集成学习-xgboost
等同于xgboost是个准曲率很高的集成学习框架,在很多比赛中成绩优异。
大多数的集成学习都使用决策树作为基分类器,主要是因为本身要训练多个分类器,而决策树速度很快,总体时间相对较少。
决策树
在讲xgboost之前,先描述一下决策树,后面要用到这些符号
决策树是把输入x映射到一个叶节点中,这个过程我们记为q(x)
叶节点总数记为T,每个叶节点有个标签(分类)或者预测值(回归)w,即W=[w1,w2,...wT]
那么决策过程就是 f(x)=W[q(x)],记为wq(x)
决策树的复杂度
决策树很容易过拟合,过拟合是因为树太深,模型过于复杂,限制过拟合主要是避免树太深,可以限制叶节点的个数不能太多,也可以限制叶节点中样本数不能太少,当然还有很多方法,
这里我们提出一个概念叫树的复杂度,可以用叶节点的个数T和叶节点的标签w来衡量,标签w可以理解为节点中样本较多,取平均会比较平滑,类似于 batch,
当然也可以用其他方式来衡量
xgboost通俗理解
本文以xgboost回归为例进行讲解
单个决策树很难保障准确率,假设单个决策树预测为y’,真实值为y,于是产生了一个误差y-y',
xgboost针对这个误差又建立了一棵决策树,分析误差产生的原因,从而弥补这个误差,新的决策树又会产生一个误差,那么继续建立一棵决策树,如此迭代下去,这就是xgboost的大致过程。
这个过程好比我们写代码,先大致写个框架,运行一下,看看哪不对,改一下,再运行一下,看看哪不对,再改一下,如此迭代,直至完全正确。
注意我们写代码时很少一下从头写到尾,因为这样很不方便调试,如果错误太多,还不如重新写,
对应到决策树就是树太深,过拟合,可能需要重新训练,所以xgboost每一棵树不能太深,这个例子不太合适,只是帮助理解
假设决策树的预测为y',真实值为y,我们把误差记为 l(y, y'),为了约束决策树的复杂度,xgboost加上了正则项,我们用 Ω(f) 来表示,f代表决策树
xgboost需要建立多棵决策树,假设y'初始值为0,即瞎猜,没有任何预测时为0,那么整个过程如下
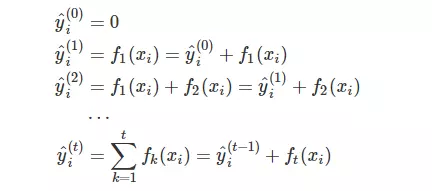
i表示样本,t表示第几棵树,yt表示前t棵树的预测值,ft(x)表示新建的第t棵树的预测值,
最终的预测值就是

k表示决策树的个数。
建树原则
那么问题来了,如何建树?
普通的决策树是利用信息增益、信息增益率或者基尼系数来建树,那么xgboost建树的指标是什么呢?
树的损失函数
之前说决策树有个损失函数
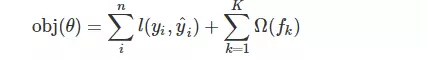
n表示样本数
根据经验,我们需要使得损失函数最小,这就是建树的原则。
那么怎么最小化损失函数呢?正常我们都会有个线性变换、激活函数,这里是一棵树,怎么办呢? 可能一时半会真想不到,先把公式变换一下吧
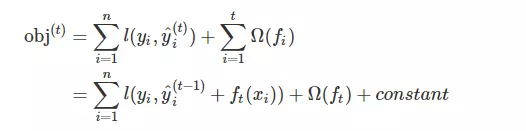
这个 constant 就是前t-1棵树的复杂度,Ω (ft)是第t棵树的复杂度。
假设l损失为均方差,上式变为
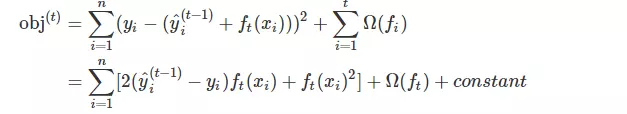
这里重新回忆一下,xgboost是一棵树一棵树的建立,也就是说在建立第t棵树时,第t-1棵树的预测值是已知的,也就是上式中 y, yt-1是已知的,故其运算值是常数,所以上式是这样的
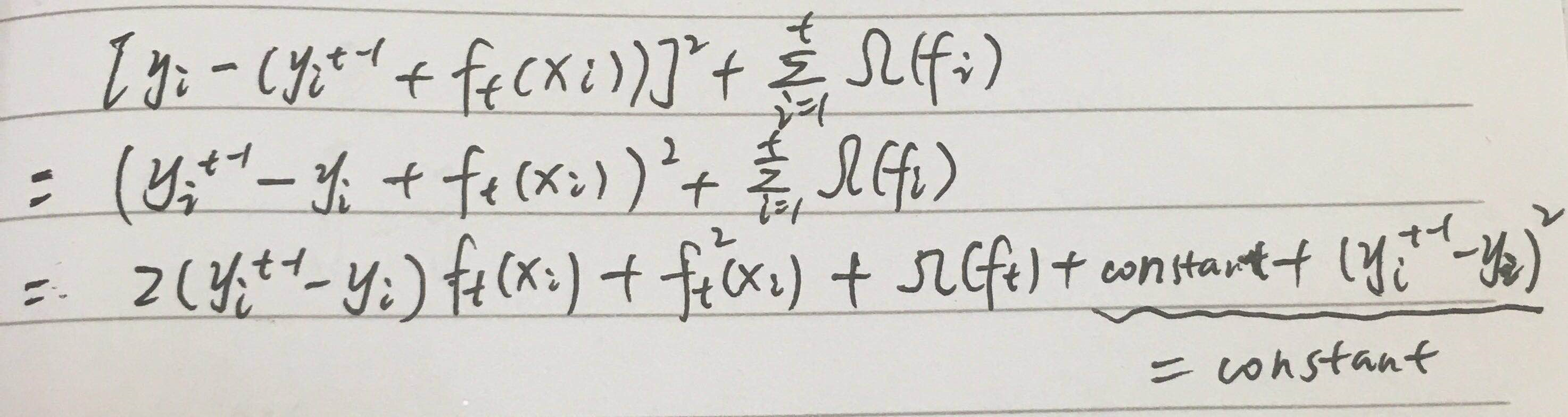
注意xgboost有个特点就是允许自定义损失函数,那么如果我们定义的损失函数不是均方差,那是不是得重新研究一下算法呢? 是的,确实要重新研究,但是xgboost为了避免这种麻烦,采用了损失函数的二阶近似
二阶Taylor展开
这里简单介绍下
泰勒级数:把非线性函数f(x)=0在x0处展开成泰勒级数,注意x0是个已知数

然后取前3项作为近似值。
损失函数 l(y,yt-1+ft(x)) 是关于 yt-1+ ft(x) 的方程,yt-1+ ft(x)对应为泰勒展开中的x,yt-1是常数,对应为泰勒展开中的x0
所以损失函数 l(y,yt-1+ft(x)) 二阶近似为
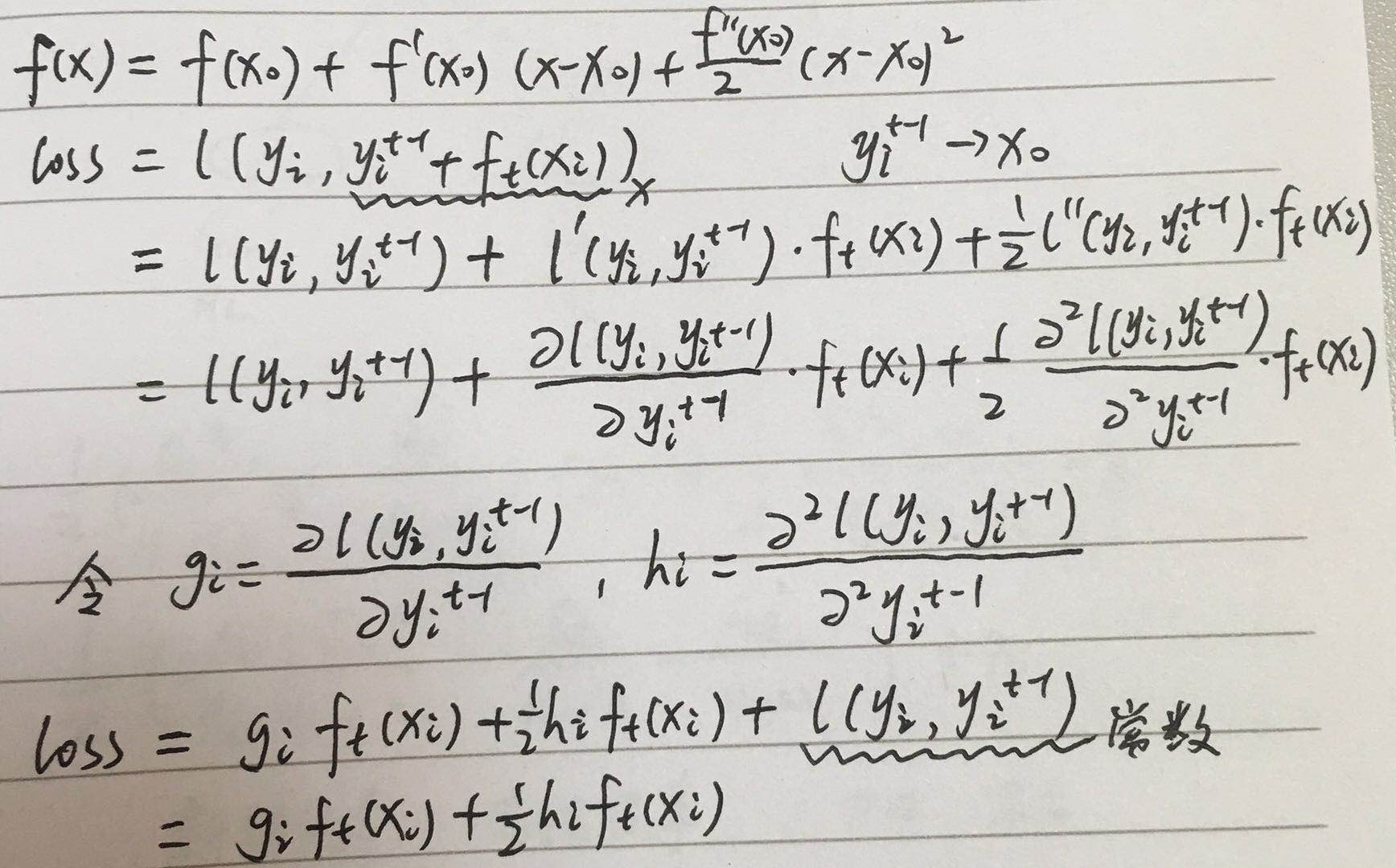
注意这里是对 l(y,yt-1+ft(x)) 的展开。
这里需要理解下gi,hi是什么东西?貌似不是很清楚。
我们以均方差为例来看下
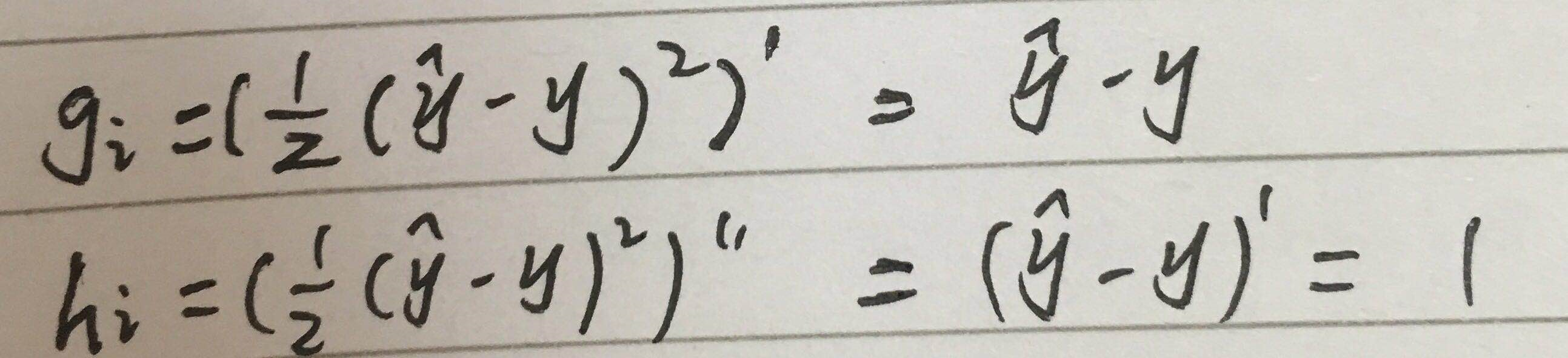
可以看到gi和hi就是损失函数对 预测值 的一阶导和二阶导,
而且gi和hi可以并行计算,并且是根据上一棵树来计算的,也就是在新建树时,他们是已知值。
树损失函数展开为
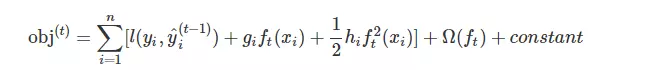
去掉常数项
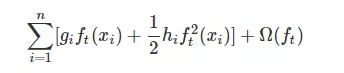
树模型 正则化 Ω(ft)
前面说到决策树的复杂度,假如用决策树的叶节点数T和叶节点的预测值w来对树进行正则化的,当然你也可以自定义其正则化的方式,合理即可,
T尽量少,w尽量平滑,所以
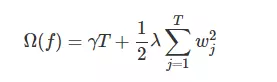
γ λ 是惩罚系数,需要自己定义,γ 越大,表示数结构越简单,其对较多叶节点的树(整棵树的叶节点)惩罚越大,λ 同理。
这种正则方式被作者证明效果很好。
树损失函数变形
ft(x)=wq(x)
故树损失函数变为
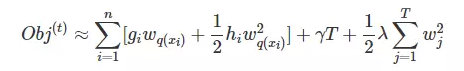
这样的式子真的没法处理,需要进一步变换
先看这张图
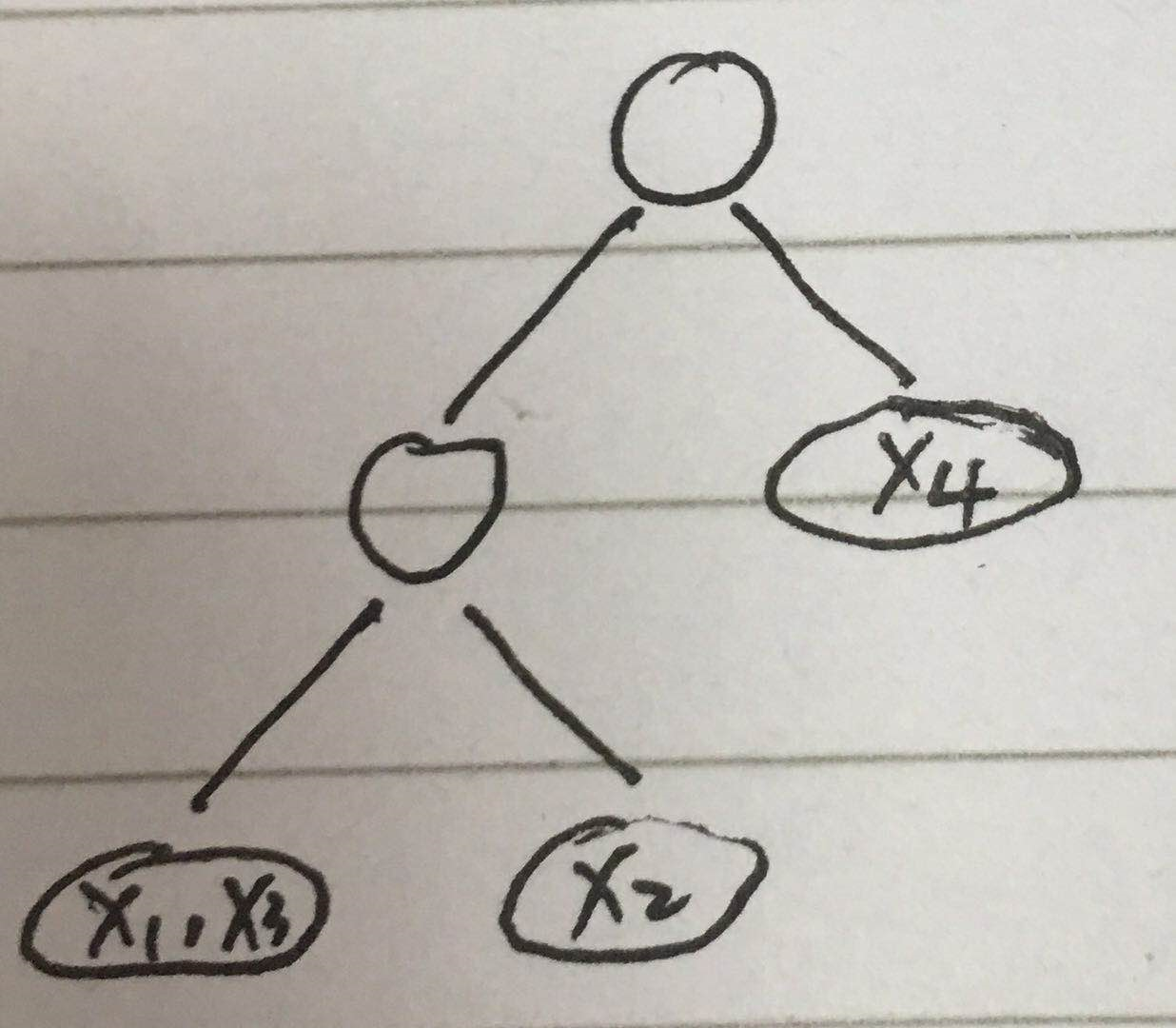
可以看到T个叶节点中包含了所有样本,也就是说遍历叶节点可以获取所有样本,且同一个叶节点中样本的预测值即wq(x)相同,
那么上式可以转化为
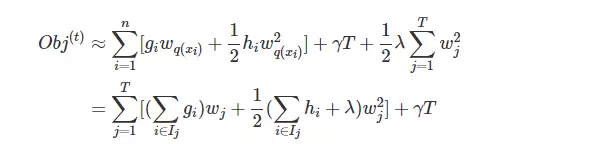
Ij表示第j个叶节点
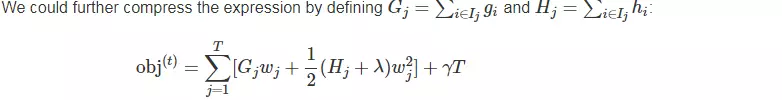
注意,对于一棵确定的树,G H 都是确定的,λ也是确定的,所有上式是一个关于w的二次函数,方程的解是 -b/2a,解带入方程就是二次曲线的最小值
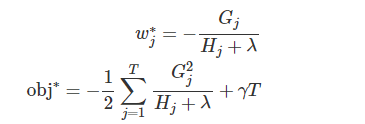
如果能使损失最小,那就是最好的树。
obj 可以理解为树的错误率,错误率越小越好。w就是预测值。
这就对应了信息增益等指标,就是分裂的评价指标,选择obj最小的属性进行分裂。
大致如图所示

这里稍微总结一下:
xgboost在上一棵树的基础上,新建一棵树,这棵树根据上一棵树的一阶导和二阶导确定最优的分裂方式。
建树
回忆一下传统的决策树如何建立,以id3为例,先根据一定的原则逐个按属性分裂,然后计算分裂前后的信息增益,选择增益最大的属性进行分裂。
xgboost貌似也是这个逻辑,因为没有其他好办法。
逐个按属性进行分裂,计算分裂前后的的损失(错误率),相减,取损失为正/负的,看谁减谁。
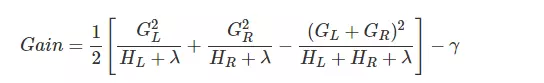

在分的属性中选择绝对值最大的,这里理解就好,语言表述会有些绕。
分裂节点
那按属性怎么分裂?方法几乎无限多,枚举肯定不现实。
回忆一下传统id3决策树,属性分裂有离散和连续之分,离散按属性值划分,连续只能二划分,排序,每两个值之间取个数(如均值)进行划分,
xgboost的属性是离散还是连续呢? 理论上也是都可以,不过回归应该是连续的。
xgboost在分裂时会防止过拟合,所以它尽可能的会减少叶节点的数量,也就是每次只进行2分裂,所以xgboost回归对应的基决策树是cart决策树。
实际分裂也大致等同于cart决策树,每次分裂都会计算损失
精确搜索法

怎么理解呢?大致思路等同于连续值处理

但是当样本太大时,这种方法也会很慢,于是作者提出了一种加速方法
近似搜索法
思路大致同精确搜索,只是在确定分裂点时,不是逐个探索,而是在对特征进行排序后,找出几个区间,作为分裂点
如先观察特征的分布情况,划分区间,再分裂。

具体作者又提出了一些选择
全局近似:即在训练前就确定分裂点,后面每棵树都用这些分裂点,这样提出候选分裂点的次数少,而每棵树探索的分裂点多,因为这种方法往往要多设一些分裂点,不然到后面就分不开了
局部近似:即每次建树时重新确定分裂点,这种方法每次尝试的少,对层数较深的树比较合适
作者做过如下尝试

桶的个数等于 1 / eps, 可以看出:
- 全局切分点的个数够多的时候,和Exact greedy算法性能相当。
- 局部切分点个数不需要那么多,因为每一次分裂都重新进行了选择。
======================== xgboost 进阶 ========================
步长
xgboost也可以加入步长,这也是防止过拟合的好方法
yt=yt-1+ηft(x)
η通常取0.1
yt-yt-1是残差,ηft(x)可以理解为在梯度上的学习,逼近目标值
双随机
xgboost还借鉴了随机森林的双随机处理方式,进一步防止过拟合,并加速训练和预测过程
xgboost实例
上文以回归为例进行原理描述,这里以分类为例进行实例解析
数据集
15个样本,2个特征
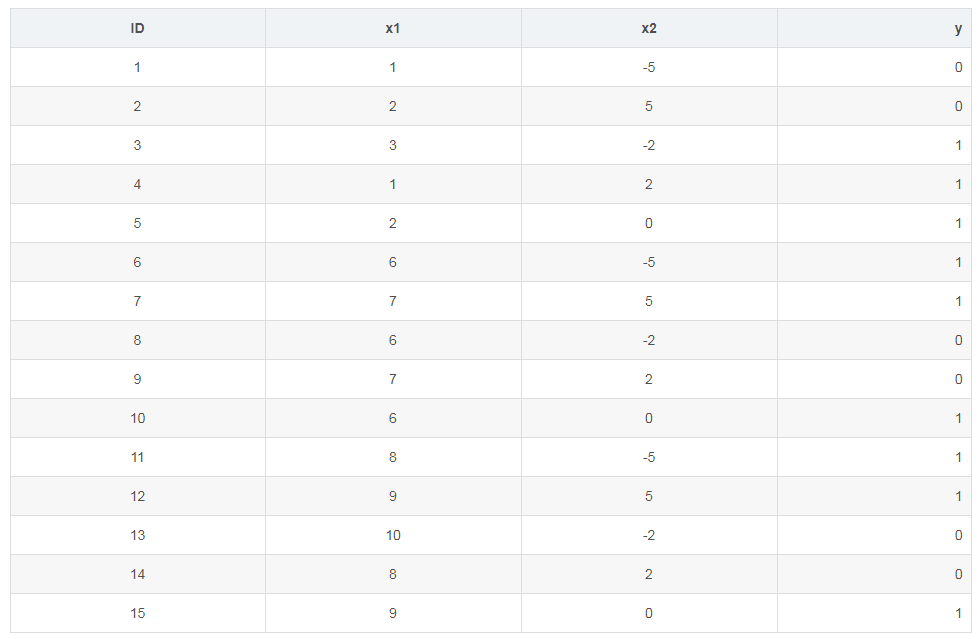
模型描述:基决策树深度max_depth为3,共2棵树num_boost_round=2,学习率eta=0.1,正则参数γ=0,λ=1,某损失函数(这不是重点,因为参考文献这里做的好像不对,所以我没有用它的)
可以假设
损失函数一阶导 gi=yi,pred-y
损失函数二阶导 hi=yi,pred*(1-yi,pred)
建第一棵树
因为在分裂过程中要计算每个节点的G H,而G H 就是节点中样本的g h 的和,故先把每个样本的g h求出来。
g h 是上一棵树的预测结果,这里是第一棵树,没有之前的预测结果,所以需要初始化一个结果,这里是01分类,我们初始化全部为0.5,当然其他也行
注意这里我们假设0.5是经过分类激活函数sigmoid后的值,是个概率值,因为经过sigmoid的值才能直接和真实标签作差,这点很重要,后面会用到,当然你也可以假设0.5是不经过sigmoid的值,这里理解就好,往后面看会理解的
根据一阶导二阶导公式计算出所有样本的g h,如下图

比如计算ID=1的样本y=0, g=0.5,0=0.5,h=0.5*(1-0.5)=0.25
下面开始分裂,目标是看看按哪个属性进行分裂增益最大
建造第一层
遍历属性,首先是第一个属性
第一个属性值排序 [1,2,3,6,7,8,9,10] 共8个值,
以1为阈值分裂,小于1为一边,不小于1为另一边,左边为空,右边为全部,gain=0
以2为阈值分裂,小于2为一边,不小于2为另一边,左边为[1,4],右边为[2,3,5,6,7,8...15],GL=0,HL=0.5,GR=-1.5,HR=3.25,gain=0.05572
其余类似,最终结果如下图
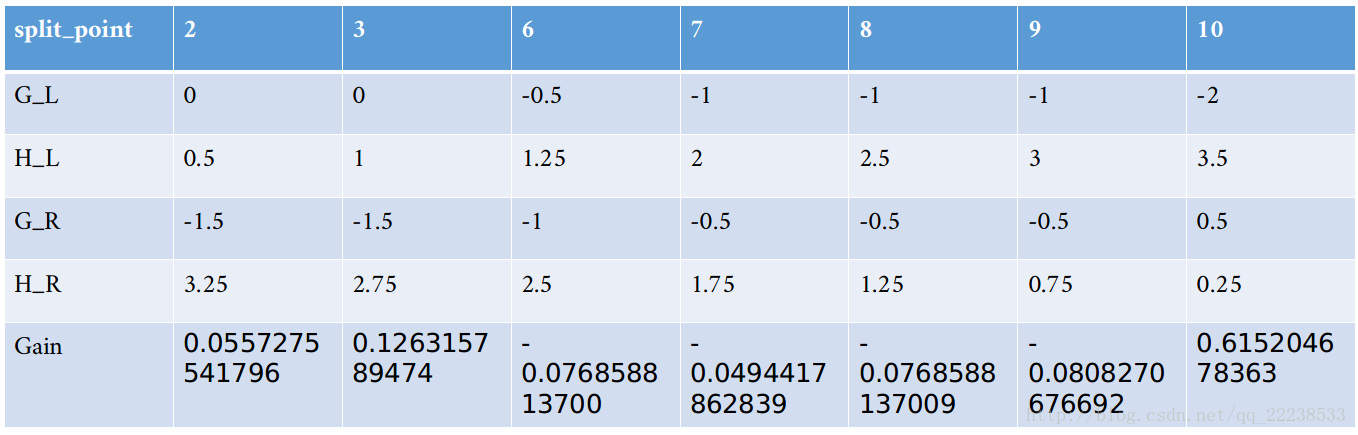
可以看到最大增益为0.615,对应分裂点为x<10
同样步骤处理第二个特征,得到结果如下图
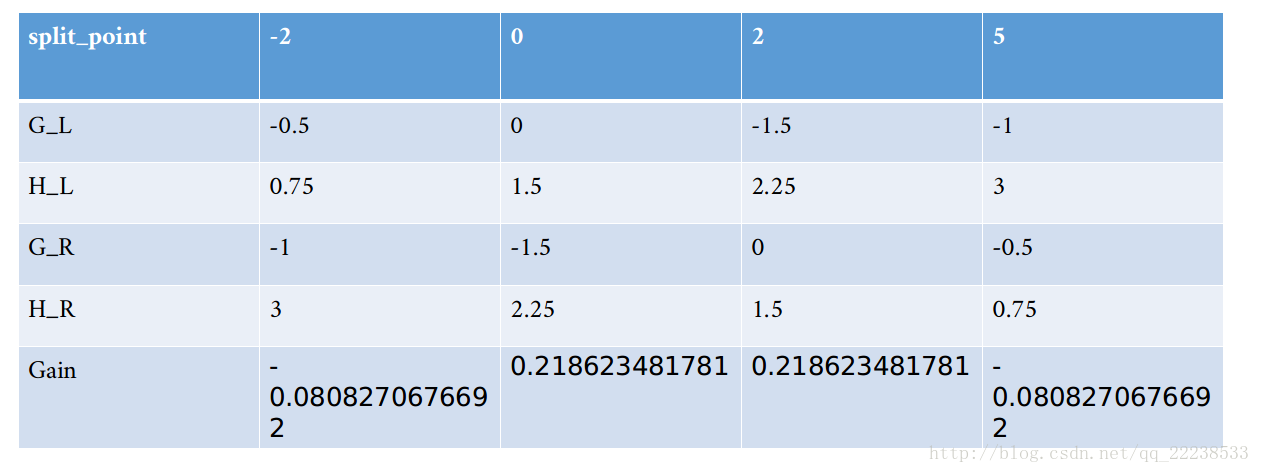
可以看到最大增益为0.2186,对应分裂点x<0
明显特征1的增益大于特征2的增益,所以按特征1进行分裂。
建造第二层
左子节点样本为[1,2,3,4,5,6,7,8,9,10,11,12,14,15]
右子节点样本为[13]
右边只有1个节点,不可再分,那么该节点的预测值为
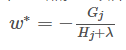
即 w=-0.4
左子节点按照第一层的方法划分,得到如下两个表

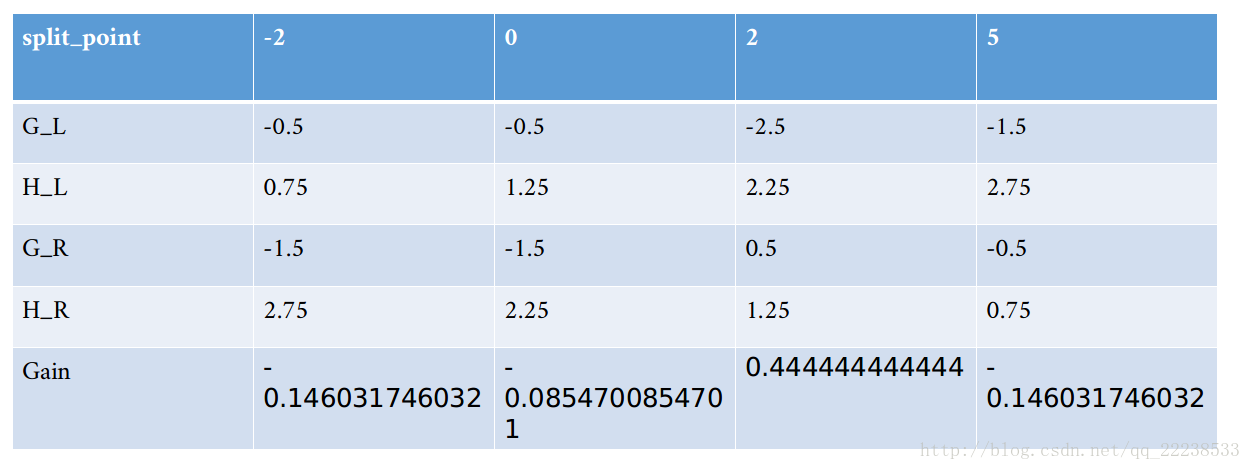
按特征2进行分裂,分裂点为x<2
第一棵树建造完毕
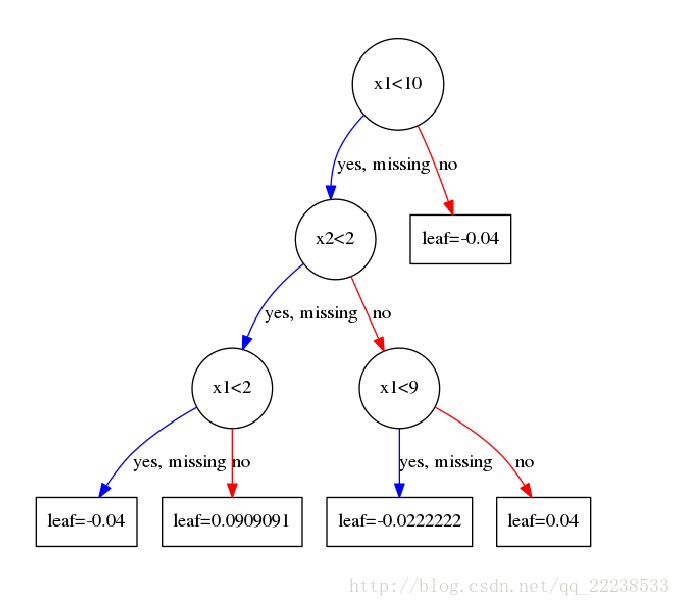
这里解释下第一层右子节点预测值为-0.04,但是上面计算出来是-0.4呀,这里相当于直接乘上了学习率0.1,后面树累加的时候就不用乘了
注意这里叶子节点上的值是没有经过sigmoid的值
建第二棵树
第二棵树的构造方法与第一棵树完全相同,只是第一棵树的基础值为初始化设定的,而第二棵树的基础值为第一棵树的预测结果,正是这个原因,在分裂计算增益寻找分裂点时两棵树才不相同。
那第一棵树的预测结果是什么呢?
是前1棵树的结果相加,即 f0+f1,但是f0是经过sigmoid的值,f1是没经过sigmoid的值,而我们需要的是没经过sigmoid的值,
所以需要把f0即初始化的0.5还原成没经过sigmoid的值,即已知函数和函数值,求x,很简单,x=0,故第一棵树的预测值为0+wq(x),然后需要经过sigmoid
*************** 注意重中之重 ***************
每棵树的初始值是经过sigmoid函数的,因为要与真实标签作差
每棵树的输出值是没有经过sigmoid函数的,这样才能与之前的输出值相加
同理得到了第二棵树
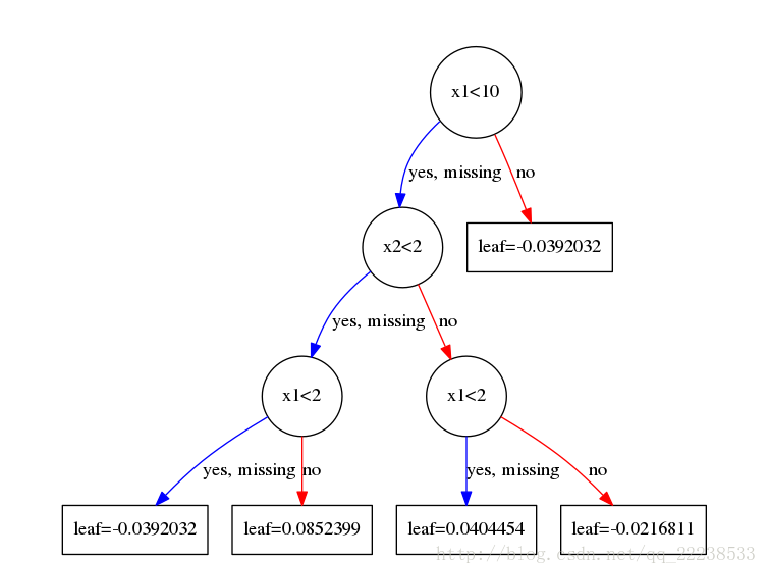
这样最后一棵树的结果即为预测值,当然分类要经过sigmoid函数。
至此模型完毕。
参考资料:
https://www.jianshu.com/p/7467e616f227
https://xgboost.readthedocs.io/en/latest/tutorials/model.html
https://blog.csdn.net/qq_22238533/article/details/79477547 手撸实例
https://www.hrwhisper.me/machine-learning-xgboost/ 此文章还有很多我这里没讲到
集成学习-xgboost的更多相关文章
- 集成学习——XGBoost(手推公式)
- 集成学习之Boosting —— XGBoost
集成学习之Boosting -- AdaBoost 集成学习之Boosting -- Gradient Boosting 集成学习之Boosting -- XGBoost Gradient Boost ...
- 大白话5分钟带你走进人工智能-第32节集成学习之最通俗理解XGBoost原理和过程
目录 1.回顾: 1.1 有监督学习中的相关概念 1.2 回归树概念 1.3 树的优点 2.怎么训练模型: 2.1 案例引入 2.2 XGBoost目标函数求解 3.XGBoost中正则项的显式表达 ...
- 集成学习小结(RF、adaboost、xgboost)
目录 回顾监督学习的一些要素 集成学习(学什么) bagging boosting 梯度提升(怎么学) GBDT Xgboost 几种模型比较 Xgboost 与 GBDT xgboost 和 LR ...
- 【Python机器学习实战】决策树与集成学习(七)——集成学习(5)XGBoost实例及调参
上一节对XGBoost算法的原理和过程进行了描述,XGBoost在算法优化方面主要在原损失函数中加入了正则项,同时将损失函数的二阶泰勒展开近似展开代替残差(事实上在GBDT中叶子结点的最优值求解也是使 ...
- 【集成学习】sklearn中xgboost模块的XGBClassifier函数
# 常规参数 booster gbtree 树模型做为基分类器(默认) gbliner 线性模型做为基分类器 silent silent=0时,不输出中间过程(默认) silent=1时,输出中间过程 ...
- 【集成学习】sklearn中xgboost模块中plot_importance函数(绘图--特征重要性)
直接上代码,简单 # -*- coding: utf-8 -*- """ ################################################ ...
- 笔记︱集成学习Ensemble Learning与树模型、Bagging 和 Boosting
本杂记摘录自文章<开发 | 为什么说集成学习模型是金融风控新的杀手锏?> 基本内容与分类见上述思维导图. . . 一.机器学习元算法 随机森林:决策树+bagging=随机森林 梯度提升树 ...
- 集成学习之Boosting —— AdaBoost原理
集成学习大致可分为两大类:Bagging和Boosting.Bagging一般使用强学习器,其个体学习器之间不存在强依赖关系,容易并行.Boosting则使用弱分类器,其个体学习器之间存在强依赖关系, ...
随机推荐
- hdu-6194 string string string 后缀数组 出现恰好K次的串的数量
最少出现K次我们可以用Height数组的lcp来得出,而恰好出现K次,我们只要除去最少出现K+1次的lcp即可. #include <cstdio> #include <cstrin ...
- hammer.js方法总结(只做了一个简单的demo)
html <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <titl ...
- 31. Next Permutation (java 字典序生成下一个排列)
题目: Implement next permutation, which rearranges numbers into the lexicographically next greater per ...
- 『Python』setup.py简介
setup.py应用场合 网上见到其他人这样介绍: 假如我在本机开发一个程序,需要用到python的redis.mysql模块以及自己编写的redis_run.py模块.我怎么实现在服务器上去发布该系 ...
- 谈一谈Vector类
一.关于Vector类的注意事项 1.从 Java 2 平台 v1.2 开始,vector类改进为实现 List 接口,成为 Java Collections Framework 的成员:所以vect ...
- hbase的api操作
创建maven工程,修改jdk pom文件里添加需要的jar包 dependencies> <dependency> <groupId>jdk.tools</gro ...
- Spring Boot集成Thymeleaf
Thymeleaf是一个java类库,是一个xml/xhtml/html5的模板引擎,可以作为mvc的web应用的view层.Thymeleaf提供了额外的模块与Spring MVC集成,所以我们可以 ...
- hdu 1025LIS思路同1257 二分求LIS
题目: Constructing Roads In JGShining's Kingdom Time Limit: 2000/1000 MS (Java/Others) Memory Limit ...
- Vue引入jQuery
1.在项目中安装jquery npm install jquery --save-dev 或者 打开package.json文件,在里面加入这行代码,jquery后面的是版本,根据你自己需求更改. d ...
- SQL Server 创建触发器(trigger)
update 触发器: if(OBJECT_ID('trigger_compost_up') is not null) drop trigger trigger_compost_up go creat ...