有10 亿个 url,每个 url 大小小于 56B,要求去重,内存只给你4G
问题:有10 亿个 url,每个 url 大小小于 56B,要求去重,内存只给你4G
思路:
1.首先将给定的url调用hash方法计算出对应的hash的value,在10亿的url中相同url必然有着相同的value。
2.将文件的hash table 放到第value%n台机器上。
3.value/n是机器上hash table的值。
将文件分布在多个机器上,这样要处理网路延时。假设有n台机器。
>>首先hash文件得到hash value v
>>将文件的hash table 放到第v%n 台机器上。
>>v/n是机器上hash table的值。
分析:
将文件的url进行hash,得到值value,相同的url的文件具有相同的value,所以会被分配到同一台机器v%n上。在同一台机器上的重复的url文件具有相同的value/n值,如果出现了冲突,不同的url在同一台机器上也可能有相同的value/n值。在每个机器上将value/n值作为key,url值作为value构成hash表进行去重。最后将内存中去重后的hash表中的value值即url写入磁盘。合并磁盘中的各部分url文件,完成去重。
56byte;
4G =4*1024=4096kb=4096*1024 byte;
--------
转自:https://www.cnblogs.com/aspirant/p/7154551.html
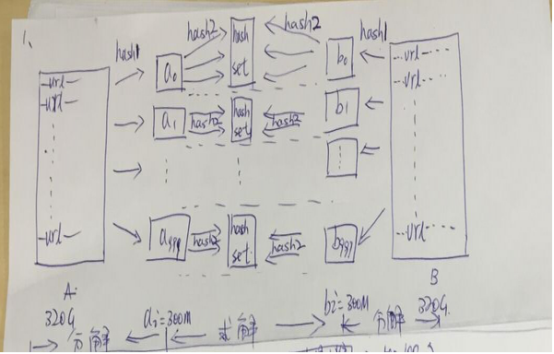
假如每个url大小为10bytes,那么可以估计每个文件的大小为50G×64=320G,远远大于内存限制的4G,所以不可能将其完全加载到内存中处理,可以采用分治的思想来解决。
Step1:遍历文件a,对每个url求取hash(url)%1000,然后根据所取得的值将url分别存储到1000个小文件(记为a0,a1,...,a999,每个小文件约300M);
Step2:遍历文件b,采取和a相同的方式将url分别存储到1000个小文件(记为b0,b1,...,b999);
巧妙之处:这样处理后,所有可能相同的url都被保存在对应的小文件(a0vsb0,a1vsb1,...,a999vsb999)中,不对应的小文件不可能有相同的url。然后我们只要求出这个1000对小文件中相同的url即可。
Step3:求每对小文件ai和bi中相同的url时,可以把ai的url存储到hash_set/hash_map中。然后遍历bi的每个url,看其是否在刚才构建的hash_set中,如果是,那么就是共同的url,存到文件里面就可以了。
草图如下(左边分解A,右边分解B,中间求解相同url):
2.有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M,要求返回频数最高的100个词。
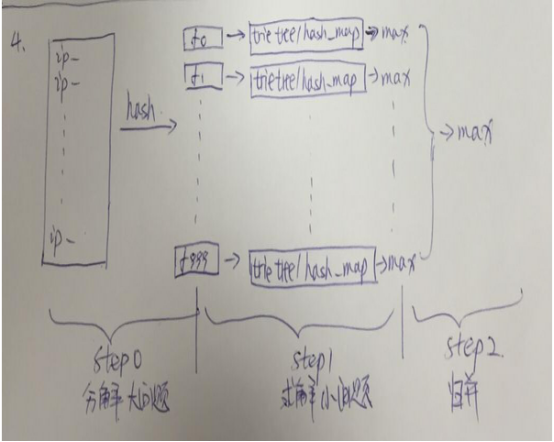
Step1:顺序读文件中,对于每个词x,取hash(x)%5000,然后按照该值存到5000个小文件(记为f0,f1,...,f4999)中,这样每个文件大概是200k左右,如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到分解得到的小文件的大小都不超过1M;
Step2:对每个小文件,统计每个文件中出现的词以及相应的频率(可以采用trie树/hash_map等),并取出出现频率最大的100个词(可以用含100个结点的最小堆),并把100词及相应的频率存入文件,这样又得到了5000个文件;
Step3:把这5000个文件进行归并(类似与归并排序);
草图如下(分割大问题,求解小问题,归并):
草图如下(分割大问题,求解小问题,归并):
3.现有海量日志数据保存在一个超级大的文件中,该文件无法直接读入内存,要求从中提取某天出访问百度次数最多的那个IP。
Step1:从这一天的日志数据中把访问百度的IP取出来,逐个写入到一个大文件中;
Step2:注意到IP是32位的,最多有2^32个IP。同样可以采用映射的方法,比如模1000,把整个大文件映射为1000个小文件;
Step3:找出每个小文中出现频率最大的IP(可以采用hash_map进行频率统计,然后再找出频率最大的几个)及相应的频率;
Step4:在这1000个最大的IP中,找出那个频率最大的IP,即为所求。
草图如下:
有10 亿个 url,每个 url 大小小于 56B,要求去重,内存只给你4G的更多相关文章
- 面试题 :10亿url去重只给4G内存
我能想到的有以下几种: 用语言判断去重,ex表格去重,数据库去重,文件名字去重, 有人说:10亿url ex表放不下!! 可以用树和折半的思想将10亿url,变成单元最小化的树,然后用ex表去重 ex ...
- 使用HAProxy、PHP、Redis和MySQL支撑每周10亿请求
在公司的发展中,保证服务器的可扩展性对于扩大企业的市场需要具有重要作用,因此,这对架构师提出了一定的要求.Octivi联合创始人兼软件架构师Antoni Orfin将向你介绍一个非常简单的架构,使用H ...
- 转 使用HAProxy,PHPRedis,和MySQL支撑10亿请求每周架构细节
[编者按]在公司的发展中,保证服务器的可扩展性对于扩大企业的市场需要具有重要作用,因此,这对架构师提出了一定的要求.Octivi联合创始人兼软件架构师Antoni Orfin将向你介绍一个非常简单的架 ...
- “军装照”背后——天天P图如何应对10亿流量的后台承载。
WeTest 导读 天天P图"军装照"活动交出了一份10亿浏览量的答卷,一时间刷屏朋友圈,看到这幕,是不是特别想复制一个如此成功的H5?不过本文不教你如何做一个爆款H5,而是介绍天 ...
- 海量数据处理 - 10亿个数中找出最大的10000个数(top K问题)
前两天面试3面学长问我的这个问题(想说TEG的3个面试学长都是好和蔼,希望能完成最后一面,各方面原因造成我无比想去鹅场的心已经按捺不住了),这个问题还是建立最小堆比较好一些. 先拿10000个数建堆, ...
- django命名url与url反向解析
1.在urls.py路由中指定别名 2.在views.py视图文件中导入from django.shortcuts import render, redirect, reverse 3.也可从这里导入 ...
- 这么设计,Redis 10亿数据量只需要100MB内存
本文主要和大家分享一下redis的高级特性:bit位操作. 本文redis试验代码基于如下环境: 操作系统:Mac OS 64位 版本:Redis 5.0.7 64 bit 运行模式:standalo ...
- python实现监控URL的一个值小于规定的值--邮件报警
监控URL的一个值小于规定的值--邮件报警 #!/usr/bin/env python #-*- coding:utf-8 -*- __author__ = 'liudong' import urll ...
- 【转】关于URL编码/javascript/js url 编码/url的三个js编码函数
来源:http://www.cnblogs.com/huzi007/p/4174519.html 关于URL编码/javascript/js url 编码/url的三个js编码函数escape(),e ...
随机推荐
- QueryString中的加号变成空格解决方法
通过Request.QueryString["CheckItem"]的方式调用值的时候,数值中的加号“+”会转换为空格“ ” 例如传输“ABC+EFG”,就会取到“ABC EFG” ...
- svg相关
1.指定点缩放公式 translate(-centerX*(factor-1), -centerY*(factor-1)) scale(factor)
- JAVA将异常的堆栈信息转成String
有时候我们需要将系统出现异常的堆栈信息显示到异常页面的一个隐藏的DIV内,这样查看源时就可以快速的定位到异常信息.这个时候就要将异常信息转成String. /* * 将异常的堆栈信息转成String ...
- react state为数组时插入值
react state为数组时,如何插入值.在react里,一切皆是状态state,如果想通过改变state修改渲染效果,只能yongsetState.但是setState又是key:value格式, ...
- ORACLE提示表名无效
在创建ORACLE数据库时,创建表 提示表名无效 请查看数据库表名是否出现了小写字母或者关键字,如USER
- 正则表达式 —— Cases 与 Tricks
1. cases 匹配任意单词(两侧可以有多个空格): ( +[a-zA-Z]+ +) 上述表达式无法匹配句子末尾的单词,若想匹配句尾或者逗号前的单词,则可拓展为: ( +[a-zA-Z]+[?,.] ...
- 【leetcode】69-Sqrt(x)
problem Sqrt(x) code class Solution { public: int mySqrt(int x) {// x/b=b long long res = x;// while ...
- sticky footer 和 flex布局的原理
Sticky footers设计是最古老和最常见的效果之一,大多数人都曾经经历过.它可以概括如下:如果页面内容不够长的时候,页脚块粘贴在视窗底部:如果内容足够长时,页脚块会被内容向下推送. 一.使用f ...
- Arrays 类的 binarySearch() 数组查询方法详解
Arrays类的binarySearch()方法,可以使用二分搜索法来搜索指定的数组,以获得指定对象.该方法返回要搜索元素的索引值.binarySearch()方法提供多种重载形式,用于满足各种类型数 ...
- NYOJ 12:喷水装置(二)(贪心,区间覆盖问题)
12-喷水装置(二) 内存限制:64MB 时间限制:3000ms 特判: No 通过数:28 提交数:109 难度:4 题目描述: 有一块草坪,横向长w,纵向长为h,在它的橫向中心线上不同位置处装有n ...