention for Visual Question Answering
Hierarchical Question-Image Co-Attention for Visual Question Answering NIPS 2016 Paper: https://arxi ...
- 论文:Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering-阅读总结
Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering-阅读总结 笔记不能简单的抄写文中 ...
- 第八讲_图像问答Image Question Answering
第八讲_图像问答Image Question Answering 课程结构 图像问答的描述 具备一系列AI能力:细分识别,物体检测,动作识别,常识推理,知识库推理..... 先要根据问题,判断什么任务 ...
- 论文笔记之:Learning Multi-Domain Convolutional Neural Networks for Visual Tracking
Learning Multi-Domain Convolutional Neural Networks for Visual Tracking CVPR 2016 本文提出了一种新的CNN 框架来处理 ...
- Deep Learning of Graph Matching 阅读笔记
Deep Learning of Graph Matching 阅读笔记 CVPR2018的一篇文章,主要提出了一种利用深度神经网络实现端到端图匹配(Graph Matching)的方法. 该篇文章理 ...
随机推荐
- ORACLE 清理SYSAUX表空间
在数据库检查中发现SYSAUX表空间占用过大,SYSAUX是ORACLE10G开始提供的功能,用于数据库为SYSTEM表空间减负. 用以下语句查出相应的表空间值 select a.tablespace ...
- django获取数据queryset中的filter选项
2.条件选取querySet的时候,filter表示=,exclude表示!=. querySet.distinct() 去重复__exact 精确等于 like 'aaa' __iexact 精确等 ...
- 新添加的磁盘大于2T 的分区方法
环境CentOS7.1 2.9t磁盘 fdisk 只能分区小于2t的磁盘,大于2t的话,就要用到parted 1,将磁盘上原有的分区删除掉: 进入:#parted /dev/sdb 查看:(par ...
- MVC模式:action、dao、model、service、util
这就是一个典型的MVC: action:主要是Struts2,用来做跳转,比如jsp页面提交的表单就是进入到action里面,然后action再调用service里面的逻辑,最后返回到jsp响应请求. ...
- 传入json字符串的post请求
/** * 传入json字符串的post请求 * @Title: getRequsetData * @Description: TODO * @param @param url * @param @p ...
- docker安装之mariadb
https://hub.docker.com/_/mariadb?tab=description Supported tags and respective Dockerfile links 10.4 ...
- MPU-6050
MPU-6000(6050)为全球首例整合性6轴运动处理组件,相较于多组件方案,免除了组合陀螺仪与加速器时间轴之差的问题,减少了大量的封装空间.当连接到三轴磁强计时,MPU-60X0提供完整的9轴运动 ...
- vetur 和 npm run lint 格式化不一致
vetur 的 template(html) 默认使用的格式化插件是 prettyhtml,虽然可以选 prettier,和 npm run lint 的格式化保持一致,但是有时候会影响到 scrip ...
- js弹窗输入
<html> <head> <title>js输入对话框</title> </head> <body> <script l ...
- Visual Studio 各版本对应关系
Known Name Version Latest KB / Revision Visual Studio 6 6 Service Pack 6; 6.0.3790.0; VB6.0-KB290887 ...