hadoop进阶---hadoop性能优化(一)---hdfs空间不足的管理优化
Hadoop 空间不足,hive首先就会没法跑了,进度始终是0%。
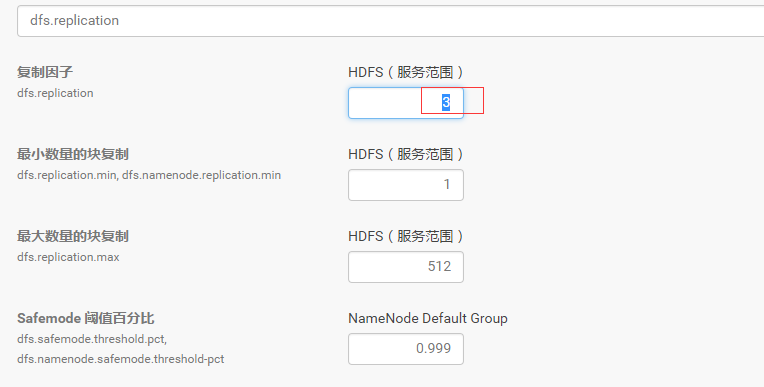
将HDFS备份数降低
将默认的备份数3设置为2。
步骤:CDH–>HDFS–>配置–>搜索dfs.replication–>设置为2
删除无用HDFS数据和Hbase表格
主要使用命令hadoop fs -du,hadoop fs -ls,hadoop fs -rm
空间不足根本的解决办法自然是清理空间。但是清理空间也要有步骤。
检查总体情况
hadoop dfsadmin -report
检查每个目录
hdfs dfs -du-h/
删除表
先清理数据表,去hive,impala里删除表
进入hive shell;
使用命令
droptable tablename;
清理完表之后,删除文件
使用命令
hadoop fs -rm -skipTrash filename;
hadoop fs -rmr -skipTrash directoryname;
删除的时候要注意使用-skipTrash选项,否则不会马上删除,而是转到垃圾桶了
删除本机linux无用文件
使用命令找出大于1G的文件看看哪些是可以删除的
M -execls -lh {} \;
清理Trash回收站
使用命令
hadoop fs -rmr-skipTrash /user/root/.Trash;
或者
hdfs dfs -expunge ;
执行完-expunge命令后,回收站的数据不会立即被清理,而是先打了一个checkpoint。显示的是一分钟后清除。
实际验证,11T的数据需要好几分钟…..
和Linux系统的回收站设计一样,HDFS会为每一个用户创建一个回收站目录:/user/用户名/.Trash/,每一个被用户通过Shell删除的文件/目录,在系统回收站中都一个周期,也就是当系统回收站中的文件/目录在一段时间之后没有被用户回复的话,HDFS就会自动的把这个文件/目录彻底删除,之后,用户就永远也找不回这个文件/目录了。在HDFS内部的具体实现就是在NameNode中开启了一个后台线程Emptier,这个线程专门管理和监控系统回收站下面的所有文件/目录,对于已经超过生命周期的文件/目录,这个线程就会自动的删除它们,不过这个管理的粒度很大。另外,用户也可以手动清空回收站,清空回收站的操作和删除普通的文件目录是一样的,只不过HDFS会自动检测这个文件目录是不是回收站,如果是,HDFS当然不会再把它放入用户的回收站中了
根据上面的介绍,用户通过命令行即HDFS的shell命令删除某个文件,这个文件并没有立刻从HDFS中删除。相反,HDFS将这个文件重命名,并转移到操作用户的回收站目录中(如/user/hdfs/.Trash/Current, 其中hdfs是操作的用户名)。如果用户的回收站中已经存在了用户当前删除的文件/目录,则HDFS会将这个当前被删除的文件/目录重命名,命名规则很简单就是在这个被删除的文件/目录名后面紧跟一个编号(从1开始知道没有重名为止)。
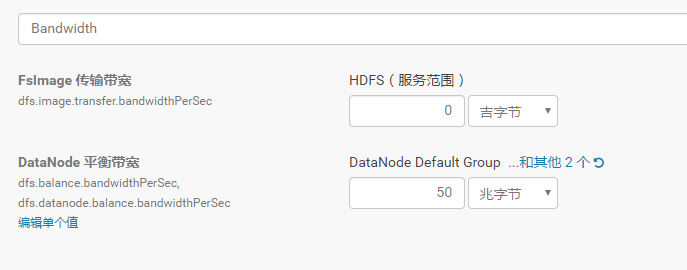
Balancer重新平衡
集群运行一段时间后各个节点的磁盘使用率可能会产生较大的差异,这时可以用balancer来重新平衡各个节点。
首先调大balancer的带宽这里设置为50MB。默认的带宽较小,防止占用太多资源。若需要快速平衡可以将带宽调为一个较大的值。
管理后台–HDFS—配置–搜索bandwidth
接着启动balancer。在管理后台中操作,步骤 hdfs-状态-操作-重新平衡
调整回收站的清理时间
Hadoop回收磁盘空间通过在core-site.xml进行设置实现。
在xml文档内添加:
<property>
<name>fs.trash.interval</name>
<value>1440</value>
<description>Number of minutes between trash checkpoints. If zero, the trash feature is disabled. </description>
</property>
</code>
通过修改value的值来设定回收磁盘空间的时间间隔。如果value是0,默认是关闭此项功能的
调整自动清除回收站
HADOOP-HDFS需要有一个Auto-Emptier 线程来自动清除trash, 以释放HDFS的总使用空间, 该功能可以配置为可选项, 可以在Configuration下增加这两个参数以供配置.
fs.trash.autoemptier.interval 执行空间检查的时间时间隔, 设置为0时, 禁用该功能, 默认为20 Seconds.
fs.trash.max.percentused 当已使用空间率大于该值, 执行回收以释放空间. 默认为0.8f
调整kafka的日志时间
步骤:管理后台–>kafka–>配置–>搜索log.retention.hours–>设置为30天
调整hbase的TTL时间
设置TTL为2592000,30天
./hbase shellhbase> desc 'ns1:t1'hbase> disable 'ns1:t1'hbase> alter 'ns1:t1', {NAME => 'n1', TTL => '2592000'}, {NAME => 'n2', TTL => '2592000'}hbase> enable 'ns1:t1'
设置成功后,hbase自动将过期数据删除,进行合并region操作。磁盘空间得以释放。
hadoop进阶---hadoop性能优化(一)---hdfs空间不足的管理优化的更多相关文章
- hadoop进阶----hadoop经验(一)-----生产环境hadoop部署在超大内存服务器的虚拟机集群上vs几个内存较小的物理机
生产环境 hadoop部署在超大内存服务器的虚拟机集群上 好 还是 几个内存较小的物理机上好? 虚拟机集群优点 虚拟化会带来一些其他方面的功能. 资源隔离.有些集群是专用的,比如给你三台设备只跑一个 ...
- Hadoop生态圈-HBase性能优化
Hadoop生态圈-HBase性能优化 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- 构建高可靠hadoop集群之1-理解hdfs架构
本文主要参考 http://hadoop.apache.org/docs/r2.8.0/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html 主要内容是对该文 ...
- hadoop进阶
Java 多线程安全机制 1.操作系统有两个容易混淆的概念,进程和线程. 进程:一个计算机程序的运行实例,包含了需要执行的指令:有自己的独立地址空间,包含程序内容和数据:不同进程的地址空间是互相隔离的 ...
- Hive数据分析——Spark是一种基于rdd(弹性数据集)的内存分布式并行处理框架,比于Hadoop将大量的中间结果写入HDFS,Spark避免了中间结果的持久化
转自:http://blog.csdn.net/wh_springer/article/details/51842496 近十年来,随着Hadoop生态系统的不断完善,Hadoop早已成为大数据事实上 ...
- 五十九.大数据、Hadoop 、 Hadoop安装与配置 、 HDFS
1.安装Hadoop 单机模式安装Hadoop 安装JAVA环境 设置环境变量,启动运行 1.1 环境准备 1)配置主机名为nn01,ip为192.168.1.21,配置yum源(系统源) 备 ...
- 大数据技术hadoop入门理论系列之二—HDFS架构简介
HDFS简单介绍 HDFS全称是Hadoop Distribute File System,是一个能运行在普通商用硬件上的分布式文件系统. 与其他分布式文件系统显著不同的特点是: HDFS是一个高容错 ...
- Hadoop vs Spark性能对比
http://www.cnblogs.com/jerrylead/archive/2012/08/13/2636149.html Hadoop vs Spark性能对比 基于Spark-0.4和Had ...
- Hadoop(24)-Hadoop优化
1. MapReduce 跑得慢的原因 优化方法 MapReduce优化方法主要从六个方面考虑:数据输入.Map阶段.Reduce阶段.IO传输.数据倾斜问题和常用的调优参数. 数据输入 Map阶段 ...
随机推荐
- 《基于 Web Service 的学分制教务管理系统的研究与实现》论文笔记(十一)
标题:基于 Web Service 的学分制教务管理系统的研究与实现 一.基本内容 时间:2014 来源:苏州大学 关键词:: 教务管理系统 学分制 Web Service 二.研究内容 1.教务管理 ...
- JQuery系列(4) - AJAX方法
jQuery对象上面还定义了Ajax方法($.ajax()),用来处理Ajax操作.调用该方法后,浏览器就会向服务器发出一个HTTP请求. $.ajax方法 $.ajax()的用法主要有两种. $.a ...
- 1、Python简介与Python安装
一.Python简介: Python 是一个高层次的结合了解释性.编译性.互动性和面向对象的脚本语言. Python的创始人为吉多·范罗苏姆(Guido van Rossum)少数几个不秃头的语言创始 ...
- 使用idea 调试java -jar xxx.jar方式启动
今日思语:希望是什么?希望就是 你还在挣扎中... idea是一个功能强大的java开发工具,可以很方便的帮助开发人员进行开发工作. 1.有时我们通过使用java -jar xxx.jar方式启动可执 ...
- 转储Active Directory数据库
获取Windows域控所有用户hash: 参考:3gstudent 方法1: 复制ntds.dit: 使用NinjaCopy,https://github.com/3gstudent/NinjaCop ...
- 11-Flutter移动电商实战-首页_屏幕适配方案和制作
1.flutter_ScreenUtil插件简介 flutter_ScreenUtil屏幕适配方案,让你的UI在不同尺寸的屏幕上都能显示合理的布局. 插件会让你先设置一个UI稿的尺寸,他会根据这个尺寸 ...
- mybatis的判定时间字段问题 java.lang.IllegalArgumentException: invalid comparison: cn.hutool.core.date.DateTime and java.lang.String
今天听组员说: mybatis在3.30版本及以上判定时间时 <if test="date_time != null and date_time != '' "> da ...
- Spark跑在Yarn上出现错误,原因是jdk的版本问题
./bin/spark-shell --master yarn 2019-07-01 12:20:13 WARN NativeCodeLoader:62 - Unable to load native ...
- app内嵌H5的上传图片的功能
1.上传组件 <!-- - hasBorder {Boolean} cell底部边框,oneline 为 true 有效 - inlineBorder {Boolean} cell底部短边框 - ...
- Nessus简单使用
1.更新插件 上次搭建完后总觉得不踏实,因为老是提示插件多久没更新了,然后果断花了1.25美刀买了台vps,终于把最新的插件下载下来了,总共190M,需要的QQ私信我.