ELK+Filebeat+Kafka+ZooKeeper 构建海量日志分析平台
日志分析平台,架构图如下:
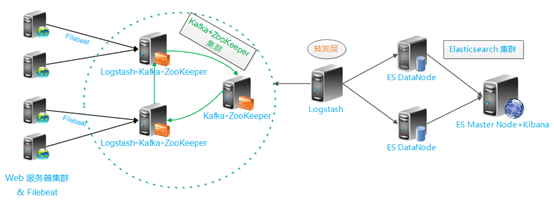
架构解读 : (整个架构从左到右,总共分为5层)
第一层、数据采集层
最左边的是业务服务器集群,上面安装了filebeat做日志采集,同时把采集的日志分别发送给两个logstash服务。
第二层、
logstash服务把接受到的日志经过格式处理,转存到本地的kafka broker+zookeeper集群中。
第三层、数据转发层
这个单独的Logstash节点会实时去kafka broker集群拉数据,转发至ES DataNode。
第四层、数据持久化存储
ES DataNode 会把收到的数据,写磁盘,建索引库。
第五层、数据检索,数据展示
ES Master + Kibana 主要协调ES集群,处理数据检索请求,数据展示。
一、服务规划:
| 主机名 | IP地址 | 服务 | 服务作用 |
| ZooKeeper-Kafka-01 | 10.200.3.85 | logstash+Kafka+ZooKeeper | 数据处理层,数据缓存层 |
| ZooKeeper-Kafka-02 | 10.200.3.86 | logstash+Kafka+ZooKeeper | 数据处理层,数据缓存层 |
| ZooKeeper-Kafka-03 | 10.200.3.87 | Kafka+ZooKeeper | 数据缓存层 |
| logstash-to-es-01 | 10.200.3.88 | logstash |
转发层logstash转发到es |
| logstash-to-es-02 | 10.200.3.89 | logstash |
转发层logstash转发到es |
| Esaster-Kibana | 10.200.3.90 | ES Master+Kibana | 数据持久化存储和数据展示 |
| ES-DataNode01 | 10.200.3.91 |
ES DataNode |
数据持久化存储 |
| ES-DataNode02 | 10.200.3.92 |
ES DataNode |
数据持久化存储 |
| nginx-filebeat | 10.20.9.31 | nginx-filebeat | filebeat收集nginx日志 |
| java-filebeat | 10.20.9.52 | java-filebeat | filebeat收集tomcat日志 |
2、软件下载和安装:
所有服务器Java jdk版本必须在1.8以上.
Elasticsearch下载地址:
wget -P /usr/local/src/ https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.6.2.tar.gz
logstash下载地址:
wget -P /usr/local/src/ https://artifacts.elastic.co/downloads/logstash/logstash-5.6.2.tar.gz
kibana下载地址:
wget -P /usr/local/src/ https://artifacts.elastic.co/downloads/kibana/kibana-5.6.2-linux-x86_64.tar.gz
Zookeeper+Kafka下载地址:
#wget http://mirrors.hust.edu.cn/apache/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz
#wget http://mirror.bit.edu.cn/apache/kafka/1.1.0/kafka_2.12-1.1.0.tgz
filebeat下载:
#curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-5.6.8-x86_64.rpm
#rpm -vi filebeat-5.6.-x86_64.rpm
3、配置安装服务:
一、Elasticsearch集群服务安装:
[root@Esaster-Kibana src]# tar -zxvf elasticsearch-5.6..tar.gz -C /usr/local/
[root@Esaster-Kibana src]# cd ..
[root@Esaster-Kibana local]# ln -s elasticsearch-5.6. elasticsearch
创建用户组
[root@Esaster-Kibana local]# groupadd elsearch
[root@Esaster-Kibana local]# useradd -g elsearch elsearch
[root@Esaster-Kibana local]# chown -R elsearch:elsearch elasticsearch*
设置系统的相关参数,如果不设置参数将会存在相关的问题导致不能启动
[root@Esaster-Kibana local]# vim /etc/security/limits.conf
# End of file
* soft nproc
* hard nproc
* soft nofile
* hard nofile
elsearch soft memlock unlimited
elsearch hard memlock unlimited
修改最大线程数的配置
[root@Esaster-Kibana ~]# vim /etc/security/limits.d/-nproc.conf
* soft nproc
root soft nproc unlimited [root@Esaster-Kibana ~]# vim /etc/sysctl.conf
vm.max_map_count=
fs.file-max=
[root@Esaster-Kibana ~]# sysctl -p
配置文件
[root@Esaster-Kibana ~]# vim /usr/local/elasticsearch/config/elasticsearch.yml
network.host: 10.200.3.90
http.port:
启动程序
[root@Esaster-Kibana ~]# su - elsearch
[elsearch@Esaster-Kibana ~]$ /usr/local/elasticsearch/bin/elasticsearch -d
验证有没有启动成功.
[elsearch@Esaster-Kibana ~]$ curl http://10.200.3.90:9200
{
"name" : "AUtPyaG",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "5hFyJ-4TShaaevOp4q-TUg",
"version" : {
"number" : "5.6.2",
"build_hash" : "57e20f3",
"build_date" : "2017-09-23T13:16:45.703Z",
"build_snapshot" : false,
"lucene_version" : "6.6.1"
},
"tagline" : "You Know, for Search"
}
至此单台的Elasticsearch部署完成,如果是集群的话只需要改elasticsearch.yml文件,添加选项即可!!
Elasticsearch集群部署
10.200.3.90 ES Master+Kibana
10.200.3.91 ES DataNode
10.200.3.92 ES DataNode
1.将3.90上面的 Elasticsearch复制到另外两台节点服务器中,只需要更改配置文件即可.
2.Elasticsearch集群Master配置文件如下(10.200.3.90:9200):
[elsearch@Esaster-Kibana config]$ cat elasticsearch.yml
# ======================== Elasticsearch Configuration =========================
#集群的名称,同一个集群该值必须设置成相同的
cluster.name: my-cluster
#该节点的名字
node.name: node-
#该节点有机会成为master节点
node.master: true
#该节点可以存储数据
node.data: true
path.data: /usr/local/elasticsearch/data
path.logs: /usr/local/elasticsearch/logs
bootstrap.memory_lock: true
#设置绑定的IP地址,可以是IPV4或者IPV6
network.bind_host: 0.0.0.0
#设置其他节点与该节点交互的IP地址
network.publish_host: 10.200.3.90
#该参数用于同时设置bind_host和publish_host
network.host: 10.200.3.90
#设置节点之间交互的端口号
transport.tcp.port:
#设置是否压缩tcp上交互传输的数据
transport.tcp.compress: true
#设置http内容的最大大小]
http.max_content_length: 100mb
#是否开启http服务对外提供服务
http.enabled: true
http.port:
discovery.zen.ping.unicast.hosts: ["10.200.3.90:9300","10.200.3.91:9300", "10.200.3.92:9300"]
discovery.zen.minimum_master_nodes:
http.cors.enabled: true
http.cors.allow-origin: "*"
3.Elasticsearch DataNode01节点(10.200.3.91)
[root@ES-DataNode01 config]# vim elasticsearch.yml |grep -v ^$
# ======================== Elasticsearch Configuration =========================
#集群的名称,同一个集群该值必须设置成相同的
cluster.name: my-cluster
#该节点的名字
node.name: node-
#该节点有机会成为master节点
node.master: true
#该节点可以存储数据
node.data: true
path.data: /usr/local/elasticsearch/data
path.logs: /usr/local/elasticsearch/logs
bootstrap.memory_lock: true
#设置绑定的IP地址,可以是IPV4或者IPV6
network.bind_host: 0.0.0.0
#设置其他节点与该节点交互的IP地址
network.publish_host: 10.200.3.91
#该参数用于同时设置bind_host和publish_host
network.host: 10.200.3.91
#设置节点之间交互的端口号
transport.tcp.port:
#设置是否压缩tcp上交互传输的数据
transport.tcp.compress: true
#设置http内容的最大大小]
http.max_content_length: 100mb
#是否开启http服务对外提供服务
http.enabled: true
http.port:
discovery.zen.ping.unicast.hosts: ["10.200.3.90:9300","10.200.3.91:9300", "10.200.3.92:9300"]
discovery.zen.minimum_master_nodes:
http.cors.enabled: true
http.cors.allow-origin: "*"
4.Elasticsearch DataNode02节点(10.200.3.92)
[root@ES-DataNode02 config]# vim elasticsearch.yml |grep -v ^$
# ======================== Elasticsearch Configuration =========================
#集群的名称,同一个集群该值必须设置成相同的
cluster.name: my-cluster
#该节点的名字
node.name: node-
#该节点有机会成为master节点
node.master: true
#该节点可以存储数据
node.data: true
path.data: /usr/local/elasticsearch/data
path.logs: /usr/local/elasticsearch/logs
bootstrap.memory_lock: true
#设置绑定的IP地址,可以是IPV4或者IPV6
network.bind_host: 0.0.0.0
#设置其他节点与该节点交互的IP地址
network.publish_host: 10.200.3.92
#该参数用于同时设置bind_host和publish_host
network.host: 10.200.3.92
#设置节点之间交互的端口号
transport.tcp.port:
#设置是否压缩tcp上交互传输的数据
transport.tcp.compress: true
#设置http内容的最大大小]
http.max_content_length: 100mb
#是否开启http服务对外提供服务
http.enabled: true
http.port:
discovery.zen.ping.unicast.hosts: ["10.200.3.90:9300","10.200.3.91:9300", "10.200.3.92:9300"]
discovery.zen.minimum_master_nodes:
http.cors.enabled: true
http.cors.allow-origin: "*"
5.启动每个服务
# /usr/local/elasticsearch/bin/elasticsearch -d
使用curl http://10.200.3.92:9200查看输入和查看日志信息.如果没有错误则部署成功.
至此Elasticsearch集群部署完成.
6.通过cluster API查看集群状态:
[root@ES-DataNode02 config]# curl -XGET 'http://10.200.3.90:9200/_cluster/health?pretty=true'
{
"cluster_name" : "my-cluster",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : ,
"number_of_data_nodes" : ,
"active_primary_shards" : ,
"active_shards" : ,
"relocating_shards" : ,
"initializing_shards" : ,
"unassigned_shards" : ,
"delayed_unassigned_shards" : ,
"number_of_pending_tasks" : ,
"number_of_in_flight_fetch" : ,
"task_max_waiting_in_queue_millis" : ,
"active_shards_percent_as_number" : 100.0
}
配置head插件:
首先安装npm软件包
参考文档:http://www.runoob.com/nodejs/nodejs-install-setup.html
Head插件安装:
参考文档: https://blog.csdn.net/gamer_gyt/article/details/59077189
Elasticsearch 5.2.x 使用 Head 插件连接不上集群
参考文档:https://www.cnblogs.com/zklidd/p/6433123.html
访问地址:http://10.200.3.90:9100/
二、安装kibana5.6(10.200.3.90):
#tar -zxvf kibana-5.6.-linux-x86_64.tar.gz -C /usr/local/
[root@Esaster-Kibana local]# ln -s kibana-5.6.-linux-x86_64 kibana
[root@Esaster-Kibana local]# cd kibana/config/
[root@Esaster-Kibana config]# vim kibana.yml
server.port:
server.host: "10.200.3.90"
server.name: "Esaster-Kibana"
elasticsearch.url: http://10.200.3.90:9200
启动kibana服务
[root@Esaster-Kibana config]#/usr/local/kibana/bin/kibana &
访问地址:
http://10.200.3.90:5601/app/kibana
三、Zookeeper+Kafka集群部署:
10.200.3.85 Kafka+ZooKeeper
10.200.3.86 Kafka+ZooKeeper
10.200.3.87 Kafka+ZooKeeper
Zookeeper+Kafka下载地址:
#wget http://mirrors.hust.edu.cn/apache/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz
#wget http://mirror.bit.edu.cn/apache/kafka/1.1.0/kafka_2.12-1.1.0.tgz
1.三台主机hosts如下,必须保持一致.
# cat /etc/hosts
10.200.3.85 ZooKeeper-Kafka-
10.200.3.86 ZooKeeper-Kafka-
10.200.3.87 ZooKeeper-Kafka-
2.安装zookeeper
# 在master节点上操作
[root@ZooKeeper-Kafka- src]# tar -zxvf zookeeper-3.4..tar.gz -C /usr/local/
[root@ZooKeeper-Kafka- src]# cd ..
[root@ZooKeeper-Kafka- local]# ln -s zookeeper-3.4. zookeeper
[root@ZooKeeper-Kafka- local]# cd zookeeper/conf/
[root@ZooKeeper-Kafka- conf]# cp zoo_sample.cfg zoo.cfg
tickTime=
initLimit=
syncLimit=
dataDir=/tmp/zookeeper
clientPort=
server.=ZooKeeper-Kafka-::
server.=ZooKeeper-Kafka-::
server.=ZooKeeper-Kafka-::
3.创建dataDir目录创建/tmp/zookeeper
# 在master节点上
[root@ZooKeeper-Kafka- conf]# mkdir /tmp/zookeeper
[root@ZooKeeper-Kafka- conf]# touch /tmp/zookeeper/myid
[root@ZooKeeper-Kafka- conf]# echo > /tmp/zookeeper/myid
.将zookeeper文件复制到另外两个节点:
[root@ZooKeeper-Kafka- local]# scp -r zookeeper-3.4./ 10.200.3.86:/usr/local/
[root@ZooKeeper-Kafka- local]# scp -r zookeeper-3.4./ 10.200.3.87:/usr/local/
4.在两个slave节点创建目录和文件
#ZooKeeper-Kafka-02节点:
[root@ZooKeeper-Kafka- local]# ln -s zookeeper-3.4. zookeeper
[root@ZooKeeper-Kafka- local]# mkdir /tmp/zookeeper
[root@ZooKeeper-Kafka- local]# touch /tmp/zookeeper/myid
[root@ZooKeeper-Kafka- local]# echo > /tmp/zookeeper/myid
#ZooKeeper-Kafka-03节点
[root@ZooKeeper-Kafka- local]# ln -s zookeeper-3.4. zookeeper
[root@ZooKeeper-Kafka- local]# mkdir /tmp/zookeeper
[root@ZooKeeper-Kafka- local]# touch /tmp/zookeeper/myid
[root@ZooKeeper-Kafka- local]# echo > /tmp/zookeeper/myid
5.分别在每个节点上启动 zookeeper测试:
[root@ZooKeeper-Kafka- zookeeper]# ./bin/zkServer.sh start
[root@ZooKeeper-Kafka- zookeeper]# ./bin/zkServer.sh start
[root@ZooKeeper-Kafka- zookeeper]# ./bin/zkServer.sh start
6.查看状态:
[root@ZooKeeper-Kafka- zookeeper]# ./bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Mode: follower
[root@ZooKeeper-Kafka- zookeeper]# ./bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Mode: leader
[root@ZooKeeper-Kafka- zookeeper]# ./bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Mode: follower
至此zookeeper集群安装成功!!!
Kafka集群安装配置
[root@ZooKeeper-Kafka- src]# tar -zxvf kafka_2.-1.1..tgz -C /usr/local/
[root@ZooKeeper-Kafka- src]# cd ..
[root@ZooKeeper-Kafka- local]# ln -s kafka_2.-1.1. kafka
修改server.properties文件
[root@ZooKeeper-Kafka- local]# cd kafka/config/
[root@ZooKeeper-Kafka- config]# vim server.properties
broker.id=
listeners=PLAINTEXT://ZooKeeper-Kafka-01:9092
advertised.listeners=PLAINTEXT://ZooKeeper-Kafka-01:9092
num.network.threads=
num.io.threads=
socket.send.buffer.bytes=
socket.receive.buffer.bytes=
socket.request.max.bytes=
log.dirs=/tmp/kafka-logs
num.partitions=
num.recovery.threads.per.data.dir=
offsets.topic.replication.factor=
transaction.state.log.replication.factor=
transaction.state.log.min.isr=
log.retention.hours=
log.segment.bytes=
log.retention.check.interval.ms=
zookeeper.connect=ZooKeeper-Kafka-:,ZooKeeper-Kafka-:,ZooKeeper-Kafka-:
zookeeper.connection.timeout.ms=
group.initial.rebalance.delay.ms=
delete.topic.enable=true
[root@ZooKeeper-Kafka- config]#
将 kafka_2.12-1.1.0 文件夹复制到另外两个节点下
[root@ZooKeeper-Kafka- local]# scp -r kafka_2.-1.1./ 10.200.3.86:/usr/local/
[root@ZooKeeper-Kafka- local]# scp -r kafka_2.-1.1./ 10.200.3.87:/usr/local/
并修改每个节点对应的 server.properties 文件的 broker.id和listeners、advertised.listeners的名称.
ZooKeeper-Kafka-02主机配置文件如下:
[root@ZooKeeper-Kafka- config]# cat server.properties
broker.id=
listeners=PLAINTEXT://ZooKeeper-Kafka-02:9092
advertised.listeners=PLAINTEXT://ZooKeeper-Kafka-02:9092
num.network.threads=
num.io.threads=
socket.send.buffer.bytes=
socket.receive.buffer.bytes=
socket.request.max.bytes=
log.dirs=/tmp/kafka-logs
num.partitions=
num.recovery.threads.per.data.dir=
offsets.topic.replication.factor=
transaction.state.log.replication.factor=
transaction.state.log.min.isr=
log.retention.hours=
log.segment.bytes=
log.retention.check.interval.ms=
zookeeper.connect=ZooKeeper-Kafka-:,ZooKeeper-Kafka-:,ZooKeeper-Kafka-:
zookeeper.connection.timeout.ms=
group.initial.rebalance.delay.ms=
delete.topic.enable=true
ZooKeeper-Kafka-03主机配置文件如下:
[root@ZooKeeper-Kafka- config]# cat server.properties
broker.id=
listeners=PLAINTEXT://ZooKeeper-Kafka-03:9092
advertised.listeners=PLAINTEXT://ZooKeeper-Kafka-03:9092
num.network.threads=
num.io.threads=
socket.send.buffer.bytes=
socket.receive.buffer.bytes=
socket.request.max.bytes=
log.dirs=/tmp/kafka-logs
num.partitions=
num.recovery.threads.per.data.dir=
offsets.topic.replication.factor=
transaction.state.log.replication.factor=
transaction.state.log.min.isr=
log.retention.hours=
log.segment.bytes=
log.retention.check.interval.ms=
zookeeper.connect=ZooKeeper-Kafka-:,ZooKeeper-Kafka-:,ZooKeeper-Kafka-:
zookeeper.connection.timeout.ms=
group.initial.rebalance.delay.ms=
delete.topic.enable=true
启动服务:
#bin/kafka-server-start.sh config/server.properties &
Zookeeper+Kafka集群测试
创建topic:
[root@ZooKeeper-Kafka- kafka]# bin/kafka-topics.sh --create --zookeeper ZooKeeper-Kafka-:, ZooKeeper-Kafka-:, ZooKeeper-Kafka-: --replication-factor --partitions --topic test
显示topic:
[root@ZooKeeper-Kafka- kafka]# bin/kafka-topics.sh --describe --zookeeper ZooKeeper-Kafka-:, ZooKeeper-Kafka-:, ZooKeeper-Kafka-: --topic test
列出topic:
[root@ZooKeeper-Kafka- kafka]# bin/kafka-topics.sh --list --zookeeper ZooKeeper-Kafka-:, ZooKeeper-Kafka-:, ZooKeeper-Kafka-:
test
[root@ZooKeeper-Kafka- kafka]#
创建 producer(生产者);
# 在master节点上 测试生产消息
[root@ZooKeeper-Kafka- kafka]# bin/kafka-console-producer.sh --broker-list ZooKeeper-Kafka-: -topic test
>hello world
>[-- ::,] INFO Updated PartitionLeaderEpoch. New: {epoch:, offset:}, Current: {epoch:-, offset:-} for Partition: test-. Cache now contains entries. (kafka.server.epoch.LeaderEpochFileCache)
this is example ...
>[-- ::,] INFO Updated PartitionLeaderEpoch. New: {epoch:, offset:}, Current: {epoch:-, offset:-} for Partition: test-. Cache now contains entries. (kafka.server.epoch.LeaderEpochFileCache)
welcome to china
>[-- ::,] INFO Updated PartitionLeaderEpoch. New: {epoch:, offset:}, Current: {epoch:-, offset:-} for Partition: test-. Cache now contains entries. (kafka.server.epoch.LeaderEpochFileCache)
创建 consumer(消费者):
# 在ZooKeeper-Kafka-02节点上 测试消费
[root@ZooKeeper-Kafka- kafka]# bin/kafka-console-consumer.sh --zookeeper ZooKeeper-Kafka-:, ZooKeeper-Kafka-:, ZooKeeper-Kafka-: -topic test --from-beginning
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
this is example ...
hello world
[-- ::,] INFO Updated PartitionLeaderEpoch. New: {epoch:, offset:}, Current: {epoch:-, offset:-} for Partition: test-. Cache now contains entries. (kafka.server.epoch.LeaderEpochFileCache)
welcome to china
#在ZooKeeper-Kafka-03节点上 测试消费
[root@ZooKeeper-Kafka- kafka]# bin/kafka-console-consumer.sh --zookeeper ZooKeeper-Kafka-:, ZooKeeper-Kafka-:, ZooKeeper-Kafka-: -topic test --from-beginning
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
welcome to china
hello world
this is example ...
然后在 producer 里输入消息,consumer 中就会显示出同样的内容,表示消费成功!
删除 topic
[root@ZooKeeper-Kafka- kafka]# bin/kafka-topics.sh --delete --zookeeper ZooKeeper-Kafka-:, ZooKeeper-Kafka-:, ZooKeeper-Kafka-: --topic test
启动和关闭服务:
#启动服务:
bin/kafka-server-start.sh config/server.properties &
#停止服务:
bin/kafka-server-stop.sh
至此Zookeeper+Kafka集群配置成功.
四、logstash安装和配置
hlogstash-to-kafka端logstash安装配置(logstash从filebeat读取日志后写入到kafka中):
主机(10.200.3.85 10.200.3.86)
[root@ZooKeeper-Kafka- src]# tar -zxvf logstash-5.6..tar.gz -C [root@ZooKeeper-Kafka- src]# cd /usr/local/
[root@ZooKeeper-Kafka local]# ln -s logstash-5.6. logstash-to-kafka [root@ZooKeeper-Kafka- config]# cat logstash.conf
input {
beats {
host => "0.0.0.0"
port =>
}
} filter {
if [log_topic] !~ "^nginx_" {
drop {}
}
ruby {
code => "
require 'date'
event.set('log_filename',event.get('source').gsub(/\/.*\//,'').downcase)
#tmptime = event.get('message').split(']')[].delete('[')
#timeobj = DateTime.parse(tmptime)
#event.set('log_timestamp',tmptime)
#event.set('log_date',timeobj.strftime('%Y-%m-%d'))
#event.set('log_year',timeobj.year)
#event.set('log_time_arr',[timeobj.year,timeobj.month,timeobj.day,timeobj.hour,timeobj.minute])
"
}
#date {
# match => [ "log_timestamp" , "ISO8601" ]
#}
mutate {
remove_field => [ "source" ]
remove_field => [ "host" ]
#remove_field =>["message"] } } output { stdout {
codec => rubydebug }
kafka {
bootstrap_servers => "10.200.3.85:9092,10.200.3.86:9092,10.200.3.87:9092"
topic_id => "%{log_topic}"
codec => json {}
} # elasticsearch {
# hosts => ["10.200.3.90:9200","10.200.3.91:9200","10.200.3.92:9200"]
# index => "logstash-%{log_filename}-%{+YYYY.MM.dd}"
# template_overwrite => true
#
# } }
nginx日志过滤和转发
[root@ZooKeeper-Kafka- config]# cat logstash.conf
input {
beats {
host => "0.0.0.0"
port =>
}
} filter {
if [log_topic] !~ "^tomcat_"{
drop {}
}
ruby {
code => "
require 'date'
event.set('log_filename',event.get('source').gsub(/\/.*\//,'').downcase)
#tmptime = event.get('message').split(']')[].delete('[')
#timeobj = DateTime.parse(tmptime)
#event.set('log_timestamp',tmptime)
#event.set('log_date',timeobj.strftime('%Y-%m-%d'))
#event.set('log_year',timeobj.year)
#event.set('log_time_arr',[timeobj.year,timeobj.month,timeobj.day,timeobj.hour,timeobj.minute])
"
} #date {
# match => [ "log_timestamp" , "ISO8601" ]
#}
mutate {
remove_field => [ "host" ]
remove_field =>["source"] } } output { stdout {
codec => rubydebug }
kafka {
bootstrap_servers => "10.200.3.85:9092,10.200.3.86:9092,10.200.3.87:9092"
topic_id => "%{log_topic}"
codec => json {}
} } [root@ZooKeeper-Kafka- config]#
tomcat日志收集及转发
转发层logstash安装,logstash从kafka读取日志写入到es中(10.200.3.88、10.200.3.89)
[root@logstash- src]# tar -zxvf logstash-5.6..tar.gz -C /usr/local/
[root@logstash- src]# cd /usr/local/
[root@logstash- local]# ln -s logstash-5.6. logstash-to-es
[root@logstash- config]# cat logstash.conf
input {
kafka {
bootstrap_servers => "ZooKeeper-Kafka-01:9092,ZooKeeper-Kafka-02:9092,ZooKeeper-Kafka-03:9092"
#bootstrap_servers => "10.200.3.85:9092,10.200.3.86:9092,10.200.3.87:9092"
group_id => "nginx_logs"
topics => ["nginx_logs"]
consumer_threads =>
decorate_events => true
codec => json {}
}
} filter {
if [log_filename] =~ "_access.log" {
grok {
patterns_dir => "./patterns"
match => { "message" => "%{NGINXACCESS}" } }
} else {
drop {}
} mutate {
remove_field => [ "log_time_arr" ]
} } output { stdout {
codec => rubydebug } elasticsearch {
hosts => ["10.200.3.90:9200","10.200.3.91:9200","10.200.3.92:9200"]
index => "logstash-%{log_filename}-%{+YYYY.MM.dd}"
template_overwrite => true
flush_size=> } } [root@logstash- config]#
从kafka读取nginx日志,转发存储到es中
[root@logstash- patterns]# cat nginx_access
ERNAME [a-zA-Z\.\@\-\+_%]+
NGUSER %{NGUSERNAME}
NGINXACCESS \[%{TIMESTAMP_ISO8601:log_timestamp1}\] %{IPORHOST:clientip} - %{NOTSPACE:remote_user} \[%{HTTPDATE:timestamp}\] \"(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})\" %{NUMBER:response} (?:%{NUMBER:bytes}|-) %{QS:referrer} %{QS:agent} %{NOTSPACE:http_x_forwarded_for} #####################################
#Nginx.conf端配置格式:
log_format main '[$time_iso8601] $remote_addr - $remote_user "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
Nginx日志格式如下
[root@logstash- config]# cat logstash.conf
input {
kafka {
bootstrap_servers => "ZooKeeper-Kafka-01:9092,ZooKeeper-Kafka-02:9092,ZooKeeper-Kafka-03:9092"
#bootstrap_servers => "10.200.3.85:9092,10.200.3.86:9092,10.200.3.87:9092"
group_id => "tomcat_logs"
topics => ["tomcat_logs"]
consumer_threads =>
decorate_events => true
codec => json {}
} } filter { grok {
patterns_dir => "./patterns"
match => { "message" => "%{CATALINALOG}" } } mutate {
remove_field => [ "log_time_arr" ]
} } output { stdout {
codec => rubydebug } elasticsearch {
hosts => ["10.200.3.90:9200","10.200.3.91:9200","10.200.3.92:9200"]
index => "logstash-%{project_name}-%{log_filename}-%{+YYYY.MM.dd}"
template_overwrite => true
flush_size=> } } [root@logstash- config]#
从kafka读取tomcat日志,转发存储到es中
[root@logstash- logstash-to-es]# cat patterns/java_access
JAVACLASS (?:[a-zA-Z$_][a-zA-Z$_0-]*\.)*[a-zA-Z$_][a-zA-Z$_0-]*
#Space is an allowed character to match special cases like 'Native Method' or 'Unknown Source'
JAVAFILE (?:[A-Za-z0-9_. -]+)
#Allow special <init> method
JAVAMETHOD (?:(<init>)|[a-zA-Z$_][a-zA-Z$_0-]*)
#Line number is optional in special cases 'Native method' or 'Unknown source'
JAVASTACKTRACEPART %{SPACE}at %{JAVACLASS:class}\.%{JAVAMETHOD:method}\(%{JAVAFILE:file}(?::%{NUMBER:line})?\)
# Java Logs
JAVATHREAD (?:[A-Z]{}-Processor[\d]+)
JAVACLASS (?:[a-zA-Z0--]+\.)+[A-Za-z0-$]+
JAVAFILE (?:[A-Za-z0-9_.-]+)
JAVASTACKTRACEPART at %{JAVACLASS:class}\.%{WORD:method}\(%{JAVAFILE:file}:%{NUMBER:line}\)
JAVALOGMESSAGE (.*)
# MMM dd, yyyy HH:mm:ss eg: Jan , :: AM
CATALINA_DATESTAMP %{MONTH} %{MONTHDAY}, %{YEAR} %{HOUR}:?%{MINUTE}(?::?%{SECOND}) (?:AM|PM)
# yyyy-MM-dd HH:mm:ss,SSS ZZZ eg: -- ::, -
TOMCAT_DATESTAMP %{YEAR}-%{MONTHNUM}-%{MONTHDAY} %{HOUR}:?%{MINUTE}(?::?%{SECOND}) %{ISO8601_TIMEZONE}
CATALINALOG %{CATALINA_DATESTAMP:timestamp} %{JAVACLASS:class} %{JAVALOGMESSAGE:logmessage}
# -- ::, - | ERROR | com.example.service.ExampleService - something compeletely unexpected happened...
TOMCATLOG \[%{TOMCAT_DATESTAMP:timestamp}\] \| %{LOGLEVEL:level} \| %{JAVACLASS:class} - %{JAVALOGMESSAGE:logmessage} # -- ::-|INFO|-Root WebApplicationContext: initialization started
MYTIMESTAMP %{YEAR}-%{MONTHNUM}-%{MONTHDAY} %{HOUR}:%{MINUTE}:%{SECOND}
MYLOG %{MYTIMESTAMP:mytimestamp}-\|%{LOGLEVEL:level}\|-%{JAVALOGMESSAGE:logmsg} ACCESSIP (?:[-]{,}\.[-]{,}\.[-]{,}\.[-]{,})
ACCESSTIMESTAMP %{MONTHDAY}\/%{MONTH}\/%{YEAR}:%{HOUR}:%{MINUTE}:%{SECOND} %{ISO8601_TIMEZONE}
HTTPMETHOD (GET|POST|PUT|DELETE)
PRJNAME ([^\s]*)
HTTPVERSION (https?\/[-]{}\.[-]{})
STATUSCODE ([-]{})
# 192.168.1.101 - - [/Apr/::: +] "GET /spring-mvc-showcase HTTP/1.1" -
ACCESSLOG %{ACCESSIP:accIP}\s-\s\-\s\[%{ACCESSTIMESTAMP:accstamp}\]\s"%{HTTPMETHOD:method}\s\/%{PRJNAME:prjName}\s%{JAVALOGMESSAGE:statusCode} JAVA_OUT_COMMON \[%{TIMESTAMP_ISO8601:log_timestamp1}\] \| %{NOVERTICALBAR:loglevel} \| %{NOVERTICALBAR:codelocation} \| %{NOVERTICALBAR:threadid} \| %{NOVERTICALBAR:optype} \| %{NOVERTICALBAR:userid} \| %{NOVERTICALBAR:phone} \| %{NOVERTICALBAR:fd1} \| %{NOVERTICALBAR:fd2} \| %{NOVERTICALBAR:fd3} \| %{NOVERTICALBAR:fd4} \| %{NOVERTICALBAR:fd5} \| %{NOVERTICALBAR:fd6} \| %{NOVERTICALBAR:fd7} \| %{NOVERTICALBAR:fd8} \| %{NOVERTICALBAR:fd9} \| %{NOVERTICALBAR:fd10} \| %{NOVERTICALBAR:fd11} \| %{NOVERTICALBAR:fd12} \| %{NOVERTICALBAR:fd13} \| %{NOVERTICALBAR:fd14} \| %{NOVERTICALBAR:fd15} \| %{NOVERTICALBAR:fd16} \| %{NOVERTICALBAR:fd17} \| %{NOVERTICALBAR:fd18} \| %{GREEDYDATA:msg}
[root@logstash- logstash-to-es]#
tomcat中papatterns日志格式
启动logstash服务
#./bin/logstash -f logstash.conf
至此logstash安装和配置完成.
五、客户端日志收集
filebeat安装及收集Nginx端日志(10.20.9.31):
官方文档: https://www.elastic.co/guide/en/beats/filebeat/5.6/filebeat-installation.html
下载安装软件:
#curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-5.6.8-x86_64.rpm
#rpm -vi filebeat-5.6.-x86_64.rpm
配置:
[root@v05-app-nginx01 ~]# vim /etc/filebeat/filebeat.yml
###################### Filebeat Configuration ######################### #=========================== Filebeat prospectors ============================= filebeat.prospectors: - input_type: log
document_type: nginx_access paths:
- /opt/ytd_logs/nginx/*_access.log fields_under_root: true fields:
log_source: 10.20.9.31
log_topic: nginx_logs
tags: ["nginx","webservers"]
multiline:
pattern: ^\[[0-9]{4}-[0-9]{2}-[0-9]{2}T
match: after
negate: true #----------------------------- Logstash output --------------------------------
output.logstash:
# The Logstash hosts
hosts: ["10.200.3.85:5044"]
测试配置文件:
/usr/bin/filebeat.sh -configtest –e
启动服务
# /etc/init.d/filebeat start
filebeat安装及收集tomcat 端日志(10.20.9.52):
1.安装略,配置文件如下.
[root@v05-app-test01 filebeat]# vim filebeat.yml
###################### Filebeat Configuration ######################### #=========================== Filebeat prospectors =============================
#
filebeat.prospectors: - input_type: log
document_type: java_access paths:
- /opt/logs/portal/catalina.-*.out fields_under_root: true fields:
log_source: 10.20.9.52
log_topic: tomcat_logs
project_name: app_01
tags: ["tomcat","javalogs"]
multiline:
#对日志按时间进行一条条分割
#pattern: ^\[[-]{}-[-]{}-[-]{}T
pattern: ^\[[-]{}-[-]{}-[-]{}[ ][-][-]:[-]{}:[-]{}
#pattern: ^\[
match: after
negate: true #----------------------------- Logstash output --------------------------------
output.logstash:
# The Logstash hosts
hosts: ["10.200.3.86:5044"]
至此,ELK+Filebeat+Kafka+ZooKeeper日志收集系统部署完成!!!
kibana使用的lucene查询语法:
链接文档:https://segmentfault.com/a/1190000002972420
ELK+Filebeat+Kafka+ZooKeeper 构建海量日志分析平台的更多相关文章
- ELK+Filebeat+Kafka+ZooKeeper 构建海量日志分析平台(elk5.2+filebeat2.11)
ELK+Filebeat+Kafka+ZooKeeper 构建海量日志分析平台 参考:http://www.tuicool.com/articles/R77fieA 我在做ELK日志平台开始之初选择为 ...
- ELK(+Redis)-开源实时日志分析平台
################################################################################################### ...
- 【转】ELK(ElasticSearch, Logstash, Kibana)搭建实时日志分析平台
[转自]https://my.oschina.net/itblog/blog/547250 摘要: 前段时间研究的Log4j+Kafka中,有人建议把Kafka收集到的日志存放于ES(ElasticS ...
- 【Big Data - ELK】ELK(ElasticSearch, Logstash, Kibana)搭建实时日志分析平台
摘要: 前段时间研究的Log4j+Kafka中,有人建议把Kafka收集到的日志存放于ES(ElasticSearch,一款基于Apache Lucene的开源分布式搜索引擎)中便于查找和分析,在研究 ...
- [Big Data - ELK] ELK(ElasticSearch, Logstash, Kibana)搭建实时日志分析平台
ELK平台介绍 在搜索ELK资料的时候,发现这篇文章比较好,于是摘抄一小段: 以下内容来自: http://baidu.blog.51cto.com/71938/1676798 日志主要包括系统日志. ...
- ELK(ElasticSearch+Logstash+ Kibana)搭建实时日志分析平台
一.简介 ELK 由三部分组成elasticsearch.logstash.kibana,elasticsearch是一个近似实时的搜索平台,它让你以前所未有的速度处理大数据成为可能. Elastic ...
- 13: ELK(ElasticSearch+Logstash+ Kibana)搭建实时日志分析平台
参考博客:https://www.cnblogs.com/zclzhao/p/5749736.html 51cto课程:https://edu.51cto.com/center/course/less ...
- Centos7下ELK+Redis日志分析平台的集群环境部署记录
之前的文档介绍了ELK架构的基础知识,日志集中分析系统的实施方案:- ELK+Redis- ELK+Filebeat - ELK+Filebeat+Redis- ELK+Filebeat+Kafka+ ...
- ELK实时日志分析平台环境部署--完整记录
在日常运维工作中,对于系统和业务日志的处理尤为重要.今天,在这里分享一下自己部署的ELK(+Redis)-开源实时日志分析平台的记录过程(仅依据本人的实际操作为例说明,如有误述,敬请指出)~ ==== ...
随机推荐
- BZOJ2509 : 送分题
求出每个点向上下左右能延伸的最大长度$left$.$right$.$up$.$down$. 枚举每一条对角线,如果$j$可以作为左上角,$i$可以作为右下角,那么有: $j+\min(down[j], ...
- CentOS 7 下 RabbitMQ 集群搭建
环境 10.0.0.20 node1 10.0.0.21 node2 10.0.0.22 node3 搭建(在所有节点执行) 添加EPEL源 [root@node1 ~]# rpm -Uvh http ...
- [Microsoft][ODBC 驱动程序管理器] 未发现数据源名称并且未指定默认驱动程序
2003的access数据库文件后缀是mdb2007的access数据库文件后缀是accdb 我装的access2010所以驱动程序选择“Microsoft Access Driver (*.mdb, ...
- JDBC(2)—Statement
介绍: 获取到数据库连接之后,就可以对数据库进行一些增.删.改操作,但是却不能进行查询操作. 增删改操作是程序到数据库的一个操作过程,但是查询是程序到数据库--数据库返回到程序的一个过程. 步骤: 步 ...
- ADC分类及参数
ADC分类 直接转换模拟数字转换器(Direct-conversion ADC),或称Flash模拟数字转换器(Flash ADC) 循续渐近式模拟数字转换器(Successive approxima ...
- JAVA4种线程池的使用
Java通过Executors提供四种线程池,分别为:newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程.newFixe ...
- Kubernetes中的亲和性与反亲和性
通常情况下,Pod分配到哪些Node是不需要管理员操心的,这个过程会由scheduler自动实现.但有时,我们需要指定一些调度的限制,例如某些应用应该跑在具有SSD存储的节点上,有些应用应该跑在同一个 ...
- 如何用 async 控制流程
来自: http://larry850806.github.io/2016/05/31/async/ [Javascript] 如何用 async 控制流程 (一) 31 May 2016 async ...
- EF迁移命令
EF迁移设置的最后一步是在包管理器控制台中输入命令“add-migration InitialMigration -IgnoreChanges”.“InitialMigration”(高亮的黄色)是您 ...
- mysql 5.5.x zip直接解压版 报1076
到官网下载mysql-5.5.10-win32.zip,然后将mysql解压到任意路径,如:C:\mysql-5.5.10-win32 打开计算机->属性->高级系统设置->环境变量 ...