[转] 基于NodeJS的前后端分离的思考与实践(五)多终端适配
前言
近年来各站点基于 Web 的多终端适配进行得如火如荼,行业间也发展出依赖各种技术的解决方案。有如基于浏览器原生 CSS3 Media Query 的响应式设计、基于云端智能重排的「云适配」方案等。本文则主要探讨在前后端分离基础下的多终端适配方案。
关于前后端分离
关于前后端分离的方案,在《基于NodeJS的前后端分离的思考与实践(一)》中有非常清晰的解释。我们在服务端接口和浏览器之间引入 NodeJS 作为渲染层,因为 NodeJS 层彻底与数据抽离,同时无需关心大量的业务逻辑,所以十分适合在这一层进行多终端的适配工作。
UA 探测
进行多终端适配首先要解决的是 UA 探测问题,对于一个过来的请求,我们需要知道这个设备的类型才能针对对它输出对应的内容。现在市面上已经有非常成熟的兼容大量设备的 User Agent 特征库和探测工具,这里有 Mozilla 整理的一个列表。其中,既有运行在浏览器端的,也有运行在服务端代码层的,甚至有些工具提供了 Nginx/Apache 的模块,负责解析每个请求的 UA 信息。
实际上我们推荐最后一种方式。基于前后端分离的方案决定了 UA 探测只能运行在服务器端,但如果把探测的代码和特征库耦合在业务代码里并不是一个足够友好的方案。我们把这个行为再往前挪,挂在 Nginx/Apache 上,它们负责解析每个请求的 UA 信息,再通过如 HTTP Header 的方式传递给业务代码。
这样做有几点好处:
我们的代码里面无需再去关注 UA 如何解析,直接从上层取出解析后的信息即可。如果在同一台服务器上有多个应用,则能够共同使用同一个 Nginx 解析后的 UA 信息,节省了不同应用间的解析损耗。
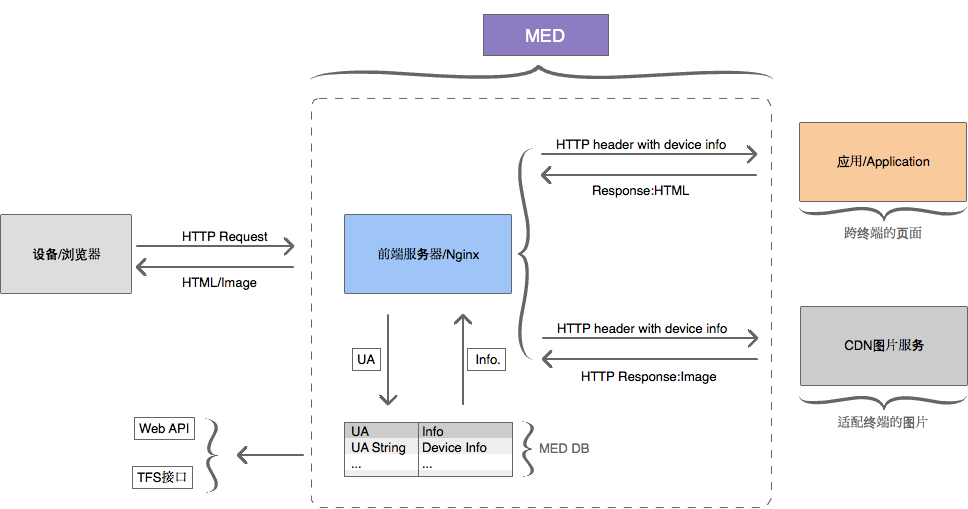
来自天猫分享的基于 Nginx 的 UA 探测方案
淘宝的 Tengine Web 服务器也提供了类似的模块 ngx_http_user_agent_module。
值得一提的是,选用 UA 探测工具时必须要考虑特征库的可维护性,因为市面上新增的设备类型越来越多,每个设备都会有独立的 User Agent,所以该特征库必须提供良好的更新和维护策略,以适应不断变化的设备。
建立在 MVC 模式中的几种适配方案
取得 UA 信息后,我们就要考虑如果根据指定的 UA 进行终端适配了。即使在 NodeJS 层,虽然没有了大部分的业务逻辑,但我们依然把内部区分为 Model / Controller / View 三个模型。
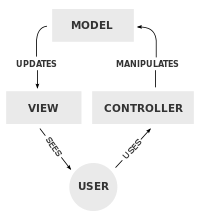
我们先利用上面的图,去解析一些已有的多终端适配方案。
建立在 Controller 上的适配方案
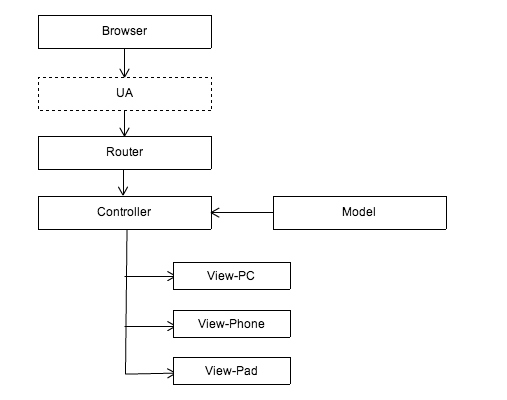
这种方案应该是最简单粗暴的处理方法。通过路由(Router)将相同的 URL 统一传递到同一个控制层(Controller)。控制层再通过 UA 信息将数据和模型(Model)逻辑派发到对应的展现(View)进行渲染,渲染层则按预先的约定提供了适配几个终端的模板。
这种方案的好处是,保持了数据和控制层的统一性,业务逻辑只需处理一次遍可以应用在所有终端上。但这种场景只适合如展示型页面等低交互型的应用,一旦业务比较复杂,各个终端的 Controller 可能有各自的处理逻辑,如果还是共用一个 Controller ,会导致 Controller 非常的臃肿而且难以维护,这无疑是一个错误的选择。
建立在 Router 上的适配方案
为了解决上面遇到的问题,我们可以在 Router 上就将设备区分,针对不同的终端分发到不同的 Controller 上:
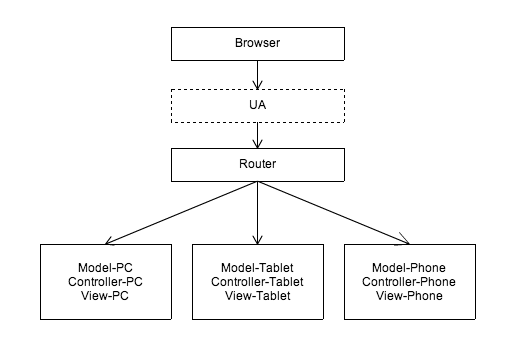
这也是最常见的方案之一,大多表现在针对不同终端使用各自独立的一套应用。如 PC 淘宝首页和 WAP 版的淘宝首页,不同设备访问 www.taobao.com ,服务器会通过 Router 的控制,重定向到 WAP 版的淘宝首页或者 PC 版的淘宝首页,它们各自是完全独立的两套应用。
但这种方案无疑带来了数据和部分逻辑无法共用的问题,各种终端之间无法分享同一份数据和业务逻辑,产生大量重复性工作,效率低下。
为了缓解这个问题,有人提出了优化后的方案:依然是在同一套应用里面,各个数据来源抽象成各个 Model,提供给不同终端的 Controller 组合使用:
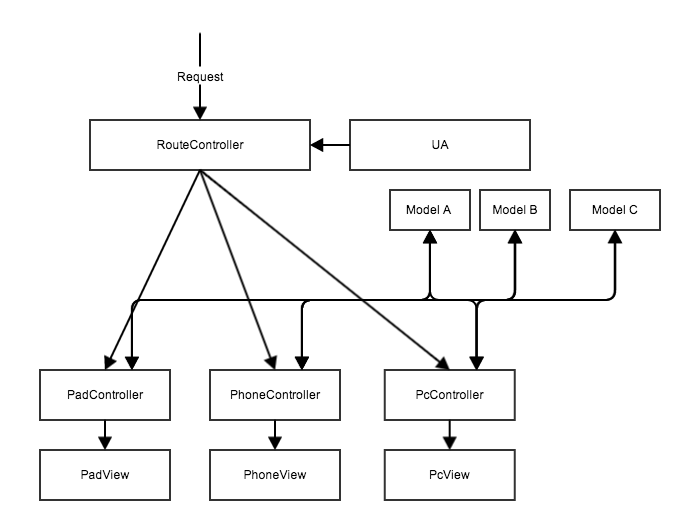
这个方案解决了前面数据无法共用的问题。在 Controller 上各个终端还是相互独立,但能共同使用同一批数据源,至少在数据上无需再针对终端类型开发独立的接口了。
以上两种基于 Router 的方案,由于 Controller 的独立,各个终端可以为自己的页面实现不同的交互逻辑,保证了各终端自身足够的灵活度,这也是为什么大部分应用采用这种方案的主要原因。
建立在 View 层的适配方案
这是淘宝下单页面使用的方案,不过区别是下单页将整体的渲染层放在了浏览器端,而不是 NodeJS 层。不过无论是浏览器还是 NodeJS,整体设计思路还是一致的:
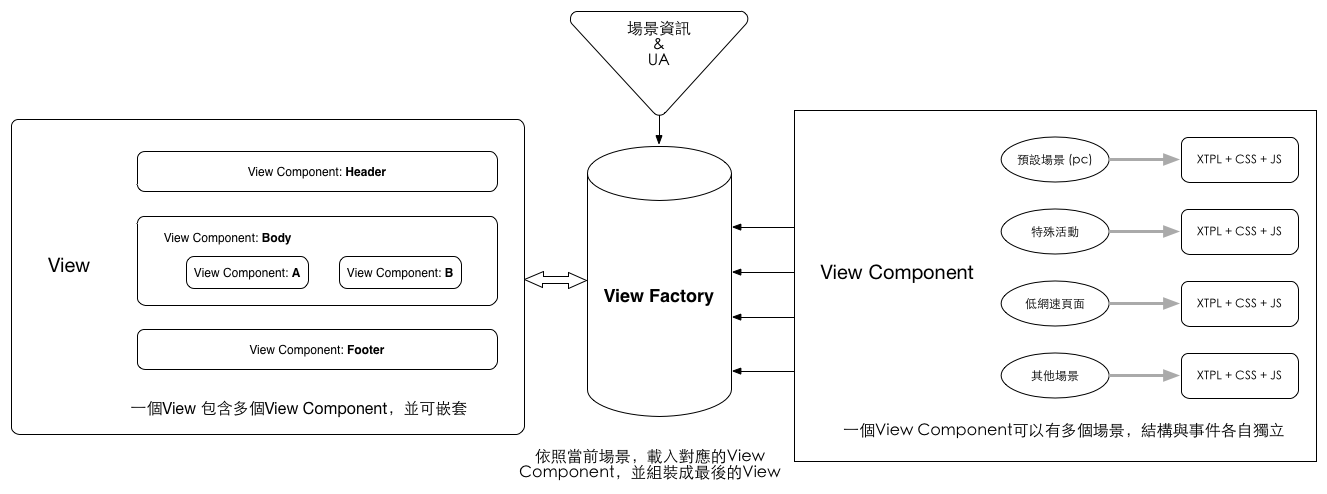
在这个方案里面,Router、Controller 和 Model 都无需关注设备信息,终端类型的判断完全交给展现层来处理。图中主要的模块是「View Factory」,Model 和 Controller 将数据和渲染逻辑传递过来之后,通过 View Factory 根据设备信息和其它状态(不仅仅是 UA 信息、也可以是网络环境、用户地区等等)从一堆预设好的组件(View Component)中抓取特定的组件,再组合成最终的页面。
这种方案有几个优势:
上层无需关注设备信息(UA),多终端的视频还是交由和最终展现最大关系的 View 层来处理;不仅仅是多终端适配,除了 UA 信息,各个 View Component 还可以根据用户状态决定自身输出何种模版,如低网速下默认隐藏图片、指定地区输出活动 Banner。每个 View Component 的不同模版间可以自行决定是否使用同一份数据、业务逻辑,提供十分灵活的实现方式。
但明显的是,这个方案也是最复杂的,尤其是要考虑一些富交互的应用场景时,Router 和 Controller 也许无法保持这么纯粹。特别对于一些整体性比较强的业务,本身无法被拆分成组件,这种方案也许并不适用;而且对于一些简单的业务,使用这种架构可能不是最佳的选择。
总结
以上几种方案,都各自体现在 MVC 模型中的一个或多个部分,在业务上如果一个方案不满足需求,更可以采取多个方案同时采用的方式。或是可以理解为,业务上的复杂度和交互属性决定了该产品更适合采用哪种多终端适配方案。
对比基于浏览器的响应式设计方案,因为绝大部分终端探测和渲染逻辑迁移到了服务端,所以在 NodeJS 层进行适配无疑带来了更好的性能和用户体验;另外,相对于一些所谓的「云适配」方案带来的转换质量问题,在基于前后端分离的「定制式」方案中也不会存在。前后端分离的适配方案在这些方面有着天然优势。
最后,为了适应更灵活的强大的适配需求,基于前后端分离的适配方案将会面临更多挑战!
[转] 基于NodeJS的前后端分离的思考与实践(五)多终端适配的更多相关文章
- (转)也谈基于NodeJS的全栈式开发(基于NodeJS的前后端分离)
原文链接:http://ued.taobao.org/blog/2014/04/full-stack-development-with-nodejs/ 随着不同终端(pad/mobile/pc)的兴起 ...
- 也谈基于NodeJS的全栈式开发(基于NodeJS的前后端分离)
前言 为了解决传统Web开发模式带来的各种问题,我们进行了许多尝试,但由于前/后端的物理鸿沟,尝试的方案都大同小异.痛定思痛,今天我们重新思考了“前后端”的定义,引入前端同学都熟悉的NodeJS,试图 ...
- 基于NodeJS的全栈式开发(基于NodeJS的前后端分离)
也谈基于NodeJS的全栈式开发(基于NodeJS的前后端分离) 前言 为了解决传统Web开发模式带来的各种问题,我们进行了许多尝试,但由于前/后端的物理鸿沟,尝试的方案都大同小异.痛定思痛,今天我们 ...
- Java Web前后端分离的思考与实践
第一节 Java Web开发方式的变化 Web开发虽然是我们常说的B/S模式,其实本质上也是一种特殊的C/S模式,只不过C和S的选择余地相对要窄了不少,而且更标准化.不论是采用什么浏览器和后端框架,W ...
- 基于NodeJS进行前后端分离
1.什么是前后端分离 传统的SPA模式:所有用到的展现数据都是后端通过异步接口(AJAX/JSONP)的方式提供的,前端只管展现. 从某种意义上来说,SPA确实做到了前后端分离,但这种方式存在两个问题 ...
- 基于 koajs 的前后端分离实践
一.什么是前后端分离? 前后端分离的概念和优势在这里不再赘述,有兴趣的同学可以看各个前辈们一系列总结和讨论: 系列文章:前后端分离的思考与实践(1-6) slider: 淘宝前后端分离实践 知乎提问: ...
- 【SpringSecurity系列2】基于SpringSecurity实现前后端分离无状态Rest API的权限控制原理分析
源码传送门: https://github.com/ningzuoxin/zxning-springsecurity-demos/tree/master/01-springsecurity-state ...
- [原创]基于VueJs的前后端分离框架搭建之完全攻略
首先请原谅本文标题取的有点大,但并非为了哗众取宠.本文取这个标题主要有3个原因,这也是写作本文的初衷: (1)目前国内几乎搜索不到全面讲解如何搭建前后端分离框架的文章,讲前后端分离框架思想的就更少了, ...
- 基于Vue的前后端分离项目实践
一.为什么需要前后端分离 1.1什么是前后端分离 前后端分离这个词刚在毕业(15年)那会就听说过,但是直到17年前都没有接触过前后端分离的项目.怎么理解前后端分离?直观的感觉就是前后端分开去做,即功 ...
随机推荐
- python-web开发环境搭建
一.安装distribute或setuptools,我用的distribute 下载链接:https://pypi.python.org/pypi/distribute [root@yeebian o ...
- CentOS下设置vim的tab键为4格
# vim /etc/vimrc 在最后一行添加 set softtabstop=4 或者set tabstop=4 或者在~/.vimrc中添加也可以 没有~/.vimrc文件可以创建一个 另: s ...
- UVA - 12487 Midnight Cowboy(LCA+思维)
https://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&page=show_problem& ...
- NTT模板
NTT(快速数论变换)用到的各种素数及原根: https://blog.csdn.net/hnust_xx/article/details/76572828 NTT多项式乘法模板 #include&l ...
- 求FIRST集和FOLLOW集
花了点时间弄了个大概,希望对和我一样的人有所帮助. 文法如下: E -> TE'E' -> +TE'|εT -> FT'T' -> *FT'|εF -> (E)|id ...
- Syncfusion HTMLUI研究一
HTMLUI可以加载HTML页面,并且相比WebKit等占用资源特别少 <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitiona ...
- 使用Word批量删除换行和空白行
转载自:https://blog.csdn.net/dearmorning/article/details/78811137 问题一:从pdf文档中复制一部分内容到word的时候,pdf的自动换行会自 ...
- F - New Distinct Substrings (后缀数组)
题目链接:https://cn.vjudge.net/contest/283743#problem/F 题目大意:给你一个字符串,然后让你求出不同的子串的个数. 具体思路:首先,一个字符串中总的子串个 ...
- css scrollbar样式设置
参考链接:https://segmentfault.com/a/1190000012800450
- Java ArrayList类
ArrayList对象可以用于存储一个对象列表 例子: ArrayList<String> list = new ArrayList<String>() 例子: public ...