让天堂的归天堂,让尘土的归尘土——谈Linux的总线、设备、驱动模型
本文系转载,著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者: 宋宝华
来源: 微信公众号linux阅码场(id: linuxdev)

公元1951年5月15日的国会听证上,美国陆军五星上将麦克阿瑟建议把朝鲜战争扩大至中国,布莱德利随后发言:“如果我们把战争扩大到中国,那么我们会被卷入到一场错误的时间,错误的地点同错误的对手打的一场错误的战争中。”
写代码,适用于同样的原则,那就是把正确的代码放到正确的位置而不是相反。同样的一个代码,可以出现在多个可能的位置,它究竟应该出现在哪里,是软件架构设计的结果,说白了一切都是为了高内聚和低耦合。
陷入绝境
下面我们设想一个名字叫做ABC的简单的网卡,它需要接在一个CPU(假设CPU为X)的内存总线上,需要地址、数据和控制总线(以及中断pin脚等)。

那么在ABC的网卡驱动里面,我们需要定义ABC的基地址、中断号等信息。假设在CPU X的电路板上面,ABC的地址为0x100000,中断号为10。假设我们是这样定义的宏:
#define ABC_BASE 0x100000
#define ABC_IRQ 10
并且这样写代码完成发送报文和初始化申请中断:
#define ABC_BASE 0x100000
#define ABC_IRQ 10
int abc_send(...)
{
writel(ABC_BASE + REG_X, 1);
writel(ABC_BASE + REG_Y, 0x3);
...
}
int abc_init(...)
{
request_irq(ABC_IRQ,...);
}
这个代码的问题在于,一旦重新换板子,ABC_BASE和ABC_IRQ就不再一样,代码也需要随之变更。
有的程序员说我可以这么干:
#ifdef BOARD_A
#define ABC_BASE 0x100000
#define ABC_IRQ 10
#elif defined(BOARD_B)
#define ABC_BASE 0x110000
#define ABC_IRQ 20
#elif defined(BOARD_C)
#define ABC_BASE 0x120000
#define ABC_IRQ 10
...
#endif
这么干固然是可以,但是如果你有1万个不同的板子,你就要ifdef一万次,这样写代码,找到了一种明显的砌墙的感觉(你感觉写代码,就跟砌墙似的,一块块砖头一样放进去的时候,简单重复机械,这个时候,就很危险了,可能代码里面就已经出现了不好的“味道”)。考虑到Linux向全世界各个产品适配,各种硬件适配的特点,究竟有多少个板子用ABC,还真的谁也说不清楚。
那么,是不是真的#ifdef走一万次,就一定能解决问题呢?还真的是不能。假设有一个电路板有2个ABC网卡,就彻底傻眼了。难道这样定义?
#ifdef BOARD_A
#define ABC1_BASE 0x100000
#define ABC1_IRQ 10
#define ABC2_BASE 0x101000
#define ABC2_IRQ 11
#elif defined(BOARD_B)
#define ABC1_BASE 0x110000
#define ABC1_IRQ 20
...
#endif
如果这样做,abc_send()和abc_init()又该如何改?难道这样:
int abc1_send(...)
{
writel(ABC1_BASE + REG_X, 1);
writel(ABC1_BASE + REG_Y, 0x3);
...
}
int abc1_init(...)
{
request_irq(ABC1_IRQ,...);
}
int abc2_send(...)
{
writel(ABC2_BASE + REG_X, 1);
writel(ABC2_BASE + REG_Y, 0x3);
...
}
int abc2_init(...)
{
request_irq(ABC2_IRQ,...);
}
…
还是这样?
int abc_send(int id, ...)
{
if (id == 0) {
writel(ABC1_BASE + REG_X, 1);
writel(ABC1_BASE + REG_Y, 0x3);
} else if (id == 1) {
writel(ABC2_BASE + REG_X, 1);
writel(ABC2_BASE + REG_Y, 0x3);
}
...
}
无论你怎么改,这个代码实在都已经是惨不忍睹了,连自己都看不下去了。我们为什么会陷入这样的困境,是因为我们犯了未能“把正确的代码,放入正确的位置的错误”,这样引入了极大的耦合。
迷途反思
我们犯的致命的错误,在于把板级互连信息,耦合进了驱动的代码,导致驱动无法跨平台。

我们转念想一想,ABC的驱动的真正职责是完成ABC网卡的收发流程,试问,这个流程,真的与它接在什么CPU(TI、三星、Broad、Allwinner等)有半毛钱关系吗?又和接在哪个板子上有半毛钱关系吗?
答案是真的没有什么关系!ABC网卡,不会因为你是TI的ARM,你是龙芯,还是你是Blackfin有什么不同。任你外面什么板子排山倒海,狗急跳墙,ABC自己都是岿然不动。
既然没有什么关系,那么这些板子级别的互连信息,又为什么要放在驱动的代码里面呢?基本上,我们可以认为,ABC不会因谁而变,所以它的代码应该是天然跨平台的。故此,我们认为“#defineABC_BASE 0x100000, #define ABC_IRQ 10”这样的代码,出现在驱动里面,属于“在错误的地点,和错误的敌人,打一场错误的战争”。它没有被放在正确的位置上,而我们写代码,一定“让天堂的归天堂, 让尘土的归尘土”。我们真实的期待,恐怕是这个样子:

软件工程强调高内聚、低耦合。若一个模块内各元素联系的越紧密,则它的内聚性就越高;模块之间联系越不紧密,其耦合性就越低。所以高内聚、低耦合强调,内部的要紧紧抱团,外面的给我滚蛋。对于驱动而言,板级互连信息,显然属于应该滚蛋的。每个软件模块最好是一个宅男,不谈恋爱,不看电影,不吃大餐,不踢足够,和外界唯一的联系就是“饿了吗”,这样的软件,显然是又高内聚、又低耦合。
有一次我在一个德国外企,问到工程师们“高内聚和低耦合是什么关系”,有一个工程师非常积极地回答,“高内聚和低耦合是一对矛盾”。我觉得他的脑子好乱,如果一定要用一个关系来描述高内聚和低耦合的关系,我认为他们符合马列主义,“高内聚和低耦合,相互依存,缺一不可,相辅相成,共同促进”,它其实反映了同一个事物两个不同的侧面,总之,把政治课本背一遍就对了。你写个串口的代码,里面从头到尾都是串口相关的东西,聚地紧,它也自然不会满世界乱跑到SPI里面去耦合。SPI要和串口低耦合,它也势必要求UART内部代码把串口的东东全部聚一起,不要乱窜,没有SPI的户口,居住证也不发给你,就给我滚回老家去。

柳岸花明
现在板级互连信息已经和驱动分离开来了,让它们彼此出现在不同的软件模块。但是,最终它们仍然有一定的联系,因为,驱动最终还是要取出基地址、中断号等板级信息的。怎么取,这是个大问题。
一种方法是ABC的驱动满世界询问各个板子,“请问你的基地址,中断号是几?”,“你妈贵姓?”这仍然是一个严重的耦合。因为,驱动还是得知道板子上有没有ABC,哪个板子有,怎么个有法。它还是在和板子直接耦合。

可不可以有另外一种方法,我们维护一个共同的类似数据库的东西,板子上有什么网卡,基地址中断号是什么,都统一在一个地方维护。然后,驱动问一个统一的地方,通过一个统一的API来获取即好?

基于这样的想法,linux把设备驱动分为了总线、设备和驱动三个实体,总线是上图中的统一纽带,设备是上图中的板级互连信息,这三个实体完成的职责分别如下:

我们把所有的板子互连信息填入设备端,然后让设备端向总线注册告知总线自己的存在,总线上面自然关联了这些设备,并进一步间接关联了设备的板级连接信息。比如arch/blackfin/mach-bf533/boards/ip0x.c这块板子有2个DM9000的网卡,它是这样注册的:
static struct resource dm9000_resource1[] = {
{
.start = 0x20100000,
.end = 0x20100000 + 1,
.flags = IORESOURCE_MEM
},{
.start = 0x20100000 + 2,
.end = 0x20100000 + 3,
.flags = IORESOURCE_MEM
},{
.start = IRQ_PF15,
.end = IRQ_PF15,
.flags = IORESOURCE_IRQ | IORESOURCE_IRQ_HIGHEDGE
}
};
static struct resource dm9000_resource2[] = {
{
.start = 0x20200000,
.end = 0x20200000 + 1,
.flags = IORESOURCE_MEM
}…
};
…
static struct platform_device dm9000_device1 = {
.name = "dm9000",
.id = 0,
.num_resources = ARRAY_SIZE(dm9000_resource1),
.resource = dm9000_resource1,
};
…
static struct platform_device dm9000_device2 = {
.name = "dm9000",
.id = 1,
.num_resources = ARRAY_SIZE(dm9000_resource2),
.resource = dm9000_resource2,
};
static struct platform_device *ip0x_devices[] __initdata = {
&dm9000_device1,
&dm9000_device2,
…
};
static int __init ip0x_init(void)
{
platform_add_devices(ip0x_devices, ARRAY_SIZE(ip0x_devices));
…
}
这样platform的总线这个统一纽带上,自然就知道板子上面有2个DM9000的网卡。一旦DM9000的驱动也被注册,由于platform总线已经关联了设备,驱动自然可以根据已经存在的DM9000设备信息,获知如下的内存基地址、中断等信息了:
static struct resource dm9000_resource1[] = {
{
.start = 0x20100000,
.end = 0x20100000 + 1,
.flags = IORESOURCE_MEM
},{
.start = 0x20100000 + 2,
.end = 0x20100000 + 3,
.flags = IORESOURCE_MEM
},{
.start = IRQ_PF15,
.end = IRQ_PF15,
.flags = IORESOURCE_IRQ | IORESOURCE_IRQ_HIGHEDGE
}
};
总线存在的目的,则是把这些驱动和这些设备,一一配对的匹配在一起。如下图,某个电路板子上有2个ABC,1个DEF,1个HIJ设备,以及分别1个的ABC、DEF、HIJ驱动,那么总线,就是让2个ABC设备和1个ABC驱动匹配,DEF设备和驱动一对一匹配,HIJ设备和驱动一对一匹配。

驱动本身,则可以用最简单的API取出设备端填入的互连信息,看一下drivers/net/ethernet/davicom/dm9000.c的dm9000_probe()代码:
static int dm9000_probe(struct platform_device *pdev)
{
…
db->addr_res = platform_get_resource(pdev, IORESOURCE_MEM, 0);
db->data_res = platform_get_resource(pdev, IORESOURCE_MEM, 1);
db->irq_res = platform_get_resource(pdev, IORESOURCE_IRQ, 0);
…
}
这样,板级互连信息,再也不会闯入驱动,而驱动,看起来也没有和设备之间直接耦合,因为它调用的都是总线级别的标准API:platform_get_resource()。总线里面有个match()函数,来完成哪个设备由哪个驱动来服务的职责,比如对于挂在内存上的platform总线而言,它的匹配类似(最简单的匹配方法就是设备和驱动的name字段一样):
static int platform_match(struct device *dev, struct device_driver *drv)
{
struct platform_device *pdev = to_platform_device(dev);
struct platform_driver *pdrv = to_platform_driver(drv);
/* When driver_override is set, only bind to the matching driver */
if (pdev->driver_override)
return !strcmp(pdev->driver_override, drv->name);
/* Attempt an OF style match first */
if (of_driver_match_device(dev, drv))
return 1;
/* Then try ACPI style match */
if (acpi_driver_match_device(dev, drv))
return 1;
/* Then try to match against the id table */
if (pdrv->id_table)
return platform_match_id(pdrv->id_table, pdev) != NULL;
/* fall-back to driver name match */
return (strcmp(pdev->name, drv->name) == 0);
}
VxBus是风河公司新的设备驱动程序架构,它是在VxWorks 6.2及以后版本被增加到VxWorks中的,直至VxWorks 6.9,基本都已经VxBus化了。但是,这个VxBus,可以说和Linux的总线、设备、驱动模型是极大地雷同的。但是,请问,你为什么要叫VxBus呢,它非常地Vx吗?
所以,这个时候我们看到的代码会是这样,无论是哪个板子的ABC设备,都统一使用了一个不变的drivers/net/ethernet/abc.c驱动,而arch/arm/mach-yyy/board-a.c这样的代码,则有很多很多份。
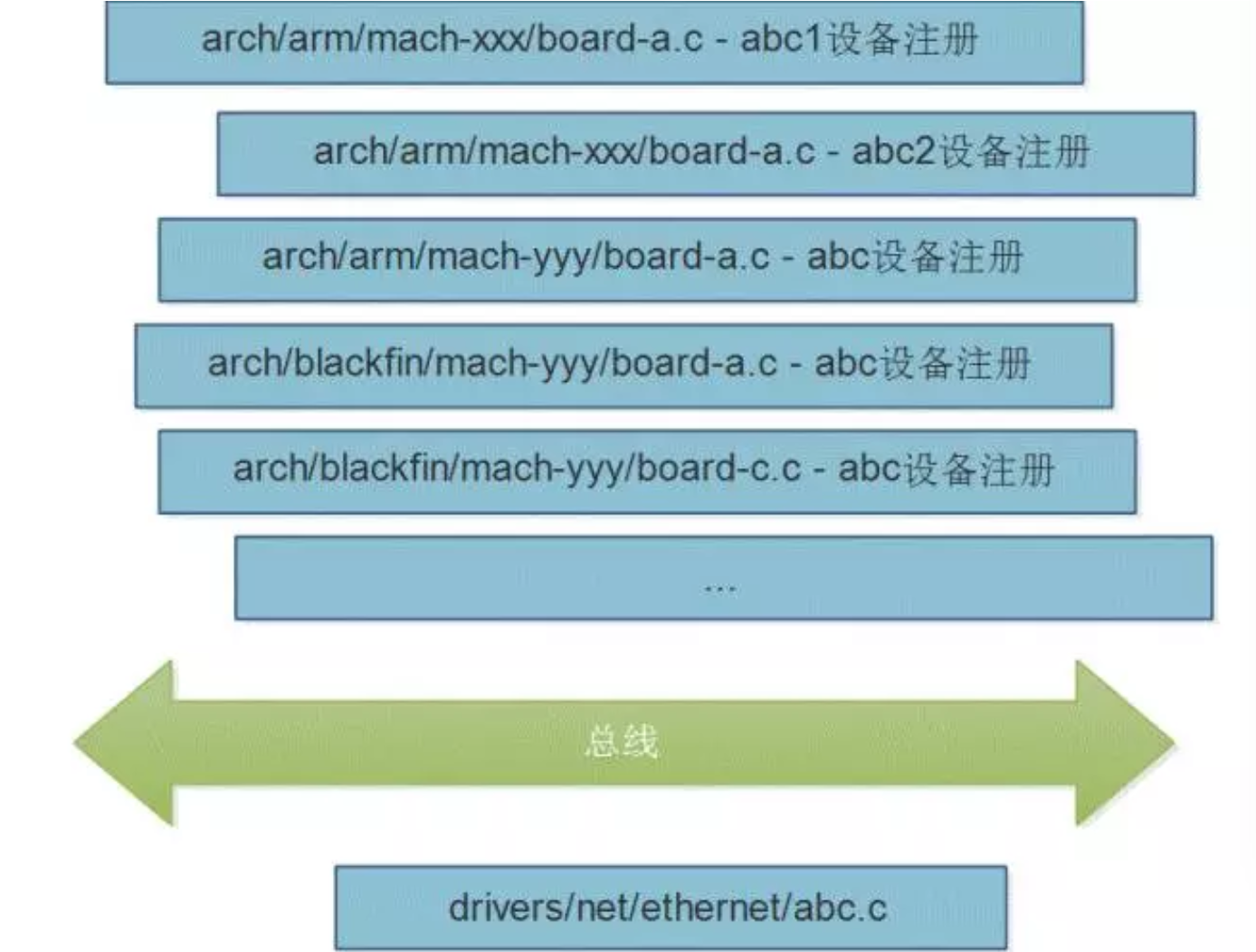
更上层楼
我们仍然看到大量的arch/arm/mach-yyy/board-a.c这样的代码,冲刺着描述板级信息的细节代码,尽管它本身已经和驱动解耦了。这些代码的存在,简直是对Linux内核的污染和对Linus Torvalds的无情藐视,因为,太木有技术含量了!
我们有理由,把这些设备端的信息,用一个非C的脚本语言来描述,这个脚本文件,就是传说中的Device Tree(设备树)。
设备树,是一种dts文件,它用最简单的语法描述每个板子上的所有设备,以及这些设备的连接信息。比如arch/arm/boot/dts/ imx1-apf9328.dts下面的DM9000就是这样的脚本,基地址、中断号都成为了DM9000设备节点的一个属性:
eth: eth@4,c00000 {
compatible = "davicom,dm9000";
reg = <
4 0x00c00000 0x2
4 0x00c00002 0x2
>;
interrupt-parent = <&gpio2>;
interrupts = <14 IRQ_TYPE_LEVEL_LOW>;
…
};
之后,C代码被剔除,arch/arm/mach-xxx/board-a.c这样的文件永远地进入了历史的故纸堆,代码就变成这样的架构,换个板子,只要换个Device Tree就好。“让天堂的归天堂, 让尘土的归尘土”,让驱动的归驱动C代码,让设备的归设备树脚本。

我们很高兴也很悲痛地看到,VxWorks 7的新版,也采用Device Tree了。我们高兴的是,它终于来了;我们悲痛的是,它终于又来晚了。Linux的车轮滚滚向前,无情碾压一切。人类的千年轨迹,沧海桑田,斗转星移,重复地进行着历史的归于历史,未来还是归于历史的过程。这是现实的悲怆,也是历史的豪迈。
《孙子兵法》曰:“水因地而制流,兵因敌而制胜。故兵无常势,水无常形;能因敌变化而取胜者,谓之神。”一切不过是顺势而为,把正确的代码,安放到正确的位置。
更多精彩更新中……欢迎关注微信公众号:linux阅码场(id: linuxdev)
让天堂的归天堂,让尘土的归尘土——谈Linux的总线、设备、驱动模型的更多相关文章
- 宋牧春: Linux设备树文件结构与解析深度分析(1) 【转】
转自:https://mp.weixin.qq.com/s/OX-aXd5MYlE_YoZ3p32qWA 作者简介 宋牧春,linux内核爱好者,喜欢阅读各种开源代码(uboot.linux.ucos ...
- [转][darkbaby]任天堂传——失落的泰坦王朝(下)
即使是日本业界人士也对1999年发生的“口袋妖怪所有权风波”知之甚少,实际上这个事件的结局足以改变游戏产业未来数十年的势力图,山内溥凭借着个人的睿智让任天堂再次渡过了命运的暗礁,而另一颗曾经炙手可热的 ...
- [转][darkbaby]任天堂传——失落的泰坦王朝(中)
TV游戏产业历史上曾有过太多表里不一的外交辞令,然而当年SQUARE和任天堂分道扬镳的真正原因确实如坂口博信在1996年2月29日的PS版 <FFVII>发表会上宣称的那样:“虽然之前有过 ...
- storysnail的Linux串口编程笔记
storysnail的Linux串口编程笔记 作者 He YiJun – storysnail<at>gmail.com 团队 ls 版权 转载请保留本声明! 本文档包含的原创代码根据Ge ...
- Linux内核学习之道
来自:http://blog.chinaunix.net/uid-26258259-id-3783679.html 内核文档 内核代码中包含有大量的文档,这些文档对于学习理解内核有着不可估量的价值,记 ...
- 如何切入 Linux 内核源代码
Makefile不是Make Love 从前在学校,混了四年,没有学到任何东西,每天就是逃课,上网,玩游戏,睡觉.毕业的时候,人家跟我说Makefile我完全不知,但是一说Make Love我就来劲了 ...
- Linux内核学习方法
Makefile不是Make Love 从前在学校,混了四年,没有学到任何东西,每天就是逃课,上网,玩游戏,睡觉.毕业的时候,人家跟我说Makefile我完全不知,但是一说Make Love我就来劲了 ...
- 【文学文娱】《屌丝逆袭》-出任CEO、迎娶白富美、走上人生巅峰
本文地址:http://www.cnblogs.com/aiweixiao/p/7759790.html 原文地址:(微信公众号) 原创 2017-10-30 微信号wozhuzaisi 程序员的文娱 ...
- Linux内核(5) - 内核学习的相关资源
“世界上最缺的不是金钱,而是资源.”当我在一份报纸上看到这句大大标题时,我的第一反应是——作者一定是个自然环保主义者,然后我在羞愧得反省自身的同时油然生出一股对这样的无产主义理想者无比崇敬的情绪来. ...
随机推荐
- org.slf4j.helpers.Log4jLoggerFactory is not on classpath. Good!
View Javadoc 1 /* 2 * Licensed to the Apache Software Foundation (ASF) under one or more 3 * contrib ...
- 【转】HTTPS 如何保证数据传输的安全性?
大家都知道,在客户端与服务器数据传输的过程中,HTTP协议的传输是不安全的,也就是一般情况下HTTP是明文传输的.但HTTPS协议的数据传输是安全的,也就是说HTTPS数据的传输是经过加密的. 在客户 ...
- Centos7将本地源更换为网易源
百度搜索: 网易源 点击进入网易开源镜像站 1. 备份当前 repo 文件 mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS- ...
- Django-Debug-Toolbar插件
目录 django配置插件: 介绍: 安装及配置: 优化ORM: django配置插件: ---配置Django-Debug-Toolbar 介绍: Django-Debug-Toolbar是项目开发 ...
- [LeetCode] 25. Reverse Nodes in k-Group 每k个一组翻转链表
Given a linked list, reverse the nodes of a linked list k at a time and return its modified list. k ...
- NOI 2019 退役记
非常抱歉,因为不退役了,所以这篇退役记鸽了.
- OAuth2.0 自我领悟
grant_type 授权模式 authorization_code 标准的Server授权模式,授权码模式 password 基于用户密码的授权模式,用户密码模式 client_credential ...
- vue组件component没效果
如果实在不知道问题所在,你就看看你的component的命名是不是驼峰命名
- scala中的Option
Scala中Option是用来表示一个可选类型 什么是可选? --> 主要是指 有值(Some) 和 无值(None)-->Some和None是Option的子类 val myMap:Ma ...
- zipkin微服务调用链分析(python)
一,概述 zipkin的作用 在微服务架构下,一个http请求从发出到响应,中间可能经过了N多服务的调用,或者N多逻辑操作,如何监控某个服务,或者某个逻辑操作的执行情况,对分析耗时操作,性能瓶颈具有很 ...