Kaggle 泰坦尼克
入门kaggle,开始机器学习应用之旅。
参看一些入门的博客,感觉pandas,sklearn需要熟练掌握,同时也学到了一些很有用的tricks,包括数据分析和机器学习的知识点。下面记录一些有趣的数据分析方法和一个自己撸的小程序。
1.Tricks
1) df.info():数据的特征属性,包括数据缺失情况和数据类型。
df.describe(): 数据中各个特征的数目,缺失值为NaN,以及数值型数据的一些分布情况,而类目型数据看不到。
缺失数据处理:缺失的样本占总数比例极高,则直接舍弃;缺失样本适中,若为非连续性特征则将NaN作为一个新类别加到类别特征中(0/1化),若为连续性特征可以将其离散化后把NaN作为新类别加入,或用平均值填充。
2)数据分析方法:将特征分为连续性数据:年龄、票价、亲人数目;类目数据:生存与否、性别、等级、港口;文本类数据:姓名、票名、客舱名
3)数据分析技巧(画图、求相关性)
- 画图
类目特征分布图&&特征与生存情况关联柱状图:
fig1 = plt.figure(figsize=(12,10)) # 设定大尺寸后使得图像标注不重叠
fig1.set(alpha=0.2) # 设定图表颜色alpha参数 plt.subplot2grid((2,3),(0,0)) # 在一张大图里分列几个小图
data_train.Survived.value_counts().plot(kind='bar')# 柱状图
plt.title(u"获救情况 (1为获救)") # 标题
plt.ylabel(u"人数") plt.subplot2grid((2,3),(0,1))
data_train.Pclass.value_counts().plot(kind="bar")
plt.ylabel(u"人数")
plt.title(u"乘客等级分布") plt.subplot2grid((2,3),(0,2))
plt.scatter(data_train.Survived, data_train.Age)
plt.ylabel(u"年龄") # 设定纵坐标名称
plt.grid(b=True, which='major', axis='y')
plt.title(u"按年龄看获救分布 (1为获救)") plt.subplot2grid((2,3),(1,0), colspan=2)
data_train.Age[data_train.Pclass == 1].plot(kind='kde')
data_train.Age[data_train.Pclass == 2].plot(kind='kde')
data_train.Age[data_train.Pclass == 3].plot(kind='kde')
plt.xlabel(u"年龄")# plots an axis lable
plt.ylabel(u"密度")
plt.title(u"各等级的乘客年龄分布")
plt.legend((u'头等舱', u'2等舱',u'3等舱'),loc='best') # sets our legend for our graph.
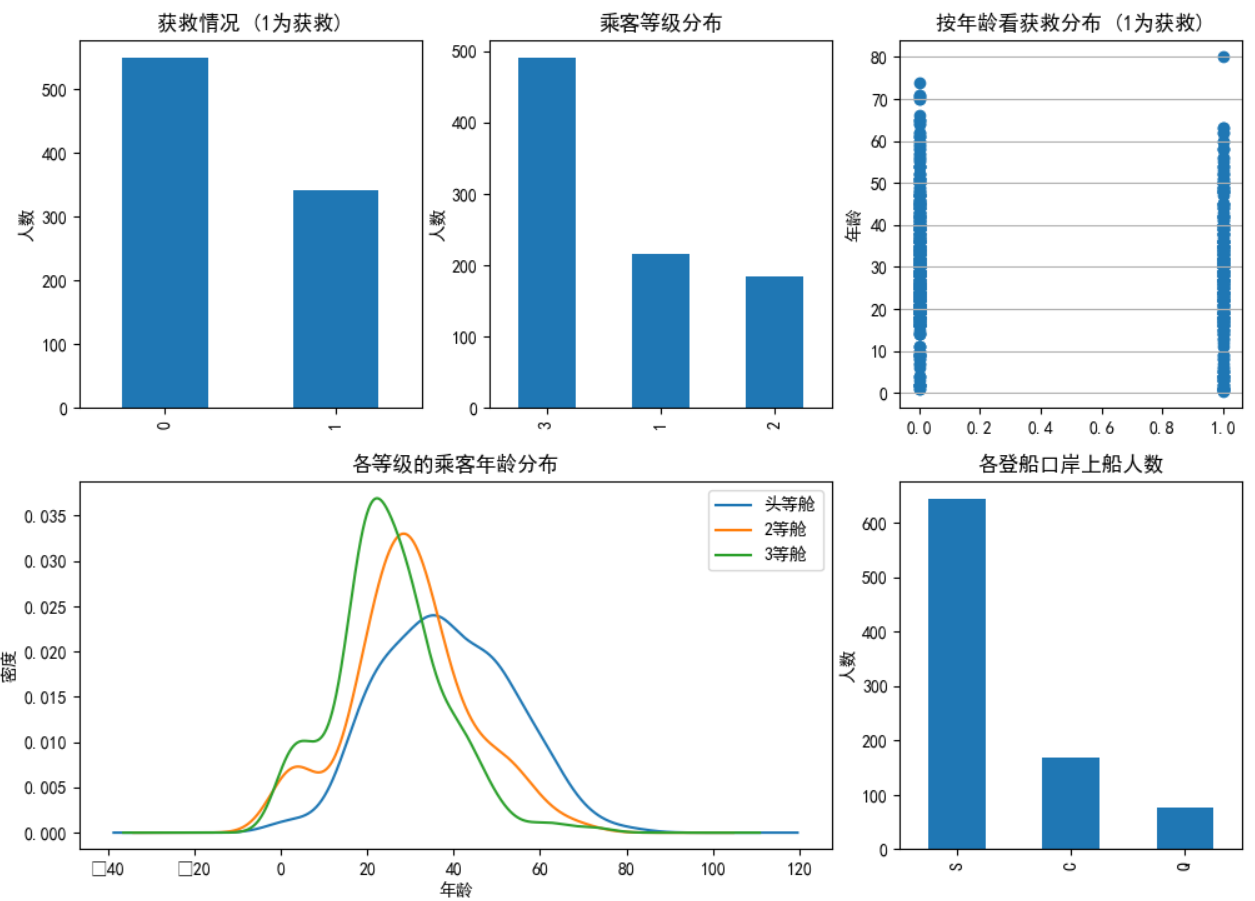

以上为3种在一张画布实现多张图的画法:
ax1 = plt.subplot2grid((3,3), (0,0), colspan=3)
ax2 = plt.subplot2grid((3,3), (1,0), colspan=2)
ax3 = plt.subplot2grid((3,3), (1, 2), rowspan=2)
ax4 = plt.subplot2grid((3,3), (2, 0))
ax5 = plt.subplot2grid((3,3), (2, 1))
plt.suptitle("subplot2grid")

此外,还有两种方法等效:
f=plt.figure()
ax=fig.add_subplot(111)
ax.plot(x,y) plt.figure()
plt.subplot(111)
plt.plot(x,y)
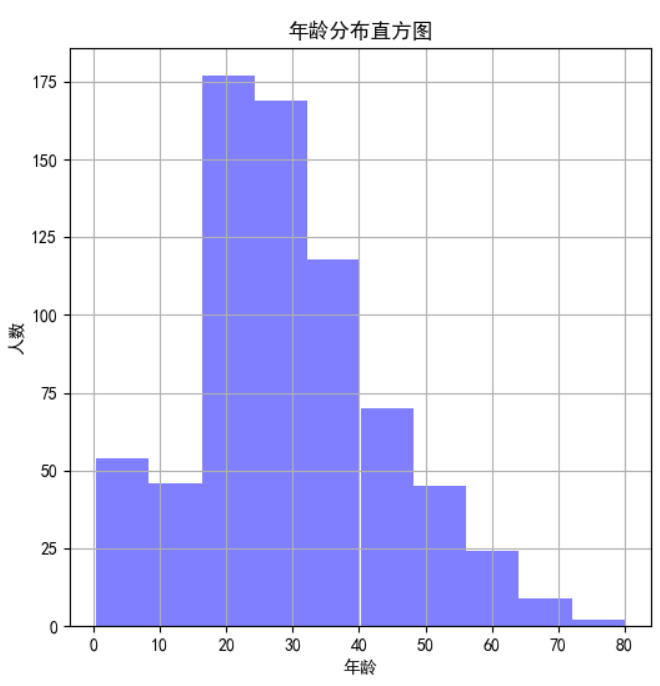
连续性特征分布可以用直方图hist来实现(见上图-年龄分布直方图):
figure1 = plt.figure(figsize=(6,6))
value_age = train_data['Age']
value_age.hist(color='b', alpha=0.5) # 年龄分布直方图
plt.xlabel(u'年龄')
plt.ylabel(u'人数')
plt.title(u'年龄分布直方图')
类目特征与生存关系柱状图(见上图-各乘客等级的获救情况):
fig2 = plt.figure(figsize=(6,5))
fig2.set(alpha=0.2)
Survived_0 = data_train.Pclass[data_train.Survived==0].value_counts()
Survived_1 = data_train.Pclass[data_train.Survived==1].value_counts()
df = pd.DataFrame({u'获救':Survived_1, u'未获救':Survived_0})
df.plot(kind='bar', stacked=True) # stacked=False时不重叠
plt.title(u"各乘客等级的获救情况")
plt.xlabel(u"乘客等级")
plt.ylabel(u"人数")
plt.show()
各属性与生存率进行关联:
eg:舱位和性别 与存活率的关系:利用pandas中的groupby函数
Pclass_Gender_grouped=dt_train_p.groupby(['Sex','Pclass']) #按照性别和舱位分组聚合
PG_Survival_Rate=(Pclass_Gender_grouped.sum()/Pclass_Gender_grouped.count())['Survived'] #计算存活率 x=np.array([1,2,3])
width=0.3
plt.bar(x-width,PG_Survival_Rate.female,width,color='r')
plt.bar(x,PG_Survival_Rate.male,width,color='b')
plt.title('Survival Rate by Gender and Pclass')
plt.xlabel('Pclass')
plt.ylabel('Survival Rate')
plt.xticks([1,2,3])
plt.yticks(np.arange(0.0, 1.1, 0.1))
plt.grid(True,linestyle='-',color='0.7')
plt.legend(['Female','Male'])
plt.show() #画图

可以看到,不管是几等舱位,都是女士的存活率远高于男士。
将连续性数据年龄分段后,画不同年龄段的分布以及存活率:
age_train_p=dt_train_p[~np.isnan(dt_train_p['Age'])] #去除年龄数据中的NaN
ages=np.arange(0,85,5) #0~85岁,每5岁一段(年龄最大80岁)
age_cut=pd.cut(age_train_p.Age,ages)
age_cut_grouped=age_train_p.groupby(age_cut)
age_Survival_Rate=(age_cut_grouped.sum()/age_cut_grouped.count())['Survived'] #计算每年龄段的存活率
age_count=age_cut_grouped.count()['Survived'] #计算每年龄段的总人数 ax1=age_count.plot(kind='bar')
ax2=ax1.twinx() #使两者共用X轴
ax2.plot(age_Survival_Rate.values,color='r')
ax1.set_xlabel('Age')
ax1.set_ylabel('Number')
ax2.set_ylabel('Survival Rate')
plt.title('Survival Rate by Age')
plt.grid(True,linestyle='-',color='0.7')
plt.show()

可以看到年龄主要在15~50岁左右,65~80岁死亡率较高,后面80岁存活率高是因为只有1人。
- 相关性分析:
Parch、SibSp取值少,分布不均匀,不适合作为连续值来处理。可以将其分段化。这里分析一下Parch和SibSp与生存的关联性
from sklearn.feature_selection import chi2
print("Parch:", chi2(train_data.filter(["Parch"]), train_data['Survived']))
print("SibSp:", chi2(train_data.filter(["SibSp"]), train_data['Survived']))
# chi2(X,y) X.shape(n_samples, n_features_in) y.shape(n_samples,)
# 返回 chi2 和 pval, chi2值描述了自变量与因变量之间的相关程度:chi2值越大,相关程度也越大,
# http://guoze.me/2015/09/07/chi-square/
# 可以看到Parch比SibSp的卡方校验取值大,p-value小,相关性更强。
4)数据预处理:
PassengerId 舍掉
Pclass为类目属性,3类。本身有序的,暂时不进行dummy coding
Name 为文本属性,舍掉,暂时不考虑
Sex为类目属性,2类。本身无序,进行dummy coding
Age为连续属性,确实较多可以用均值填充。幅度变化大。可以将其以5岁为step进行离散化或利用scaling将其归一化到[-1,1]之间
SibSp为连续属性,但比较离散,不适合按照连续值处理,暂时不用处理。或者可以按照其数量>3和<=3进行dummy coding
Parch为连续属性。但比较离散,不适合按照连续值处理,暂时不用处理。
Ticket为文本属性,舍掉,暂时不考虑
Fare为连续属性,幅度变化大,可以利用scaling将其归一化到[-1,1]之间
Cabin为类目属性,但缺失严重,可以按照是否缺失来0/1二值化,进行dummy coding
Embarked为类目属性,缺失值极少,先填充后进行dummy coding
综上,可用的数据特征有:Pclass,Sex,Age,SibSp,Parch,Fare,Cabin,Embarked
此外需注意的是,需对训练集和测试集的数据做同样的处理。
2.实例。
根据以上思路,一个小baseline诞生了:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from pandas import Series, DataFrame
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report
from learning_curve import *
from pylab import mpl
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
mpl.rcParams['font.sans-serif'] = ['SimHei'] #使得plt操作可以显示中文
from sklearn.feature_extraction import DictVectorizer data_train = pd.read_csv('train.csv')
data_test = pd.read_csv('test.csv') feature = ['Pclass','Age','Sex','Fare','Cabin','Embarked','SibSp','Parch'] # 考虑的特征 X_train = data_train[feature]
y_train = data_train['Survived'] X_test = data_test[feature] X_train.loc[data_train['SibSp']<3, 'SibSp'] = 1 #按照人数3来划分
X_train.loc[data_train['SibSp']>=3, 'SibSp'] = 0
X_train['Age'].fillna(X_train['Age'].mean(), inplace=True)
X_test.loc[data_test['SibSp']<3, 'SibSp']=1
X_test.loc[data_test['SibSp']>=3, 'SibSp'] = 0
X_test['Age'].fillna(X_test['Age'].mean(), inplace=True) # 缺失的年龄补以均值
X_test['Fare'].fillna(X_test['Fare'].mean(), inplace=True)
# X_train.loc[X_train['Age'].isnull(), 'Age'] = X_train['Age'].mean() dummies_SibSp = pd.get_dummies(X_train['SibSp'], prefix='SibSp') #进行dummy coding
dummies_Sex = pd.get_dummies(X_train['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(X_train['Pclass'], prefix='Pclass')
dummies_Emabrked = pd.get_dummies(X_train['Embarked'], prefix='Embarked') ss=StandardScaler() X_train.loc[X_train['Cabin'].isnull(), 'Cabin'] = 1
X_train.loc[X_train['Cabin'].notnull(), 'Cabin'] = 0
X_train['Age_new'] = (X_train['Age']/5).astype(int)
X_train['Fare_new'] = ss.fit_transform(X_train.filter(['Fare']))
X_train = pd.concat([X_train, dummies_Sex, dummies_Pclass, dummies_Emabrked, dummies_SibSp], axis=1)
X_train.drop(['Age', 'Sex', 'Pclass', 'Fare','Embarked', 'SibSp'], axis=1, inplace=True) dummies_SibSp = pd.get_dummies(X_test['SibSp'], prefix='SibSp')
dummies_Sex = pd.get_dummies(X_test['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(X_test['Pclass'], prefix='Pclass')
dummies_Emabrked = pd.get_dummies(X_test['Embarked'], prefix='Embarked') X_test['Age_new'] = (X_test['Age']/5).astype('int')
X_test['Fare_new'] = ss.fit_transform(X_test.filter(['Fare']))
X_test = pd.concat([X_test, dummies_Sex, dummies_Pclass, dummies_Emabrked, dummies_SibSp], axis=1)
X_test.drop(['Age', 'Sex', 'Pclass', 'Fare','Embarked','SibSp'], axis=1, inplace=True)
X_test.loc[X_test['Cabin'].isnull(), 'Cabin'] = 1
X_test.loc[X_test['Cabin'].notnull(), 'Cabin'] = 0 dec = LogisticRegression() # logistic回归
dec.fit(X_train, y_train)
y_pre = dec.predict(X_test) # 交叉验证
all_data = X_train.filter(regex='Cabin|Age_.*|Fare_.*|Sex.*|Pclass_.*|Embarked_.*|SibSp_.*_Parch')
X_cro = all_data.as_matrix()
y_cro = y_train.as_matrix()
est = LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
print(cross_val_score(dec, X_cro, y_cro, cv=5)) # 保存结果
# result = pd.DataFrame({'PassengerId':data_test['PassengerId'].as_matrix(), 'Survived':y_pre.astype(np.int32)})
# result.to_csv("my_logisticregression_1.csv", index=False) # 学习曲线
plot_learning_curve(dec, u"学习曲线", X_train, y_train) # 查看各个特征的相关性
columns = list(X_train.columns)
plt.figure(figsize=(8,8))
plot_df = pd.DataFrame(dec.coef_.ravel(), index=columns)
plot_df.plot(kind='bar')
plt.show() # 分析SibSp
# survived_0 = data_train.SibSp[data_train['Survived']==0].value_counts()
# survived_1 = data_train.SibSp[data_train['Survived']==1].value_counts()
# df = pd.DataFrame({'获救':survived_1, '未获救':survived_0})
# df.plot(kind='bar', stacked=True)
# plt.xlabel('兄妹个数')
# plt.ylabel('获救情况')
# plt.title('兄妹个数与获救情况') # 不加SibSp [ 0.70 0.80446927 0.78651685 0.76966292 0.79661017]
# 加上SibSp [ 0.70 0.78212291 0.80337079 0.79775281 0.81355932] # logistic:[ 0.78212291 0.80446927 0.78651685 0.76966292 0.80225989] why?
3.结果分析与总结
1)学习曲线函数:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import learning_curve # 用sklearn的learning_curve得到training_score和cv_score,使用matplotlib画出learning curve
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None, n_jobs=1,
train_sizes=np.linspace(.05, 1., 20), verbose=0, plot=True):
"""
画出data在某模型上的learning curve.
参数解释
----------
estimator : 你用的分类器。
title : 表格的标题。
X : 输入的feature,numpy类型
y : 输入的target vector
ylim : tuple格式的(ymin, ymax), 设定图像中纵坐标的最低点和最高点
cv : 做cross-validation的时候,数据分成的份数,其中一份作为cv集,其余n-1份作为training(默认为3份)
n_jobs : 并行的的任务数(默认1)
"""
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes, verbose=verbose) train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1) if plot:
plt.figure(1)
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel(u"训练样本数")
plt.ylabel(u"得分")
plt.gca().invert_yaxis()
plt.grid() plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std,
alpha=0.1, color="b")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std,
alpha=0.1, color="r")
plt.plot(train_sizes, train_scores_mean, 'o-', color="b", label=u"训练集上得分")
plt.plot(train_sizes, test_scores_mean, 'o-', color="r", label=u"交叉验证集上得分") plt.legend(loc="best") plt.draw()
plt.show()
plt.gca().invert_yaxis() midpoint = ((train_scores_mean[-1] + train_scores_std[-1]) + (test_scores_mean[-1] - test_scores_std[-1])) / 2
diff = (train_scores_mean[-1] + train_scores_std[-1]) - (test_scores_mean[-1] - test_scores_std[-1])
return midpoint, diff
learning_curve.py
见下图:将learning_curve画出可以看到两者在0.8左右趋于平行,但是正确率不够高,应该是属于欠拟合。所以可以考虑加入新的特征,再对特征进行更深的挖掘 。

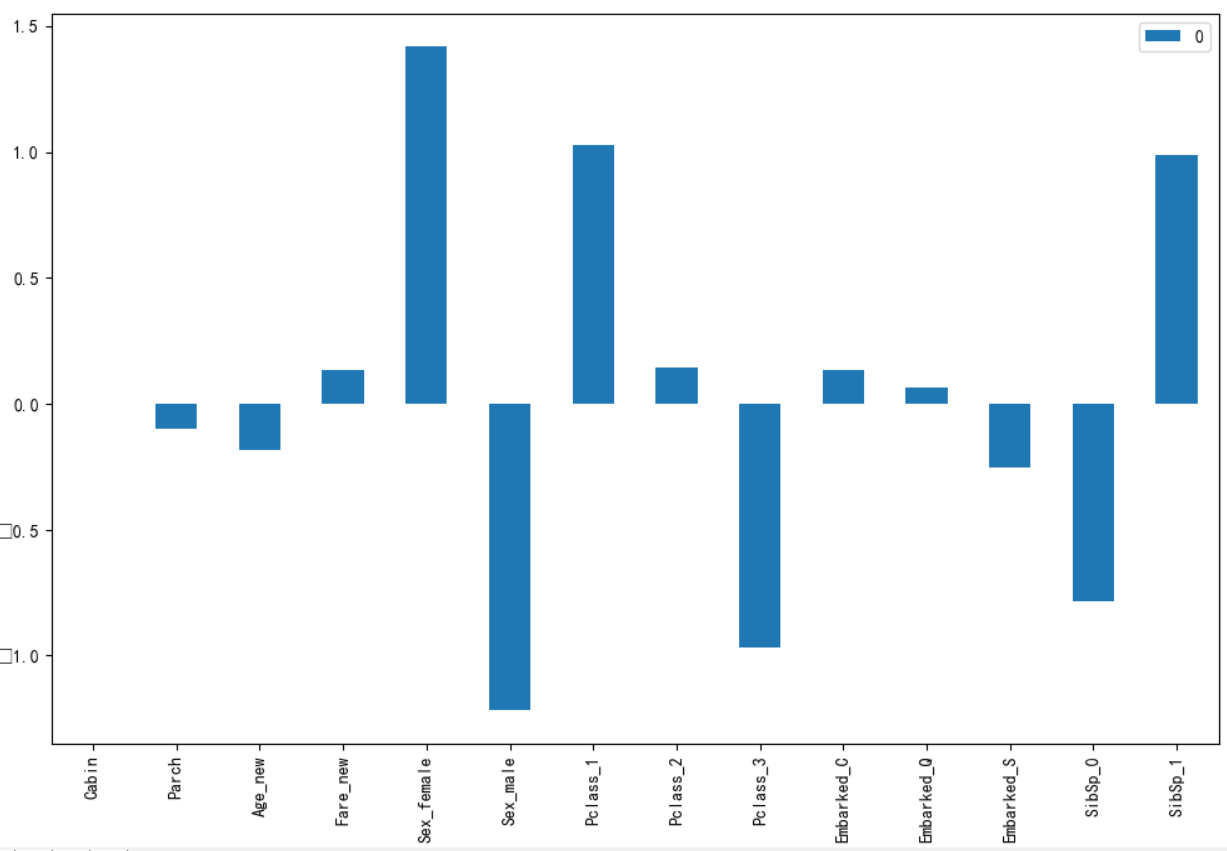
2)特征相关性分析图
columns = list(X_train.columns)
plt.figure(figsize=(8,8))
plot_df = pd.DataFrame(dec.coef_.ravel(), index=columns)
plot_df.plot(kind='bar')
plt.show()
结果见下图:通过logistic学到的参数权重
性别、等级和亲属相关性较强,而亲属在前面已经了解到相关性并不强,所以可以对这一特征加以优化,例如将Parch+SibSp作为一个新特征。
其他特征或正相关或负相关,但都不太明显。
cabin怎么没有相关性呢?
3)交叉验证
# 交叉验证
all_data = X_train.filter(regex='Cabin|Age_.*|Fare_.*|Sex.*|Pclass_.*|Embarked_.*|SibSp_.*_Parch')
X_cro = all_data.as_matrix()
y_cro = y_train.as_matrix()
est = LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
print(cross_val_score(dec, X_cro, y_cro, cv=5))
每次通过训练集学习到参数后进行分类,但是怎么评价结果的好坏呢,可以利用交叉验证来实现,根据交叉验证的结果大致可以知道运用于测试集的结果。
这是本次测试的交叉验证结果: [ 0.78212291 0.80446927 0.78651685 0.76966292 0.80225989]
实际提交到Kaggle上时候准确率为0.7751

参考:
机器学习系列(3)_逻辑回归应用之Kaggle泰坦尼克之灾
机器学习笔记(1)-分析框架-以Kaggle Titanic问题为例
机器学习一小步:Kaggle上的练习Titanic: Machine Learning from Disaster(一)
Kaggle 泰坦尼克的更多相关文章
- Kaggle泰坦尼克数据科学解决方案
原文地址如下: https://www.kaggle.com/startupsci/titanic-data-science-solutions --------------------------- ...
- 逻辑回归应用之Kaggle泰坦尼克之灾(转)
正文:14pt 代码:15px 1 初探数据 先看看我们的数据,长什么样吧.在Data下我们train.csv和test.csv两个文件,分别存着官方给的训练和测试数据. import pandas ...
- pytorch kaggle 泰坦尼克生存预测
也不知道对不对,就凭着自己的思路写了一个 数据集:https://www.kaggle.com/c/titanic/data import torch import torch.nn as nn im ...
- python__画图表可参考(转自:寒小阳 逻辑回归应用之Kaggle泰坦尼克之灾)
出处:http://blog.csdn.net/han_xiaoyang/article/details/49797143 2.背景 2.1 关于Kaggle 我是Kaggle地址,翻我牌子 亲,逼格 ...
- Kaggle泰坦尼克-Python(建模完整流程,小白学习用)
参考Kernels里面评论较高的一篇文章,整理作者解决整个问题的过程,梳理该篇是用以了解到整个完整的建模过程,如何思考问题,处理问题,过程中又为何下那样或者这样的结论等! 最后得分并不是特别高,只是到 ...
- 逻辑回归应用之Kaggle泰坦尼克之灾
机器学习系列(3)_逻辑回归应用之Kaggle泰坦尼克之灾 标签: 机器学习应用 2015-11-12 13:52 3688人阅读 评论(15) 收藏 举报 本文章已收录于: 机器学习知识库 分类 ...
- Kaggle_泰坦尼克乘客存活预测
转载 逻辑回归应用之Kaggle泰坦尼克之灾 此转载只为保存!!! ————————————————版权声明:本文为CSDN博主「寒小阳」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附 ...
- kaggle之泰坦尼克的沉没
Titanic 沉没 参见:https://github.com/lijingpeng/kaggle 这是一个分类任务,特征包含离散特征和连续特征,数据如下:Kaggle地址.目标是根据数据特征预测一 ...
- 利用python进行泰坦尼克生存预测——数据探索分析
最近一直断断续续的做这个泰坦尼克生存预测模型的练习,这个kaggle的竞赛题,网上有很多人都分享过,而且都很成熟,也有些写的非常详细,我主要是在牛人们的基础上,按照数据挖掘流程梳理思路,然后通过练习每 ...
随机推荐
- Zabbix 添加对交换机端口流量超出阈值的监控
点击返回:自学Zabbix之路 点击返回:自学Zabbix4.0之路 点击返回:自学zabbix集锦 22 Zabbix 添加对交换机端口流量超出阈值的监控 本文主要讲解利用zabbix 添加对交换机 ...
- 洛谷 P1378 油滴扩展 改错
P1378 油滴扩展 题目描述 在一个长方形框子里,最多有\(N(0≤N≤6)\)个相异的点,在其中任何一个点上放一个很小的油滴,那么这个油滴会一直扩展,直到接触到其他油滴或者框子的边界.必须等一个油 ...
- 单片机如何产生PWM信号
用89C52产生控制二相步进电机的程序,用PWM信号控制步进电机 用普通I/O口采用软件定时器中断可以模拟PWM输出 /*采用6MHz晶振,在P1.0脚上输出周期为2.5s,占空比为20%的脉冲信号* ...
- [CF1091D]New Year and the Permutation Concatenation
link 题目大意 给$n!$个$n$的排列,按字典序从小到大连成一条序列,例如$3$的情况为:$[1,2,3, 1,3,2, 2,1,3 ,2,3,1 ,3,1,2 ,3,2,1]$,问其中长度为$ ...
- MVC中权限的知识点及具体实现代码
一:知识点部分 权限是做网页经常要涉及到的一个知识点,在使用MVC做权限设计时需要先了解以下知识: MVC中Url的执行是按照Controller->Action->View页面,但是我们 ...
- 关于scrollintoview()真的是有意思极了,结合普通tab切换一起看看
scrollIntoView(alignWithTop) 是html5新特性中的一个元素,他主要是指滚动浏览器窗口或容器元素,以便在当前视窗的可见范围看见当前元素. alignWithTop是true ...
- 洛谷 P1020 导弹拦截(dp+最长上升子序列变形)
传送门:Problem 1020 https://www.cnblogs.com/violet-acmer/p/9852294.html 讲解此题前,先谈谈何为最长上升子序列,以及求法: 一.相关概念 ...
- jdk8的特性stream().map()
转: https://blog.csdn.net/sanchan/article/details/70753645 java8的optional的使用: http://www.jdon.com/ide ...
- spring校验注解
@Null 被注释的元素必须为 null @NotNull 被注释的元素必须不为 null @AssertTrue 被注释的元素必须为 true @AssertFalse 被注 ...
- CPU密集型和I/O密集型区别
CPU密集型 一些进程绝大多数时间在计算上,称为计算密集型(CPU密集型)computer-bound.一些大量循环的代码(例如:图片处理.视频编码.人工智能等)就是CPU密集型. I/O密集型 有一 ...