sqoop 导入增量数据到hive
版本
hive:apache-hive-2.1.0
sqoop:sqoop-1.4.6
hadoop:hadoop-2.7.3
导入方式
1.append方式
2.lastmodified方式,必须要加--append(追加)或者--merge-key(合并,一般填主键)

创建mysql表并添加数据
-- ----------------------------
-- Table structure for `data`
-- ----------------------------
DROP TABLE IF EXISTS `data`;
CREATE TABLE `data` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` char(20) DEFAULT NULL,
`last_mod` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8; -- ----------------------------
-- Records of data
-- ----------------------------
INSERT INTO `data` VALUES ('', '', '2019-08-28 17:34:51');
INSERT INTO `data` VALUES ('', '', '2019-08-28 17:31:57');
INSERT INTO `data` VALUES ('', '', '2019-08-28 17:31:58');
先将mysql表数据全部导入hive
sqoop import --connect jdbc:mysql://192.168.0.8:3306/hxy --username root --password 123456 --table data --hive-import --fields-terminated-by ',' -m 1
注意:fields-terminated-by 要是不指定值的话,默认分隔符为'\001',并且以后每次导入数据都要设置 --fields-terminated-by '\001',不然导入的数据为NULL。建议手动设置 --fields-terminated-by的值

成功导入之后,会在HDFS的/soft/hive/warehouse/data看到数据文件
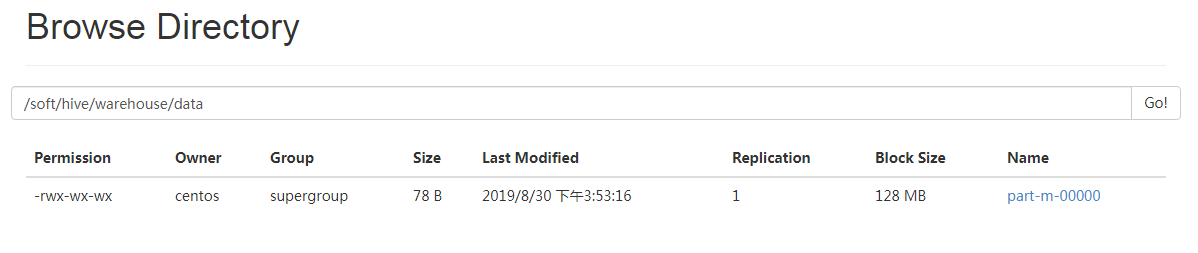
默认生成的hive表为内部表,内部表的数据文件默认保存路径为/user/hive/warehouse,我在hive-site.xml中,把hive.metastore.warehouse.dir值设成了/soft/hive/warehouse
hive表数据
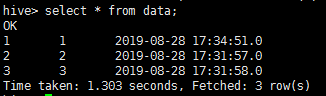
增量导入--append方式导入
官网说append方式下,append 用于自增的 id 列(lastmodified 用于更新的日期列),但是我自己动手发现append方式下,也可以通过时间类型增量导入
官网原文:You should specify append mode when importing a table where new rows are continually being added with increasing row id values. You specify the column containing the row’s id with --check-column. Sqoop imports rows where the check column has a value greater than the one specified with --last-value.
1.last-value是数字类型(推荐)
往mysql插入2条数据
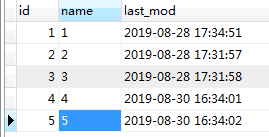
--targrt-dir的值设置成hive表数据文件存储的路径。假如你的hive表为外部表,则--targrt-dir要指向外部表的存储路径
--last-value 3,意味mysql中id为3的数据不会被导入
sqoop import --connect jdbc:mysql://192.168.0.8:3306/hxy \
--username root \
--password 123456 \
--table data \
--target-dir '/soft/hive/warehouse/data' \
--incremental append \
--check-column id \
--last-value 3 \
-m 1
导入成功之后查看数据
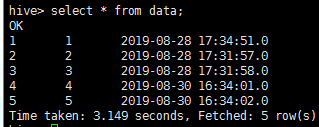
2.last-value是时间类型(不推荐)
mysql新增2条数据

执行sqoop命令,按 --check-column last_mod --last-value '2019-08-30 16:34:02' 条件查找
sqoop import --connect jdbc:mysql://192.168.0.8:3306/hxy \
--username root \
--password 123456 \
--table data \
--target-dir '/soft/hive/warehouse/data' \
--incremental append \
--check-column last_mod \
--last-value '2019-08-30 16:34:02' \
-m 1
查看hive数据(mysql中,时间值为2019-08-30 16:34:02的数据不会被导入)

增量导入--lastmodified方式导入
lastmodified 用于更新的日期列
1.--incremental lastmodified --append
将mysql新插入3条数据,并且把id为7的name做了修改
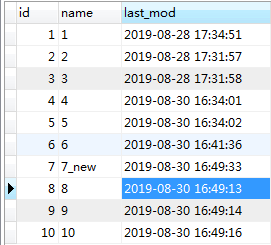
执行sqoop命令 (--incremental lastmodified --append方式下,mysql中和--last-value指定的值相等的数据也不会被导入,所以想要让id为8的数据也导入进去,last-value的值就应该比id为8的数据的时间要小)
sqoop import --connect jdbc:mysql://192.168.0.8:3306/hxy \
--username root \
--password 123456 \
--table data \
--target-dir '/soft/hive/warehouse/data' \
--check-column last_mod \
--incremental lastmodified \
--last-value '2019-08-30 16:49:12' \
--m 1 \
--append
结果
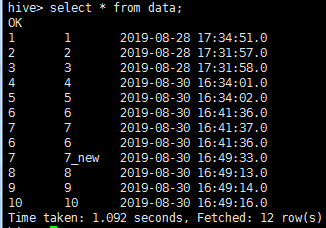
可以看到,7,8,9,10都导入进来了,表中出现了2个id为7的数据,出现了数据重复
--incremental lastmodified --append的作用:把大于last-value时间的数据都导入进来,之前就存在但是后期修改过的数据并不会进行合并,只会当做新增的数据加进来,所以使用--incremental lastmodified --append有可能导致数据重复的问题
2.--incremental lastmodified --merge-key
往mysql插入2条数据,并且把id为10的数据做了修改

执行sqoop命令(--merge-key的值一般填主键,merge-key方式下,mysql中时间和last-value相同的数据会被导入)
sqoop import --connect jdbc:mysql://192.168.0.8:3306/hxy \
--username root \
--password 123456 \
--table data \
--target-dir '/soft/hive/warehouse/data' \
--check-column last_mod \
--incremental lastmodified \
--last-value '2019-08-30 17:05:49' \
--m 1 \
--merge-key id
结果

可以看到,新数据11,12都被加了进来,id为10的值做了合并操作,修改后的"10_new"替换了原来的"10",没有数据重复的现象
并且,id为7的数据也被合并了,可是last-value的值明明比id为7的时间要大,原因是:只要出现id重复的情况,就合并数据,不考虑时间条件。id不为重复的情况下,才会考虑时间条件
--incremental lastmodified --merge-key的作用:修改过的数据和新增的数据(前提是满足last-value的条件)都会导入进来,并且重复的数据(不需要满足last-value的条件)都会进行合并
sqoop 导入增量数据到hive的更多相关文章
- sqoop导入增量数据
使用sqoop导入增量数据. 核心参数 --check-column 用来指定一些列,这些列在增量导入时用来检查这些数据是否作为增量数据进行导入,和关系行数据库中的自增字段及时间戳类似这些被指定的列的 ...
- Sqoop导入mysql数据到Hbase
sqoop import --driver com.mysql.jdbc.Driver --connect "jdbc:mysql://11.143.18.29:3306/db_1" ...
- Sqoop导入MySQL数据
导入所有表: sqoop import-all-tables –connect jdbc:mysql://ip:port/dbName --username userName --password p ...
- sqoop导oracle数据到hive中并动态分区
静态分区: 在hive中创建表可以使用hql脚本: test.hql USE TEST; CREATE TABLE page_view(viewTime INT, userid BIGINT, pag ...
- sqoop导出mysql数据进入hive错误
看mr的运行显示:sqoop job可以获得的select max(xxx)结果,但是当mr开始时却显示大片错误,就是连接超时,和连接重置等问题, 最后去每个节点ping mysql的ip地址,发现 ...
- sqoop导入数据
来源https://www.cnblogs.com/qingyunzong/p/8807252.html 一.概述 sqoop 是 apache 旗下一款“Hadoop 和关系数据库服务器之间传送数据 ...
- 第3节 sqoop:6、sqoop的数据增量导入和数据导出
增量导入 在实际工作当中,数据的导入,很多时候都是只需要导入增量数据即可,并不需要将表中的数据全部导入到hive或者hdfs当中去,肯定会出现重复的数据的状况,所以我们一般都是选用一些字段进行增量的导 ...
- 大数据学习——sqoop导入数据
把数据从关系型数据库导入到hadoop 启动sqoop 导入表表数据到HDFS 下面的命令用于从MySQL数据库服务器中的emp表导入HDFS. sqoop import \ --connect jd ...
- sqoop上传数据到hdfs,并用hive管理数据。
sqoop导入mysql数据表到HDFS中sqoop import --connect jdbc:mysql://master:3306/test --username root --password ...
随机推荐
- Nginx 配置 HTTPS SSL
配置文件如下:[可以在阿里云上申请免费证书] #user nobody; worker_processes 1; events { worker_connections 1024; } http { ...
- libmysqlclient.so.18 not found 的解决方法
现象:在银河麒麟下,安装了mysql,并且mysql服务正常运行,但是Qt访问mysql还是报Driver not loaded,ldd Qt自己的mysql驱动报错如标题所示.路径: 解释:很明显就 ...
- PHP用curl抓取网站数据,仿造IP、伪造来源等,防屏蔽解决方案教程
1.伪造客户端IP地址,伪造访问referer:(一般情况下这就可以访问到数据了) curl_setopt($curl, CURLOPT_HTTPHEADER, ['X-FORWARDED-FOR:1 ...
- EasyDSS高性能RTMP、HLS(m3u8)、HTTP-FLV、RTSP流媒体服务器同步输出http-flv协议流是怎么实现的?
http-flv是什么 http-flv是以http为传输协议,flv媒体格式为内容的方式实时下载flv音视频帧.为什么选择flv格式而非mp4?原因是mp4必须要有moov box或者moof bo ...
- LeetCode_434. Number of Segments in a String
434. Number of Segments in a String Easy Count the number of segments in a string, where a segment i ...
- 托马斯·贝叶斯 (Thomas Bayes)
朴素贝叶斯 Day15,开始学习朴素贝叶斯,先了解一下贝爷,以示敬意. 托马斯·贝叶斯 (Thomas Bayes),英国神学家.数学家.数理统计学家和哲学家,1702年出生于英国伦敦,做过神甫: ...
- java静态代理和JDK动态代理
静态代理 编译阶段就生产了对应的代理类 public interface IBussiness { void execute(); } public class BussinessImpl imple ...
- [转帖]Socat 入门教程
https://www.hi-linux.com/posts/61543.html 现在安装k8s 必须带 socat 今天看一下socat 到底是啥东西呢. Socat 是 Linux 下的一个多功 ...
- Python开发之规范化目录
13.规范化目录 规范目录优点: 可读性高 加载快 查询修改简 规范化目录结构 (1) start.py文件:首要配置启动文件,运行run()就可以执行项目 #start import sys imp ...
- python基础 — 局部变量/全局变量
变量作用区域 变量器作用的额代码范围称为变量的作用与,不同作用区域之间互不影响,函数每部定义的变量一般为局部变量,而不属于任何函数的变量一般为全局变量.所以我们在这里按变量的作用区域分为两类,全局变量 ...