论文笔记:Learning how to Active Learn: A Deep Reinforcement Learning Approach
Learning how to Active Learn: A Deep Reinforcement Learning Approach
2018-03-11 12:56:04
1. Introduction:
对于大部分 NLP 的任务,得到足够的标注文本来进行模型的训练是一个关键的瓶颈。所以,active learning 被引入到 NLP 任务中以最小化标注数据的代价。AL 的目标是通过识别一小部分数据来进行标注,以此来降低 cost,选来最小化监督模型的精度。
毫无疑问的是,AL 对于其他语言来说,特别是 low-resource languages,是非常重要的,因为其 annotation 通常很难获取,标注预算不太大。这种设置是 AL 很自然的应用,然而,很少有工作完成这个部分。一个潜在的原因是:大部分AL algorithm 需要 data 的一小部分作为 “seed set” 来学习一个基础的分类器,可以用于后续的主动数据选择(Active data selection)。然而,在低资源设定下给定匮乏的数据,这个假设使得标准的方法变的不可实施。
本文中,我们提出 PAL,简称:Policy based Active Learning,是一种新颖的方法来从数据中,学习一个 dynamic AL strategy。这使得该策略可以应用于其他设定,如:cross-lingual applications。我们的算法不需要一个固定的 heuristic,而是去学习如何主动地选择数据,构成了一个强化学习问题。一个智能的 agent,必须决定是否序列的选择数据进行标注,其中,决策策略是利用 deep Q-network 来学习的。该策略是利用观测到的:句子的内容信息(content information),监督模型的分类及其置信度(the supervised model's classifications and its confidence)。对应的,一个丰富、动态的策略可以通过标注决策的历史序列来进行标注新的数据中进行学习。
此外, 为了降低目标语言对数据的依赖,而且可能是 low resource,我们可以在另一个语言中AL的策略迁移到目标语言当中(we first learn the policy of active learning on another language and then transfer it to the target language)。在一个 high resource language 上学一个策略是很简单的,因为有大量的数据,如:English。我们构建cross-lingual word embeddings 来学习匹配的数据表示,使得学习到的策略可以轻易地移植到其他语言中。
我们的工作与前人在 NLP 上 AL 的探索不同。大部分前人的 AL algorithms 是研发以基于一种语言用于 NER tasks,然后用于该语言。另一个主要的不同在于,许多 AL algorithms 利用固定数据的启发式选择(use a fixed data selection heuristic),例如:不确定性采样(uncertainty sampling)。然而,在我们的算法中,我们显示的利用 uncertainty information 作为RL agent 的一个主要观测。
2. Methodology:
2.1 Active learning as a decision process
AL 是用于标注数据的简单算法,首先从一个未标注的数据集中选择一些 instances,然后通过一个人工环节来进行标注,然后依次循环,直至满足某一停止标准,即:the annotation budget is exhausted。通常,这个选择函数是基于某一预先训练模型的估计,此时已经在每一个阶段拟合标注的数据集,其中,数据点,是依赖于该模型的预测不确定性进行选择的(the datapoints are selected based on the model's predictive uncertainty),or divergence in predictions over an ensemble。这些方法的关键 idea 在于:find the instances on which the model is most likely to make errors, 即:找到使得模型最可能犯错的那些数据点。这样,在他们的标注以及包含后,该模型在此类 unseen data 上变的鲁棒。
AL 算法的过程可以看做是 decision process,将 AL algorithm 看做是序列决策过程,AL的阶段对应系统的状态(the stages of active learning corresponding to the state of the system)。Accordingly,the state corresponds to the selected data for labelling and their labels, and each step in the active learning algorithm corresponding to a selction action, wherein the heuristic selects the next items from a pool. 当预算消耗完毕的时候,该过程终止。
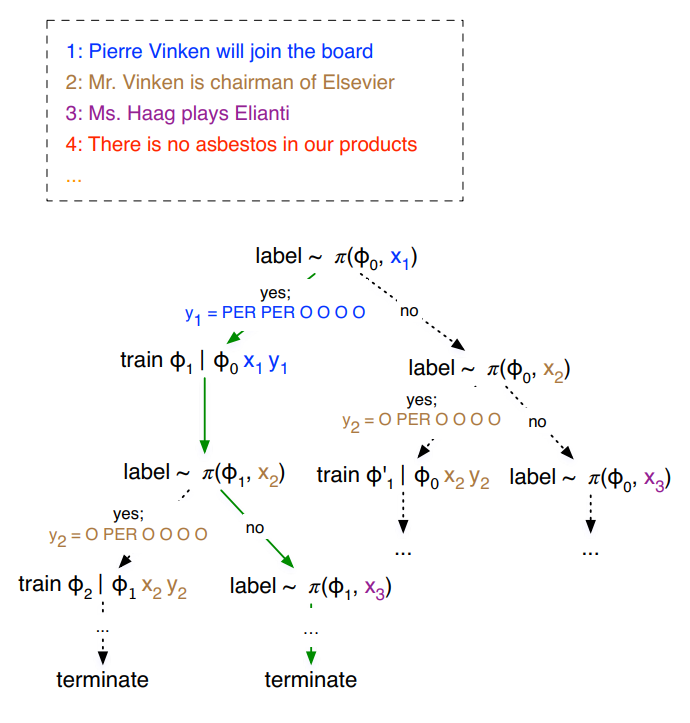
2.2 Steam-based learning:
之所以会有这个假设,是因为想把 active learning 看做是序列决策问题,用 DRL 来解决。所以,这里抛弃了传统的基于 pool 的那种思路,用这种顺序处理的做法。
2.2.1 State:
由三个部分构成:
content representation : 用现有的 CNN 来提取句子的feature;
representation of marginals :
confidence of sequential prediction : 序列估计的置信度
2.2.2 Action:
动作就是选择 或者 不选择
2.2.3 Reward:
奖励是根据 held-out performance 进行评价的,即:根据选择某一动作后,是否使得验证集的性能得到了提升,给予 pos or neg 的奖励;
2.2.4 Budget:
总得需要标注的 instance 的个数
2.2.5 Reinforcement Learning:
这里用的就是 DQN 算法,具体可以参考其他博客。

2.3 Cross-lingual policy transfer :
这里进行跨语言策略迁移的目的是:为了处理数据量比较少的语言中的 active learning 问题。作者采用 Transfer learning 的方法,在数据量丰富的数据集上学习一个比较好的 policy,然后将这种策略应用到 数据量较少的 domain 或者 task 上。

可以看到这个 Algorithm 2 与 Algorithm 1 很大的不同在于输入多了一个 policy,而这个 policy 是在 source language 上学习出来的。
2.4 Cold-start transfer :
以上迁移学习方法有如下两个局限性:
1. the requirement for held-out evaluation data ; 需要 held-out 数据
2. the embedding of the oracle annotation inside the learning loop 循环内部需要手动标注
前者意味着需要更多的监督信息,后者需要实时处理,并且需要人工参与。
For this data and -communication-impverished setting, denoted as cold-start ,
==>> 我们仅仅允许一次给 target data 请求标注的机会;
==>> 不用 held-out data,不进行策略更新; 即: the agent can select a batch of unlabeled target instances for annotations, but can not use these resulting annotations or any other feedback to refine the selection.
在这种更加困难的情况下,我们采用 pre-trained model,使得 the agent 可以在缺乏 feedback 的情况下,做出更加具有信息量的决策。

论文笔记:Learning how to Active Learn: A Deep Reinforcement Learning Approach的更多相关文章
- 论文笔记之:Dueling Network Architectures for Deep Reinforcement Learning
Dueling Network Architectures for Deep Reinforcement Learning ICML 2016 Best Paper 摘要:本文的贡献点主要是在 DQN ...
- 论文笔记之:Active Object Localization with Deep Reinforcement Learning
Active Object Localization with Deep Reinforcement Learning ICCV 2015 最近Deep Reinforcement Learning算 ...
- 18 Issues in Current Deep Reinforcement Learning from ZhiHu
深度强化学习的18个关键问题 from: https://zhuanlan.zhihu.com/p/32153603 85 人赞了该文章 深度强化学习的问题在哪里?未来怎么走?哪些方面可以突破? 这两 ...
- 论文笔记之:Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning
论文笔记之:Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning 2017-06-06 21: ...
- Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记
Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记 arXiv 摘要:本文提出了一种 DRL 算法进行单目标跟踪 ...
- 论文笔记之:Asynchronous Methods for Deep Reinforcement Learning
Asynchronous Methods for Deep Reinforcement Learning ICML 2016 深度强化学习最近被人发现貌似不太稳定,有人提出很多改善的方法,这些方法有很 ...
- 论文笔记之:Deep Reinforcement Learning with Double Q-learning
Deep Reinforcement Learning with Double Q-learning Google DeepMind Abstract 主流的 Q-learning 算法过高的估计在特 ...
- 论文笔记之:Playing Atari with Deep Reinforcement Learning
Playing Atari with Deep Reinforcement Learning <Computer Science>, 2013 Abstract: 本文提出了一种深度学习方 ...
- 论文笔记之:Human-level control through deep reinforcement learning
Human-level control through deep reinforcement learning Nature 2015 Google DeepMind Abstract RL 理论 在 ...
随机推荐
- clientWidth,offsetWidth,scrollWidth区别
<html> <head> <title>clientWidth,offsetWidth,scrollWidth区别</title> </head ...
- Gambler Bo (高斯消元求特解)
对于图中的每一个点假设点击Xi * m + j 然后每个点都有那么对于每一个点可以列举出一个方程式,n*m个点解n*m个未知数.利用高斯消元就可以解决. 问题就在这个题目可能不止有一个特,所以我们需要 ...
- C# 调整控件的Z顺序
当窗口或者容器控件中的控件在布局过程中发生重叠的时候,会出现层次性.Z顺序较大的控件会遮挡Z顺序较小的控件,放在顶层的控件会挡住放在底层的控件. 1.编辑一个这样的窗口(使用Label控件) 2.添加 ...
- [转载]oracle函数listagg的使用说明
工作中经常遇到很多需求是这样的,根据条件汇总某些字段,比如我遇到的是,我们公司有三个投资平台,同一个客户拿手机号在三个平台都注册了,但注册过的用户名不一样,显示的时候需要根据手机号显示所有注册过的名称 ...
- JAVA基本语法测试
一: 1,JAVA的基本运行单位是类 2,类的成员:成员变量,构造方法,普通方法和内部类 3,成员变量种类:字符类型:char 布尔类型:boolean 数值类型:byte, s ...
- 编写一个JavaWeb项目
基本流程:JSP文件显示页面,在前端页面输入赋值,使用form或href超链接传值到Servlet中方法,在Servlet方法中调用Dao层的类对象,将数据传到数据库中,并实现对数据库里的数据的增删改 ...
- Django框架----路由系统、视图和模板(简单介绍)
一.路由配置系统(urls) URL配置(URLconf)就像Django所支撑网站的目录.它的本质是URL与要为该URL调用的视图函数之间的映射表: 你就是以这种方式告诉Django,对于这个URL ...
- MyEclipse 10.7(版本:eclipse 3.7.x-Indigo系列)安装activiti-eclipse-plugin插件(流程设计器)
基本信息 1.本机MyEclipse 10.7菜单[Help->About MyEclipse Enterprise Workbench]的版本信息: MyEclipse Enterprise ...
- url去重 --布隆过滤器 bloom filter原理及python实现
https://blog.csdn.net/a1368783069/article/details/52137417 # -*- encoding: utf-8 -*- ""&qu ...
- ==和equals的区别。
1.java中equals和==的区别 值类型是存储在内存中的堆栈(简称栈),而引用类型的变量在栈中仅仅是存储引用类型变量的地址,而其本身则存储在堆中. 2.==操作比较的是两个变量的值是否相等,对于 ...