influxDB应用及TICK stack
InfluxData平台用于处理度量和事件的时间序列平台,常被称为TICK stack,包含4个组件:Telegraf,influxDB,Chronograf和Kapacitor,分别负责时间序列数据的:data collection,data storage,data visualization,和data processing and alerting。
一. 基础
1. 基础概念
influxdb是时间序列数据库,与常用的关系数据库模型不同。以下列采样数据为例介绍。
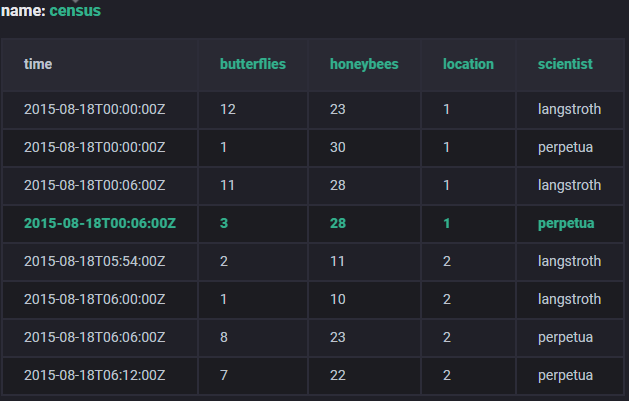
time:influxdb是时间序列数据库,所有都与time相关,time列存储timestamp,显示日期和时间,遵循RFC3339 UTC格式。
database:通用概念,管理一系列相关数据的集合,包含users,数据等,针对influxdb,包含users,retention policies,continuous queries和time series data。
measurement:一类数据的集合,与关系数据库的table等同。measurement的名字是strings。采样数据的measurement是census。
point:一条数据,Each point is uniquely identified by its series and timestamp。每条influxdb数据写规则遵循line protocal:
<measurement>[,<tag-key>=<tag-value>...] <field-key>=<field-value>[,<field2-key>=<field2-value>...] [unix-nano-timestamp]
与采样数据的每行相对应。
tag:用于存储metadata,用于标记数据。tags是键值对,由tag keys和tag values组成。采用数据中tag keys是location和scientist,tag key location的tag values是1和2,tag key scientist的tag values是langstroth和perpetua。tags是可索引的(indexed),可根据tags进行快速查询。tags是可选的,可以不含有tags。
tag set:不同tag键值对的组合,采样数据中有四个tag set:
l location = 1, scientist = langstroth
l location = 2, scientist = langstroth
l location = 1, scientist = perpetua
l location = 2, scientist = perpetua
field:存储数据,键值对,由field keys和field values组成,采样数据中field key是butterflies和honeybees,field values记录数量。field keys是string,field values可为strings,floats,integers或者Booleans。对influxdb每条数据,fields是必有的。fields不可索引,这意味着以field过滤数据时必须扫描measurement所有数据,效率不高。一般情况下,field不应包含元数据。
field set:field-key和field-value的集合。每条记录(point)的field-key和field-value是一条field set。
RP,retention policy:保存策略。描述数据保存多久(duration)和数据保存几份(replication)。一般为autogen retention policy:an infinite duration and a replication factor set to one。
series:数据的集合,共享同一retention policy、measurement、tag set。采样数据中包含4组series:
l series 1 autogen census location = 1,scientist = langstroth
l series 2 autogen census location = 2,scientist = langstroth
l series 3 autogen census location = 1,scientist = perpetua
l series 4 autogen census location = 2,scientist = perpetua
2. 扩展概念
batch:批处理,与通用概念相同。A collection of points in line protocol format, separated by newlines (0x0A). A batch of points may be submitted to the database using a single HTTP request to the write endpoint. influxdb推荐batch大小为5000-10000 points。
CQ:continuous query,An InfluxQL query that runs automatically and periodically within a database. 在一个数据库中自动周期运行的数据查询。
now():The local server’s nanosecond timestamp.
schema:How the data are organized in InfluxDB. The fundamentals of the InfluxDB schema are databases, retention policies, series, measurements, tag keys, tag values, and field keys.
wal:write ahead log,The temporary cache for recently written points. To reduce the frequency with which the permanent storage files are accessed, InfluxDB caches new points in the WAL until their total size or age triggers a flush to more permanent storage. This allows for efficient batching of the writes into the TSM.
tsm:Time Structured Merge tree,The purpose-built data storage format for InfluxDB. TSM allows for greater compaction and higher write and read throughput than existing B+ or LSM tree implementations.
3. InfluxQL
InfluxQL是一种类似SQL的查询语言,用于与influxdb中的数据进行交互。详细语法见https://docs.influxdata.com/influxdb/v1.7/query_language/。
1.select
SELECT <field_key>[,<field_key>,<tag_key>] FROM <measurement_name>[,<measurement_name>]
l 当包含tag_key时必须指定一个field_key。
l <database_name>.<retention_policy_name>.<measurement_name> 限定measurement
l <database_name>..<measurement_name> 采用默认(default)retention policy
l 推荐用双引号将field/tag/measurement等引用。
l "<field_key>"::field,"<tag_key>"::tag 当field和tag有相同名字时,用于指定名称是field还是tag
SELECT_clause FROM_clause WHERE <conditional_expression> [(AND|OR) <conditional_expression> [...]]
2. where
where基于fields/tags/timestamps过滤数据,the default time range is between 1677-09-21 00:12:43.145224194 and 2262-04-11T23:47:16.854775806Z UTC. For SELECT statements with a GROUP BY time() clause, the default time range is between 1677-09-21 00:12:43.145224194 UTC and now().
l SELECT * FROM "h2o_feet" WHERE time > now() - 7d
l SELECT * FROM "h2o_feet" WHERE "water_level" + 2 > 11.9
3. group by
Group by支持tags或时间间隔分组
SELECT_clause FROM_clause [WHERE_clause] GROUP BY [* | <tag_key>[,<tag_key]]
SELECT <function>(<field_key>) FROM_clause WHERE <time_range> GROUP BY time(<time_interval>),[tag_key] [fill(<fill_option>)]
SELECT <function>(<field_key>) FROM_clause WHERE <time_range> GROUP BY time(<time_interval>,<offset_interval>),[tag_key] [fill(<fill_option>)]
4. info
INFO写查询结果到指定measurement
SELECT_clause INTO <measurement_name> FROM_clause [WHERE_clause] [GROUP_BY_clause]
l INTO <database_name>.<retention_policy_name>.<measurement_name>
l INTO <database_name>.<retention_policy_name>.:MEASUREMENT FROM /<regular_expression>/
Writes data to all measurements in the user-specified database and retention policy that match the regular expressionin the FROM clause. :MEASUREMENT is a backreference to each measurement matched in the FROM clause.
5. order by
ORDER BY time DESC反序显示数据
SELECT_clause [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] ORDER BY time DESC
6. limit
LIMIT/SLIMIT限定points和series数量
SELECT_clause [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] LIMIT <N>
SELECT_clause [INTO_clause] FROM_clause [WHERE_clause] GROUP BY *[,time(<time_interval>)] [ORDER_BY_clause] LIMIT <N1> SLIMIT <N2>
7. tz
The tz() clause returns the UTC offset for the specified timezone.
SELECT_clause [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause] tz('<time_zone>')
l SELECT "water_level" FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:18:00Z' tz('America/Chicago')
8. 数据类型指定
SELECT_clause <field_key>::<type> FROM_clause
type可以为float,integer,string,或boolean。
9. 数据类型转换
SELECT_clause <field_key>::<type> FROM_clause
type可为float或integer。
10. 多语句查询用分号(;)分割。
11. 子查询
SELECT_clause FROM ( SELECT_statement ) [...]
SELECT_clause FROM ( SELECT_clause FROM ( SELECT_statement ) [...] ) [...]
二. influxdata平台安装
两种体验方式:本地安装或docker安装。
1. 本地安装
在Ubuntu16.04上可直接从influxdata仓库中https://repos.influxdata.com/ubuntu/pool/stable/下载编译好的deb包通过如下命令安装:
sudo dpkg -i <package_name>
软件包版本号及端口如下:
|
name |
version |
port |
config file |
|
telegraf |
1.11.0 |
/etc/telegraf/telegraf.conf |
|
|
influxdb |
1.7.6 |
8086 HTTP API 8088 RPC 8083 web |
/etc/influxdb/influxdb.conf |
|
chronograf |
1.7.12 |
8888 web |
|
|
kapacitor |
1.5.2 |
9092 HTTP API |
/etc/kapacitor/kapacitor.conf |
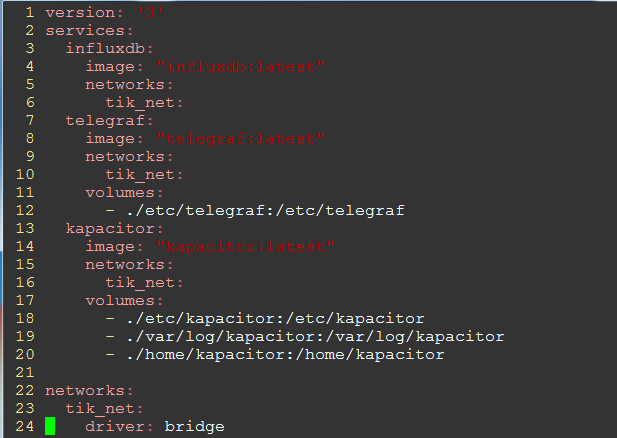
2. docker安装
参考https://docs.influxdata.com/kapacitor/v1.5/introduction/install-docker/部署,https://docs.influxdata.com/downloads/tik-docker-tutorial.tar.gz下载docker-compose相关文件。
本部署方案中包括三个组件influxdb、telegraf和kapacitor,不包含chronograf。
三. influxdb使用
有三种方式可访问influxdb:命令行(command line interface),库(client library)和HTTP API。
命令行
influxDB安装包默认包含cli工具influx,可直接输入命令启动influx:
$influx
$ influx -precision rfc3339
Connected to http://localhost:8086 version 1.7.6
InfluxDB shell version: 1.7.
Enter an InfluxQL query
> help
Usage:
connect <host:port> connects to another node specified by host:port
auth prompts for username and password
pretty toggles pretty print for the json format
chunked turns on chunked responses from server
chunk size <size> sets the size of the chunked responses. Set to to reset to the default chunked size
use <db_name> sets current database
format <format> specifies the format of the server responses: json, csv, or column
precision <format> specifies the format of the timestamp: rfc3339, h, m, s, ms, u or ns
consistency <level> sets write consistency level: any, one, quorum, or all
history displays command history
settings outputs the current settings for the shell
clear clears settings such as database or retention policy. run 'clear' for help
exit/quit/ctrl+d quits the influx shell show databases show database names
show series show series information
show measurements show measurement information
show tag keys show tag key information
show field keys show field key information A full list of influxql commands can be found at:
https://docs.influxdata.com/influxdb/latest/query_language/spec/
> show databases
name: databases
name
----
telegraf
_internal
> use telegraf
Using database telegraf
> show measurements
name: measurements
name
----
cpu
disk
diskio
kernel
mem
processes
swap
system
> show series
key
---
cpu,cpu=cpu-total,host=ubuntu-wang
cpu,cpu=cpu0,host=ubuntu-wang
cpu,cpu=cpu1,host=ubuntu-wang
disk,device=sda1,fstype=ext4,host=ubuntu-wang,mode=rw,path=/
disk,device=sda1,fstype=ext4,host=ubuntu-wang,mode=rw,path=/var/lib/kubelet
disk,device=sda1,fstype=ext4,host=ubuntu-wang,mode=rw,path=/var/lib/rancher/volumes
diskio,host=ubuntu-wang,name=loop0
diskio,host=ubuntu-wang,name=sda
diskio,host=ubuntu-wang,name=sda1
diskio,host=ubuntu-wang,name=sda2
diskio,host=ubuntu-wang,name=sda5
kernel,host=ubuntu-wang
mem,host=ubuntu-wang
processes,host=ubuntu-wang
swap,host=ubuntu-wang
system,host=ubuntu-wang
> select * from cpu limit
name: cpu
time cpu host usage_guest usage_guest_nice usage_idle usage_iowait usage_irq usage_nice usage_softirq usage_steal usage_system usage_user
---- --- ---- ----------- ---------------- ---------- ------------ --------- ---------- ------------- ----------- ------------ ----------
--24T07::20Z cpu-total ubuntu-wang 95.42682926828536 0.25406504065046054 0.20325203252035398 1.8800813008130035 2.235772357723244
--24T07::20Z cpu0 ubuntu-wang 95.24291497978086 0.20242914979758425 0.3036437246964483 1.8218623481786898 2.429149797571011
常用命令:
help:显示帮助信息及命令
show databases:显示所有数据库
use <db_name>:设置当前数据库
show measurements:显示数据库中所有表(measurements)
insert:插入数据
select:查询数据
exit:退出命令行
注:数据插入查询可使用SQL语句完成,可参考https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/
参考:
1. https://docs.influxdata.com/ https://github.com/influxdata/docs.influxdata.com
2. https://docs.influxdata.com/influxdb/v1.7/concepts/key_concepts/ 基础概念
3. https://docs.influxdata.com/influxdb/v1.7/tools/api/ HTTP API
4. https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/ SELECT
5. https://jasper-zhang1.gitbooks.io/influxdb/content/ 中文文档
6. https://repos.influxdata.com/ 不同系统安装包下载
influxDB应用及TICK stack的更多相关文章
- 再不懂时序就 OUT 啦!,DBengine 排名第一时序数据库,阿里云数据库 InfluxDB 正式商业化!
云数据库 InfluxDB® 版介绍 阿里云数据库 InfluxDB® 版已于近日正式启动商业化 . 云数据库 InfluxDB® 是基于当前最流行的开源数据库 InfluxDB 提供的在线数据库服务 ...
- 下一个计划 : .NET/.NET Core应用性能管理系统
前言 最近几个月一直在研究开源的APM和监控方案,并对比使用了Zipkin,CAT,Sky-walking,PinPoint(仅对比,未实际部署),Elastic APM,TICK Stack,Pro ...
- Telegraf安装与介绍
Telegraf 是什么? Telegraf 是一个用 Go 编写的代理程序,是收集和报告指标和数据的代理.可收集系统和服务的统计数据,并写入到 InfluxDB 数据库.Telegraf 具有内存占 ...
- 打造“云边一体化”,时序时空数据库TSDB技术原理深度解密
本文选自云栖大会下一代云数据库分析专场讲师自修的演讲——<TSDB云边一体化时序时空数据库技术揭秘> 自修 —— 阿里云智能数据库产品事业部高级专家 认识TSDB 第一代时序时空数据处理工 ...
- 云栖深度干货 | 打造“云边一体化”,时序时空数据库TSDB技术原理深度解密
本文选自云栖大会下一代云数据库分析专场讲师自修的演讲——<TSDB云边一体化时序时空数据库技术揭秘> 自修 —— 阿里云智能数据库产品事业部高级专家 认识TSDB 第一代时序时 ...
- TICK技术栈(三)InfluxDB安装及使用
1.什么是InfluxDB? InfluxDB是一个用Go语言开发的时序数据库,用于处理高写入和查询负载,专门为带时间戳的数据编写,对DevOps监控,IoT监控和实时分析等应用场景非常有用.通过自定 ...
- 【ELK Stack】ELK+KafKa开发集群环境搭建
部署视图 运行环境 CentOS 6.7 x64 (2核4G,硬盘100G) 需要的安装包 Runtime jdk1.8 : jdk-8u91-linux-x64.gz (http://www.ora ...
- Monitoring and Tuning the Linux Networking Stack: Receiving Data
http://blog.packagecloud.io/eng/2016/06/22/monitoring-tuning-linux-networking-stack-receiving-data/ ...
- 性能测试监控:Jmeter +InfluxDB +collectd +Grafana
虚拟机ip 192.168.180.128 Influxdb Influxdb是一个开源的分布式时序.时间和指标数据库,使用go语言编写,无需外部依赖. 它有三大特性: 时序性(Time Series ...
随机推荐
- 怎样在sql server profiler跟踪时只显示自己关心的内容
当我们想知道.net程序到底执行了哪些SQL的时候,通常会使用sql server profiler,但是如果不加设置,我们程序执行的sql通常会被系统的SQL淹没,通过以下的方法,可以只显示我们需要 ...
- springboot 80转443
application.yml 中配置https证书信息 向spring容器中注入两个Bean,代码如下 import java.util.Map; import org.apache.catalin ...
- 【SSH进阶之路】Hibernate系列——总结篇(九)
这篇博文是Hibernate系列的最后一篇,既然是最后一篇,我们就应该进行一下从头到尾,整体上的总结,将这个系列的内容融会贯通. 概念 Hibernate是一个对象关系映射框架,当然从分层的角度看,我 ...
- Properties的有序读写
使用java.util.Properties提供的类,读取properties文件的时候,读出来的是乱序的 如下边的情况 import java.io.*; import java.util.Arra ...
- ASP.NET Core 之跨平台的实时性能监控
前言 前面我们聊了一下一个应用程序 应该监控的8个关键位置. . 嗯..地址如下: 应用程序的8个关键性能指标以及测量方法 最后卖了个小关子,是关于如何监控ASP.NET Core的. 今天我们就来讲 ...
- Java的三大版本
Java的三大版本 Write Once.Run Anywhere JavaSE:标准版(桌面程序,控制台开发......) JavaME:嵌入式开发(手机,小家电......) JavaEE:E企业 ...
- 在ensp中的acl控制
原理 实验模拟 实验拓扑 相关参数 我们在每一台路由器上设置ospf服务,使其互相能通 下面我们配置基本ACL控制访问 配置完成后,尝试在R1上建立telent连接 但是这样设置是不安全的,只要是直连 ...
- 说说Java Web中的Web应用程序|乐字节
大家好,我是乐字节的小乐,今天接着上期文章<Javaweb的概念与C/S.B/S体系结构>继续往下介绍Java Web ,这次要说的是web应用程序. 1. Web 应用程序的工作原理 W ...
- Hyperledger Fabric 入门 first-network 搭建
1.准备环境: 安装git.docker.curl.go [root@test_vonedao_83 fabric]# git --version git version 1.8.3.1 [root@ ...
- node-sass 报错